ClickHouse集群搭建总结
简介
ClickHouse是俄罗斯最大的搜素引擎Yandex于2016年开源的列式数据库管理系统,使用C++ 语言编写, 主要应用于OLAP场景。
使用理由
在大数据量的情况下,能以很低的延迟返回查询结果。
笔者注: 在单机亿级数据量的场景下可以达到毫秒级的查询性能,单机能处理百亿的数据量, 聚合、计数、求和等统计操作的性能是MySQL的100倍。
主要特点
- 列式储存
- 数据压缩
- 支持大部分标准sql
- 支持分区(类似分表)
- 使用稀疏索引作为索引的主要实现
- 支持分布式
- 可以在牺牲精度的前提下,快速的返回一个近似结果
缺点
- 没有完整的事务支持。
- 缺少高频率,低延迟的修改或删除已存在数据的能力。
- 稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
- 没有自增类型
来源:ClickHouse使用总结_推迟享受。的博客-CSDN博客
ClickHouse集群架构

ClickHouse分片
定义
ClickHouse中的每个服务节点都可称为一个shard(分片)。
Distributed表引擎自身不存储任何数据,它能够作为分布式表的一层透明代理,在集群内部自动开展数据的写入、分发、查询、路由等工作。
zk作用
Zookeeper 安装3节点,版本要求在 ZooKeeper 3.4.5 或更高版本.
你可以配置任何现有的 ZooKeeper 集群,系统会使用里面的目录来存取元数据(该目录在创建可复制表时指定)。
如果配置文件中没有设置 ZooKeeper ,则无法创建复制表,并且任何现有的复制表都将变为只读。
在 ClickHouse 中,ZooKeeper 不参与任何实质性的数据传输。ZooKeeper 在 ClickHouse 中主要用在副本表数据的同步(ReplicatedMergeTree引擎)以及分布式表(Distributed)的操作上。因此需要确保zk集群的硬盘空间和高可用。
查看zk配置是否生效
如果 Zookeeper 配置成功,可以查看 system.zookeeper 这张表,如果存在则表示配置成功,不存在请检查各节点关于 Zookeeper 的配置,同时也可以利用该表查看 Zookeeper 中的元数据信息
select * from system.zookeeper where path='/';
docker搭建ck集群
系统准备
#关闭firewall 与 selinux 和 swap
systemctl disabled firewalled && systemctl stop firewalled
setenforce 0
sed -ri 's#(^SELINUX=).*#\1disabled#g' /etc/selinux/config
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
搭建zk集群
Zookeeper 安装3节点,版本要求在 ZooKeeper 3.4.5 或更高版本.
在每个服务器上你想存放的位置,新建一个文件夹来存放zk的配置信息,这里是 /usr/soft/zookeeper/ ,在每个服务器上依次运行以下启动命令:
server01执行:
暴露出的使用端口是2181端口,集群通信端口是2888和3888端口。
docker run -d --name zookeeper_node --restart always \
-v /usr/soft/zookeeper/data:/data \
-v /usr/soft/zookeeper/datalog:/datalog \
-v /usr/soft/zookeeper/logs:/logs \
-v /usr/soft/zookeeper/conf:/conf \
--network host \
-e ZOO_MY_ID=1 zookeeper
server02执行:
docker run -d --name zookeeper_node --restart always \
-v /usr/soft/zookeeper/data:/data \
-v /usr/soft/zookeeper/datalog:/datalog \
-v /usr/soft/zookeeper/logs:/logs \
-v /usr/soft/zookeeper/conf:/conf \
--network host \
-e ZOO_MY_ID=2 zookeeper
server03执行:
docker run -d --name zookeeper_node --restart always \
-v /usr/soft/zookeeper/data:/data \
-v /usr/soft/zookeeper/datalog:/datalog \
-v /usr/soft/zookeeper/logs:/logs \
-v /usr/soft/zookeeper/conf:/conf \
--network host \
-e ZOO_MY_ID=3 zookeeper
创建目录
创建ClickHouse的工作目录,每个节点都要创建:
mkdir -p /data/clickhouse/data
mkdir -p /data/clickhouse/logs
mkdir -p /data/clickhouse/conf
配置文件
1.config.xml
在每个节点 /data/clickhouse/conf 目录下放入文件:config.xml,注意检查端口,避免冲突。
trace
/var/log/clickhouse-server/clickhouse-server.log
/var/log/clickhouse-server/clickhouse-server.err.log
1000M
10
8123
10000
9004
9005
9009
0.0.0.0
4096
3
false
/path/to/ssl_cert_file
/path/to/ssl_key_file
false
/path/to/ssl_ca_cert_file
none
0
-1
-1
false
none
true
true
sslv2,sslv3
true
true
true
sslv2,sslv3
true
RejectCertificateHandler
100
0
10000
0.9
4194304
0
8589934592
5368709120
1000
134217728
10000
/var/lib/clickhouse/
/var/lib/clickhouse/tmp/
`
/var/lib/clickhouse/user_files/
users.xml
/var/lib/clickhouse/access/
false
false
false
false
default
default
true
false
' | sed -e 's|.*>\(.*\)<.*|\1|')
wget https://github.com/ClickHouse/clickhouse-jdbc-bridge/releases/download/v$PKG_VER/clickhouse-jdbc-bridge_$PKG_VER-1_all.deb
apt install --no-install-recommends -f ./clickhouse-jdbc-bridge_$PKG_VER-1_all.deb
clickhouse-jdbc-bridge &
* [CentOS/RHEL]
export MVN_URL=https://repo1.maven.org/maven2/com/clickhouse/clickhouse-jdbc-bridge/
export PKG_VER=$(curl -sL $MVN_URL/maven-metadata.xml | grep '' | sed -e 's|.*>\(.*\)<.*|\1|')
wget https://github.com/ClickHouse/clickhouse-jdbc-bridge/releases/download/v$PKG_VER/clickhouse-jdbc-bridge-$PKG_VER-1.noarch.rpm
yum localinstall -y clickhouse-jdbc-bridge-$PKG_VER-1.noarch.rpm
clickhouse-jdbc-bridge &
Please refer to https://github.com/ClickHouse/clickhouse-jdbc-bridge#usage for more information.
]]>
/etc/clickhouse-server/config.d/metrika.xml
3600
3600
60
system
query_log
toYYYYMM(event_date)
7500
system
trace_log
toYYYYMM(event_date)
7500
system
query_thread_log
toYYYYMM(event_date)
7500
system
query_views_log
toYYYYMM(event_date)
7500
system
part_log
toYYYYMM(event_date)
7500
system
metric_log
7500
1000
system
asynchronous_metric_log
7000
engine MergeTree
partition by toYYYYMM(finish_date)
order by (finish_date, finish_time_us, trace_id)
system
opentelemetry_span_log
7500
system
crash_log
1000
system
processors_profile_log
toYYYYMM(event_date)
7500
*_dictionary.xml
*_function.xml
/clickhouse/task_queue/ddl
click_cost
any
0
3600
86400
60
max
0
60
3600
300
86400
3600
/var/lib/clickhouse/format_schemas/
hide encrypt/decrypt arguments
((?:aes_)?(?:encrypt|decrypt)(?:_mysql)?)\s*\(\s*(?:'(?:\\'|.)+'|.*?)\s*\)
\1(???)
false
false
https://[email protected]/5226277
2.metrika.xml
在每个节点 /data/clickhouse/conf 目录下放入文件:metrika.xml,注意每个节点的副本名称都需要修改,不能冲突。本次我们搭建的是一个2节点,无副本的集群。
注意 所有节点/etc/hosts要把需要的zk和ck主机名配置进去。
true
bigdata1
10000
clickhouse
clickhouse
true
bigdata2
10000
clickhouse
clickhouse
bigdata1
2181
bigdata2
2181
bigdata3
2181
single
r1
分片副本组合使用
在实际生产环境中,为了能够达到高可用,会对每个分片进行备份,即对每个节点的本地表进行备份,将分片和副本组合使用,组合的方式采用环形复制拓扑,充分利用两者的优势。如下图所示为一个 3 分片 + 1 副本的分布式表。
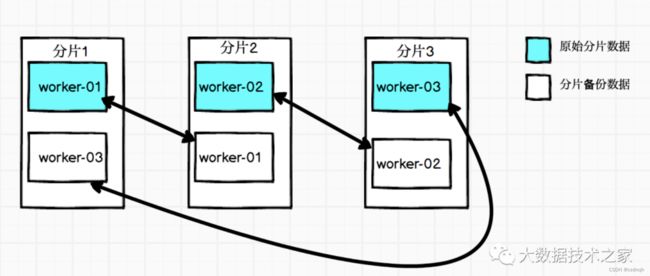
宏变量配置样例
01
03
worker_01
02
01
worker_02
03
02
worker_03
3.users.xml
在每个节点 /data/clickhouse/conf 目录下放入文件:users.xml,用于资源配置。
10000000000
10000000000
300
5000000000
1
::/0
default
default
3600
0
0
0
0
0
也可以在命令行中创建用户:
create database if not exists tutorial;
CREATE ROLE dba;GRANT all ON *.* TO dba;
CREATE USER dba_u@'%' IDENTIFIED WITH sha256_password BY '密码';
GRANT dba TO dba_u;
GRANT all ON tutorial.* TO 'dba_u';
启动服务
docker-compose -f docker-compose.yml up -d clickhouse
version: '2'
services:
clickhouse:
container_name: clickhouse
image: clickhouse/clickhouse-server:22.9.7.34
restart: always
privileged: true
environment:
- TZ=Asia/Shanghai
- CLICKHOUSE_USER=clickhouse
- CLICKHOUSE_PASSWORD=clickhouse
- CLICKHOUSE_DEFAULT_ACCESS_MANAGEMENT=1
volumes:
- /data/clickhouse/data:/var/lib/clickhouse
- /data/clickhouse/logs:/var/log/clickhouse-server
- /data/clickhouse/conf/config.xml:/etc/clickhouse-server/config.xml
- /data/clickhouse/conf/users.xml:/etc/clickhouse-server/users.xml
- /data/clickhouse/conf/metrika.xml:/etc/clickhouse-server/config.d/metrika.xml
- /etc/hosts:/etc/hosts
hostname: bigdata1
ulimits:
nofile:
soft: 262144
hard: 262144
network_mode: 'host'来源:
https://www.cnblogs.com/chuijingjing/p/17051485.html
数据库 - ClickHouse安装及集群搭建 - 个人文章 - SegmentFault 思否
https://mp.weixin.qq.com/s/L0XIstgsrDiAGjhhhqoQrw
Clickhouse Docker集群部署
Docker快速搭建Clickhouse集群(3分片3副本) - 爱码网
验证:
创建本地表
MergeTree,这个引擎本身不具备同步副本的功能,如果指定的是ReplicaMergeTree,会同步到对应的replica上面去。一般在实际应用中,创建分布式表指定的都是Replica的表。
分布式表本身不存储数据,数据存储其实还是由本地表t_cluster完成的。这个dist_t_cluster仅仅做一个代理的作用。
如果在任意节点创建表以后,其他节点都能同步到表结构,说明集群生效。
CREATE TABLE default.test ON CLUSTER clickhouse_cluster
(
name String DEFAULT 'lemonNan' COMMENT '姓名',
age int DEFAULT 18 COMMENT '年龄',
gongzhonghao String DEFAULT 'lemonCode' COMMENT '公众号',
my_time DateTime64(3, 'UTC') COMMENT '时间'
) ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(my_time)
ORDER BY my_time
CREATE TABLE t_cluster ON CLUSTER clickhouse_cluster (
id Int16,
name String,
birth Date
)ENGINE = MergeTree()
PARTITION BY toYYYYMM(birth)
创建分布式表
CREATE TABLE default.dist_t_cluster ON CLUSTER clickhouse_cluster as t_cluster engine = Distributed(clickhouse_cluster, default, t_cluster, rand());
插入测试数据
多插入几条,在任意节点上查看分布式表,都能够看到数据。
insert into dist_t_cluster values(1, 'aaa', '2021-02-01'), (2, 'bbb', '2021-02-02');
客户端工具
大数据ClickHouse(二十):ClickHouse 可视化工具操作 - 知乎