深度应用驱动的医学知识图谱构建(二)

更多分享请关注公众号 系统之神与我同在
数研院医学知识图谱构建
1.模型建立
医学领域的知识图谱由于其知识专业性强,行业通常采用自 上而下的方式,先构建Schema,再抽取知识。
数研院医学知识图谱Schema主要参考了UMLS语义网络、http://Schema.org、cnschema等建立,涉及四大领域

2019年8月首次发布Schema ,目前包含72种语义类型、493种语义关系。

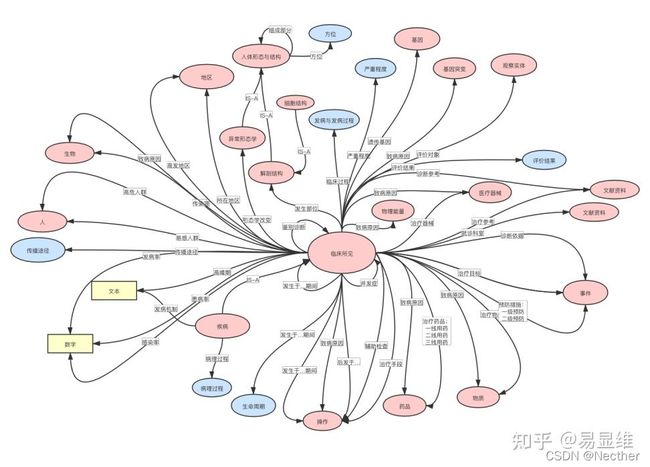
Schema查询和下载网址:http://schema.omaha.org.cn
Schema分别用于指导“七巧板”医学本体术语集和“汇知”医学知识图谱的构建,完善医学知识表达的体系。

2.“七巧板” 本体术语集构建
2.1确定领域范畴
以满足临床诊疗需求为切入点,开始尝试构建医学知识图谱:

2.2选取合适的知识源
充分收录行业现行标准、教科书、指南等权威知识源,并同时补充临床病历、互联网诊疗中的术语。

2.3梳理重要术语
梳理领域中的重要术语,并由领域专家进行语义层面的实体归一,完成概念化。

2.4建立关系
“七巧板”医学本体术语集的核心构件包括:概念、术语、关系及映射。

充分保留知识源中的已有层级关系,通过机器推理、人工添加的方式进行优化:

挖掘知识源中的属性关系,并通过机器推荐、人工添加进行补充:
制定明确的映射规则,采用机器推荐、专家审核的方式建立映射:

2.5存储和浏览
采用关系型数据库,分为概念表、术语表、关系表、映射表进行存储,且保留历史痕迹。

术语浏览器实现术语集构件的快速查找,并可按需实现子集定制。

2.6平台及工具支撑
研制知识库维护平台(CoWork),内嵌术语集研制规则, 支持多人共同协作:

术语集编辑器可实现概念层面的编辑功能需求,并支持多人同时在线协作。

术语映射工具利用算法推荐,调高映射效率。
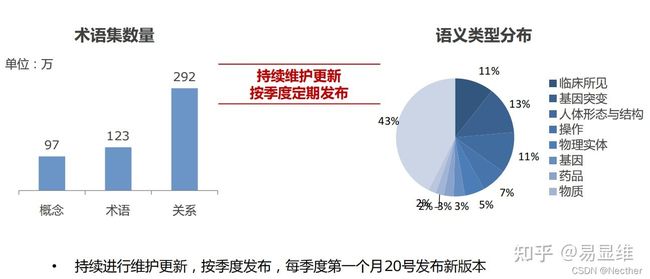
“七巧板”术语集目前收录97万概念、123万术语和292万关系,包含疾病、操作、药品等语义类型:
3.“汇知” 图谱构建
3.1选取合适的知识源
选取临床指南、临床路径、医学书籍文献等权威知识源,并同时补充医学百科类知识:

3.2知识抽取
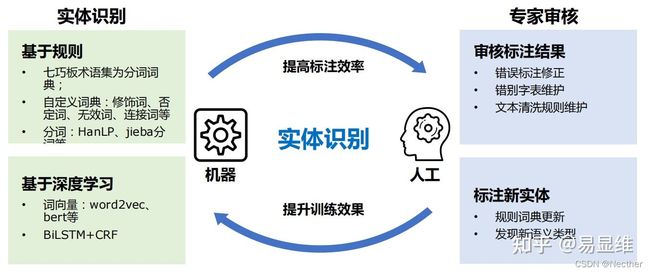
基于规则的命名实体识别+专家审核提高标注效率,产生的标注数据用于训练深度学习模型:
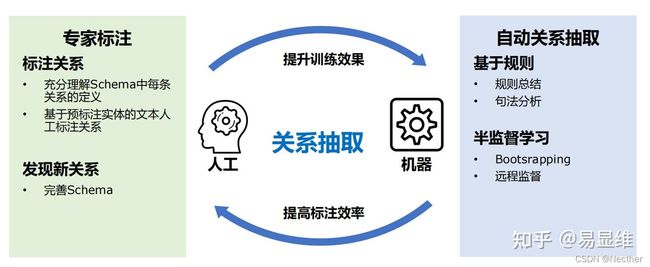
基于实体识别的结果,专家标注关系,产生的标注数据用于句法规则总结和半监督学习:
3.3知识融合
最大化地将“汇知”图谱与“七巧板”术语集融合,可为图谱的深度应用打下基础:
 3.4知识存储和检索
3.4知识存储和检索
除传统的三元组外,加入“属性组”和“来源”字段,使知识表达地更加准确,同时确保知识的可溯源性。

保留三元组的来源,满足三元组在不同场景应用的需求。

通过可视化搜索,可快速直观地查看图谱数据:
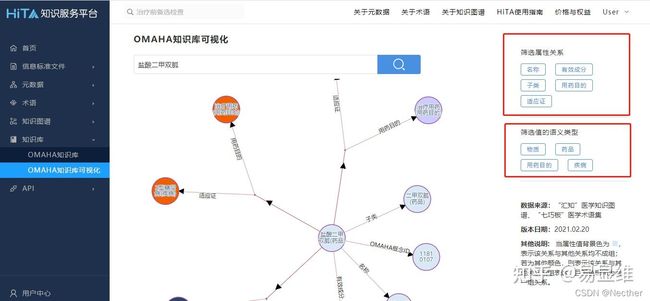
3.5平台及工具支撑
研制知识库维护平台(CoWork),内嵌知识图谱集研制规则,支持多人共同协作。

创建多种自定义标注方案,批量上传和分配任务,在基于brat的文本标注工具上,各地志愿者可合作共建知识图谱:

“汇知”图谱目前已发布7个领域,共计约11万实体,82万三元组。

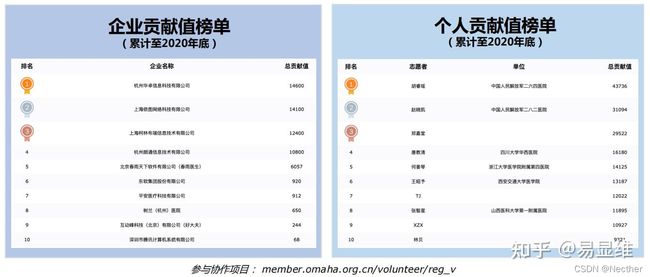
数研院发起的知识图谱协作项目已持续开展5年,已有百名个人志愿者、多家优秀企业参与。
 医学知识图谱应用案例
医学知识图谱应用案例
智能预警:知识图谱作为底层支撑,辅以更多规则,实现更全面的临床诊疗推理。
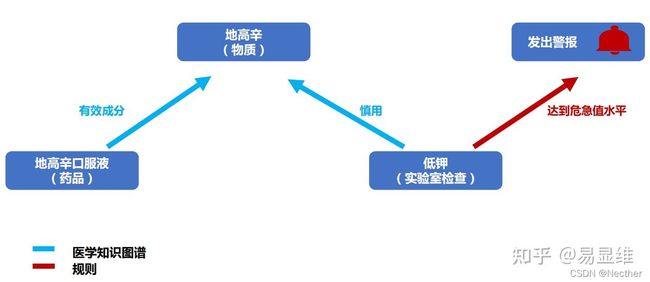
智能预警:基于知识图谱进行推理,实现实验室危急结果的预警和处方异常预警。

指南推荐:基于医学本体层级关系推理后进行推荐,使推荐结果更丰富。
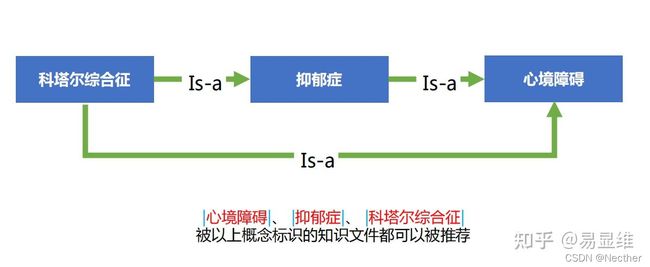
指南推荐:根据患者信息,推荐相似病历、临床路径、指南等,辅助医生制定治疗计划、规范治疗流程。

数据直报:将医学知识图谱中的部分内容作为信息模型中的值集,实现医疗数据与医学知识之间的绑定。

数据直报:信息系统中提前设定相应规则,基于“法定传染病”子集,进行传染病直报判断与提示。

智能编码:通过术语集与ICD编码的映射,使医生关注于临床,提高编码质量、效率,为DRG的实施做好准备。

智能编码:通过智能编码引擎,可快速高效开展医疗数据标准化工作,助力医疗数据分析与应用。

科研分析:在数据治理环节,医学知识图谱可辅助将医疗数据进行标准化、标注等处理,数据得以被深层挖掘。
科研分析:在统计分析环节,利用知识图谱关系,可提供医生更多维度以进行数据分析。
