如何用六步教会你使用python爬虫爬取数据
前言:
用python的爬虫爬取数据真的很简单,只要掌握这六步就好,也不复杂。以前还以为爬虫很难,结果一上手,从初学到把东西爬下来,一个小时都不到就解决了。
python爬出六部曲
第一步:安装requests库和BeautifulSoup库:
在程序中两个库的书写是这样的:
import` `requests``from` `bs4 ``import` `BeautifulSoup
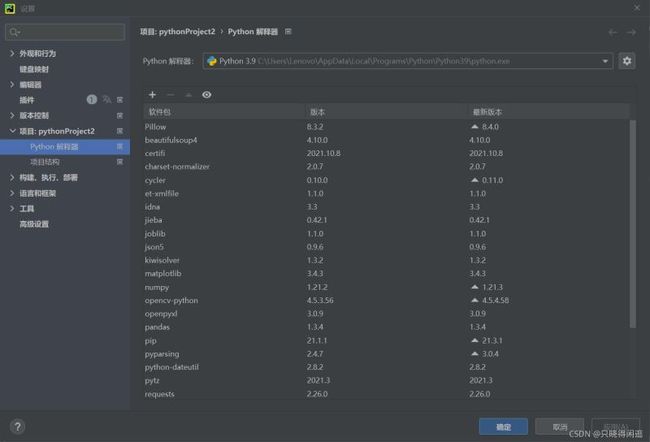
由于我使用的是pycharm进行的python编程。所以我就讲讲在pycharm上安装这两个库的方法。在主页面文件选项下,找到设置。进一步找到项目解释器。之后在所选框中,点击软件包上的+号就可以进行查询插件安装了。有过编译器插件安装的hxd估计会比较好入手。具体情况就如下图所示。
第二步:获取爬虫所需的header和cookie:
我写了一个爬取微博热搜的爬虫程序,这里就直接以它为例吧。获取header和cookie是一个爬虫程序必须的,它直接决定了爬虫程序能不能准确的找到网页位置进行爬取。
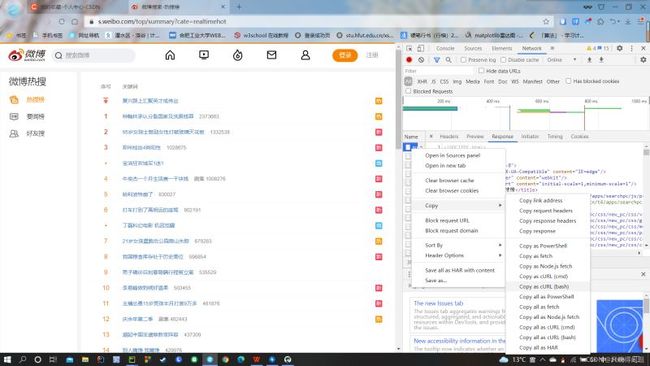
首先进入微博热搜的页面,按下F12,就会出现网页的js语言设计部分。如下图所示。找到网页上的Network部分。然后按下ctrl+R刷新页面。如果,进行就有文件信息,就不用刷新了,当然刷新了也没啥问题。然后,我们浏览Name这部分,找到我们想要爬取的文件,鼠标右键,选择copy,复制下网页的URL。就如下图所示。
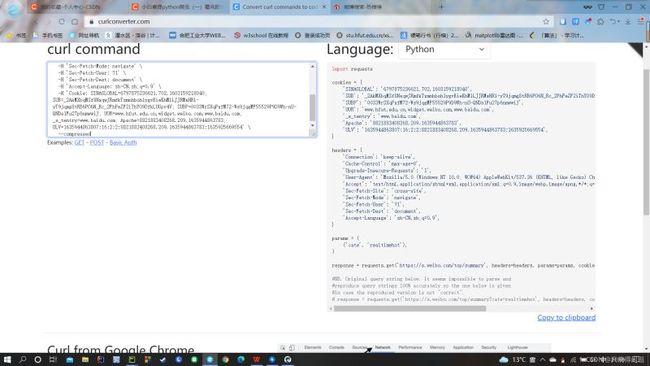
复制好URL后,我们就进入一个网页Convert curl commands to code。这个网页可以根据你复制的URL,自动生成header和cookie,如下图。生成的header和cookie,直接复制走就行,粘贴到程序中。
#爬虫头数据``cookies ``=` `{`` ``'SINAGLOBAL'``: ``'6797875236621.702.1603159218040'``,`` ``'SUB'``: ``'_2AkMXbqMSf8NxqwJRmfkTzmnhboh1ygvEieKhMlLJJRMxHRl-yT9jqmg8tRB6PO6N_Rc_2FhPeZF2iThYO9DfkLUGpv4V'``,`` ``'SUBP'``: ``'0033WrSXqPxfM72-Ws9jqgMF55529P9D9Wh-nU-QNDs1Fu27p6nmwwiJ'``,`` ``'_s_tentry'``: ``'www.baidu.com'``,`` ``'UOR'``: ``'www.hfut.edu.cn,widget.weibo.com,www.baidu.com'``,`` ``'Apache'``: ``'7782025452543.054.1635925669528'``,`` ``'ULV'``: ``'1635925669554:15:1:1:7782025452543.054.1635925669528:1627316870256'``,``}``headers ``=` `{`` ``'Connection'``: ``'keep-alive'``,`` ``'Cache-Control'``: ``'max-age=0'``,`` ``'Upgrade-Insecure-Requests'``: ``'1'``,`` ``'User-Agent'``: ``'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6241 SLBChan/25'``,`` ``'Accept'``: ``'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'``,`` ``'Sec-Fetch-Site'``: ``'cross-site'``,`` ``'Sec-Fetch-Mode'``: ``'navigate'``,`` ``'Sec-Fetch-User'``: ``'?1'``,`` ``'Sec-Fetch-Dest'``: ``'document'``,`` ``'Accept-Language'``: ``'zh-CN,zh;q=0.9'``,``}``params ``=` `(`` ``(``'cate'``, ``'realtimehot'``),``)
复制到程序中就像这样。这是微博热搜的请求头。
第三步:获取网页:
我们将header和cookie搞到手后,就可以将它复制到我们的程序里。之后,使用request请求,就可以获取到网页了。
#获取网页``response ``=` `requests.get(``'https://s.weibo.com/top/summary'``, headers``=``headers, params``=``params, cookies``=``cookies)
第四步:解析网页:
这个时候,我们需要回到网页。同样按下F12,找到网页的Elements部分。用左上角的小框带箭头的标志,如下图,点击网页内容,这个时候网页就会自动在右边显示出你获取网页部分对应的代码。
![]()
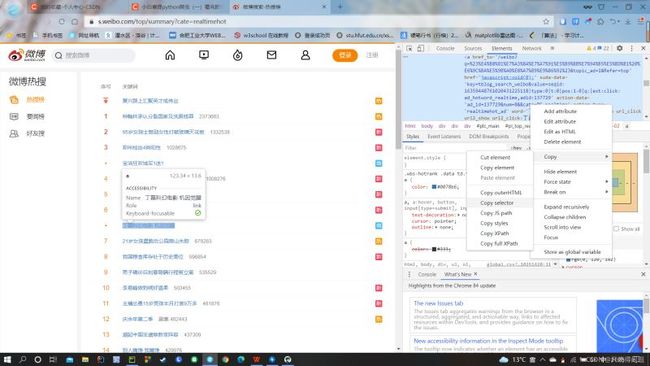
如上图所示,我们在找到想要爬取的页面部分的网页代码后,将鼠标放置于代码上,右键,copy到selector部分。就如上图所示。
第五步:分析得到的信息,简化地址:
其实刚才复制的selector就相当于网页上对应部分存放的地址。由于我们需要的是网页上的一类信息,所以我们需要对获取的地址进行分析,提取。当然,就用那个地址也不是不行,就是只能获取到你选择的网页上的那部分内容。
#pl_top_realtimehot > table > tbody > tr:nth-child(1) > td.td-02 > a``#pl_top_realtimehot > table > tbody > tr:nth-child(2) > td.td-02 > a``#pl_top_realtimehot > table > tbody > tr:nth-child(9) > td.td-02 > a
这是我获取的三条地址,可以发现三个地址有很多相同的地方,唯一不同的地方就是tr部分。由于tr是网页标签,后面的部分就是其补充的部分,也就是子类选择器。可以推断出,该类信息,就是存储在tr的子类中,我们直接对tr进行信息提取,就可以获取到该部分对应的所有信息。所以提炼后的地址为:
#pl_top_realtimehot > table > tbody > tr > td.td-02 > a
这个过程对js类语言有一定了解的hxd估计会更好处理。不过没有js类语言基础也没关系,主要步骤就是,保留相同的部分就行,慢慢的试,总会对的。
第六步:爬取内容,清洗数据
这一步完成后,我们就可以直接爬取数据了。用一个标签存储上面提炼出的像地址一样的东西。标签就会拉取到我们想获得的网页内容。
#爬取内容``content``=``"#pl_top_realtimehot > table > tbody > tr > td.td-02 > a"
之后我们就要soup和text过滤掉不必要的信息,比如js类语言,排除这类语言对于信息受众阅读的干扰。这样我们就成功的将信息,爬取下来了。
fo ``=` `open``(``"./微博热搜.txt"``,``'a'``,encoding``=``"utf-8"``)``a``=``soup.select(content)``for` `i ``in` `range``(``0``,``len``(a)):`` ``a[i] ``=` `a[i].text`` ``fo.write(a[i]``+``'\n'``)``fo.close()
我是将数据存储到了文件夹中,所以会有wirte带来的写的操作。想把数据保存在哪里,或者想怎么用,就看读者自己了。
爬取微博热搜的代码实例以及结果展示:
import` `os``import` `requests``from` `bs4 ``import` `BeautifulSoup``#爬虫头数据``cookies ``=` `{`` ``'SINAGLOBAL'``: ``'6797875236621.702.1603159218040'``,`` ``'SUB'``: ``'_2AkMXbqMSf8NxqwJRmfkTzmnhboh1ygvEieKhMlLJJRMxHRl-yT9jqmg8tRB6PO6N_Rc_2FhPeZF2iThYO9DfkLUGpv4V'``,`` ``'SUBP'``: ``'0033WrSXqPxfM72-Ws9jqgMF55529P9D9Wh-nU-QNDs1Fu27p6nmwwiJ'``,`` ``'_s_tentry'``: ``'www.baidu.com'``,`` ``'UOR'``: ``'www.hfut.edu.cn,widget.weibo.com,www.baidu.com'``,`` ``'Apache'``: ``'7782025452543.054.1635925669528'``,`` ``'ULV'``: ``'1635925669554:15:1:1:7782025452543.054.1635925669528:1627316870256'``,``}``headers ``=` `{`` ``'Connection'``: ``'keep-alive'``,`` ``'Cache-Control'``: ``'max-age=0'``,`` ``'Upgrade-Insecure-Requests'``: ``'1'``,`` ``'User-Agent'``: ``'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6241 SLBChan/25'``,`` ``'Accept'``: ``'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'``,`` ``'Sec-Fetch-Site'``: ``'cross-site'``,`` ``'Sec-Fetch-Mode'``: ``'navigate'``,`` ``'Sec-Fetch-User'``: ``'?1'``,`` ``'Sec-Fetch-Dest'``: ``'document'``,`` ``'Accept-Language'``: ``'zh-CN,zh;q=0.9'``,``}``params ``=` `(`` ``(``'cate'``, ``'realtimehot'``),``)``#数据存储``fo ``=` `open``(``"./微博热搜.txt"``,``'a'``,encoding``=``"utf-8"``)``#获取网页``response ``=` `requests.get(``'https://s.weibo.com/top/summary'``, headers``=``headers, params``=``params, cookies``=``cookies)``#解析网页``response.encoding``=``'utf-8'``soup ``=` `BeautifulSoup(response.text, ``'html.parser'``)``#爬取内容``content``=``"#pl_top_realtimehot > table > tbody > tr > td.td-02 > a"``#清洗数据``a``=``soup.select(content)``for` `i ``in` `range``(``0``,``len``(a)):`` ``a[i] ``=` `a[i].text`` ``fo.write(a[i]``+``'\n'``)``fo.close()
总结
到此这篇关于如何用六步教会你使用python爬虫爬取数据的文章就介绍到这了,更多相关python爬虫爬取数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
读者福利:知道你对Python感兴趣,便准备了这套python学习资料
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等习教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
- ① Python所有方向的学习路线图,清楚各个方向要学什么东西
- ② 600多节Python课程视频,涵盖必备基础、爬虫和数据分析
- ③ 100多个Python实战案例,含50个超大型项目详解,学习不再是只会理论
- ④ 20款主流手游迫解 爬虫手游逆行迫解教程包
- ⑤ 爬虫与反爬虫攻防教程包,含15个大型网站迫解
- ⑥ 爬虫APP逆向实战教程包,含45项绝密技术详解
- ⑦ 超300本Python电子好书,从入门到高阶应有尽有
- ⑧ 华为出品独家Python漫画教程,手机也能学习
- ⑨ 历年互联网企业Python面试真题,复习时非常方便
Python学习路线汇总
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

Python必备开发工具

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
Python学习视频600合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

100道Python练习题
检查学习结果。

面试刷题
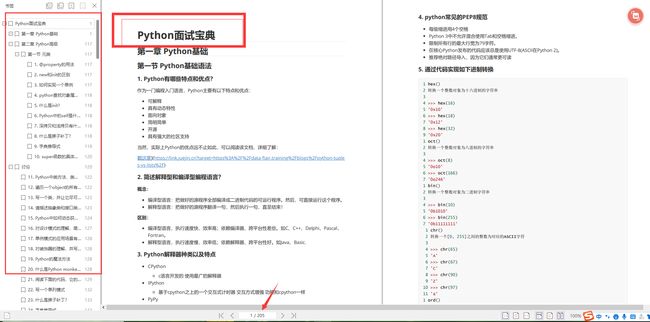

python副业兼职与全职路线

上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码 即可领取↓↓↓
