【论文精读CVPR_2020(Oral)】FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping
【论文精读CVPR_2020】FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping
- 0、前言
- Abstract
- 1. Introduction
- 2. Related Works
-
- 2.1 3D-Based Approaches.
- 2.2 GAN-Based Approaches.
- 3. Methods
-
- 3.1. Adaptive Embedding Integration Network
-
- 3.1.1 Identity Encoder:
- 3.1.2 Multi-level Attributes Encoder:
- 3.1.3 Adaptive Attentional Denormalization Generator:
- 3.1.4 Training Losses
- 3.2 Heuristic Error Acknowledging Refinement Network
- 4. Experiments
-
- 4.1. Comparison with Previous Methods
-
- 4.1.1 Qualitative Comparison:
- 4.1.2 Quantitative Comparison:
- 4.1.3 Human Evaluation:
- 4.2. Analysis of the Framework
-
- 4.2.1 Adaptive Embedding Integration:
- 4.2.2 Multi-level Attributes:
- 4.2.3 Second Stage Refinement
- 4.3. More Results on Wild Faces
- 5. Conclusions
- A. Network Structures
- B. Training Strategies
- 个人思考与总结

0、前言
Lingzhi Li, Jianmin Bao, Hao Yang, Dong Chen, Fang Wen
论文地址:https://arxiv.org/abs/1912.13457
GitHub地址(Unofficial):https://github.com/mindslab-ai/faceshifter
项目地址:https://lingzhili.com/FaceShifterPage/
整体方法的pipeline:
- AEI-Net首先提取源脸身份特征和多尺度的目标脸属性特征,然后输入级联的AAD ResBlk,也就是生成器来生成第一阶段的换脸图像 Y ^ s , t \hat{Y}_{s,t} Y^s,t。其中用到了对抗损失,也即是GAN的训练方法。
- 然后是利用HEAR-Net第二阶段来来处理人脸的遮挡,idea来自目标图像与目标图像的重构图像(第一阶段生成的结果)直接的差异意味着异常发生的位置,也就是遮挡。
四个关键点源脸的形状,目标的照明和图像分辨率,遮挡处理。
| 缩写 | 全拼 |
|---|---|
| AAD | Adaptive Attentional Denormalization,AEI-Net的主要子模块,是一个生成器,用于集成目标属性和源身份。 |
| HEAR-Net | Heuristic Error Acknowledging Refinement Network,就是一个U-net。 |
| AEI-Net | Adaptive Embedding Integration Network,AEI-Net的可训练模块包括多级属性编码器和ADD-Generator,还用了对抗训练,即鉴别器GAN。 |
Abstract
介绍:在这项工作中,我们提出了一个新的两阶段框架,称为FaceShifter,用于高保真和遮挡感知的人脸交换。
与许多现有的人脸交换算法在合成交换人脸时仅利用目标图像中的有限信息不同,我们的框架在第一阶段通过彻底地、自适应地利用和集成目标属性来生成高保真的交换人脸。
我们提出了一种提取多层次目标人脸属性的新属性编码器,以及一种经过精心设计的自适应注意去正规化Adaptive Attentional Denormalization(AAD)层的新生成器,以自适应地整合身份和属性进行人脸合成。
为了解决具有挑战性的面部遮挡,我们附加了一个新的启发式错误确认改进网络((HEAR-Net)的第二阶段。
在不需要人工标注的情况下,以自监督的方式训练异常区域的恢复。实验:大量关于野外人脸的实验表明,与其他最先进的方法相比,我们的换脸结果不仅在感知上更吸引人,而且还能更好地保存身份。
有关生成的数据集和更多细节,请参阅我们的项目网页https://lingzhili.com/FaceShifterPage/
1. Introduction
换脸是指将目标图像中的一个人的身份替换为源图像中的另一个人的身份,同时保留头部姿势、面部表情、光照、背景等属性。
人脸交换技术在电影合成、电脑游戏、隐私保护等领域有着广泛的应用前景,因此在视觉和图形界引起了极大的兴趣。
【换脸介绍】
人脸交换的主要难点是如何提取和自适应重组两幅图像的身份和属性。
早期基于替换的作品[6,42]只是简单地替换了人脸内部区域的像素。
因此,它们对姿势和视角的变化很敏感。
基于3D的作品[7,12,26,31]使用3D模型来处理姿势或视角差异。
然而,人脸三维重建的精度和鲁棒性都不尽人意。
最近,基于GAN的作品[22,28,29,30,4]给出了令人印象深刻的结果。
但要综合真实和高保真的结果仍然是一个挑战。
【换脸的困难:如何提取和自适应重组两幅图像的身份和属性】
在本研究中,我们着重于提高人脸交换的保真度。
为了使结果在感知上更吸引人,重要的是合成的交换人脸不仅可以共享目标人脸的姿态和表情,而且可以无缝地贴合到目标图像中而不产生不一致性:
交换人脸的渲染应该忠实于目标场景的光照(例如,方向,强度,颜色),交换人脸的像素分辨率也应该与目标图像的分辨率一致。
这两种情况都不能通过简单的alpha或泊松混合来处理。
相反,在交换人脸的合成过程中,我们需要对目标图像的属性进行全面的、自适应的整合,使目标图像的属性(包括场景照明或图像分辨率)能够帮助交换人脸更加真实。
【说明了目标脸图像的场景光照(方向,强度,颜色)和像素分辨率的重要性,的确很多方法都没考虑!】
然而,以前的换脸方法要么忽略了这种集成的需求,要么缺乏以一种彻底的、自适应的方式执行它的能力。
具体来说,以往的许多方法只使用目标图像中的姿态和表情指导来合成交换后的人脸,然后利用目标人脸的掩模将人脸混合到目标图像中。
这个过程很容易产生伪影,因为:
1)在合成交换的人脸时,除了姿势和表情,利用的目标图像知识很少,很难尊重场景照明或图像分辨率等目标属性;
2)这样的混合将丢弃源面在目标掩模外部的所有周边区域。
因此,这些方法不能保持源身份的人脸形状。我们在图2中展示了一些典型的故障案例。
【提取源脸身份信息然后用mask混合到目标人脸的方法,不能很好的利用目标图像和源图像周围的信息。容易产生伪影。】
为了实现高保真的人脸交换结果,在我们的框架的第一阶段,我们设计了一个基于GAN的网络,名为自适应嵌入集成网络(AEI-Net),以实现目标属性的全面和自适应集成。
我们对网络结构进行了两方面的改进:
1)我们提出了一种新的多级属性编码器,用于提取不同空间分辨率下的目标属性,而不是如RSGAN[29]和IPGAN[5]将其压缩成单一向量。
2)我们提出了一种新颖的自适应注意去正则化(AAD)生成器,它可以自适应地学习在哪里整合属性或身份嵌入。
与RSGAN[29]、FSNet[28]和IPGAN[5]使用的单级集成相比,这种自适应集成带来了相当大的改进。
通过这两个改进,本文提出的AEI-Net可以解决光照和人脸形状不一致的问题,如图2所示。
【AEI-Net用于集成目标属性,AAD用于自适应整合属性或身份嵌入】
此外,面部遮挡处理一直是人脸交换的挑战。
与Nirkin等人[30,31]训练人脸分割以获得具有遮挡意识的人脸掩模不同,我们的方法可以通过自监督的方式学习恢复人脸异常区域,无需任何手工标注。
我们观察到,当将相同的人脸图像作为目标和源输入一个训练良好的AEI-Net时,重建的人脸图像在多个区域偏离了输入,这些偏离强烈地暗示了人脸遮挡的位置。
因此,我们提出了一种新的启发式误差确认改进网络((HEAR-Net),在这种重构误差的指导下进一步改进结果。
该方法更具有通用性,可以识别更多的异常类型,如眼镜、阴影和反射效应以及其他不常见的遮挡。
【说明文章的灵感来源,以及优点:自监督处理人脸遮挡】
提出的两阶段人脸交换框架FaceShifter是主题不可知的。
一旦训练完成,该模型就可以应用于任何新的面孔对,而不需要像DeepFakes[1]和Korshunova等人[22]那样进行特定的主题训练。
实验表明,与其他先进的方法相比,我们的方法获得的结果更真实,更忠实于输入。
【主题不可知的】

2. Related Works
换脸在视觉和图形学研究中有着悠久的历史。
早期的研究[6,42]只是交换哪些具有相似的姿势面孔。
最近的算法解决了这一局限性,大致分为两类:基于3D的方法和基于GAN的方法。
【3D和GAN方法介绍】
2.1 3D-Based Approaches.
Blanz等人。[7]考虑了不同姿势的两张脸之间的3D变换,但是需要用户交互并且不处理表情。
Thies等人的[39]利用3DMM从RGB-D图像中捕捉头部动作,将静态的脸变成可控制的化身。
它在Face2Face[40]中扩展为RGB引用。
Olszewski等人的[32]动态推断3D人脸纹理,以提高操作质量。
Kim et al.[20]使用3DMM对不同的视频分别建模,使肖像可控,而Nagano et al.[27]只需要一个图像来再现其中的肖像。
最近,Thies等人的[38]采用了神经纹理,可以更好地解决人脸再现中的几何纠缠问题。
然而,当应用于面部交换时,这些方法很难利用目标属性,如遮挡、照明或照片风格。
为了保持目标面部遮挡,Nirkin等人[331,30]收集数据,以监督的方式训练一个遮挡感知的人脸分割网络,这有助于预测一个可见的目标人脸掩膜,用于混合到交换后的人脸中。
而我们的方法在没有任何手工标注的情况下,以自我监督的方式发现遮挡。
【现有3D方法很难利用目标属性,如遮挡、照明或照片风格,FSGAN需要有监督训练】
2.2 GAN-Based Approaches.
在基于GAN的人脸交换方法中,Korshunova等人的[23]交换人脸类似于转换风格。
它分别为不同的来源身份建模,比如尼古拉斯·凯奇的CageNet,泰勒·斯威夫特的SwiftNet。
最近流行的DeepFakes[1]是这种主题感知面部交换的另一个例子:对于每一个新的输入,一个新的模型必须在两个视频序列上训练,一个针对源,一个针对目标。
【很老的方法,每个不同的人都要重新训练】
这一限制已经被主题未知的人脸交换研究解决:
RSGAN[29]学会分别提取人脸和头发区域的矢量嵌入,并将它们重新组合以合成交换的人脸。
FSNet[28]将源图像的人脸区域表示为矢量,与非人脸目标图像相结合,生成交换后的人脸。
IPGAN[5]将人脸的身份和属性分解为向量。
通过直接引入来自源身份和目标图像的监控,IPGAN支持人脸交换,具有更好的身份保存。
但是,由于压缩表示方式造成的信息丢失,以及缺乏更具有自适应性的信息集成,这三种方法都无法生成高质量的人脸图像。
最近,FSGAN[30]同时进行了人脸再现和换脸。
它遵循与[32,27]相似的再制定和混合策略。
虽然FSGAN利用了一个遮挡感知的人脸分割网络来保持目标遮挡,但它几乎不考虑光照或图像分辨率等目标属性,也不能保持源身份的人脸形状。
【FSGAN几乎不考虑光照或图像分辨率等目标属性,也不能保持源身份的人脸形状】
3. Methods
我们的方法需要两个输入图像,即源图像 X s X_s Xs提供身份,目标图像 X t X_t Xt提供属性,如姿势、表情、场景照明和背景。
交换后的人脸图像是通过一个叫做FaceShifter的两阶段框架生成的。
第一阶段,利用自适应嵌入集成网络(AEI-Net)生成基于信息集成的高保真人脸交换结果 Y ^ s , t \hat{Y}_{s,t} Y^s,t。
在第二阶段,我们使用启发式错误确认网络(HEAR-Net)处理面部遮挡并改进结果,最终结果用 Y s , t Y_{s,t} Ys,t表示。
【第一阶段AEI-Net生成 Y ^ s , t \hat{Y}_{s,t} Y^s,t,第二阶段HEAR-Net处理遮挡生成 Y s , t Y_{s,t} Ys,t】
3.1. Adaptive Embedding Integration Network
在第一阶段,我们的目标是生成一个高保真的人脸图像 Y ^ s , t \hat{Y}_{s,t} Y^s,t,它应该保留源 X s X_s Xs的身份和目标 X t X_t Xt的属性(如姿势,表情,光照,背景)。
为了实现这一目标,我们的方法由3个部分组成:
i)身份编码器 z i d ( X s ) z_{id}(X_s) zid(Xs),它从源图像 X s X_s Xs提取身份;
ii)多级属性编码器 z a t t ( X t ) z_{att}(X_t) zatt(Xt),提取目标图像 X t X_t Xt的属性;
iii)自适应注意去正则化(AAD)发生器,生成交换的人脸图像。
图3(a)显示了整个网络结构。
【第一阶段pipeline】

3.1.1 Identity Encoder:
我们使用预先训练的最先进的人脸识别模型[13]作为身份编码器。([13]是Arcface: Additive angular margin loss for deep face recognition.)
定义身份嵌入 z i d ( X s ) z_{id}(X_s) zid(Xs)为最后一层FC层之前生成的最后一个特征向量。
我们认为,通过对大量的2D人脸数据进行训练,这样的人脸识别模型可以提供比3DMM等基于3D的模型更有代表性的身份嵌入[7,8]。
【Arcface提取源脸身份特征】
3.1.2 Multi-level Attributes Encoder:
脸部属性,如姿势、表情、灯光和背景,比身份需要更多的空间信息。
为了保留这些细节,我们提出将嵌入的属性表示为多级特征映射,而不是像以前的方法那样将其压缩为单个向量[5,29]。
具体来说,我们将目标图像 X t X_t Xt输入一个类似U-net的结构中。
然后定义属性嵌入作为U-Net解码器生成的特征映射。
更正式地,我们定义:
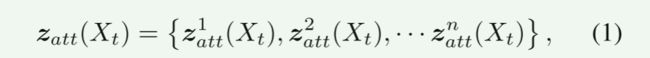
式中 z a t t k ( X t ) z_{att}^k(X_t) zattk(Xt)表示来自U-Net解码器的第k级特征图,n为特征层数。
【类似U-net的多层目标脸属性特征编码】
我们的属性嵌入网络不需要任何属性标注,它通过自监督训练提取属性:我们要求生成的交换面 Y ^ x t \hat{Y}_{x_t} Y^xt和目标图像 X t X_t Xt具有相同的属性嵌入。
损失函数将在方程7中引入。
在实验部分(4.2节),我们也研究了属性嵌入学到了什么。
【自监督训练,加属性的损失函数约束,使得生成脸与目标脸属性相近。缺点是(可能会带回一些目标的身份信息)】
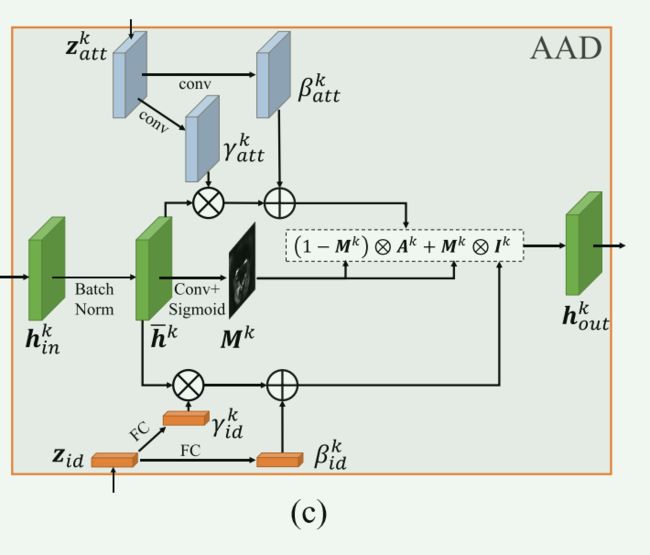
3.1.3 Adaptive Attentional Denormalization Generator:
然后,我们将这两个嵌入方法 z i d ( X s ) z_{id}(X_s) zid(Xs)和 z a t t ( X t ) z_{att}(X_t) zatt(Xt)集成起来,生成原始交换面 Y ^ s , t \hat{Y}_{s,t} Y^s,t。
以前的方法[5,29]只是通过特征串联来进行集成。
它会导致相对模糊的结果。
为此,我们提出了一种新的自适应注意去正则化(AAD)层,以一种更适应的方式来完成这一任务。
受到SPADE[33]和AdaIN机制的启发[14,16],提出的AAD层利用去正规化来实现多个特征级别的特征集成。
【AAD就是多层特征编码】
如图3( c)所示,在第k个特征层中,设 h i n k h^k_{in} hink表示送入AAD层的激活图activation map,该激活图应为大小为 C k × H k × W k C^k ×H^k ×W^k Ck×Hk×Wk的3D张量, C k C^k Ck为通道数, H k × W k H^k ×W^k Hk×Wk为空间维数。
在集成之前,我们在 h i n k h^k_{in} hink上进行批量归一化batch normalization[17]:
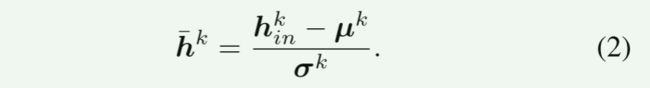
这里, µ k ∈ R C k µ_k∈\mathbb{R}^{C^k} µk∈RCk和 σ k ∈ R C k σ_k∈\mathbb{R}^{C^k} σk∈RCk是 h i n k h^k_{in} hink在小批量中通道激活的平均值和标准差。
然后,我们从 h ˉ k \bar{h}^k hˉk中设计了3个平行分支,分别进行
1)属性集成、2)身份集成和3)自适应注意掩模mask。
对于属性嵌入集成,设 z a t t k z_{att}^k zattk为嵌入在该特征层的属性,该特征层为大小为 C a t t k × H k × W k C^k_{att} × H^k × W^k Cattk×Hk×Wk的三维张量。
为了将 z a t t k z_{att}^k zattk集成到激活中,我们根据嵌入的属性对归一化的 h ˉ k \bar{h}^k hˉk进行去正则化,计算出一个属性激活 A k A^k Ak,公式为:
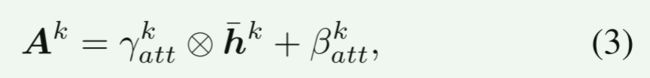
其中 γ a t t k γ^k_{att} γattk和 β a t t k β^k_{att} βattk是两个调制参数,它们都是由 z a t t k z_{att}^k zattk卷积而来的。
它们与 h ˉ k \bar{h}^k hˉk具有相同的张量维。
计算得到的 γ a t t k γ^k_{att} γattk和 β a t t k β^k_{att} βattk分别与 h ˉ k \bar{h}^k hˉk进行元素平均相乘和相加。
【属性嵌入的方法】
对于身份嵌入集成,设 z i d k z^k_{id} zidk为身份嵌入,其大小为 C i d C_{id} Cid的一维向量。
我们还通过计算身份激活 I k I^k Ik来集成 z i d k z^k_{id} zidk,方法与集成属性类似。
它的表达式是:
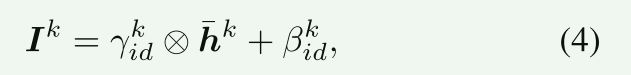
其中 γ i d k ∈ R C k γ^k_{id}∈\mathbb{R}^{C^k} γidk∈RCk和 β i d k ∈ R C k β^k_{id}∈\mathbb{R}^{C^k} βidk∈RCk是另两个由 z i d z_{id} zid通过FC层生成的调制参数。
【身份嵌入的方法】
AAD层的一个关键设计是自适应调整身份嵌入和属性嵌入的有效区域,使它们能够参与人脸不同部位的合成。
例如,身份嵌入应该相对侧重于合成面部最具辨识性的部分,如眼睛、嘴巴和脸部轮廓。
因此,我们在AAD层采用了一种注意机制。
具体来说,我们通过卷积和sigmoid操作,使用 h ˉ k \bar{h}^k hˉk生成一个注意力面具 M k M^k Mk。
M k M^k Mk的值在0到1之间。
【自适应调整嵌入区域,sigmoid操作是获得[0,1]之间的一个数的,也就可以得到注意力面具 M k M^k Mk】
最后,AAD层 h o u t k h^k_{out} houtk的输出可以作为两种激活 A k A^k Ak和 I k I^k Ik的元素级组合,通过掩模 M k M^k Mk加权,如图3( c)所示。它的表达式是:
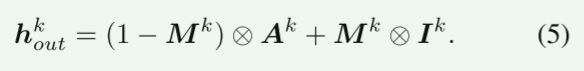
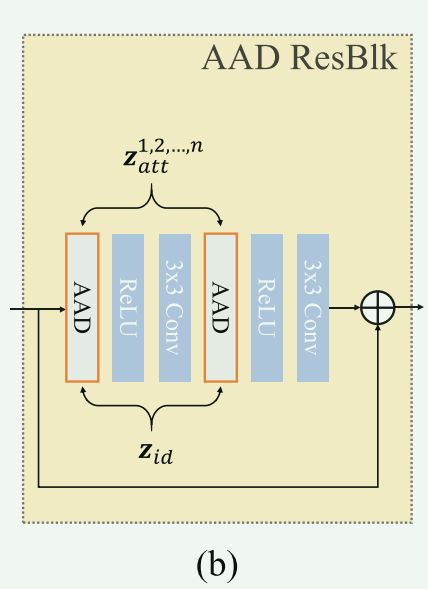
然后,AAD生成器由多个AAD层构建。
如图3(a)所示,从源 X s X_s Xs中提取身份嵌入 z i d z_{id} zid,从目标 X t X_t Xt中提取属性嵌入 z a t t z_{att} zatt后,我们将AAD残差块(AAD ResBlks)级联生成交换面 Y ^ s , t \hat{Y}_{s,t} Y^s,t, AAD ResBlks的结构如图3(b )所示。
对于第k个特征级的AAD ResBlk,它首先将上采样的上一级激活作为输入,然后将该输入与 z i d z_{id} zid和 z a t t k z_{att}^k zattk进行集成。
最终的输出图像 Y ^ s , t \hat{Y}_{s,t} Y^s,t由最后一次激活卷积得到。
【AAD的级联介绍】
3.1.4 Training Losses
我们对AEI-Net进行对抗训练。
让 L a d v \mathcal{L}_{adv} Ladv为使得 Y ^ s , t \hat{Y}_{s,t} Y^s,t现实的对抗损失。
它在下采样输出图像上实现多尺度鉴别器[33]。
此外,身份保存损失用于保存源的身份。
它的表达式是:

其中cos(·,·)表示两个向量的余弦相似度。
我们还将属性保存损失定义为从 X t X_t Xt到 Y ^ s , t \hat{Y}_{s,t} Y^s,t的多级属性嵌入之间的L2距离。
它的表达式是
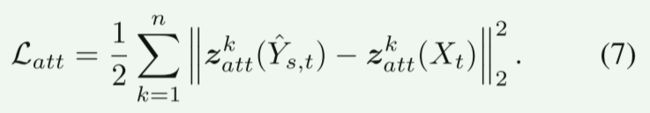
当训练样本中的源图像和目标图像相同时,我们将重建损失定义为目标图像 X t X_t Xt和 Y ^ s , t \hat{Y}_{s,t} Y^s,t之间的像素级L-2距离
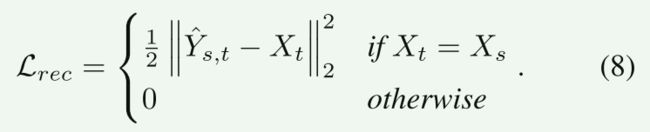
最后以上述损失的加权总和训练AEI-Net

λ a t t = λ r e c = 10 , λ i d = 5 λ_{att} = λ_{rec} = 10, λ_{id} = 5 λatt=λrec=10,λid=5。AEI-Net的可训练模块包括多级属性编码器和ADD-Generator。
【训练AEI-Net的整个损失函数】
最终整个AEI-Net如下图:

3.2 Heuristic Error Acknowledging Refinement Network
虽然在第一阶段用AEI-Net生成的人脸交换结果 Y ^ s , t \hat{Y}_{s,t} Y^s,t可以很好地保留目标的属性,如pose, expression, scene lighting,但往往不能保留目标人脸 X t X_t Xt上出现的遮挡。
以前的方法[31,30]使用附加的人脸分割网络来处理人脸遮挡。
它是在包含有遮挡意识的面罩的人脸数据上训练的,这需要大量的手工标注。
此外,这种监督的方法可能很难识别看不见的遮挡类型。
【监督训练有一些缺陷,如需要太多人力,难以识别看不见的遮挡类型】
我们提出了一种启发式的方法来处理面部遮挡。
如图4(a)所示,当目标人脸被遮挡时,在交换后的人脸中,一些遮挡可能会消失,如覆盖人脸的头发或头巾上挂的链子。
同时,我们观察到,如果我们将源图像和目标图像的相同图像输入训练良好的AEI-Net,这些遮挡在重建图像中也会消失。
因此,重建图像和输入之间的误差可以用来定位人脸遮挡。
我们称其为输入图像的启发式误差heuristic error,因为它启发式地指出异常发生的位置。
【重建图像与输入图像之间的误差代表了异常发生的位置 Δ Y t \Delta Y_t ΔYt,也即是遮挡】

受上述观察的启发,我们利用一种新型的HEAR-Net来生成一幅精细的人脸图像。
首先得到目标图像的启发式误差为:

然后将启发式误差 Δ Y t \Delta Y_t ΔYt和第一级结果 Y ^ s , t \hat{Y}_{s,t} Y^s,t代入U-Net结构,得到精化图像 Y s , t Y_{s,t} Ys,t:

HEAR-Net的流水线如图4(b)所示。
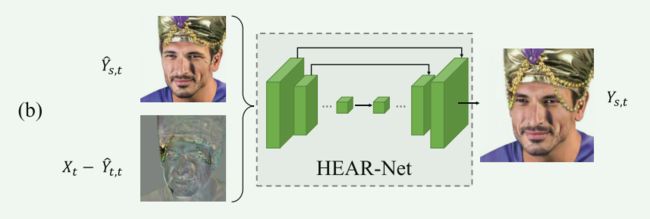
【用 X t X_t Xt的重构图像与其之间的误差,来处理遮挡】
我们以一种完全自监督的方式训练HEAR-Net,而不使用任何手工注释。
给定任意目标人脸图像 X t X_t Xt,有或没有遮挡区域,我们利用以下损失来训练HEAR-Net。
第一种是身份保存损失,以保存源的身份。
与第一阶段相似,它被表述为:
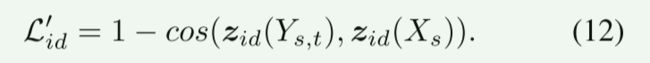
变更损失 L c h g ′ \mathcal{L}^\prime _{chg} Lchg′保证了第一阶段和第二阶段结果的一致性:

重建损失 L r e c ′ \mathcal{L}^\prime _{rec} Lrec′限制了在源图像和目标图像相同的情况下,第二阶段能够重建输入:
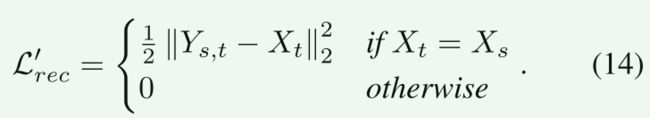
由于在大多数人脸数据集中,被遮挡的人脸数量非常有限,因此我们提出用合成遮挡来增强数据。
闭塞是随机从各种数据集中采样的,包括EgoHands [3], GTEA Hand2K[15,25,24]和ShapeNet[9]。
在随机旋转、缩放和颜色匹配之后,它们被混合到现有的人脸图像中。
请注意,在训练过程中,我们没有使用任何遮挡遮挡监督,即使是这些合成遮挡。
【在数据集中增加了一些遮挡来训练HEAR-Net】
最后,用以上损失之和训练HEAR-Net:

HEAR-Net的pipeline如下:

4. Experiments
Implementation Detail:
对于每一张人脸图像,我们首先使用[11]提取的5个点地标对人脸进行对齐和裁剪,裁剪后的图像大小为256 × 256,覆盖整个人脸以及一些背景区域。
AEI-Net中属性嵌入数设为n = 8(公式1)。
HEAR-Net中downsamples/upsamples设为5。
有关网络结构和训练策略的更多细节,请参阅补充材料。
【属性嵌入数设为n = 8,U-net深度为5】
AEI-Net使用CelebA-HQ[18]、FFHQ[19]和VGGFace[34]进行训练。
而HEAR-Net只使用这些数据集中具有Top-10%启发式错误的部分人脸进行训练,并附加合成遮挡。
遮挡图像随机采样自EgoHands [3], GTEA Hand2K[15,25,24]和对象渲染自ShapeNet[9]。
【训练数据集】
4.1. Comparison with Previous Methods
4.1.1 Qualitative Comparison:
我们在图5中的FaceForensics++[36]测试图像上,将我们的方法与FaceSwap[2]、Nirkin等人[31]、DeepFakes[1]和IPGAN[5]进行比较。
与最新工作FSGAN[30]的比较如图6所示。
我们可以看到,由于FaceSwap、Nirkin等人、DeepFakes和FSGAN都遵循了先合成人脸内部区域,然后再混合到目标人脸的策略,正如预期的那样,他们都存在混合不一致的问题。
这些方法生成的所有人脸都与目标人脸共享完全相同的人脸轮廓,忽略源人脸的形状(图5行1-4,图6行1-2)。
此外,他们的结果不能很好地尊重来自目标图像的关键信息,如光照(图5行3,图6行3-5),图像分辨率(图5行2和4)。
IPGAN[5]由于其属性表示层次单一,所有样本的分辨率都降低了。
IPGAN不能很好地保存目标人脸的表情,如闭上的眼睛(图5行2)。

【忽略源人脸的形状(图5行1-4,图6行1-2)。光照(图5行3,图6行3-5)。图像分辨率(图5行2和4)】
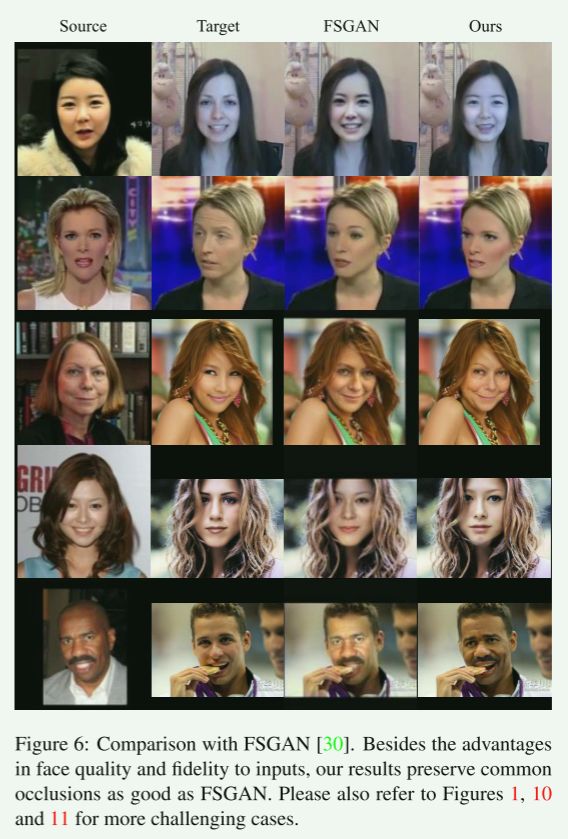
我们的方法很好地解决了所有这些问题。
通过很好地保持源(而不是目标)的人脸形状,并忠实地尊重目标(而不是源)的照明和图像分辨率,我们实现了更高的保真度。
我们的方法也有能力超越FSGAN[30]处理遮挡。
【四个关键点源脸的形状,目标的照明和图像分辨率,遮挡处理。】
4.1.2 Quantitative Comparison:
实验建立在FaceForensics++[36]数据集上。
对于FaceSwap[2]和DeepFakes[1],测试集由每种方法的10K张人脸图像组成,从每个视频剪辑中均匀采样10帧。
对于IPGAN[5]、Nirkin et al.[31]和我们的方法,使用与其他方法相同的源和目标图像对生成10K张人脸图像。
然后我们对ID检索、姿态误差和表达误差这三个指标进行定量比较。
【ID retrieval, pose error and expression error.】
我们使用不同的人脸识别模型[41]提取身份向量,并采用余弦相似度来度量身份距离。
对于测试集中交换的每个人脸,我们在所有FaceForensics++原始视频帧中搜索最近的人脸,并检查它是否属于正确的源视频。
所有这些检索的平均精度报告为表1中的ID检索,用于测量身份保存能力。
我们的方法获得了较高的身份检索分数,并且有较大的差距。
【ID retrieval用以衡量身份保存的能力。】
我们使用姿态估计器[37]来估计头部姿态,使用3D人脸模型[10]来检索表情向量。
我们报告表1中交换后的人脸与其目标人脸之间的姿态和表情向量的 L − 2 \mathcal{L}-2 L−2距离作为姿态和表情误差。
该方法在表情保存方面具有优势,在姿态保存方面也是可以与其他方法相媲美的。
我们没有使用人脸地标比较作为[30],因为人脸地标涉及身份信息,而这些信息在交换后的人脸和目标人脸之间应该是不一致的。
【pose error and expression error用以衡量属性保存的能力】
4.1.3 Human Evaluation:
我们进行了三个用户研究,以评估所提模型的表现。
我们让用户选择:
i)与源人脸拥有最相似的身份;
ii)与目标图像头部姿态、面部表情和场景光照最相似的;
iii)最现实的一个。
在每个研究单元中,给出了两个真实的人脸图像、源和目标,以及由FaceSwap[2]、Nirkin et al.[31]、DeepFakes[1]和我们生成的4个重组后的人脸交换结果。
我们要求用户选择一张最符合我们描述的脸。
对于每个用户,从1K个FaceForensics++测试集中随机抽取20对面孔,不存在重复。
最后,我们从100名人类评估者那里收集答案。
每项研究中每种方法的平均选择百分比见表2。
结果表明,该模型在很大程度上优于其他三种方法。

【用户调研实验,值得关注。】
4.2. Analysis of the Framework
4.2.1 Adaptive Embedding Integration:
为了验证使用注意掩模进行自适应集成的必要性,我们将AEI-Net与两个基线模型进行了比较:
i)Add:AAD层采用了基于元素的加操作,而不是使用式5中的掩模 M k M_k Mk。该模型的输出激活 h o u t k h^k_{out} houtk直接用 h o u t k = A k + I k h^k_{out}= A^k + I^k houtk=Ak+Ik计算;
ii) Cat:采用元素级联,不使用掩码 M k M_k Mk,输出激活为 h o u t k = C o n c a t [ A k , I k ] h^k_{out}= Concat[A^k, I^k] houtk=Concat[Ak,Ik]。图7比较了两个基线模型以及AEI-Net的结果。由于没有软蒙板进行自适应融合嵌入,由基线模型生成的人脸相对模糊,并含有大量的重影伪影。
【消融实验,没有 M k M_k Mk结果变得模糊并且含有大量的重影伪影】

我们也将图8中AAD层在不同层次上的蒙版 M k M_k Mk进行了可视化,在图8中,越亮的像素表示方程5中身份嵌入的权重越大。
结果表明,身份嵌入在底层效果更好。
它的有效区域在中层变得稀疏,在中层中,它只在一些与面部身份密切相关的关键区域激活,如眼睛、嘴巴和脸部轮廓的位置。

【 M k M_k Mk是通过 h ˉ k \bar{h}^k hˉk进行卷积和sigmoid操作得到的在0-1之间,越亮代表接近1】
4.2.2 Multi-level Attributes:
为了验证是否有必要提取多层属性,我们将其与另一个基线模型Compressed进行比较,该模型与AEI-Net具有相同的网络结构,但只利用了前三个层次的嵌入 z a t t k , k = 1 , 2 , 3 z^k_{att}, k = 1,2,3 zattk,k=1,2,3。
它最后嵌入的 z a t t 3 z^3_{att} zatt3被输入所有更高级别的AAD集成。
其结果也在图7中进行了比较。
与IPGAN[5]类似,其结果也存在模糊等问题,因为目标图像中的很多属性信息都丢失了。
【多层目标属性编码的消融实验,有模糊问题,因为目标图像中的很多属性信息都丢失了】
为了理解在属性嵌入中编码的内容,我们将所有层次的嵌入 z a t t k z^k_{att} zattk(双线性上采样到256 × 256并向量化)串联起来作为统一的属性表示。
我们进行PCA(主成分分析),将向量维数降为512。
然后,我们对这些向量的 L − 2 \mathcal{L}-2 L−2距离最近的训练集中的人脸进行测试querying。
如图9所示的三个结果验证了我们的意图,属性嵌入可以很好地反映面部属性,如头部姿势、头发颜色、表情,甚至面部是否存在太阳镜。
因此,这也解释了为什么我们的AEI-Net有时可以在没有第二阶段的情况下,保持像太阳眼镜一样的遮挡在目标脸上(图10(8))。
【目标属性的编码内容】


4.2.3 Second Stage Refinement
图10中显示了多个示例,其中包含一阶段的结果 Y ^ s , t \hat{Y}_{s,t} Y^s,t和二阶段的结果 Y s , t Y_{s,t} Ys,t。
这表明AEI-Net能够产生高保真的人脸交换结果,但有时它的输出 Y ^ s , t \hat{Y}_{s,t} Y^s,t没有保留目标中的遮挡。
幸运的是,处于第二阶段的HEAR-Net能够恢复它们。
【实验pipeline】
HEAR-Net可以处理各种各样的遮挡,如奖牌(1)、手(2)、头发(3)、脸部彩画(4)、面具(5)、半透明物体(6)、眼镜(7)、头巾(8)和浮动文本(9)。
此外,它还能够纠正在 Y ^ s , t \hat{Y}_{s,t} Y^s,t中偶尔发生的颜色偏移。
此外,当目标人脸具有非常大的姿态(6)时,HEAR-Net可以帮助修正人脸形状。
【看图10】
4.3. More Results on Wild Faces
最后,通过对从互联网上下载的人脸图像进行测试,验证了FaceShifter的强大功能。
如图11所示,我们的方法可以处理各种条件下的人脸图像,包括大姿态、不寻常的照明和非常具有挑战性的遮挡。
【泛化性能很好。】

5. Conclusions
介绍:在本文中,我们提出了一个名为FaceShifter的新框架,用于高保真和遮挡感知的人脸交换。
第一阶段的AEI-Net自适应地整合身份和属性,以合成高保真结果。
第二阶段的HEAR-Net以自监督的方式恢复异常区域,无需任何人工标注。实验:提出的框架在生成真实的人脸图像时表现出卓越的性能,给出任何人脸对,而不需要对受试者进行特定的训练。
大量实验表明,该框架的性能明显优于以往的人脸交换方法。
A. Network Structures
AEI-Net和HEAR-Net的详细结构如图12所示。
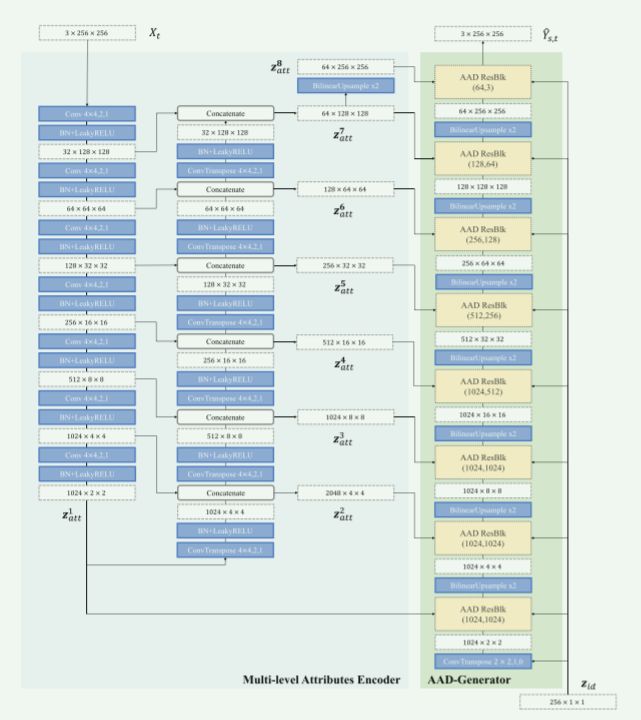
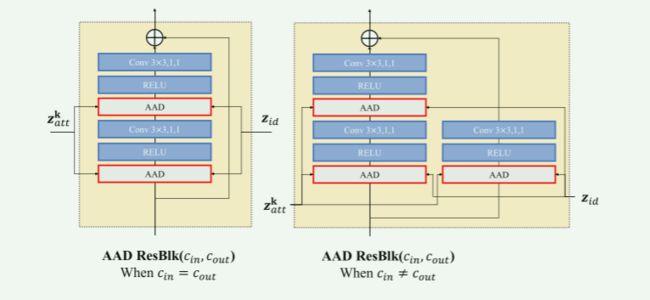
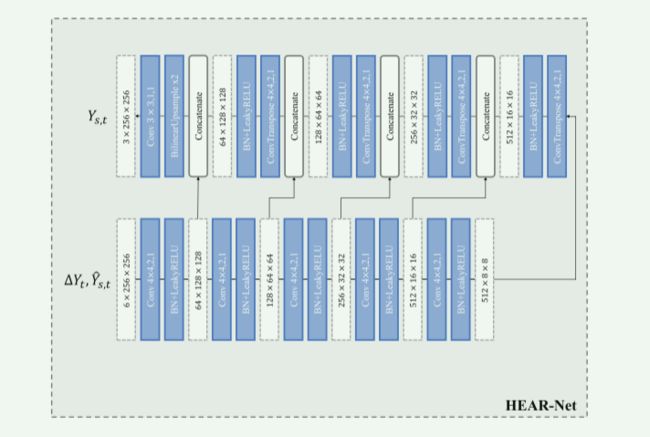
图12:网络结构。
Conv k,s,p表示核大小为k, stride s, padding p的卷积层。
ConvTranspose k,s,p表示核大小为k, stride s, padding p的转置卷积层。
所有LeakyReLUs都有α = 0.1。
AAD ResBlk( c i n c_{in} cin, c o u t c_{out} cout)表示一个AAD ResBlk,具有cin和cout的输入和输出通道。
B. Training Strategies
在AEI-Net中,我们使用与[33]相同的多尺度鉴别器,将对抗损失实现为铰链hinge损失。
训练样本中含有 X t ! = X s X_t != X_s Xt!=Xs在训练AEI-Net时为80%,在训练HEAR-Net时为50%。
用β1 = 0, β2 = 0.999, lr = 0.0004的ADAM[21]对所有的网络进行训练。
AEI-Net用500K步进行训练,而HEAR-Net用50K步进行训练,两者都使用4个P40 GPU,每个GPU有8张图像。
我们使用同步的均值和方差计算,也就是说,这些统计数据是从所有的GPUs中收集的。
除了从EgoHands[3]和GTEA Hand2K中采样手图像[15,25,24]外,我们还使用公共代码1来渲染ShapeNet[9]对象在遮挡数据增强中。
一些合成的遮挡如图13所示。
【训练细节】

个人思考与总结
- 首先文章是提出了一个两阶段的方法来实现换脸,第一阶段的生成就是常规的图像重建,分别利用源脸身份信息和目标脸属性信息,然后利用GAN来训练。
- 其次第二阶段是一个精心设计的网络,也就是一个U-net来处理遮挡,问题是这可能会带回一些目标的身份信息,使它们交换后的结果与目标相似。
- 待续…
https://github.com/panmari/stanford-shapenet-renderer ↩︎