Mastering Diverse Domains through World Models
domain 和task的定义
domain(域)

task(任务)


参考:
论文摘要
通用智能需要解决多个领域的任务。人们认为强化学习算法具有这种潜力,但它一直受到为新任务调整所需资源和知识的阻碍。在 DeepMind 的一项新研究中,研究人员提出了DreamerV3,一种基于世界模型的通用可扩展的算法 ,它在具有固定超参数的广泛领域中优于以前的方法。这些领域包括连续和离散动作、视觉和低维输入、2D 和 3D 世界、不同的数据量、奖励频率和奖励等级。研究人员观察到DreamV3还具有良好的扩展特性,能够通过更大的模型参数会带来更好的效果。同时,DreamerV3是第一个没有人类数据或主动教育的情况下从零开始能够在MineCraft中收集钻石的算法,这是人工智能领域的一个长期挑战。研究人员表示,这样的通用算法可以使强化学习的到广泛应用,并有望扩展到硬决策问题。
下图 1 中的结果发现,DreamerV3 在所有领域都实现了强大的性能,并在其中 4 个领域的表现优于所有以前的算法,同时在所有基准测试中使用了固定超参数。
突出贡献:
1. 在使用固定的超参数的情况下学习掌握不同的领域,避免了复杂的调参工作,使强化学习易于适用
2.可扩展性强,模型大小的增加可以提高性能和数据效率
3.在多个领域都优于其他现有的专业算法
4.DreamerV3是第一个没有人类数据或主动教育的情况下从零开始能够在MineCraft中收集钻石的算法,解决了人工智能领域的一个长期挑战。
研究背景
钻石是《我的世界》游戏中最受欢迎的物品之一,它是游戏中最稀有的物品之一,可被用来制作游戏中绝大多数最强的工具、武器以及盔甲。因为只有在最深的岩石层中才能找到钻石,所以产量很低。
对于熟悉游戏的玩家来说,从0开始在《我的世界》(Minecraft)中挖出一块钻石,可能只需要几分钟的时间,但对于AI来说,15分钟内可能都挖不出一块钻石。
为了发掘AI的潜力,2019年,CMU、微软、DeepMind和OpenAI联手在顶会NeurIPS上举办了一个名叫MineRL的竞赛,要求参赛队伍在4天时间内,训练出一个能在15分钟内挖出钻石的AI“矿工”。(neural information processing systems (NeurIPS) )
AI智能体 为何难以挖出矿石
合成钻石步骤复杂:既不能使用一种工具,也不能一挖到底
一般而言从0开始到挖出钻石,分为以下几个步骤: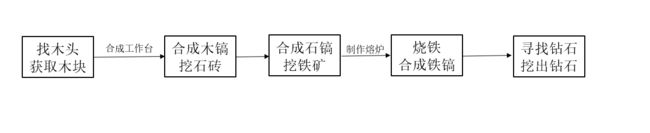
这一整个流程,对于人而言是比较好理解的,但对于AI而言,需要面临大量的决策,面临的环境、任务都具有无限种可能。在提交参赛的660份作品中,没有一份能胜任这项任务,大部分AI能够完成一些基础、碎片式的工作,但它无法将这些零碎的工作完整地串联起来。
DreamerV3 的出现改变了这一现状,它收集的第一颗钻石,发生在 30M 环境步数 / 17 天游戏时间之内。DreamerV3 能在没有任何人工数据辅助的情况下收集钻石,或许效率还有很大改进空间,但 AI 智能体现在可以从头开始学习收集钻石这一事实本身,是一个重要的里程碑。
相关工作(related work)
1.agent是什么?
中国科学界已经趋向于将其翻译为:智能体
Agent在某种程度上属于人工智能研究范畴,因此要想给Agent下一个确切的定义就如同给人工智能下一个确切的定义一样困难。在分布式人工智能和分布式计算领域争论了很多年,也没有一个统一的认识。
研究人员从不同的角度给出了Agent的定义,常见的主要有以下几种:
1) FIPA(Foundation for Intelligent Physical Agent),一个致力于Agent技术标准化的组织给Agent下的定义是:“Agent是驻留于环境中的实体,它可以解释从环境中获得的反映环境中所发生事件的数据,并执行对环境产生影响的行动。” 在这个定义中,Agent被看作是一种在环境中“生存”的实体,它既可以是硬件(如机器人),也可以是软件。
2) 著名Agent理论研究学者Wooldridge博士等在讨论Agent时,则提出“弱定义”和“强定义”二种定义方法:弱定义Agent是指具有自主性、社会性、反应性和能动性等基本特性的Agent;强定义Agent是指不仅具有弱定义中的基本特性,而且具有移动性、通信能力、理性或其它特性的Agent;
3) Franklin和Graesser则把Agent描述为“Agent是一个处于环境之中并且作为这个环境一部分的系统,它随时可以感测环境并且执行相应的动作,同时逐渐建立自己的活动规划以应付未来可能感测到的环境变化”;
4) 著名人工智能学者、美国斯坦福大学的Hayes-Roth认为“智能Agent能够持续执行三项功能:感知环境中的动态条件;执行动作影响环境条件;进行推理以解释感知信息、求解问题、产生推断和决定动作”;
5) Agent研究的先行者之一,美国的Macs则认为“自治或自主Agent是指那些宿主于复杂动态环境中,自治地感知环境信息,自主采取行动,并实现一系列预先设定的目标或任务的计算系统”。
参考:
强化学习流派
在许多强化学习问题中,智能体既需要一个对过去和现在状态的良好描述,还需要一个优秀的模型来预测未来的状态。作为真实世界的一个表征,世界模型采用无监督的方式进行训练,能取得较好的策略。
强化学习根据是否为环境建模分为两大类,model based和model free,这算是一个比较基本的划分。
MFRL又可以接着依据后续训练的侧重点分为value-based以及policy-based。当然,MBRL也可以按此继续划分。
相对来说,MFRL更直观,也更通用一点,MBRL常常是针对某一个问题的设定。毕竟,一种很显然的构造MBRL算法的方式就是在MFRL基础上,加上对该特定问题的环境的建模。比如说,在simulation中,可以采用神经网络来近似去模拟前向动力学(难点是Contact的求解)。而对于在真实环境中的机器人,就是可以用神经网络去模拟真是情况下的观测结果。这两种的对环境的建模是不一样的。

agent工作流程
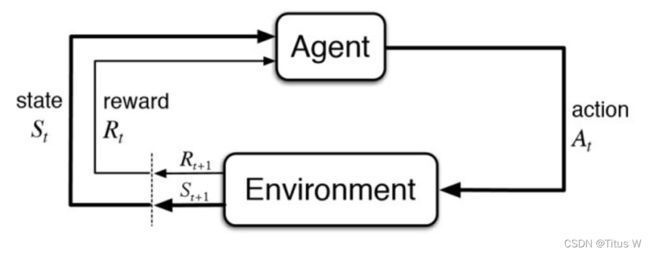
首先Agent会先观察周围的环境,环境会在每一个时刻返回给Agent一个state状态,Agent会根据Policy来做出相应的动作action来影响环境。随着动作的输入,环境会反馈相应的reward奖励和下一步的state,于是形成这样一个循环(State Action State Reward),目的就是优化policy,使Agent在环境中获得尽可能多的奖励。
上面所述就是无模型的强化学习,这种经典的强化学习发现,在不断的训练和学习过程中,Agent需要不断通过action和reward与环境进行交互,但是在实际部署中,往往不一定会有这样的条件,在真实场景中的实用性也因此受到了限制。
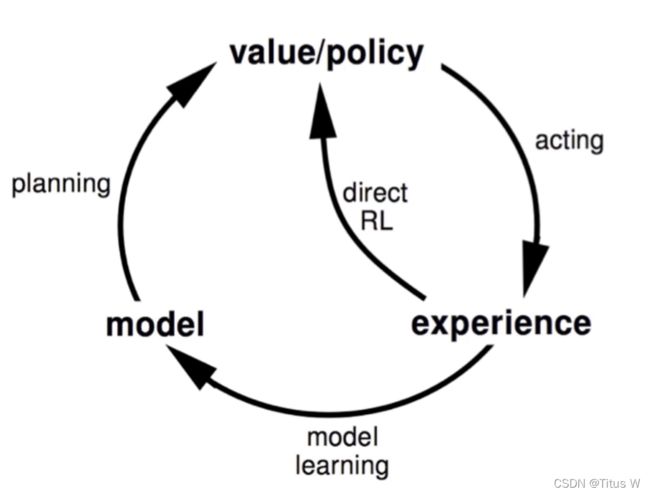
基于模型的算法流程如上图所示,在训练Policy的同时,设计一个world model来辅助形成(State Action State Reward)元组。例如,先利用上图Model free的流程来训练world model,然后再用训练好的world model 加速对policy的优化。
与MFRL方法相比,MFRL中agent只能使用从与真实环境的交互中采样的数据(称为经验数据),MBRL使agent能够充分利用学习模型中的经验数据。
有了环境模型,agent就可以有想象力(Imagination)。它可以与模型进行交互,以便于利用模拟数据来生成更多的采样数据。理想情况下,如果模型足够准确,则可以在模型中学习良好的策略,在model中学习的过程就叫做dreamer。
https://blog.csdn.net/BAAIBeijing/article/details/107502641
https://blog.csdn.net/weixin_46235765/article/details/121739673
2. 世界模型(World Model)
参考:
Introduction
世界模型(World Model)首次由 Jürgen Schmidhuber 与 David Ha 在 neural information processing systems (NeurIPS) 2018中提出(NeurIPS是人工智能领顶级会议,与ICML并称为人工智能领域难度最大,水平最高,影响力最强的会议!),主要出发点是打造一个通用强化学习环境的生成神经网络模型,为强化学习技术的落地提供完美的模拟环境。这篇工作入选了当年 NeurIPS 的 oral paper。World Models
世界模型可以以无监督的方式快速训练,以学习环境的压缩空间和时间表示。通过使用世界模型中提取的特征作为智能体的输入,可以训练出一个非常紧凑和简单的策略以解决指定的任务。甚至可以使智能体完全沉浸在由它的世界模型生成的梦境中进行训练,并且将策略迁移回现实环境中。
世界模型的灵感来源于心理学上的“心理世界模型”(mental model of the world)。
在人对世界的理解过程中,我们往往是以有限的感官所能感知到的事物为基础,形成一个心理世界模型。我们所做的决定和行动都是基于这个模型。
为了处理流经我们日常生活的大量信息,大脑要学会抽象表示信息的空间和时间特性。我们能够观察一个场景并记住其中的抽象描述。证据还表明,我们在任何时刻所感知的,都是由我们的大脑根据我们的内部心理模型对未来的预测所决定的。
心理模型不仅仅是预测未来,而且会根据我们当前的运动行为来预测未来的感官数据。我们能够在这种预测模型上采取行动,并在我们面临危险时表现出快速的行为,而不需要有意识地规划一个行动路线。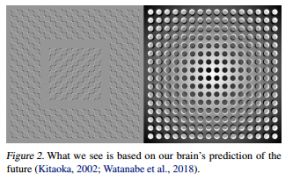
以棒球为例。击球手只有毫秒级的时间来决定如何挥动球棒,时间要短于它大脑接受到相关视觉信号的时间。我们之所以有这种击打速度为100mph棒球的能力,就是因为我们可以本能地预测球将在何时到达哪里。对于专业选手来说,这一切都发生在潜意识。按照内在模型的预测肌肉可以反射性地在恰当时间和位置挥动球棒(Gerrit et al., 2013)。他们可以迅速地根据自己对未来的预测采取行动,而不需要有意识地推演未来可能的情景来制定运动计划(Hirshon, 2013)。
MBRL和MFRL区别在于agent是否对环境建模。在model based方法中,模型的选用面临一个矛盾:
一方面,为了更有效地学习环境,需要更强大、表达力更高的模型。另一方面,强化学习难以学习大型模型数以百万计的权重(奖励分配的搜索空间太大)。
PS:credit assignment问题是说,在许多RL任务中,reward都是很稀疏的,往往在一串序列结束后才给出,而在这之前agent已经采取了很多action,credit assignment 问题就是要解决究竟是哪一个action对最后的reward的影响最大,对final reward,哪些action起了有益的作用,哪些action起了负面作用。credit assignment问题使得传统的RL算法很难训练数百万个参数的大模型,因此在实际应用中,由于小网络在训练过程中更快,反而有比较好的策略。(通俗来讲就是,由于sparse reward,大型网络的参数很不好训练,所以在性能上输给了小型网络,但作者认为采用小型网络只是暂时的成功,未来要用的还是大型网络的
既然模型的规模主要受奖励分配的搜索空间限制,而更大、更复杂的模型主要优势在于学习环境,因此,可不可以将模型拆开呢?让一个较大的复杂模型专门负责学习环境,不涉及奖励分配问题,同时让一个较小的模型执行任务,这样较大的复杂模型就不会影响奖励分配的搜索空间,而较小模型可以通过“询问”较大模型,获取对环境的理解,从而更好地学习。
模型架构
World Model基于上述思路,组合使用两个模型绕开了上面提到的矛盾。
使用大型的世界模型,建模环境
使用小型的控制者模型,学习执行任务
World Model
从上述结构中可以看到,世界模型包括两部分,Vision Model(V),用于编码视觉信息,和Memory RNN(M),基于历史信息预测未来的编码。
视觉组件(V)作用是学会输入帧的抽象压缩表示,使用VAE(变分自动编码器)实现,将每幅图像都转成一个很小的隐变量向量Z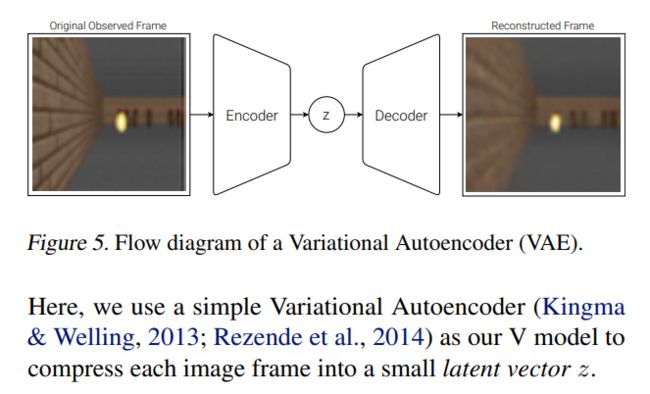

记忆组件(M)基于循环神经网络(LSTM)实现,预测模型V的隐变量z未来的输出,也就是预测下一帧图像的可能分布。由于现实环境的诸多复杂随机性,我们训练RNN的输出为一个概率密度函数p(z),而不是z的确定预测。
p(z)逼近于一个混合高斯分布,RNN被训练成在给定当前和过去信息的情况下,输出下一帧隐变量
Z t + 1 Z_{t+1} Zt+1的概率分布。特别地,RNN建模了 P ( Z t + 1 , a t , Z t , h t ) P(Z_{t+1},a_t,Z_t,h_t) P(Zt+1,at,Zt,ht)其中 a t a_t at为时刻t采取的动作, h t h_t ht为时刻上RNN的隐藏状态。采样时,我们调整一个温度参数 τ \tau τ来控制模型不确定性,诸如(Ha & Eck, 2017)中做的,我们发现调整 τ \tau τ对于后面训练控制器非常有用。这个方法可以看作是结合了RNN(MDN-RNN)(Graves, 2013; Ha, 2017a)的混合密度网络(Mixture Density Network, Bishop, 1994),被应用在序列生成问题。
从上图可以看到,记忆组件的输出层用了MDN(混合密度网络),这样可以输出潜向量的概率分布——混合高斯分布,输出是混合高斯分布,这使得我们可以通过调整温度参数来增加随机性。这一方面增加了控制者通过破解“作弊”的难度,另一方面,适当增加温度参数,可以增加挑战性。而在高温(高难度)梦境下训练的agent,迁移到现实环境时,通常会有更好的表现。这其实和一般模拟考试难度会比正式考试高是一个道理。当然,温度参数太高,随机性过高,难度太大,agent也无法成功学习。
Controller Model
控制者模型C的目标,就是把前面视觉组件V和记忆组件M的输出一起作为输入,并输出这个时刻智能体agent应该做出的动作(action)。实验中,我们故意让模型C尽量的小,并和V、M分离开训练,这样可以把智能体的复杂性都放到世界模型中(模型V和模型M)。
模型C 就是一个简单的一层线性模型,将 Z t Z_t Zt和 h t h_t ht映射成每个时间步的动作:
a t = W c [ z t h t ] + b c ( 1 ) a_t=W_c[z_th_t]+b_c(1) at=Wc[ztht]+bc(1)
在该线性模型中, W c W_c Wc和 b c b_c bc分别是权重矩阵和偏移向量,将串联到一起的 [ z t h t ] [z_th_t] [ztht]映射成动作向量 a t a_t at。
组件之间的交互
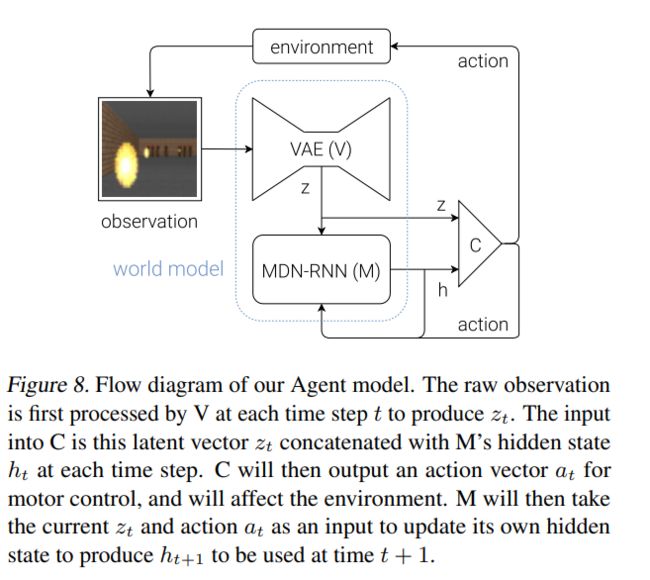
视觉组件和记忆组件用的都是标准的模型(VAE、LSTM、MDN),可以在GPU上训练。
由于控制者模型是非常简单的线性模型,所以各种训练策略都可以尽情使用,包括演化算法。具体使用的是CMA-ES(协方差矩阵自适应演化策略)。CMA-ES在这一规模的线性模型上的表现比较好。
Learning Inside of a Dream
所谓世界想象能力,就是模型在学习时,自身对环境假想一个模拟的环境,甚至可以在没有环境训练的情况下,自己想象一个环境去训练。其实就是我们人类镜像神经元的功能。
由于控制者模型对环境的感知完全依赖世界模型,它并不能区分真实和虚幻。因此,它可以在世界模型为它编造的“梦境”中学习。如果世界模型虚构的“梦境”足够好,那么控制者模型在梦境中所学能够在以后迁移到真实场景中。
那么“梦境”是如何实现的呢?首先,刚才提到的记忆组件M中的RNN是生成序列的能手,所以根据之前游戏图像再“想象”一些图像帧应该不成问题(RNN生成一些隐变量z,再根据隐变量z,由视觉组件VAE的decode生成的图像帧即可)。所以对于“强视觉”的游戏,把RNN的记忆能力用在视觉预测上似乎是个好主意 。
2018年,当 Jürgen Schmidhuber 与 David Ha 提出世界模型后,他们将世界模型用于解决一个赛车竞速的强化学习任务。带有预测能力的世界模型可以有效地提取空域与时域特征,再将这些特征应用于控制模型,然后训练一个最小的控制模型来完成连续域控制任务,即赛车。
PlaNet介绍
论文:http://proceedings.mlr.press/v97/hafner19a/hafner19a.pdf
PlaNet全称为Learning Latent Dynamics for Planning from Pixels(基于像素规划的潜在动力学学习)。解决的问题是有contact dynamics的continuous control问题。
本文建模了如下几个模块,但对于policy并没有显式建模,而是采用planning算法来选择动作。
本文的Pla指的是Planning,特指对环境Dynamics的Planning。核心思想是通过对Simulator的Dynamics Model用神经网络近似,来在DeepMind control suite上进行验证(里面也是有Contact Dynamics的)。
RSSM(Recurrent state-space model)
RSSM是本文的核心模块,建模了除policy外的所有预测过程,在后面的Dreamer中都有用到。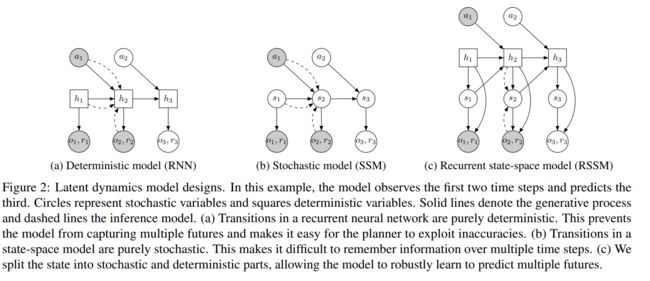
在这个例子中,模型观察前两个时间步骤并预测第三个时间步骤。圆表示随机变量和平方确定性变量。实线表示生成过程,虚线表示推理模型。(a)递归神经网络的转换纯粹是确定性的。这样可以防止模型捕获多个未来状态,并使得规划者很容易利用不准确性。(b)状态空间模型中的转变是纯粹随机的。这使得在多个时间步骤中很难记住信息。©我们将状态分为随机和确定性两部分,使模型能够稳健地学习预测多个未来。
一种是简单的确定性模型的RNN结构,每个timestep输入action,输出observation和reward,hidden state建模state,因此transition模型是完全确定性的,无法建模不同的特征转移。第二种是一种随机状态转移模型,即两个连续状态的转移是随机的,在建模的时候应该是每个timestep的预测由同一个mlp完成,但是无法建模多步的信息。
最后作者设计了RSSM,把随机部分和确定性部分分别建模,每个timestep的hidden state去infer 推理一个随机的state,并且有确定性的转移保证多步信息被建模。
下面是作者提出的RSSM模型的公式:
确定性状态模型
随机状态模型
观察模型
奖励模型
采用乘积形式的概率来定义动作序列的概率,![]()
然后利用类似于ELBO的方法,把极大似然估计函数转化成一个重采样项和KL散度,将这个作为LOSS训练,其中运用了Jessen不等式:
总结来说,RSSM框架的主要思路就是将状态分割为确定性 h t h_t ht和随机性 s t s_t st两部分,同时采取变分推断的方法进行极大似然估计。
Multi-step prediction
在这篇文章中作者提到了one-step和multi-step的状态预测推导。多步预测(Multi-step prediction),对于MBRL来说,这是一个常用的实施技巧。利用多步预测,多步预测可以避免在初期dynamics model训练不充分的时候,从 s t − 1 s_{t-1} st−1到 s t s_t st变化的模型的不准确性的累积效应。采用d步的多步预测,可以提前给出d步的states,然后就可以预测d个新的states,方便模型自己学习state的transition。代价就是需要的神经网络计算更加多。
DreamerV1
【ICLR2020】论文:Dream to Control:Learning Behaviors by Latent Imagination
Dreamer是PlaNet的延续,也是MBRL算法。
所解决的问题
无模型 (Model-free) 强化学习方法通过试错来学习预测成功动作,让 DeepMind 的 DQN 能够玩 Atari 游戏,也让 AlphaStar 可以在星际争霸 II(Starcraft II) 游戏中击败世界冠军,不过由于这种方法需要大量的环境交互,在真实场景中的实用性也因此受到了限制。
相较之下, 基于模型的 强化学习方法能额外学习环境的简化模型。这一 世界模型 让智能体能够预测潜在动作序列的结果,能够在假设场景中的新情境中训练并做出明智决策,从而减少实现目标所必需的试错次数。过去,学习精确的世界模型并利用此类模型学习成功行为的方法一直存在挑战。
作者:在与 DeepMind 的合作之下,我们推出 Dreamer,这是一种从图像中学习世界模型并使用此模型来学习长期行为的强化学习 (RL) 智能体。通过模型预测的反向传播,Dreamer 能够利用世界模型进行高效的行为学习。通过从原始图像中学习计算 _压缩模型状态 _(Compact Model States) ,智能体只需使用一块 GPU 即可从成千上万的预测序列中高效地并行学习。在给定原始图像输入的 20 个连续控制任务基准测试中,Dreamer 在性能、数据效率和计算时间三个方面均达到最高水准 (state-of-the-art)。参考:
PS: 文章提出一个叫Dreamer的算法,就是去学一个world model,然后强化学习在compact state space上进行。就相当于所有的学习过程都不是和真正的环境交互学习,而是在world model上进行,所以把这个东西叫做Dreamer,相当于梦里学习,梦里啥都有。
思考:对于复杂的强化学习任务,一个非常重要的解决方法就是把整个环境抽象到一个低维的表示中(World model),然后在这个环境学习。但如何抽象到低维表示,且抽象到低维空间后不影响最终的效果是比较困难的
Dreamer的工作原理
作者提出了一种基于梯度的,在纯隐状态空间中学习的算法。用一种新的actor-critic算法去与所学的环境模型进行交互。因为是在所学的这个环境模型中进行学习,所以能够获得多步的累计奖励,进行多步长期的学习规划。
前面介绍的PlaNet没有设计专门的policy模块来学习action,是通过planning算法来选择动作,与之不同的是,本文有专门的policy网络,用model的梯度来更新。
Dreamer的核心就是环境的采样只用来学习world model,而policy全部使用model imagine出来的数据进行更新。
Dreamer智能体工作流程
Dreamer 包括三个非常典型的基于模型的学习方法流程:(1)学习世界模型;(2)根据世界模型做出的预测中学习行为;(3)在环境中使用学习来的行为以获取新反馈。在学习行为时,Dreamer 使用估值网络 (Value Network) 将规划范畴之外的奖励也纳入考量,同时使用行动网络 (Actor Network) 来高效地计算动作。这三个流程可并行执行,并不断重复,直至智能体实现其目标: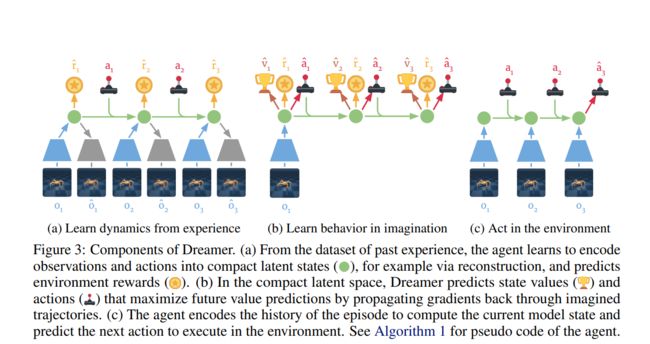
Dreamer智能体的三个流程可以总结为:(1)智能体从过去的经验中学习得到世界模型;(2)根据此模型的预测,智能体随后学习用于预测未来奖励的估值网络和用于选择行动的行动网络;(3)行动网络用于与环境进行交互。
学习世界模型
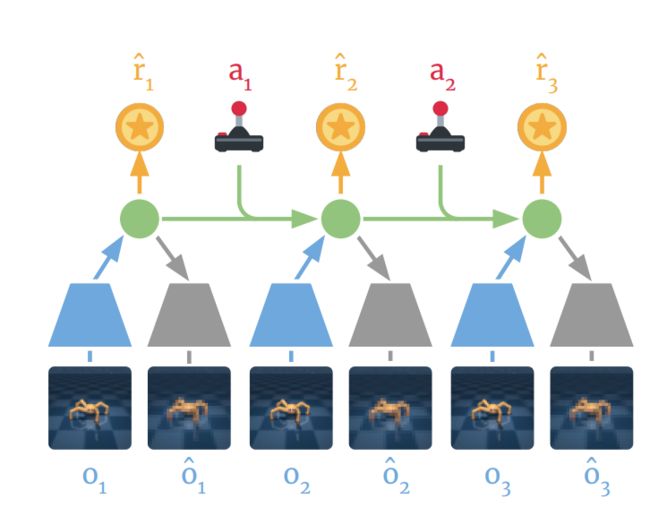
Dreamer使用PlaNet世界模型,该模型基于从输入图像计算出的一系列 压缩模型状态(Compact Model States) 来预测结果,而不是直接从一个图像来预测下一个。
具体过程如上图所示,使用过去的图像( o 1 − o 3 o_1-o_3 o1−o3)和动作( a 1 − a 2 a_1-a_2 a1−a2),计算出一系列二压缩模型状态(如图中绿色圆圈所示),并通过这些状态重构图像(![]() )然后预测奖励
)然后预测奖励 。使用 PlaNet 世界模型的一大优势在于,通过使用压缩模型状态而非图像来预测,可显著提升计算效率。这使得模型能够在单个 GPU 上即可并行预测数千个序列。该方法还有助于实现泛化,进而实现准确的长期视频预测。
。使用 PlaNet 世界模型的一大优势在于,通过使用压缩模型状态而非图像来预测,可显著提升计算效率。这使得模型能够在单个 GPU 上即可并行预测数千个序列。该方法还有助于实现泛化,进而实现准确的长期视频预测。
高效行为学习
之前开发的基于模型的智能体通常有两种选择动作的方式,一是通过多个模型预测来进行规划,二是使用世界模型代替模拟器来重用现有的无模型技术。这两种设计都需要很大的计算量,并且无法充分利用学习得到的世界模型。此外,即使是性能强大的世界模型,其精确预测未来的能力也有限,这使得以往很多基于模型的智能体都存在短视问题。
Dreamer 通过预测到的状态序列对奖励梯度进行反向传播,以此高效学习行动网络来预测成功动作,而这一点在无模型的方法中是不可能实现的。这让 Dreamer 能够了解到其动作的微小变化会如何影响未来的奖励预测,使其能够朝着奖励最大化的方向优化其行动网络。为考虑超出预测范畴的奖励,估值网络会预估每个模型状态的未来奖励总和。然后,这些奖励和价值将反向传播以优化行动网络,使其选择改进后的动作: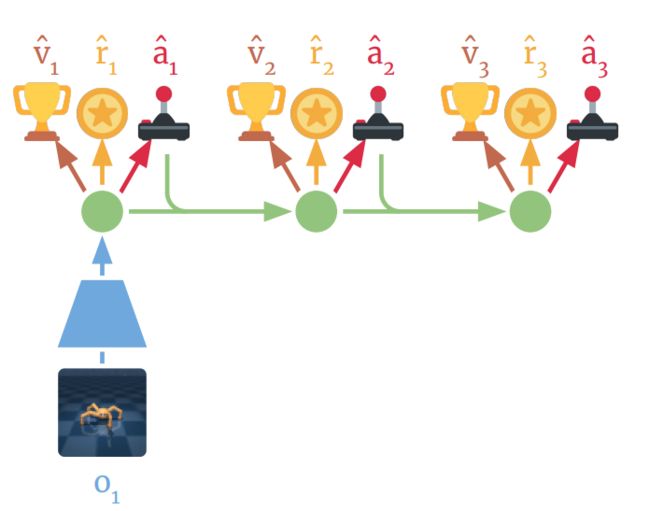
具体流程如上图所示,Dreamer首先会学习每个状态的长期值(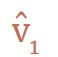 ),然后通过状态序列将这些值反向传播至行动网络,预测可产生高奖励和价值的动作(
),然后通过状态序列将这些值反向传播至行动网络,预测可产生高奖励和价值的动作(![]() )。
)。
learning latent dynamic
训练latent state 的encoding,作者提到了三种方式,
1.reward prediction
只用预测reward的方式来训练隐层表征,其中p函数表示利用了真实数据observation的函数,q函数完全使用的是dynamics model进行估计的。
- Reconstruction
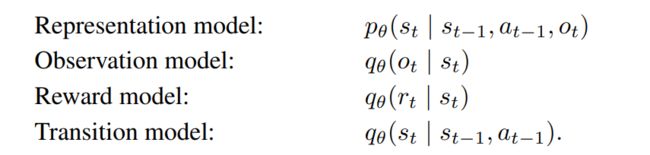
与PlaNet采用的函数类似,但引入了一个将现实observation和虚拟的变量state共同预测下一步state的函数,observation model仅仅提供学习信号。
这一方法基本上就是在PlaNet算法的基础上,用RSSM来实现transition model,用RSSM+CNN来实现representation model等等。
同时用reconstruction loss+reward预测的方式训练隐层表征: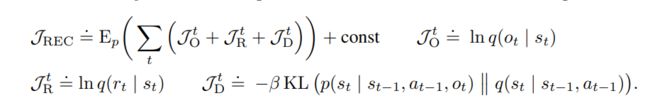
3. Contrastive estimation
用对比学习训练方式训练隐层表征,也就是不借助observation model(decoder),采用一个state model从观测预测状态,相当于是对比一下observation和state的区别,比如用noise contrastive estimation (NCE)去学。
然后在这个model的基础上去学强化。
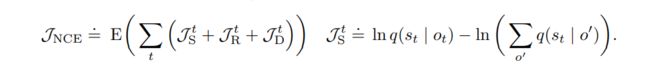
参考:【ICLR2020】Dream to Control:Learning Behaviors by Latent Imagination_小小何先生的博客-CSDN博客_dream to control
总结
1.文章的主要目的就是把整个学习过程都通过world model解决,尽可能减少与真实环境的交互。文章中也提到了很多解决的办法,从实验结果来看,dreamer在连续控制问题上,Dreamer 在性能、数据效率和计算时间三个方面均达到最高水准 (state-of-the-art)。但是在Discrete control上面,比如Atari,还是没有明显优势。(这是下一代将会解决的问题)
2本文model 可以.通过latent imagination学习长期行为。通过预测action和state值来解决,反向传播梯度
Dreamer V2
论文:Mastering Atari with Discrete World Models
https://www.cnblogs.com/initial-h/p/15623585.html
解决了什么问题?
参考:
深度 RL 的最新进展已经使得 基于模型的方法 能够从图像输入中学习精确的 世界模型2,并将其用于规划。这些世界模型可以 从更少的交互中学习,推动离线数据的泛化,实现前瞻性探索,并允许 在多个任务之间 重复使用知识。
尽管现有的世界模型(如 SimPLe)拥有诱人的优势,但其仍不够精确,无法在最具竞争力的强化学习基准上与性能最佳的无模型方法相媲美:迄今为止,在完善的 Atari 基准测试 中,我们需要使用 DQN、IQN 和 Rainbow 等无模型算法,才能达到人类的水准。
作者团队与DeepMind 和多伦多大学合作,推出了首款基于世界模型的 RL 智能体 DreamerV2,其可在 Atari 基准测试中达到人类水准。DreamerV2 是第二代 Dreamer 智能体,仅在由像素级数据训练得到的世界模型中的隐空间内学习行为。DreamerV2 完全依赖于图像中的一般信息,并且即使其表征不受未来任务奖励的影响,也能精确预测这些奖励。DreamerV2 使用单个 GPU,在相同计算和样本量的情况下,性能优于顶级无模型算法。
从上图可以看出,经过 2 亿步后,进行游戏的模型在 55 款 Atari 游戏(雅达利游戏,电脑小游戏)中的归一化得分的中位数。DreamerV2 的性能大大优于之前的世界模型。此外,在相同计算和样本量内,DreamerV2 的表现超过了顶级无模型智能体。
与DreamerV1的区别
上面介绍的Dreamer模型在连续控制上表现良好,但是在Atari上效果不佳,这篇论文就基于DreamerV1继续做Atari,做到效果比model free方法更好。与Dreamer相比,网络结构基本相同,做了如下改动:
Reinforce only 指的是训练policy的时候不用dynamics的梯度回传,根据作者所说,在continuous control下,用梯度回传的效果更好;而在atari这种离散任务上,只用reinforce的效果则更佳。
主要改动有两点:
- 世界模型使用离散表示。dreamerV2将dreamer5中states这样的的隐变量替换成了categorical variables(分类变量)借此技术,世界模型能够根据离散概念来推理世界,并能够更精确地预测未来的表征。
- using KL balancing。KL loss(using discrete latents and balancing terms within the KL loss.)。KL本身就不是对称的,作者通过调整KL的权重来实现模型的泛化。
具体的就是把之前的高斯潜变量变成分类潜变量,以及有一项KL balancing的loss
为什么使用离散的变量表达整个模型的状态

如左图,加入我们使用原来的随机变量,我们其实是默认未来的图像都是符合高斯分布的。那么未来所有图像的高斯分布呢,叠在一起可能会形成粉色的Ideal Prediction这样的,很显然这个分布根本不是高斯分布,但是我们实际的模型(蓝色的Model Prediction)用高斯分布尝试拟合粉色的模型,肯定很难达到一个满意的拟合效果。相反如果我们全部使用稀疏离散的变量来描述图像的状态,把这些分布结合在一起不管怎么样都能获得一个离散的状态空间。参考:https://blog.csdn.net/weixin_46235765/article/details/121739673
文中对为何使用分类变量也作出了一些假设:
- 普通的高斯分布难以处理多模的变化。高斯先验不一定能拟合高斯后验,但分类变量不存在这样的问题,就如上图所示。
- 分类变量的稀疏化操作可以有益于泛化。
- 分类变量相比高斯变量更不容易产生梯度爆炸的情况。
- 对于突变,分类变量比单峰的高斯分布更容易get到这个点。单峰的高斯分布更容易处理缓变的东西。
模型架构
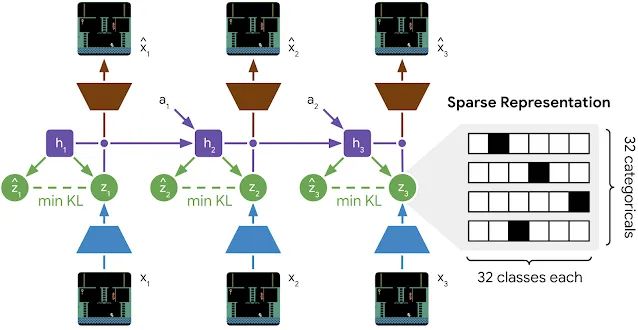
简单理解,纵向:coder和decoder,将图片编码后解码
横向:使用RSSM,大概可以理解为某种RNN架构
参考: Dreamer-v2 [Mastering Atari with Discrete World Models]
coder and decoder
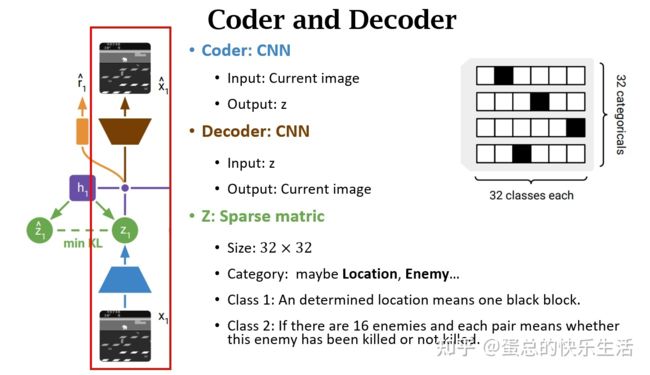
Z是一个比较稀疏的矩阵,作者使用了32个变量,每个变量又会拥有32个种类,也就是会有32*32种可能性用来描述整个状态空间。并且使用了稀疏编码,黑色地方是1其他都是0,也即one-hot-encoding这样的策略。
pS:用离散状态表达又会带来一个问题,就是当梯度传递的时候,梯度是无法翻过离散变量的,那么如何解决这样的问题呢?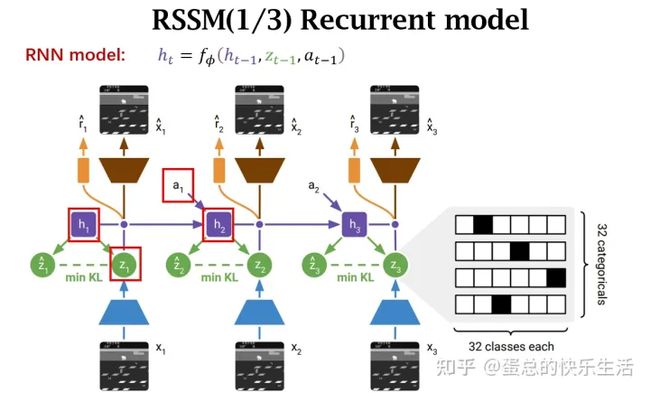
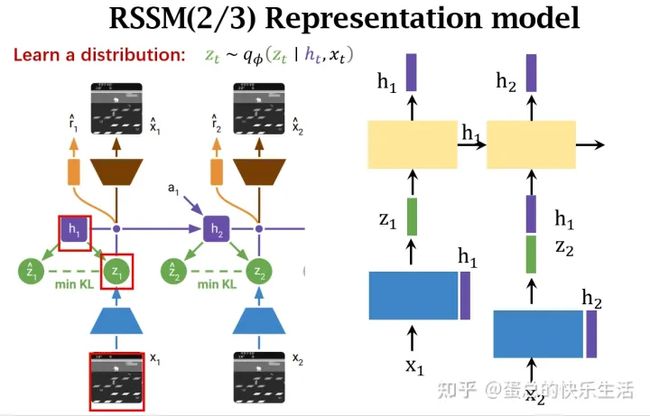
对应论文的这些公式:
开发了名为DreamerV2的强化学习智能体,可以纯粹从世界模型的紧凑型潜在空间中的预测中学习行为。世界模型使用离散表示,并且与策略分开进行训练。
据研究人员表示,DreamerV2首次通过学习在单独训练的世界模型中的行为,而在Atari基准测试55个任务上达到人类级性能。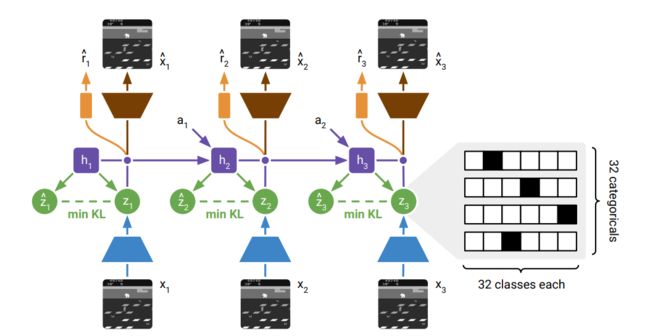
DayDreamer: World Models for Physical Robot Learning
[论文略读]DayDreamer: World Models for Physical Robot Learning
模型结构
Dreamer V3由三个神经网络算法组成,分别是世界模型(world model)、critic 和actor,世界模型预测潜在行动的未来结果,批评者判断每种情况的价值,参与者学习达到有价值的情况。
Symlog prediction
在世界模型中重建input,预测奖励和价值函数是困难的任务,因为他们的规模和定义是随着domain改变而变化的,很难找到同一套超参数来适应。(文章中提到说使用平方损失来预测大目标会导致分歧,而使用绝对值损失和Huber 损失则会导致学习停滞)因此,为了解决这一困境,本文在decoder,reward predictor和critic中采用了符号对数预测(symlog predictions)。
从图中可以看出,如果使用log作为转换,就无法预测具有负值的目标,因此,文章提出了symlog函数作为转换,symlog函数压缩了数值较大的正值和负值的大小,且关于原点对称,同时保留了输入符号,这样就可以在需要的时候迅速将网络预测移至较大的值。同时可以发现,symlog在原点周围近似于线性的,变换前和变换后趋于相同(文章里说的是具有同一性),因此它不会影响已经足够小的目标学习。
transformation 和inverse 用到的函数分别命名为symlog 和symexp![]()
接下来就可以控制网络的输入和transformation之后的label接近,需要使用的时候再把真实值inverse出来即可: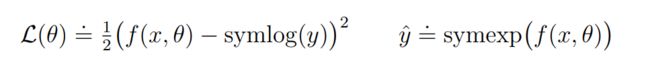
DreamerV3 在decoder,reward predictor和critic中采用了符号对数预测(symlog predictions),它还使用symlog函数对编码器的输入进行了压缩。虽然这一方法比较简单,但很稳健,可以保证模型在不同的环境中快速学习。同时,在symlog prediction的帮助下,可以无需针对特定环境截断大的奖励或通过奖励归一化引入非平稳性等一系列特定的trick了。
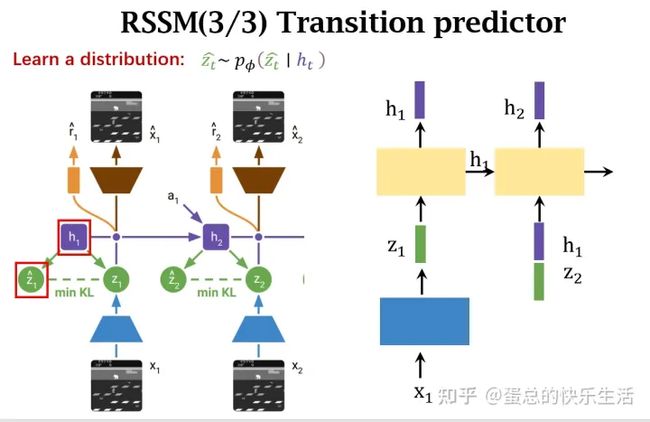
1. 世界模型 (world model)
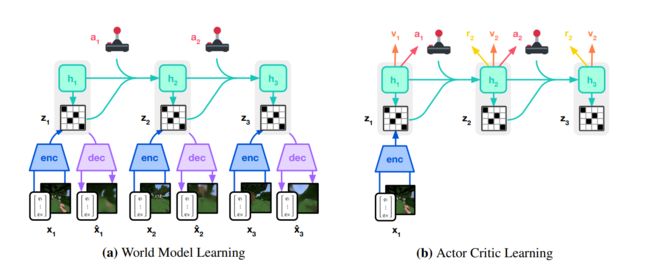
左图是world model学习的过程,与Dreamer V2的结构类似,通过RSSM结构来一边在真实环境sample(采样)的同时,一边完成model learning的过程。
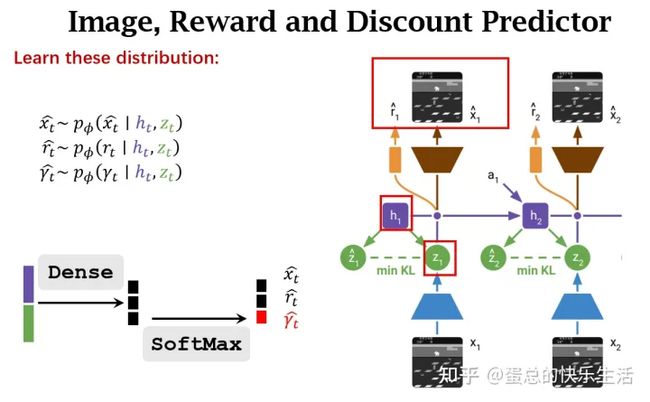
整体的World model 和Dreamer V2 基本一致,都是先将input x t x_t xt编码到discrete representation 隐变量 z t z_t zt,然后基于RSSM结构来预测dynamic,具有循环状态 h t h_t ht的序列模型在给定过去动作 a t − 1 a_{t−1} at−1的情况下预测这些表示的序列。 h t h_t ht 和 z t z_t zt 的串联形成模型状态,从中预测奖励 r t r_t rt 和 episode 连续标志 c t c_t ct ∈{0,1} 并重建输入以确保信息表示。整体的world model 组成结构如下:
world model的参数 ϕ \phi ϕ由end-to-end函数优化,损失函数包括 the prediction loss L p r e d L_{pred} Lpred, the dynamics loss L d y n L_{dyn} Ldyn, and the representation loss L r e p L_{rep} Lrep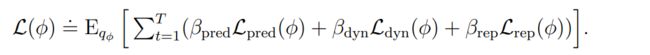
同时,为了确保能够得到缩放良好的KL散度,而不是在训练初期就达到高点,DreamerV3还使用了1% uniform和99% 神经网络输出融合的output。
2.Actor Critic Learning
与前两代Dreamer算法相同,dreamerV3也采用了 Actor-Critic结构,Actor Critic神经网络纯粹是从世界模型预测的抽象序列学习行为。在环境交互期间, 通过从 actor 网络中采样来选择动作,无需进行前瞻性规划。
actor and critic 网络基于模型状态 s t = { h t , z t } s_t=\{h_t,z_t\} st={ht,zt}运行,由此可从world model中学习到的Markovian representation中获益。actor的目标是在每个模型状态的折扣因子 γ = 0.997 的情况下最大化预期回报 R t ≐ ∑ τ = 0 ∞ γ τ r t + τ R_t \doteq \sum_{\tau=0}^{\infty} \gamma^\tau r_{t+\tau} Rt≐∑τ=0∞γτrt+τ 。为了考虑超出预测范围T=16的奖励,critic学习预测当前actor行为下每个状态的回报: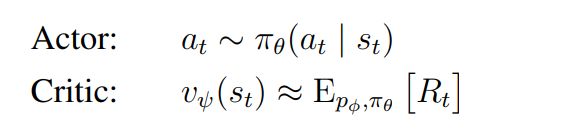
从重放输入的表示开始, dynamics predictor and actor 产生一系列预期的 model states s1:T , actions a1:T , rewards r1:T , and continuation flags c1:T 。为了估计超出预测范围的奖励和回报,使用到 deepmind自创的 λ-returns 这样一种trick,它整合了预期奖励和价值。
在critic 损失函数的选择上,没有选择 via squared error or symlog predictions (平方误差或symlog预测)对λ-returns 进行回归,因为critic预测的是一个潜在的广泛的回报分布的期望值,用上面这些方法可能会减慢学习速度。所以DreamerV3选择了一种twohot encoder的离散回归方法,将经过symlog函数转化后的λ-returns 离散化为255个等间距的bucket bi 。Critic在这些bukets上的输出变为softmax分布 p ψ ( b i ∣ s t ) p_\psi\left(b_i \mid s_t\right) pψ(bi∣st)。 Importantly, the critic can predict any continuous value in the interval because its expected bucket value can fall between the buckets: ![]()
在连续值情况下,twohot encoder会以 k 和 k+1 的buket为界,中间最接近编码的连续值为1,其他值为0。最后critic的损失函数记做: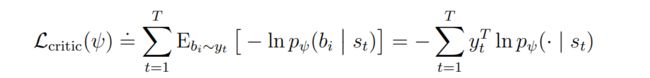
作者发现,对critic的离散回归可以加速学习,特别是在奖励稀少的情况下,这可能是因为奖励和回报的双峰分布。对于world model的reward prediction使用同样的离散回归方法。
为了稳定回报的规模,需要使用统计学方法将其归一化,这对于dense reward环境中的任务,比较容易实现,将回报除以标准差即可,但在奖励稀疏的环境中,回报的标准差一般较小,如果直接除的话,会放大 near-zero returns 中的噪音,导致接近于确定的策略,无法进行探索。
为了能够在dense reward和sparse reward(奖励密集和奖励稀疏)环境中都能够取得较好的效果,作者提出,在不扩大小收益的情况下,缩小大收益的规模。在actor更新过程中,DreamerV3通过将回报除以规模 S 来实现这一想法,更新过程如下: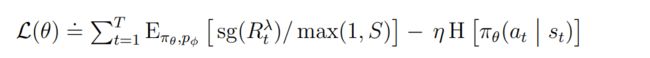
实验
在实验中,作者进行了包括Vector based DMC,Pixel based DMC,Atari 100k/200M,Bsuite,Crafter,DMLab,MineCraft在内的多个domain的150多个task实验,以评估 DreamerV3 在固定超参数下跨不同领域的通用性和可扩展性,并与已有文献中 SOTA 方法进行比较,在不修改超参数的情况下,均取得了惊人的性能,详细的实验结果及曲线在附录中。此外还将 DreamerV3 应用于具有挑战性的视频游戏《我的世界》。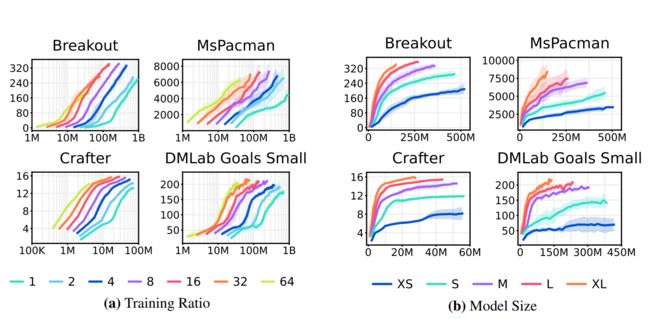
上图展示了随着训练频率和模型参数量的提升,DreamerV3效果还能获得正向的提升,具体domain和模型参数量的对应关系如下: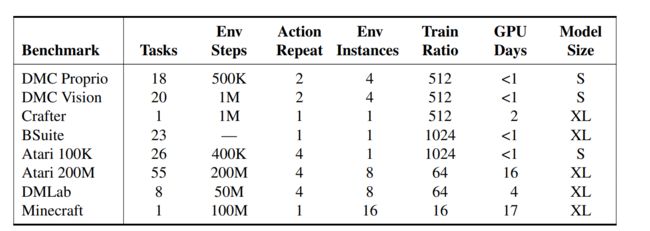
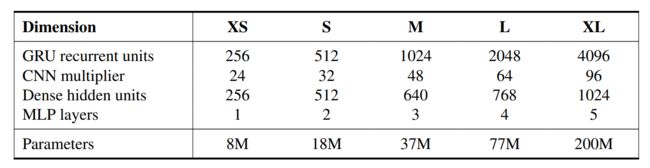
整体来说18M的参数量跑DMC等环境还是相当小的,并且所有实验均在1块V100显卡完成。
对于 DreamerV3,DeepMind 直接报告随机训练策略的性能,并避免使用确定性策略进行单独评估运行,从而简化了设置。所有的 DreamerV3 智能体均在一个 Nvidia V100 GPU 上进行训练。
https://analyticsindiamag.com/deepmind-unleashes-dreamerv3-a-multi-domain-world-model/