哈工大 大数据 数据库实验(3) 物理数据库设计--索引结构
指导书:
HIT邹老师数据库实验三资源-CSDN文库
导入数据库
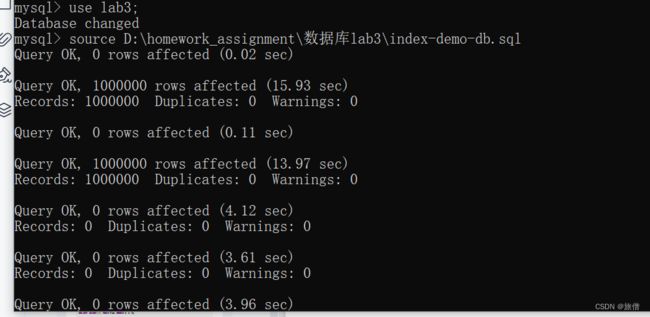
操作
两个元组的分布规律

1.查询元组的数据分布
SELECT COUNT(*) FROM Foo;
SELECT COUNT(*) FROM Foo WHERE id = 0;
SELECT COUNT(*) FROM Foo WHERE a = 0;
SELECT COUNT(*) FROM Foo WHERE b = 0;
SELECT COUNT(*) FROM Foo WHERE c = 0;
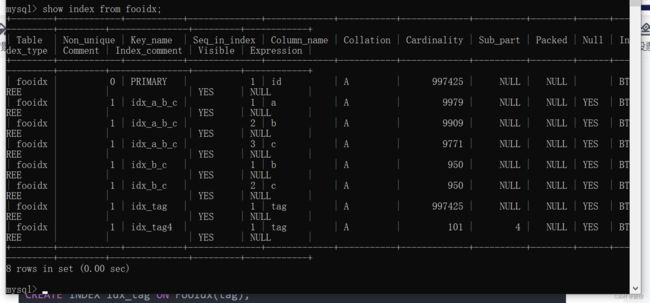
2.在FooIdx上创建如下索引:
文件里已经建完了 导入文件会报错
CREATE INDEX idx_a_b_c ON FooIdx(a, b, c);
CREATE INDEX idx_b_c ON FooIdx(b, c);
CREATE INDEX idx_tag ON FooIdx(tag);
CREATE INDEX idx_tag4 ON FooIdx(tag(4)); --该索引可以在MySQL上创建,但⽆法在PostgreSQL上创建查看索引
3.在Foo和FooIdx上分别执⾏⼀系列查询,测量每个查询的执⾏时间,⽐较同⼀个查询在哪个表上执⾏得更快。
进行两种查询
source 路径 执行更快SELECT * FROM Foo WHERE b = 123 AND c = 23;
SELECT * FROM FooIdx WHERE b = 123 AND c = 23;

左边为为增加索引 右边是增加索引的查询时间
-- 搜索键等值⽐较
- 对于foo中没有索引的扫描查看查询计划,possible key = NULL表明他没有可能在查询的时候建立索引。所以foo只能做扫描。
- 由于fooidx中有bc的索引所以查找速度很快,否则 比如他只有abc索引但是他只需要查找bc,b在存储空间中是连续存放的 所以可以加快查找速度。type是ref代表他在查询的时候并没有做前端扫描,possible key = idx_b_c(b,c)
- 另外key_len是10的原因: 4+4+1+1



-- 搜索键前缀等值⽐较
不是前缀比较 因为他得先寻找b的值 但是c是连续的同时b不一定是连续,所以索引可能失效。
- 对于第一个查询,由于foo上没有建立索引,所以只能全程扫描
- 对于第二个查询,通过查看查询计划发现他使用的key_len是5,说明只扫描了前五位,也就是一个int字节+1
- 为了进一步验证前缀作为主顺序我们用后缀进行查询,通过查询计划发现他没有索引只能全程扫描。
EXPLAIN SELECT * FROM Foo WHERE b = 123;
EXPLAIN SELECT * FROM FooIdx WHERE b = 123;
EXPLAIN SELECT * FROM FooIdx WHERE c = 23; -- ⾮前缀
-- 索引键值前缀⽐较

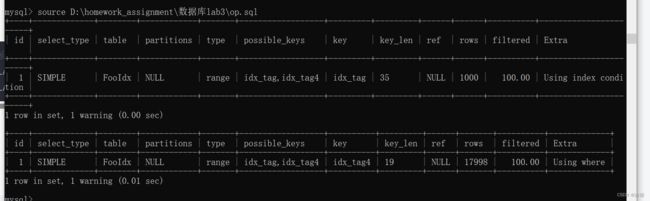
- 如果小于等于四位就用tag4前四位索引
- 如果大于就用tag索引

EXPLAIN SELECT * FROM Foo WHERE tag LIKE '00123%';
EXPLAIN SELECT * FROM FooIdx WHERE tag LIKE '00123%'; -- MySQL: 使⽤前缀索引; PostgreSQL:
使⽤顺序扫描
-- 多属性索引键的限制
- 如果范围比较大那么做索引就没有意义,这是DBMS性质决定的
- 如果是小范围的话建立索引的数据库会利用索引值进行查询。
EXPLAIN SELECT * FROM Foo WHERE b BETWEEN 123 AND 234;
EXPLAIN SELECT * FROM FooIdx WHERE b BETWEEN 123 AND 134;
EXPLAIN SELECT * FROM FooIdx WHERE b = 123 AND c BETWEEN 23 AND 45;
- key_len是5 说明只使用了b作为索引 只根据b值 查找相应的c,讲查找到的c和24做比较 所以dbms很懒
- 对于第二个他跳过 了中间属性 不能使用中间的值,使得中间的值可能被打乱所以不能跳过中间的值,只能单一的使用前缀作为索引。
表达式不能做匹配
-- 多属性索引键的限制
EXPLAIN SELECT * FROM FooIdx WHERE b = 123 AND c + 1 = 24; -- 不能与表达式进⾏⽐较
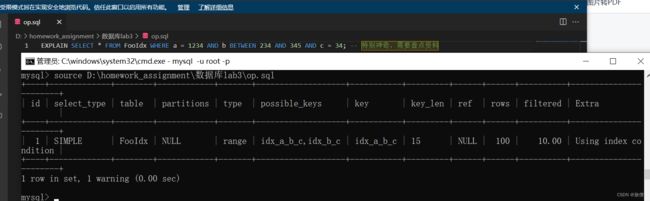
EXPLAIN SELECT * FROM FooIdx WHERE a = 1234 AND c = 34; -- MySQL: 不能跳过中间属性;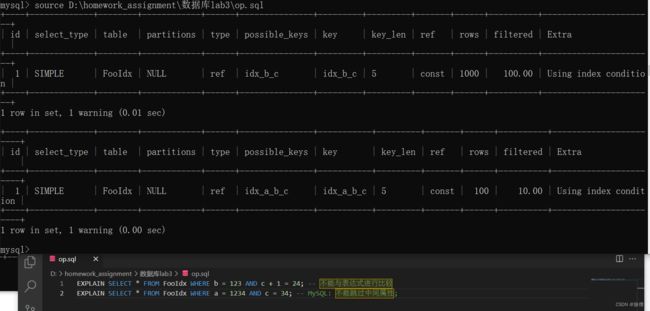
-- 别神奇 查查资料(doge)
EXPLAIN SELECT * FROM FooIdx WHERE a = 1234 AND b BETWEEN 234 AND 345 AND c = 34; -- 特别神奇,需要查点资料分析原因:理论上不能跳跃属性进行查询,a的选择度比较高,通过筛选之后得到的元组比较少,所以DBMS自动优化了
覆盖索引
-- 覆盖索引
EXPLAIN SELECT c FROM FooIdx WHERE b = 123;
EXPLAIN SELECT a FROM FooIdx WHERE b = 123; -- ⽆法覆盖
EXPLAIN SELECT id FROM FooIdx WHERE b = 123;

只需要找到索引项之后不用再回去找CS-001了
覆盖索引使得函数返回不需要回表了。
查看是否索引覆盖的方法: 看extra 是否是using index

索引合并
-- 索引合并
EXPLAIN SELECT * FROM FooIdx WHERE tag LIKE '001234%' OR b = 56; -- MySQL: 使⽤索引合并;访问时tag真正是idx_tag和idx_b_c并集得到元组的地址 先排序后归并using where

-- ⾮聚簇索引
EXPLAIN SELECT * FROM FooIdx WHERE b BETWEEN 123 AND 134;
EXPLAIN SELECT * FROM FooIdx WHERE b BETWEEN 123 AND 234; -- MySQL: 范围过⼤,查询优化器没⽤索引; PostgreSQL: ⽤索引

-- 前缀索引
EXPLAIN SELECT * FROM FooIdx WHERE tag LIKE '00123%'; -- MySQL: 使⽤前缀索引; PostgreSQL:使⽤顺序扫描
EXPLAIN SELECT * FROM FooIdx WHERE tag LIKE '0012%'; -- MySQL: 使⽤前缀索引; PostgreSQL:使⽤顺序扫描