正则表达式命令
文章目录
- 一.基础命令
-
- 1.grep命令
-
- 1.1grep格式
- 1.2grep命令选项
- 2.特殊的符号
-
- 2.1空行——^$
- 2.2以什么为开头—^,以什么为结尾—$
-
- 2.2.1以什么为开头的格式:
- 2.2.2以什么为结尾的格式:
- 3.只匹配单行——^匹配的字符$
- 二.文本处理命令
-
- 1.sort命令
-
- 1.1命令解释及格式
- 1.2常用选项
- 2.uniq命令——快捷去重
-
- 2.1 格式
- 2.2常用选项
- 3.tr命令
-
- 3.1语法格式:
- 3.2常用选项:
- 4.cut命令——快速裁剪
-
- 4.1cut截取方法
- 4.2格式
- 4.3选项
- 4.4示例
- 5.split——文件拆分
-
- 5.1格式
- 5.2选项
- 5.3示例
- 6.paste——合并文件
-
- 6.1格式
- 6.2选项
- 7.拓展
-
- 7.1统计当前主机的连接状态
- 7.2统计当前连接主机数
一.基础命令
1.grep命令
对文本的内容进行过滤,针对行处理
1.1grep格式
grep [选项]…查找条件 目标文件
1.2grep命令选项
-m+数字——————匹配几次后停止
eg:grep -m 1 root /etc/passwd————————————多个匹配只取

-v ————————取反
eg:grep -v root /etc/passwd————————————————除了root其余展示出来

-i —————————忽略字符大小写
eg:grep -i Root /etc/passwd————————————————不考虑大小写展示出来
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7XPNWlym-1685701824030)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602143112862.png)]](http://img.e-com-net.com/image/info8/b056b071f1434bb6bb90c1e813965f84.png)
-n——————————显示匹配行号
eg:grep -n root /etc/passwd
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ot6zA9kt-1685701824031)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602143425384.png)]](http://img.e-com-net.com/image/info8/749b01883a014ec0b97faf74f477b4d6.png)
-c—————————只显示匹配行号
eg:grep -c root /etc/passwd
![]()
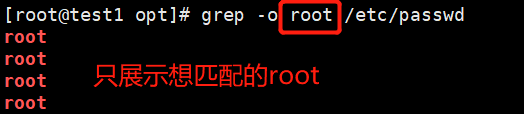
-o——————————仅显示匹配到的字符串
eg:grep -o root /etc/passwd
-A——————————匹配自身当前行的后三行,包含自身展示出来
eg:grep -A 3 zjf /etc/passwd

-B————————————自身前几行包含自身展示
eg:grep -B 3 zjf /etc/passwd

-C————————————本身的前三行和后三行以及本身展示出
eg:grep -C 3 zjf /etc/passwd

-e——————————————逻辑或,可以跟多个条件,若有显示,没有不显示
eg:grep -e root -e bash /etc/passwd

-w————————————匹配整个单词
eg:grep -w root /etc/passwd
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JIaL32hd-1685701824033)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602150124918.png)]](http://img.e-com-net.com/image/info8/c454840393014c9d9035d8a3878d9ef7.png)
-E——————————表示使用扩展正则相当于egrep
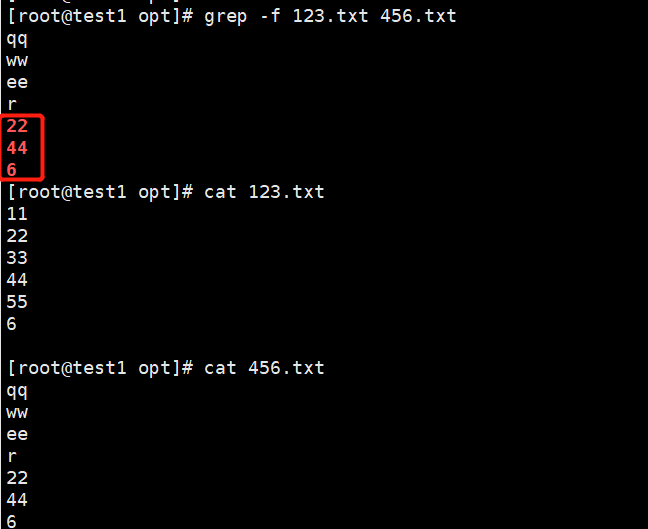
-f——————————根据模式文件处理两个文件的相同内容,第一个文件作为匹配条件
eg:grep -f 123.txt 456.txt
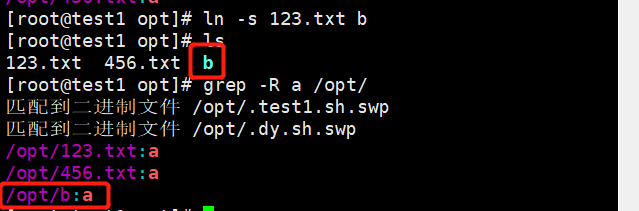
-r——————————递归目录文件当中的文件内容所包含的想要的文件内容
不对软链接处理
eg:grep -r a /opt/

-R——————————可以处理软链接中的文件内容
eg:grep -R a /opt/
2.特殊的符号
2.1空行——^$
示例:

cat 123.txt | grep -v "^$" > test.txt————过滤掉123.txt里的空行将内容传送给test.txt

2.2以什么为开头—^,以什么为结尾—$
2.2.1以什么为开头的格式:
grep “^所要让开头的字符” 文件名
示例:
grep "^4" 123.txt
grep "^a" 123.txt

2.2.2以什么为结尾的格式:
grep “^所要让开头的字符” 文件名
示例:
grep "h$" 123.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3mRCVGV6-1685701824035)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602154141168.png)]](http://img.e-com-net.com/image/info8/75de8b4793344c46a206de4606a3739c.png)
3.只匹配单行——^匹配的字符$
格式:
^匹配的字符$
示例:
grep -n "^root$" dh.txt

二.文本处理命令
1.sort命令
1.1命令解释及格式
以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序
语法格式:
sort 选项 参数
1.2常用选项
-f————————————————忽略大小写,默认会大写字母排在前面
eg:sort -f test.txt

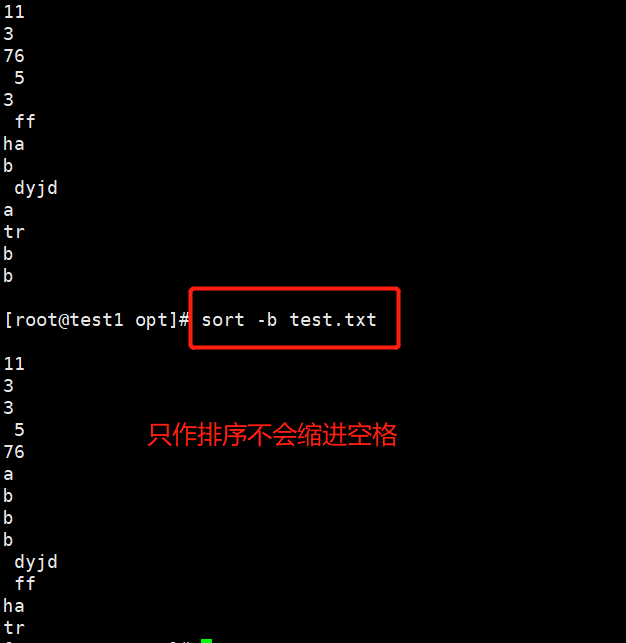
-b——————————————只排序不会忽略空格,忽略每行前面的空格
eg:sort -b test.txt
-n:按照数字进行排序
eg:sort -n test.txt

-r:针对字母的反向排序
eg:sort -r test.txt
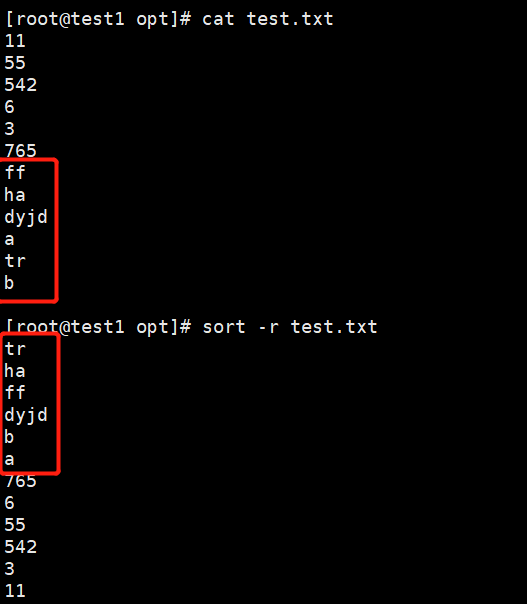
-u:等同uniq,表示相同的数据仅显示一行,去重
eg:sort -u test.txt

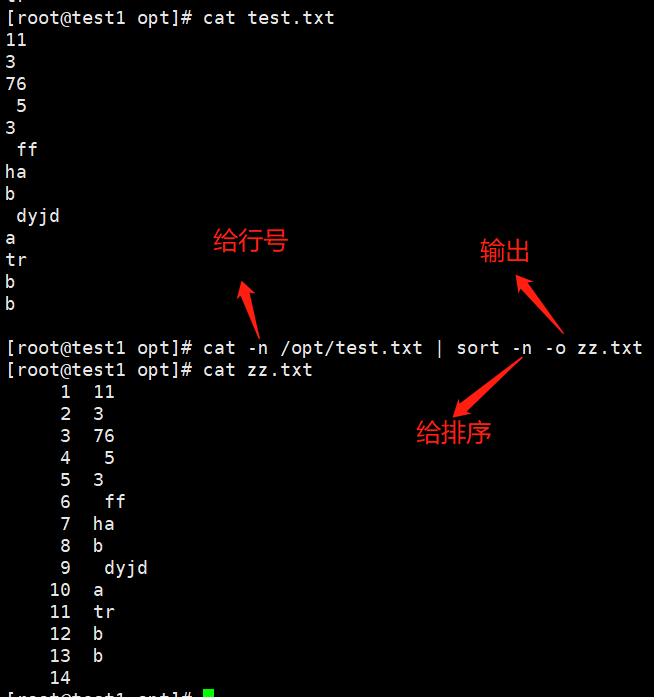
-o <输出文件>:将排序后的结果转存至指定文件
eg:cat /opt/test.txt | sort -o zjf.txt
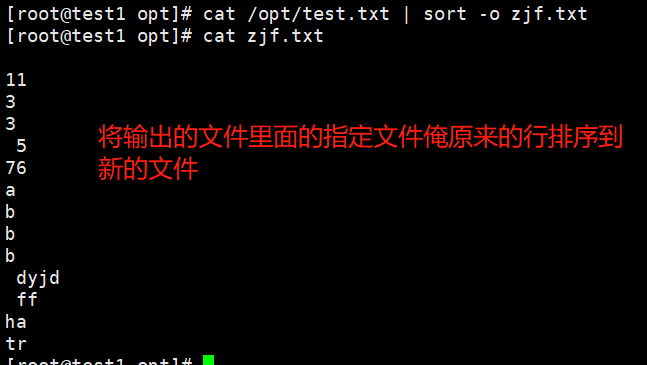
按原来的行一模一样的传到新的文件
2.uniq命令——快捷去重
uniq命令用于报告或者忽略文件中连续的重复行,常与sort命令结合使用。
2.1 格式
uniq [选项] 参数
cat 文件| uniq 选项
2.2常用选项
-c——————————————统计连续重复的行的次数,并且合并重复的行
eg:uniq -c test1.txt

去重排序:
cat test1.txt | uniq -c test1.txt | sort -n

-u——————————————显示仅出现一次的行(包括不连续的重复行)
eg:uniq -u test1.txt

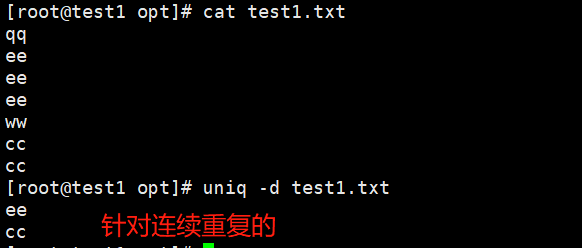
-d 仅显示重复出现的行(必须是连续的重复行)
eg:uniq -d test1.txt
3.tr命令
常用于对来自标准输入的字符进行替换、压缩和删除
参数:
字符集1:
指定要转换或删除的原字符集。当执行转换操作时,
必须使用参数”字符集2“指定转换操作时,必须使用参数”字符集2“指定转换的目标字符集。
但执行删除操作时,不需要参数”字符集2“
字符集2:
指定要转换成的目标字符集
3.1语法格式:
tr 选项 参数
3.2常用选项:
-c:保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换
eg:echo abc | tr -c ‘ab’ ‘a’
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XvmdV6ji-1685701824039)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602175012821.png)]](http://img.e-com-net.com/image/info8/a6f2b74a2d3c48e38ff7968a862e0d86.jpg)
-d:删除所有属于字符集1的字符
eg:echo abc | tr -d ‘ab’————————删除ab,打印c
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CEJa77XG-1685701824040)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602175215342.png)]](http://img.e-com-net.com/image/info8/747acd17939849c58a154da3ed4688c0.png)
-s:将重复出现的字符串压缩为一个字符串,用字符集2 替换 字符集1
eg:cat xx.txt | tr -s “w” “b”

-t:字符集2 替换 字符集1,不加也行
eg:echo 192.168.198.11 | tr “.” “:”
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p5gDSIG5-1685701824040)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602180239906.png)]](http://img.e-com-net.com/image/info8/25333333b70845f898b412bd9a8bdb1a.png)
echo 192.168.198.11 | tr -d “.”
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9nsQ0jww-1685701824040)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602180334654.png)]](http://img.e-com-net.com/image/info8/7ebd4998e6db484cb6c369be0f5d4c03.png)
将 echo $PATH中的":"替换为换行

4.cut命令——快速裁剪
4.1cut截取方法
cut截取方法
对字段进行截取和剪裁
4.2格式
格式一:cut [选项] 参数
格式二:cat 文件名 | cut [选项]
4.3选项
-d 指定分隔符(默认分隔符为Tab)
-f 按字段进行截取。指定第n个字段;
-b 以字节为单位进行截取
-c 以字符为单位进行截取
–complement 排除所指定的字段
–output-delimiter 更改输出内容的分隔符
4.4示例
(1)cut -d ":" -f 1-3 /etc/passwd————————以":"作为分隔符,指定第一个到第三个字段进行输出
cat /etc/passwd | cut -d ":" -f 1-3

head -n 2 /etc/passwd | cut -d ":" --complement -f 2————————指定以":"作为分隔符,但是删除了第二个字段进行输出

head -n 2 /etc/passwd | cut -d ":" --complement -f 1-5 --output-delimiter="@"——————————将分隔符转换为@,进行输出

5.split——文件拆分
split命令用于在Linux下将大文件拆分为若干小文件。
5.1格式
split 选项 参数 原始文件 拆分后文件名前缀
5.2选项
-l 指定行数对文件拆分
-b 指定文件的大小拆分
5.3示例
split -l 20 test6.txt sc
split -b 2m test6.txt dx

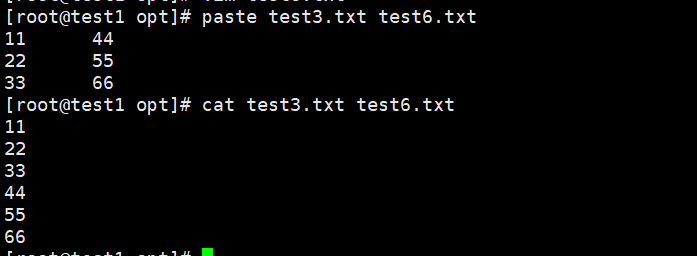
6.paste——合并文件
按照字段来进行文件的合并
6.1格式
paste [选项] 文件1 文件2
6.2选项
-d 用于指定文件的分隔符(默认情况下为制表符"\n")
-s 将列和行的内容进行互相交换
paste和cat合并有什么区别
cat是上下合并
paste是左右合并
7.拓展
7.1统计当前主机的连接状态
ss -nta | grep -v ‘^State’ |cut -d " " -f 1| sort | uniq -c
3 ESTAB #表示建立的 TCP 连接处于活动状态
17 LISTEN
7.2统计当前连接主机数
ss -nt | tr -s " "|cut -d " " -f 5 | sort -n | uniq -c
1 Local
2 192.168.233.21:22