SpringCloudAlibaba(简介及核心组件使用)
微服务架构常见的问题
一旦采用微服务系统架构,就势必会遇到这样几个问题:
-
这么多小服务,如何管理他们?服务发现/服务注册---》注册中心
-
这么多小服务,他们之间如何通讯?Feign -> 基于 http 的微服务调用组件 / RPC
-
这么多小服务,客户端怎么访问他们?服务网关 --> 所有客户端访问的一个入口
-
这么多小服务,一旦出现问题了,应该如何自处理?熔断器 --> 保险丝
-
这么多小服务,一旦出现问题了,应该如何排错?调用连追踪
对于上面的问题,是任何一个微服务设计者都不能绕过去的,因此大部分的微服务产品都针对每一
个问题提供了相应的组件来解决它们。
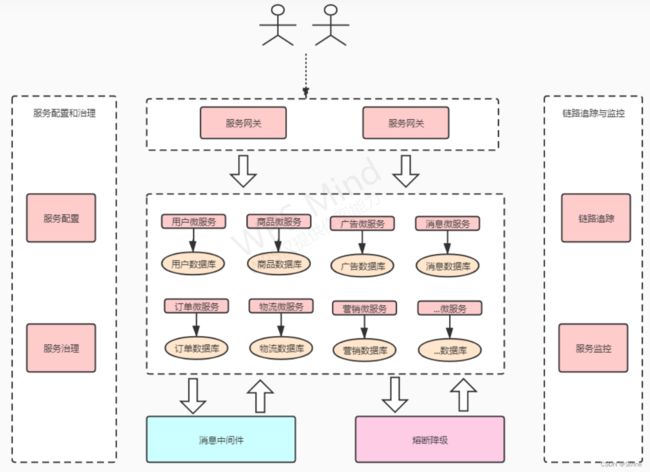
SpringCloud介绍
Spring Cloud 是一系列框架的集合。它利用 Spring Boot 的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。
Spring Cloud 并没有重复制造轮子,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过 Spring Boot 风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
SpringCloud和SpringBoot的关系
-
SpringBoot 专注于快速方便的开发单个个体微服务。
-
SpringCloud 是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务整合并管理起来,为各个微服务之间提供,配置管理、服务发现、断路器、路由、事件总线、分布式事务、等等集成服务。
总结: SpringBoot专注于快速、方便的开发单个微服务个体,SpringCloud关注全局的服务治理组件的集合。
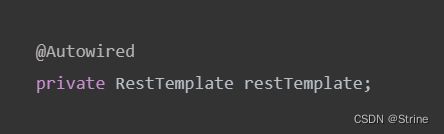
基于RestTemplate的远程调用
1.在启动类上添加RestTemplate的bean配置

2.在OrderServiceImpl中注入RestTemplate并实现远程调用

虽然我们已经可以实现微服务之间的调用。但是我们把服务提供者的网络地址(ip,端口)等硬编码到了代码中,这种做法存在许多问题:
-
一旦服务提供者地址变化,就需要手工修改代码
-
一旦是多个服务提供者,无法实现负载均衡功能
-
一旦服务变得越来越多,人工维护调用关系困难
那么应该怎么解决呢, 这时候就需要通过注册中心动态的实现服务治理。
服务治理Nacos Discovery
什么是服务治理?
服务治理是微服务架构中最核心最基本的模块。用于实现各个微服务的自动化注册与发现。
服务注册:在服务治理框架中,都会构建一个注册中心,每个服务单元向注册中心登记自己提供服
务的详细信息。并在注册中心形成一张服务的清单,服务注册中心需要以心跳的方式去监测清单中
的服务是否可用,如果不可用,需要在服务清单中剔除不可用的服务。
服务发现:服务调用方向服务注册中心咨询服务,并获取所有服务的实例清单,实现对具体服务实
例的访问。
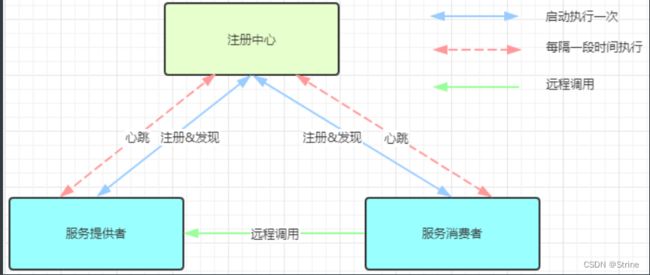
通过上面的调用图会发现,除了微服务,还有一个组件是服务注册中心,它是微服务架构非常重要
的一个组件,在微服务架构里主要起到了协调者的一个作用。注册中心一般包含如下几个功能:
-
服务发现:
服务注册:保存服务提供者和服务调用者的信息
服务订阅:服务调用者订阅服务提供者的信息,注册中心向订阅者推送提供者的信息
-
服务健康检测
检测服务提供者的健康情况,如果发现异常,执行服务剔除
-
而Nacos 是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。它是 SpringCloud Alibaba 组件之一,负责服务注册发现和服务配置。
常见的其他注册中心还有Zookeeper、Eureka、Consul等等;
基于Open Feign的远程调用
是什么?
Feign 是 Spring Cloud 提供的一个声明式的伪 Http 客户端, 它使得调用远程服务就像调用本地服务一样简单, 只需要创建一个接口并添加一个注解即可。
Nacos 很好的兼容了 Feign, Feign 默认集成了 Ribbon, 所以在 Nacos 下使用 Fegin 默认就实现了负载均衡的效果。
如何使用?
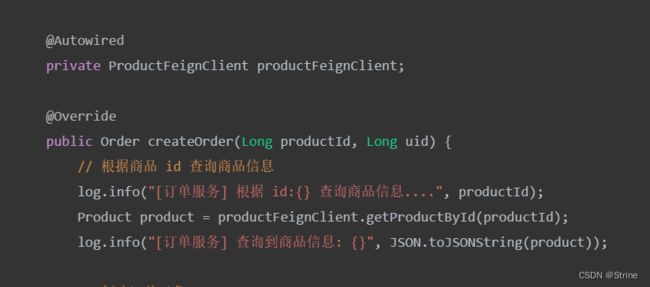
在启动类贴上Feign的扫描注解@EnableFeignClients:

我们在需要调用其他服务的模块中添加FeignApi接口:

修改Service层的业务逻辑如下:
Ribbon负载均衡
是什么?
通俗的讲, 负载均衡就是将负载(工作任务,访问请求)进行分摊到多个操作单元(服务器,组件)上进行执行。
根据负载均衡发生位置的不同,一般分为服务端负载均衡和客户端负载均衡。
服务端负载均衡指的是发生在服务提供者一方,比如常见的Nginx负载均衡
而客户端负载均衡指的是发生在服务请求的一方,也就是在发送请求之前已经选好了由哪个实例处理请求
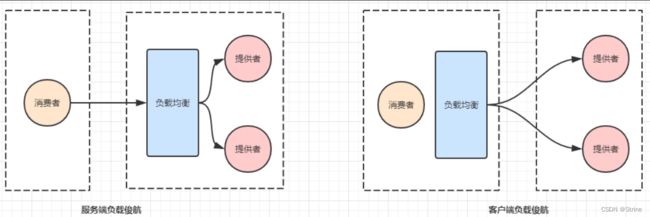
我们在微服务调用关系中一般会选择客户端负载均衡,也就是在服务调用的一方来决定服务由哪个提供者执行。
而Ribbon是 Spring Cloud 的一个组件, 它可以让我们使用一个注解就能轻松的搞定负载均衡
在RestTemplate的生成方法上面贴上@LoadBalanced注解

Ribbon支持的负载策略如下:

Sentinel熔断降级
高并发场景下带来的常见问题
在微服务架构中,我们将业务拆分成一个个的服务,服务与服务之间可以相互调用,但是由于网络
原因或者自身的原因,服务并不能保证服务的100%可用,如果单个服务出现问题,调用这个服务就会出现网络延迟,此时若有大量的网络涌入,会形成任务堆积,最终导致服务瘫痪。
服务器雪崩效应
在分布式系统中,由于网络原因或自身的原因,服务一般无法保证 100% 可用。如果一个服务出现了
问题,调用这个服务就会出现线程阻塞的情况,此时若有大量的请求涌入,就会出现多条线程阻塞等待,进而导致服务瘫痪。
由于服务与服务之间的依赖性,故障会传播,会对整个微服务系统造成灾难性的严重后果,这就是
服务故障的 “雪崩效应” 。
常见容错方案
常见的容错思路有隔离、超时、限流、熔断、降级这几种,下面分别介绍一下。
隔离机制: 比如服务A内总共有100个线程, 现在服务A可能会调用服务B,服务C,服务D.我们在服务A进行远程调用的时候,给不同的服务分配固定的线程,不会把所有线程都分配给某个微服务. 比如调用服务B分配30个线程,调用服务C分配30个线程,调用服务D分配40个线程. 这样进行资源的隔离,保证即使下游某个服务挂了,也不至于把服务A的线程消耗完。比如服务B挂了,这时候最多只会占用服务A的30个线程,服务A还有70个线程可以调用服务C和服务D.

超时机制: 在上游服务调用下游服务的时候,设置一个最大响应时间,如果超过这个时间,下游未作出反应,就断开请求,释放掉线程。

限流机制: 限流就是限制系统的输入和输出流量已达到保护系统的目的。为了保证系统的稳固运行,一旦达到的需要限制的阈值,就需要限制流量并采取少量措施以完成限制流量的目的。

熔断机制: 在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断。

-
服务熔断一般有三种状态:
-
熔断关闭状态(Closed)
服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制
-
熔断开启状态(Open)
后续对该服务接口的调用不再经过网络,直接执行本地的fallback方法
-
半熔断状态(Half-Open)
尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率。如果成功率达到预
期,则说明服务已恢复,进入熔断关闭状态;如果成功率仍旧很低,则重新进入熔断关闭状
态。
-
-
降级机制: 降级其实就是为服务提供一个兜底方案,一旦服务无法正常调用,就使用兜底方案。

常见容错组件
-
Hystrix
Hystrix 是由 Netflflix 开源的一个延迟和容错库,用于隔离访问远程系统、服务或者第三方库,防止
级联失败,从而提升系统的可用性与容错性。
-
Resilience4J
Resilicence4J 一款非常轻量、简单,并且文档非常清晰、丰富的熔断工具,这也是 Hystrix 官方推
荐的替代产品。不仅如此,Resilicence4j 还原生支持Spring Boot 1.x/2.x,而且监控也支持和
prometheus 等多款主流产品进行整合。
-
Sentinel
Sentinel 是阿里巴巴开源的一款断路器实现,本身在阿里内部已经被大规模采用,非常稳定。
什么是Sentinel
Sentinel (分布式系统的流量防卫兵) 是阿里开源的一套用于服务容错的综合性解决方案。它以流量
为切入点, 从流量控制、熔断降级、系统负载保护等多个维度来保护服务的稳定性
Sentinel 具有以下特征:
-
丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景, 例如秒杀(即
突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用
应用等。
-
完备的实时监控:Sentinel 提供了实时的监控功能。通过控制台可以看到接入应用的单台机器秒
级数据, 甚至 500 台以下规模的集群的汇总运行情况。
-
广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块, 例如与 Spring
Cloud、Dubbo、gRPC 的整合。只需要引入相应的依赖并进行简单的配置即可快速地接入
Sentinel。
Sentinel 分为两个部分:
-
核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo /
Spring Cloud 等框架也有较好的支持。
-
控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
Sentinel的熔断规则
熔断规则就是设置当满足什么条件的时候,对服务进行降级。Sentinel提供了三个衡量条件:
-
慢调用比例: 选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。
-
异常比例: 当单位统计时长内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是
[0.0, 1.0],代表 0% - 100%。 -
异常数:当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
Sentinel的容错维度

流量控制:流量控制在网络传输中是一个常用的概念,它用于调整网络包的数据。任意时间到来的请求往往是
随机不可控的,而系统的处理能力是有限的。我们需要根据系统的处理能力对流量进行控制。
熔断降级:当检测到调用链路中某个资源出现不稳定的表现,例如请求时间长或异常比例升高的时候,则
对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联故障。
系统负载保护:Sentinel 同时提供系统维度的自适应保护能力。当系统负载较高的时候,如果还持续让
请求进入可能会导致系统崩溃,无法响应。在集群环境下,会把本应这台机器承载的流量转发到其
它的机器上去。如果这个时候其它的机器也处在一个边缘状态的时候,Sentinel 提供了对应的保
护机制,让系统的入口流量和系统的负载达到一个平衡,保证系统在能力范围之内处理最多的请
求。
Sentinel的规则种类

服务网关
大家都都知道在微服务架构中,一个系统会被拆分为很多个微服务。那么作为客户端要如何去调用
这么多的微服务呢?如果没有网关的存在,我们只能在客户端记录每个微服务的地址,然后分别去调用。

这样的架构,会存在着诸多的问题:
-
客户端多次请求不同的微服务,增加客户端代码或配置编写的复杂性
-
认证复杂,每个服务都需要独立认证。
-
微服务做集群的情况下,客户端并没有负责均衡的功能
上面的这些问题可以借助API 网关来解决。
所谓的API网关,就是指系统的统一入口,它封装了应用程序的内部结构,为客户端提供统一服
务,一些与业务本身功能无关的公共逻辑可以在这里实现,诸如认证、鉴权、监控、路由转发等等。
添加上API网关之后,系统的架构图变成了如下所示:
 常见网关介绍
常见网关介绍
-
Ngnix+lua
使用nginx的反向代理和负载均衡可实现对api服务器的负载均衡及高可用,lua是一种脚本语言,可以来编写一些简单的逻辑, nginx支持lua脚本
-
Kong
基于Nginx+Lua开发,性能高,稳定,有多个可用的插件(限流、鉴权等等)可以开箱即用。 问题:只支持Http协议;二次开发,自由扩展困难;提供管理API,缺乏更易用的管控、配置方式。
-
Zuul
Netflflix开源的网关,功能丰富,使用JAVA开发,易于二次开发 问题:缺乏管控,无法动态配置;依赖组件较多;处理Http请求依赖的是Web容器,性能不如Nginx
-
Spring Cloud Gateway
Spring 公司为了替换 Zuul 而开发的网关服务,将在下面具体介绍。
注意:SpringCloud alibaba 技术栈中并没有提供自己的网关,我们可以采用 Spring Cloud Gateway 来做网关
Gateway
Spring Cloud Gateway 是 Spring 公司基于Spring 5.0,Spring Boot 2.0 和 Project Reactor 等技术
开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式。它的目标是替代
Netflflix Zuul,其不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安
全,监控和限流。
优点:
-
性能强劲:是第一代网关 Zuul 的 1.6 倍
-
功能强大:内置了很多实用的功能,例如转发、监控、限流等
-
设计优雅,容易扩展
缺点:
-
其实现依赖 Netty 与 WebFlux,不是传统的 Servlet 编程模型,学习成本高
-
不能将其部署在 Tomcat、Jetty 等 Servlet 容器里,只能打成 jar 包执行
-
需要 Spring Boot 2.0 及以上的版本,才支持
主要定义了下面的几个信息:
-
id,路由标识符,区别于其他 Route。
-
uri,路由指向的目的地 uri,即客户端请求最终被转发到的微服务。
-
order,用于多个 Route 之间的排序,数值越小排序越靠前,匹配优先级越高。
-
predicate,断言的作用是进行条件判断,只有断言都返回真,才会真正的执行路由。
-
filter,过滤器用于修改请求和响应信息。
执行流程:
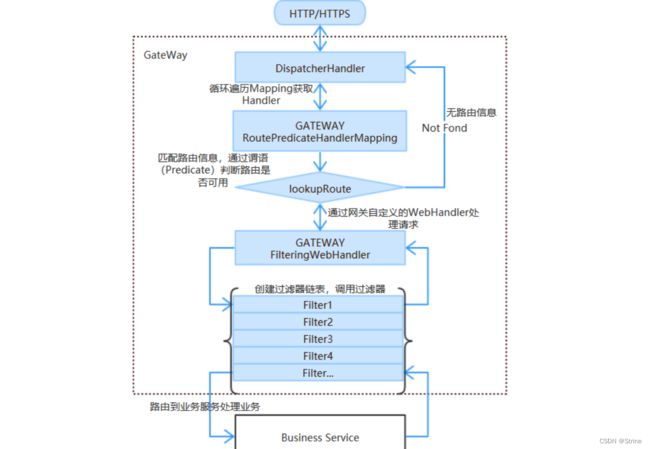
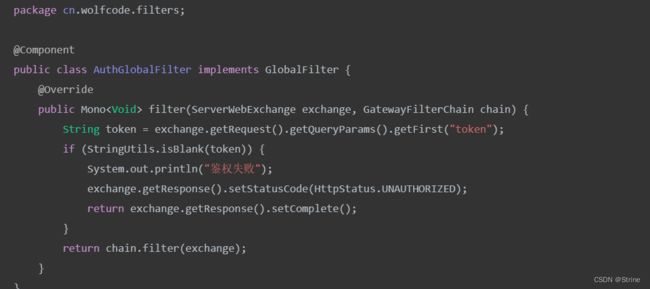
这里主要讲一下全局过滤器:
全局过滤器作用于所有路由, 无需配置。通过全局过滤器可以实现对权限的统一校验,安全性验证等功能。
分布式链路追踪
微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
分布式链路追踪(Distributed Tracing),就是将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
常见的链路追踪技术
-
cat :由大众点评开源,基于Java开发的实时应用监控平台,包括实时应用监控,业务监控 。 集成
方案是通过代码埋点的方式来实现监控,比如: 拦截器,过滤器等。 对代码的侵入性很大,集成
成本较高。风险较大。
-
zipkin :由Twitter公司开源,开放源代码分布式的跟踪系统,用于收集服务的定时数据,以解决微
服务架构中的延迟问题,包括:数据的收集、存储、查找和展现。该产品结合spring-cloud-sleuth
使用较为简单, 集成很方便, 但是功能较简单。
-
pinpoint: Pinpoint是韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点
是支持多种插件,UI功能强大,接入端无代码侵入。
-
skywalking:SkyWalking是本土开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多
种插件,UI功能较强,接入端无代码侵入。目前已加入Apache孵化器。
-
Sleuth
SpringCloud 提供的分布式系统中链路追踪解决方案。
而我们如果使用Sleuth的话一般是以Zipkin+Sleuth的方式,其中zipkin是Twitter基于google的分布式监控系统Dapper(论文)的开发源实现,zipkin用于跟踪分布式服务之间的应用数据链路,分析处理延时,帮助我们改进系统的性能和定位故障。