数据结构基础内容-----第五章 串
文章目录
- 串
- 串的比较
- 串的抽象数据类型
-
- 串的顺序存储结构
- 朴素的额模式匹配算法
- kmp模式匹配算法
串
在计算机编程中,串(String)是指由零个或多个字符组成的有限序列。它是一种基本的数据类型,在许多编程语言中都得到了支持和广泛应用。通常情况下,我们使用单引号或双引号来表示一个串,例如:“Hello World” 或者 ‘123456’。
串可以进行各种操作,比如拼接、截取、查找、替换等等。在实际应用中,串经常用于处理文本、密码等方面。例如,在网站开发中,我们需要对用户输入的字符串进行验证、过滤、加密等操作。此外,在数据处理及分析方面,也需要用到串类型。
串的比较
在计算机编程中,字符串的比较通常是指比较两个字符串的字典序。字典序比较适用于对字符串进行排序和查找操作。
具体来说,如果我们要比较两个字符串s1和s2的字典序,可以按照以下步骤进行:
从左到右依次比较s1和s2的每个字符。
如果当前字符相等,则比较下一个字符。
如果当前字符不相等,则比较它们的ASCII码值。如果s1当前字符的ASCII码值小于s2当前字符的ASCII码值,则s1小于s2;反之则s1大于s2。
如果s1或s2已经比较完了所有字符,且前面所有字符都相等,则长度较短的字符串小于长度较长的字符串。
例如,比较"abc"和"abd"的字典序时,首先比较第一个字符’a’和’b’,发现它们不相等,因此可以确定“abc”小于“abd”。
串的抽象数据类型
串的抽象数据类型(ADT)是一种数据结构,它定义了对字符串进行操作的抽象接口。常见的串操作包括插入、删除、查找、替换和比较等。
ADT String {
data:
串的字符集,每个元素都属于此集合中的某个字符
operation:
StrAssign(T, chars) // 将T赋值为由chars组成的串
StrCopy(T, S) // 复制串S到T
StrLength(S) // 返回串S的长度
StrEmpty(S) // 判断串S是否为空
Concat(T, S1, S2) // 将串S1和S2连接起来,结果存在T中
SubString(Sub, S, pos, len) // 返回串S从pos开始长度为len的子串Sub
StrCompare(S1, S2) // 比较串S1和S2的大小关系,返回0表示相等,返回正数表示S1大于S2,返回负数表示S1小于S2
Index(S, T, pos) // 在串S中从pos位置开始查找串T,返回T在S中第一次出现的位置,如果没找到则返回-1
Replace(S, T, V) // 在串S中查找所有的T,并将其替换为V
CountChar(S, ch) // 统计串S中某个字符ch出现的次数
DeleteChar(S, pos) // 删除串S中指定位置pos的字符
Insert(S, pos, T) // 在串S的pos位置插入串T
Reverse(S) // 反转串S
Trim(S) // 去掉串S两端的空格
ToUpper(S) // 将串S中的所有字母字符转换为大写
ToLower(S) // 将串S中的所有字母字符转换为小写
}
串的顺序存储结构
串的顺序存储结构是将串中的每个字符依次存放在一段连续的存储空间中,通常使用数组来实现。在顺序存储结构中,我们可以通过下标访问或修改某个字符,因此访问速度较快。
以下是一个简单的串的顺序存储结构定义:
#define MAXSIZE 1000 // 定义串的最大长度
typedef struct {
char data[MAXSIZE]; // 存储串的字符数组
int length; // 串的当前长度
} SqString;
其中,data数组用来存储串的每个字符,length表示当前串的长度。对于一个长度为n的串,它的第i个字符存储在data[i-1]的位置,即下标从0到n-1。
串的链式存储结构是通过链表来实现,每个节点存储一个字符,节点之间用指针连接起来。相比于顺序存储结构,链式存储结构可以动态地分配和释放内存,适合存储长度不确定的串。
以下是一个简单的串的链式存储结构定义:
typedef struct node {
char data; // 存储字符
struct node *next; // 指向下一个节点的指针
} Node, *LinkStr;
// 串的链式存储结构
typedef struct {
LinkStr head; // 头指针
int length; // 串的当前长度
} LiString;
其中,每个节点包含一个字符和一个指向下一个节点的指针,head指向链表的第一个节点。在使用链式存储结构时,我们需要注意处理指针的赋值、节点的插入和删除等操作,以及避免出现空指针引用等问题。
需要注意的是,在使用链式存储结构时,由于每个节点都需要额外的指针空间来存储,因此占用的内存会比较大。
朴素的额模式匹配算法
朴素的模式匹配算法,也被称为暴力匹配算法或者Brute-Force算法,是一种简单有效的字符串匹配算法。该算法的基本思想是从目标串的第一个字符开始,依次和模式串进行比较,如果匹配失败则将目标串向右移动一个字符,再从目标串的下一个字符开始重新匹配。
具体而言,朴素的模式匹配算法可以按照以下步骤进行:
将模式串p和目标串t的开头对齐。
逐个比较p和t中相应位置的字符,若全部相等,则匹配成功;否则,转到步骤3。
将t向右移动一位,并从第一步开始重复匹配过程,直到找到匹配位置或者t遍历完毕。
下面是一个简单的朴素模式匹配算法的实现:
int BruteForce(string t, string p) {
int i = 0, j = 0; // i和j分别指向t和p的当前匹配位置
int m = t.length(), n = p.length();
while (i < m && j < n) { // 循环直到匹配完成或者t已经遍历完毕
if (t[i] == p[j]) { // 当前字符匹配成功,继续比较下一个字符
i++;
j++;
} else { // 当前字符匹配失败,将t向右移动一位重新开始比较
i = i - j + 1;
j = 0;
}
}
if (j == n) { // 匹配成功,返回匹配位置
return i - j;
} else { // 匹配失败
return -1;
}
}
朴素模式匹配算法的时间复杂度为O(mn),其中m和n分别是目标串和模式串的长度。在最坏情况下,算法需要比较mn次才能完成匹配。该算法虽然简单易懂,但是对于大规模的字符串匹配来说效率较低,因此通常不适用于实际应用。
kmp模式匹配算法
KMP算法是一种字符串匹配算法,可以在一个文本串S内查找一个模式串P的出现位置。KMP算法的主要思想是利用已知信息消除匹配过程中的不必要的比较。
具体实现方法如下:
-
预处理模式串P,得到next数组。next[i]表示当第i个字符匹配失败时,应该移动模式串的指针到哪个位置继续匹配。
-
在文本串S中查找模式串P。假设当前文本串匹配到了第j个字符,模式串匹配到了第k个字符,如果S[j]和P[k]相等,则继续比较下一个字符;如果S[j]和P[k]不相等,则将模式串的指针移动到next[k]位置继续匹配。
-
如果模式串匹配成功,返回文本串中匹配的起始位置。
KMP算法的时间复杂度是O(m+n),其中m和n分别是模式串和文本串的长度。KMP算法比朴素的字符串匹配算法效率更高,特别是在模式串较长的情况下。
KMP算法的关键是求出模式串的next数组,其可以在匹配过程中快速移动模式串指针,从而提高算法效率。下面介绍如何计算next数组的值。
对于模式串P,我们定义next[j]表示P[0] ~ P[j-1]这个子串中前后缀的最长公共部分长度。例如,当j=4时,next[4]表示P[0]~P[3]这个子串的最长公共前后缀长度。
具体地,我们可以使用递推的方式来计算next数组的值。假设我们已经计算出了next[0]、next[1]、… 、next[j-1]的值,现在要计算next[j]的值。我们需要找到P[0] ~ P[j-1]的一个真前缀,它同时也是P[0]~P[j-1]的一个真后缀,并且在其中找到长度最长的那个。然后将这个长度赋给next[j]即可。
更具体地,我们可以按照以下步骤进行计算:
-
让i=0,j=1,next[0]=-1。
-
如果P[i]=P[j],则将next[j]=next[i]+1,i和j都加1。
-
如果P[i]≠P[j],则令i=next[i],直到i=-1或者P[i]=P[j]为止。这里需要注意,当i=-1时,说明已经没有更短的真前缀和真后缀相同的子串了,我们将next[j]=0,j加1即可。
-
重复步骤2和3,直到计算出所有的next值。
最终计算得到的next数组就是模式串的前缀表,它可以在KMP算法中快速移动模式串指针,提高算法效率。
kmp看起来有点难懂,可以通过部分可视化算法网站来实现Dynamic Programming
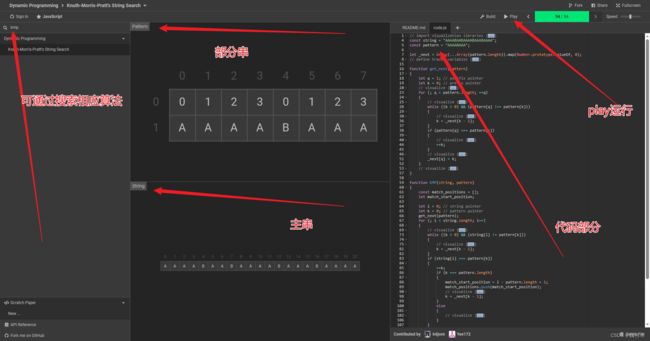
例子
#include 尽管KMP算法已经很优秀了,但是我们仍然可以对其进行进一步的改进。
一种比较常见的改进方法是使用双指针算法,在匹配过程中同时维护文本串指针i和模式串指针j。具体地,当两个字符相等时,i和j同时向后移动,否则根据next数组的值将j移动到相应位置。这种改进可以进一步减少不必要的计算量,提高算法效率。
另外一种改进方法是使用BM算法,其核心思想是通过对比文本串与模式串最后一个字符的距离,选择合适的步长进行移动。例如,当文本串中的一个字符与模式串最后一个字符不匹配时,可以根据该字符在模式串中出现的位置,移动模式串指针到下一个可能匹配的位置。这种改进方法可以进一步提高算法效率,特别是在处理长文本串和短模式串时效果更加明显。
除此之外,还有一些其他的改进方法,如Sunday算法、Horspool算法等。实际上,不同的算法适用于不同的场景,我们可以根据具体情况选择合适的算法进行优化。