Java 集合详解一篇文章讲解Java 三大集合
更好阅读体验:Java 集合详解 | 一篇文章搞定Java 三大集合
好看的皮囊像是一个个容器,有趣的灵魂像是容器里的数据。接下来讲解Java集合数据容器。
文章篇幅有点长,还请耐心阅读。如只是为了解决某个疑问,可以阅读目录来查找你所需的内容。
开门见山:「Java集合框架图」
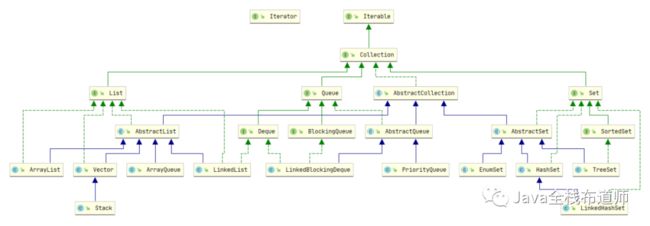
Collection

Map
1.Iterator(迭代器)
迭代器的基本功能就是遍历集合中的所有元素。
Iterable 接口组合了迭代器Iterator,通过方法:Iterator iterator(); 来获取迭代器。
Collection 和 Map是 Java集合框架的根接口,Iterable 接口提供了迭代的功能。
1.1.集合和迭代器的关系
Collection 接口通过继承Iterable 接口来获得迭代功能;
Map 接口的迭代功能是嫁接Collection 接口的迭代功能,看Map 接口的抽象方法就知道了:具体怎么用在Map 集合的常用方法中讲到。
// 通过键来遍历,返回值是Set集合,Map的key是Set集合,特性也和Set一样的
Set keySet();
// 通过值来遍历,返回值是Collection
Collection values();
// 通过键值对来遍历,返回值是Set集合
Set> entrySet();
2.集合和集合特点
List集合:元素按进入先后有序排序有序排序保存,可以存储重复元素
Set集合:不可以存储重复元素
Map集合:Key值不可以重复(key等于Set集合),Value值可以重复
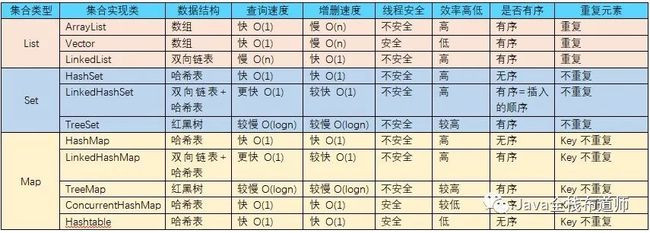
数据结构:数组、双向链表、哈希表、二叉树;关于数据底层存储结构,决定了集合绝大部分的特性,如:查询和增删快慢,是否有序,是否可以重复。
线程安全:就是集合中的方法使用了同步锁关键字:synchronized;有锁的效率低。
3.怎么选择集合
根据需求和集合特点来选择所需的集合类型。
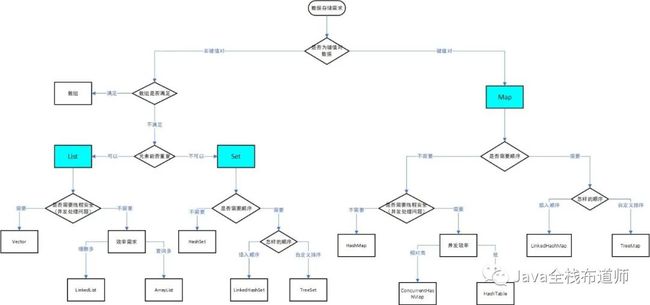
「集合的具体使用」
4.List 集合
4.1.单集合操作
List list = new ArrayList();
// 1.1 新增元素
list.add("测试1");
list.add("测试2");
System.out.println("集合大小="+list.size());
// 1.2 指定下标新增,index 范围:[0,list.size()]
list.add(1,"测试3");
for (int i=0;i {
System.out.println("交集="+str);
});
// 3 移除指定集合元素(差集)
list.add("存在和价值");
list.removeAll(linkedList);
for (String str : list){
System.out.println("差集="+str);
}
// 4 并集,如果集合见存在相同元素,则去除相同在合并就可以得到并集
list.removeAll(linkedList);
list.addAll(linkedList);
for (int i=0;i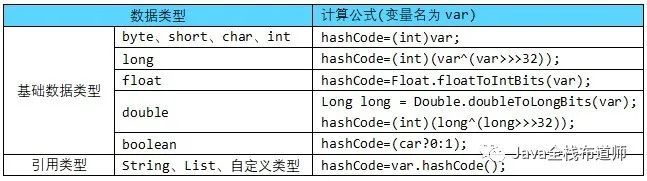
一个实体类有多个成员变量,为了避免偶然出现哈希值相等问题,常常将多列的哈希值成语质数再相加:hashCode=(int)var*31+var.hashCode()*31;
「例子」
public class Person {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age &&
Objects.equals(name, person.name);
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((name == null) ? 0 : name.hashCode())*prime;
result = prime * result + age*prime;
return result;
}
}
如果觉得这样生成hashCode麻烦,可以用Objects类型的hash方法生成
@Override
public int hashCode() {
return Objects.hash(name,age);
}
在使用HashSet 或 LinkedHashSet 集合时,实现hashCode和equals 方法即可。但在使用TreeSet 的时候,实体类还需要重写比较器来实现定制排序。
5.2.比较器的实现
「比较器实现方式汇总」
- 实体类实现Comparable接口,重写compareTo方法;
- 专门写一个实现类实现Comparator接口,重写compare方法;创建TreeSet的时候传入该实体类的对象;
- 匿名实现Comparator;
- lambda实现Comparator;
第1种方式实现Comparable接口,重写compareTo方法;例如Person类通过age 和 name 字段进行排序
// 1.实现Comparable接口,重写compareTo方法
@Override
public int compareTo(Object obj) {
if (!(obj instanceof Person))
throw new RuntimeException("不是正确对象");
Person p = (Person) obj;
if (p.age > this.age) return -1;
if (p.age == this.age) {
return this.name.compareTo(p.name);
}
return 1;
}
比较器有多种实现方式,这只是其中一种比较简单的。
第2、3、4方式核心代码都一样,只是写法不同
// 2.单独类实现
public class ComparatorImpl implements Comparator {
@Override
public int compare(Object o1, Object o2) {
if (o1==o2) return 0;
if (!(o1 instanceof Person) || !(o2 instanceof Person))
throw new RuntimeException("不是Person 类型");
Person p1=(Person)o1;
Person p2=(Person)o2;
int num=p1.getName().compareTo(p2.getName());
if (num==0){
return new Integer(p1.getAge()).compareTo(new Integer(p2.getAge()));
}
return num;
}
}
// 怎么使用
Set treeSet = new TreeSet(new ComparatorImpl());
// 3.匿名方式
TreeSet ts = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {内容一样}
});
// 4.lambda 方式 (匿名方式的简写)
TreeSet ts = new TreeSet((o1, o2)->{内容一样}
});
1和2的实现方式的特点是写死了,所有使用的定制排序都是一样的,不能对不同的对象定制不同的排序规则,需要对每个对象定制不同排序则使用3或4的实现方式。
5.3.Set 集合通用方法

5.4.TreeSet 特有方法
- Comparator comparator():用于获取定制排序Comparator 对象。如果实现了自定义定制排序,则该方法返回Comparator对象;反正返回null。
- Object first():返回集合中的第一个元素。
- Object last():返回集合中的最后一个元素。
- Object lower(Object e):返回集合中位于指定元素之前的元素(即小于指定元素的最大元素,参考元素不需要是TreeSet集合里的元素)。
- Object higher(Object e):返回集合中位于指定元素之后的元素(即大于指定元素的最小元素,参考元素不需要是TreeSet集合里的元素)。
- SortedSet subSet(Object fromElement, ObjecttoElement):返回此Set的子集合,范围从fromElement(包含)到toElement(不包含)。
- SortedSet headSet(Object toElement):返回此Set的子集,由小于toElement的元素组成。
- SortedSet tailSet(Object fromElement) :返回此Set 的子集,由大于或等于fromElement的元素组成。
6.1.Map 集合
「建议:要想掌握好Map集合得先学会Collection集合」
Map集合存储键值对数据,Key 拥有Set集合特点,Value 拥有着Collection的特点,Map 像是Set+Collection的集合。所以在使用map存储、获取对象时,用作Key的对象必须实现equals 和 hashCode 方法。不重写这两个方法就会出现,相同的Key的数据也可以保存到Map集合中,就会出现**「key不唯一」**,如:当你使用map.get() 获取到的是“null”。
6.2.为什么必须重写equals 和 hashCode 方法
「必须举个例子说明,因为常常有人在这掉入陷阱」
public class Student {
private String name;
private int age;
public Student(){}
public Student(String name,int age){
this.name=name;
this.age=age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
测试是否会保存相同的key
// 测试
public class TestMap {
public static void main(String[] args) {
Student student1 = new Student("张三", 18);
Student student2 = new Student("我是唯一", 28);
Student student3 = new Student("张三", 18);
HashMap studentHashMap = new HashMap<>();
studentHashMap.put(student1,student1);
studentHashMap.put(student2,student2);
studentHashMap.put(student3,student3);
Iterator> iterator = studentHashMap.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry next = iterator.next();
System.out.println("key="+next.getKey()+"|value="+next.getValue());
}
}
}
结果:相同的Key也保存成功了

测试通过key来获取value:关键来了最容易理解错的一步
错误示范:使用前面定义的对象引用来获取
// 错误示范:使用前面定义的对象引用来获取
Student student = studentHashMap.get(student3);
System.out.println(student);
错误示范结果:在存有相同的key的map集合中,拿到了value值

正确示范:使用新定义的对象引用来获取(定义的对象字段值是相同的)
// 正确示范:使用新定义的对象引用来获取:定义的对象字段值是相同的
Student student4 = new Student("张三", 18);
Student student = studentHashMap.get(student4);
System.out.println(student);
测试结果

实现equals 和 hashCode方法后再来正确示范
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name,age);
}
实现后的测试结果
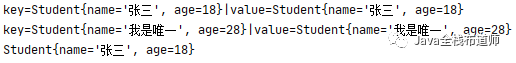
之所以会测不出来null的问题是因为在同一个类中测试往往喜欢使用前面的存储时的引用来操作map.get,那肯定是测不出来的,因为new的所有对象的地址肯定都是唯一的,所以用唯一的地址去获取,那肯定是可以get到的。正确的是新建一个内容相同,地址不同的引用去获取。
当使用TreeMap 时,作为key的对象还需要定制排序,这个操作和Set集合的定制排序一样,具体看Set 集合定制排序。
6.3.Map集合常用方法
HashMap hashMap = new HashMap<>();
// 新增
hashMap.put("test1","test1-value");
hashMap.put("test2","test2-value");
// map和其他集合都重写了toString
System.out.println(hashMap);
System.out.println("集合大小"+hashMap.size());
System.out.println("集合大小是否=0:"+hashMap.isEmpty());
System.out.println("是否包含key=test1的元素:"+hashMap.containsKey("test1"));
System.out.println("是否包含value=test1的元素:"+hashMap.containsValue("test1"));
System.out.println("获取Key=test1的值:"+hashMap.get("test1"));
// 移除元素
hashMap.remove("test1");
System.out.println(hashMap);
// 集合合并
HashMap hashMap1 = new HashMap<>();
hashMap1.put("test1","test1"); // 相同key的会覆盖原来的值
hashMap1.put("hashMap1","hashMap1-value");
hashMap.putAll(hashMap1);
System.out.println(hashMap);
输出结果

通过迭代器来遍历:「key 集合」、「value集合」和「key-value集合(entry)」
看代码就知道key集合是Set集合,value集合是Collection集合,entry集合是Set集合
HashMap hashMap = new HashMap<>();
hashMap.put("testKey1","testValue1");
hashMap.put("testKey2","testValue2");
// 1.通过 键 来遍历,返回值是Set集合,Map的key是Set集合,特性也和Set一样的
//获取集合中所有key的Set集合
Set keySet = hashMap.keySet();
//通过Set集合的迭代器进行遍历 (为了好理解分开两步来获取,开发时可以一步到位)
Iterator iteratorKey = keySet.iterator();
while (iteratorKey.hasNext()) {
String next = iteratorKey.next();
System.out.println("key="+next);
}
// 2.通过 值 来遍历,返回值是Collection
// 获取集合中所有value的集合
Collection collection = hashMap.values();
//通过集合的迭代器进行遍历
Iterator iteratorValue = collection.iterator();
while (iteratorValue.hasNext()){
String next = iteratorValue.next();
System.out.println("value="+next);
}
// 3.通过 键值对 来遍历,返回值是Set集合
//获取Map元素对象的Set集合
Set> entrySet = hashMap.entrySet();
//通过Set集合的迭代器进行遍历
Iterator> iteratorEntry = entrySet.iterator();
while (iteratorEntry.hasNext()){
//单个map元素对象
Map.Entry entry = iteratorEntry.next();
System.out.println("key="+entry.getKey()+",value="+entry.getValue());
}
输出结果

6.4.Map集合的三种遍历方式
前面讲了三种方式,前两种只是准对key 和 value的遍历。
在这里汇总的都是针对整个Map的遍历方式:「「通用迭代器方式」」,「「forEach」「和」「forEach方法」」。
// 通用遍历方式
Iterator> iteratorEntry = hashMap.entrySet().iterator();
while (iteratorEntry.hasNext()){
Map.Entry entry = iteratorEntry.next();
System.out.println("key="+entry.getKey()+",value="+entry.getValue());
}
// forEach
for (Map.Entry entry : hashMap.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println("key=" + key + ",value=" + value);
}
// 调用forEach方法,lambda语法
hashMap.forEach((key,value)->{
System.out.println("key="+key+",value="+value);
});
HashMap、LinkedHashMap、TressMap和ConcurrentHashMap……那么多的方法,只能自己去学习了。

7.Collections 集合工具类
Collections 是用于操作List、Set和Map等集合的工具类。该工具类提供了大量方法(功能)对集合元素进行排序、查询、修改等操作,对集合对象实现同步控制等方法。
7.1.排序问题
常用于对List集合元素排序的方法有
- 自然排序:void sort(List list);
- 比较器定制排序:void sort(List list,Comparator c);
- 反转排序:void reverse(List list);
- 随机排序:void shuffle(List list);
// 0.数据准备
List arrayList = new ArrayList<>();
arrayList.add("z");
arrayList.add("a");
arrayList.add("c");
arrayList.add("b");
System.out.println("插入顺序:"+arrayList);
// 1.自然排序
Collections.sort(arrayList);
System.out.println("自然排序:"+arrayList);
// 2.比较器定制排序
Collections.sort(arrayList, new Comparator() {
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});
System.out.println("定制排序:"+arrayList);
// 3.反转排序
Collections.reverse(arrayList);
System.out.println("反转排序:"+arrayList);
// 4.随机排序
Collections.shuffle(arrayList);
System.out.println("随机排序:"+arrayList);
7.2.解决线程安全问题
ArrayList 和 Vector 的主要区别是线程安全,虽然Vector可以解决线程安全,但不建议使用。可以通过集合工具类(Collections类)来解决ArrayList 并发访问线程安全问题。对于Set和Map集合线程安全问题,也可以通过Collections类来解决。

// 创建对象时使用
List synchronizedList = Collections.synchronizedList(new ArrayList());
Collections 工具类还有查找操作、修改操作等等,更多知识自行学习。

原创不易,还请三联。更多优质文章