【编译原理】有限自动机在语法分析中的应用
目录
前言
一、需求说明
二、有限自动机设计
1. 常量语法
2. 变量语法
3. 语句语法
三、编码实现
1. 词法分析
2. 语法分析
四、测试案例
前言
本章将使用一个具体的例子来生成token序列以及生成抽象语法树。例子:简单数学代数方程的语法分析。
一、需求说明
1. 变量用字母+数字表示,且首字符是字母;
2. 支持加+、减-、乘*、除/四则运算和括号;
3. 以分号为语句结束。
二、有限自动机设计
1. 常量语法
①整个常量只有数字和小数点组成;
②最多只有一个小数点,小数点前后都只有且最少一个数字。
那么有限自动机为下图所示:

2. 变量语法
①整个变量只有字母和数字组成,且首字符为字母。
有限自动机为下图所示:

3. 语句语法
①整个语句最多只能有一个等于号;
②语句已分号结尾表示结束;
③在等于号的一边,变量与变量、变量与常量、常量与常量之间必须有运算符;
④因为加号、减号可以表示正数和负数,所以加号、减号前面可以不是常量和变量;
⑤上括号后面必须是常量、变量、嵌套上括号、下括号的其中一个;
⑥下括号前面必须是常量、变量、嵌套下括号、上括号的其中一个。
有限自动机为下图所示:
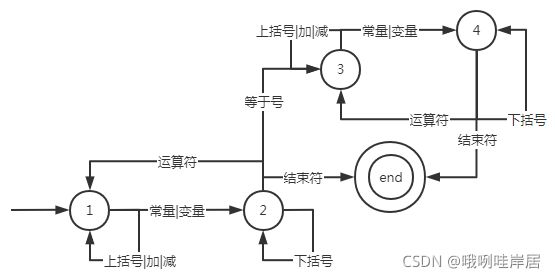
注:(状态1、状态2) 和 (状态3、状态4) 需要分开的原因是为了区分支不支持等于号,有了等于号就进入状态3了
三、编码实现
确定的有限状态机中,一个状态中的每一个输入都只对应着一个输出状态,这样子很方便编程实现。
语言版本:C++ 98/03
1. 词法分析
目的:将每一段字符划分为一个词组,同时与其类型都存入一个token对象之中,然后一个语句生成一个或多个token组成token序列。
例子:a + b = 200 + 100 - 1;
这个语句可以切割成10段,分别是:a、+、b、=、200、+、100、-、1、;,将这10段分别标识类型,一起放入一个token序列。本文章分析例子得到token序列如下:
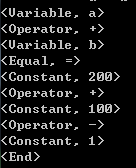
至此,词法分析完成。
头文件lexical_analysis.h源码:
#ifndef LEXICAL_ANALYSIS_H
#define LEXICAL_ANALYSIS_H
#include
#include
// 词性
namespace LexicalType
{
enum LexicalType
{
Operator, // 操作
Constant, // 常数
Variable, // 变量
Equal, // 等于号
UpParentheses, // 上括号
DownParentheses, // 下括号
End, // 语句结束
};
} // namespace SyntaxType
// 词法解析错误码
namespace LexicalCode
{
enum LexicalCode
{
Success, // 成功
UnkownCharacter, // 不明字符
};
} // namespace LexicalCode
struct LexicalAnalysisResult
{
unsigned int row; // 错误行号,解析成功时为0
unsigned int col; // 错误列号,解析成功时为0
LexicalCode::LexicalCode code; // 错误码
}; // struct LexicalAnalysisResult
struct SyntaxToken
{
unsigned int row; // 起始行号
unsigned int col; // 起始列号
LexicalType::LexicalType type;
std::string value;
}; // struct SyntaxToken
typedef std::vector SeqToken;
/*
* 解析操作
* @str 字符串起始地址
* @len 字符串长度
* @out 用于解析后的token队列,如果解析失败,则不改变
* @return 错误信息
*/
extern LexicalAnalysisResult Parse(const char *str, unsigned int len, SeqToken &out);
#endif // LEXICAL_ANALYSIS_H
源文件lexical_analysis.cpp源码:
#include "lexical_analysis.h"
// 判断 v ∈ [low, high]
#define range(low, v, high) ((v) <= (high) && (v) >= (low))
// 判断 v 是否为数字
#define is_digital(v) range('0', v, '9')
// 判断 v 是否为字母
#define is_word(v) range('a', v, 'z') || range('A', v, 'Z')
// 判断 v 是否为空字符
#define is_empty(v) ((v) == ' ' || (v) == '\f' || (v) == '\t' || (v) == '\v')
// 判断 v 是否为2元运算符
#define is_operator2(v) ((v) == '+' || (v) == '-' || (v) == '*' || (v) == '/' || (v) == '^')
// 判断 v 是否为等于号
#define is_equal_symbol(v) ((v) == '=')
// 判断 v 是否为结束符
#define is_end(v) ((v) == ';')
// 判断 v 是否为换行符
#define is_line_end(v) ((v) == '\n')
// 判断 v 是否为变量符号
#define is_algebra(v) (is_word(v) || is_digital(v))
// 判断 v 是否为上括号
#define is_up_parentheses(v) ((v) == '(')
// 判断 v 是否为下括号
#define is_down_parentheses(v) ((v) == ')')
// 判断 v 是否为小数点
#define is_point(v) ((v) == '.')
// 下一行
#define next_col(d, r, c) ++(d);++(c)
// 下一列
#define next_row(d, r, c) ++(d);++(r);c=0
static std::string ParseNumber(const char **str, unsigned int &row, unsigned int &col)
{
const char *cur = *str;
std::string result;
result += *cur;
next_col(cur, row, col);
bool meet_point = false;
while(true)
{
if(is_digital(*cur))
{
result += *cur;
next_col(cur, row, col);
continue;
}
if(is_empty(*cur))
{
next_col(cur, row, col);
continue;
}
if(is_line_end(*cur))
{
next_row(cur, row, col);
continue;
}
if(!meet_point && is_point(*cur))
{
result += *cur;
next_col(cur, row, col);
meet_point = true;
continue;
}
break;
}
*str = cur;
return result;
}
static std::string ParseAlgebra(const char **str, unsigned int &row, unsigned int &col)
{
const char *cur = *str;
std::string result;
result += *cur;
next_col(cur, row, col);
while(true)
{
if(is_algebra(*cur))
{
result += *cur;
next_col(cur, row, col);
continue;
}
if(is_empty(*cur))
{
next_col(cur, row, col);
continue;
}
if(is_line_end(*cur))
{
next_row(cur, row, col);
continue;
}
break;
}
*str = cur;
return result;
}
LexicalAnalysisResult LexicalParse(const char *str, unsigned int len, SeqToken &out)
{
LexicalAnalysisResult result;
result.row = 0;
result.col = 0;
SeqToken token_list;
unsigned int row = 1, col = 1;
const char *cur = str, *end = str + len;
while(cur < end && *cur != '\0')
{
SyntaxToken token;
// 变量
if(is_word(*cur))
{
token.row = row;
token.col = col;
token.type = LexicalType::Variable;
token_list.push_back(token);
std::string s = ParseAlgebra(&cur, row, col);
token_list.back().value.swap(s);
continue;
}
// 数字
if(is_digital(*cur))
{
token.row = row;
token.col = col;
token.type = LexicalType::Constant;
token_list.push_back(token);
std::string s = ParseNumber(&cur, row, col);
token_list.back().value.swap(s);
continue;
}
// 运算符
if(is_operator2(*cur))
{
token.row = row;
token.col = col;
token.type = LexicalType::Operator;
token.value = *cur;
token_list.push_back(token);
next_col(cur, row, col);
continue;
}
// 上括号
if(is_up_parentheses(*cur))
{
token.row = row;
token.col = col;
token.type = LexicalType::UpParentheses;
token.value = *cur;
token_list.push_back(token);
next_col(cur, row, col);
continue;
}
// 下括号
if(is_down_parentheses(*cur))
{
token.row = row;
token.col = col;
token.type = LexicalType::DownParentheses;
token.value = *cur;
token_list.push_back(token);
next_col(cur, row, col);
continue;
}
// 空白符
if(is_empty(*cur))
{
next_col(cur, row, col);
continue;
}
// 等于号
if(is_equal_symbol(*cur))
{
token.row = row;
token.col = col;
token.type = LexicalType::Equal;
token.value = *cur;
token_list.push_back(token);
next_col(cur, row, col);
continue;
}
// 结束符
if(is_end(*cur))
{
token.row = row;
token.col = col;
token.type = LexicalType::End;
token_list.push_back(token);
next_col(cur, row, col);
continue;
}
// 换行
if(is_line_end(*cur))
{
next_row(cur, row, col);
continue;
}
token_list.clear();
result.code = LexicalCode::UnkownCharacter;
break;
}
if(!token_list.empty())
{
out.swap(token_list);
result.code = LexicalCode::Success;
}
return result;
}
2. 语法分析
目的:分析token序列,判断语法是否正常,同时根据token序列生成抽象语法树。
其实上面词法分析所得的token序列也算是一种中缀表达式,借助栈结构可将中缀表达式转化为二叉树(这里就不展开如何转化了)。
如1. 词法分析中的token序列转化为:

头文件syntax_analysis.h源码:
#ifndef SYNTAX_ANALYSIS_H
#define SYNTAX_ANALYSIS_H
#include "lexical_analysis.h"
namespace SyntaxCode
{
enum SyntaxCode
{
Success, // 成功
RepeatEqual, // 等于号重复了
ParenthesesMismatch, // 括号没有封闭
MissingOperator, // 缺失操作数
MissingTerminator, // 缺失结束符
EmptySide, // 等号一边为空
Error,
};
} // namespace SyntaxCode
// 语法树结点
struct SyntaxTreeNode
{
SyntaxTreeNode *left;
SyntaxTreeNode *right;
SyntaxToken value;
};
typedef std::vector SeqTreeNode;
/*
* 释放树结点及其递归子结点的空间
*/
extern void DeallocTreeNode(SyntaxTreeNode *node);
struct SyntaxAnalysisResult
{
unsigned int row;
unsigned int col;
SyntaxCode::SyntaxCode code;
};
/*
* 根据错误码获取错误描述字符串
* @code __in__ 错误码,Parse函数返回值中的errcode
*/
extern const char * ErrorDescribe(SyntaxCode::SyntaxCode code);
/*
* 根据token列表生成抽象语法树
*/
extern SyntaxAnalysisResult ToAST(SeqTreeNode &trees, const SeqToken &token_list);
#endif // SYNTAX_ANALYSIS_H
源文件syntax_analysis.cpp源码:
#include "syntax_analysis.h"
#include
#include
#if __cplusplus >= 201103L
#define null nullptr
#else
#define null 0
#endif
// 判断 v 是否为 空
#define is_null(v) (null == (v))
void DeallocTreeNode(SyntaxTreeNode *node)
{
if(is_null(node))
{ return; }
std::queue qn;
qn.push(node);
while(!qn.empty())
{
node = qn.front();
qn.pop();
if(!is_null(node->left))
{ qn.push(node->left); }
if(!is_null(node->right))
{ qn.push(node->right); }
delete node;
}
}
const char * ErrorDescribe(SyntaxCode::SyntaxCode code)
{
switch(code)
{
case SyntaxCode::Success:
return "Success";
case SyntaxCode::RepeatEqual:
return "Repeat equal";
case SyntaxCode::ParenthesesMismatch:
return "Parentheses mismatch";
case SyntaxCode::MissingOperator:
return "Missing operator";
case SyntaxCode::MissingTerminator:
return "Missing terminator";
case SyntaxCode::EmptySide:
return "Empty side";
case SyntaxCode::Error:
return "Unkown error";
}
return "";
}
static SyntaxToken AllocEmptyToken()
{
SyntaxToken result;
result.type = LexicalType::Constant;
result.value = "0";
return result;
}
static SyntaxTreeNode* AllocTreeNode()
{
SyntaxTreeNode *node = new SyntaxTreeNode;
node->left = null;
node->right = null;
return node;
}
static int GetPriority(const std::string &s)
{
if(s == "=") return 0; // 等于号
if(s == "+" || s == "-") return 1; // 加减
if(s == "*" || s == "/") return 2; // 乘除
if(s == "^") return 9; // 指数
if(s == "(") return 10; // 括号
return -1;
}
static int CompPriority(const std::string &s1, const std::string &s2)
{
return GetPriority(s1) - GetPriority(s2);
}
static void ClearSeqTreeNode(SeqTreeNode &trees)
{
for(SeqTreeNode::iterator it = trees.begin(); it != trees.end(); ++it)
{
DeallocTreeNode(*it);
}
trees.clear();
}
class SyntaxTreeParser
{
enum SyntaxParseState
{
PS1,
PS2,
PS3,
PS4,
End,
Invalid
}; // enum SyntaxParseState
public:
SyntaxTreeNode* Parse(SeqToken::const_iterator &beg,
SeqToken::const_iterator end,
SyntaxAnalysisResult &result);
~SyntaxTreeParser();
private:
void HandleTop();
SyntaxParseState P1();
SyntaxParseState P2();
SyntaxParseState P3();
SyntaxParseState P4();
private:
std::stack _M_oper_stack;
std::stack _M_arg_stack;
SeqToken::const_iterator _M_end;
SeqToken::const_iterator *_M_cur;
SyntaxAnalysisResult *_M_result;
unsigned int _M_parentheses_layer;
};
SyntaxTreeParser::~SyntaxTreeParser()
{
while(!_M_arg_stack.empty())
{
DeallocTreeNode(_M_arg_stack.top());
_M_arg_stack.pop();
}
}
void SyntaxTreeParser::HandleTop()
{
SyntaxTreeNode *tmp = AllocTreeNode();
tmp->value = _M_oper_stack.top();
_M_oper_stack.pop();
tmp->right = _M_arg_stack.top();
_M_arg_stack.pop();
tmp->left = _M_arg_stack.top();
_M_arg_stack.pop();
_M_arg_stack.push(tmp);
}
SyntaxTreeNode* SyntaxTreeParser::Parse(
SeqToken::const_iterator &beg,
SeqToken::const_iterator end,
SyntaxAnalysisResult &result)
{
typedef SyntaxParseState(SyntaxTreeParser::*ParseFunc)();
static ParseFunc pf[] =
{
&SyntaxTreeParser::P1,
&SyntaxTreeParser::P2,
&SyntaxTreeParser::P3,
&SyntaxTreeParser::P4
};
while(!_M_oper_stack.empty())
{ _M_oper_stack.pop(); }
while(!_M_arg_stack.empty())
{
DeallocTreeNode(_M_arg_stack.top());
_M_arg_stack.pop();
}
_M_parentheses_layer = 0;
_M_cur = &beg;
_M_end = end;
_M_result = &result;
_M_result->row = 0;
_M_result->col = 0;
_M_result->code = SyntaxCode::Success;
SyntaxParseState state = SyntaxParseState::PS1;
for(; (*_M_cur) != _M_end; ++(*_M_cur))
{
state = (this->*pf[state])();
if(state == SyntaxParseState::Invalid)
{
_M_result->row = (*_M_cur)->row;
_M_result->col = (*_M_cur)->col;
return null;
}
if(state == SyntaxParseState::End)
{ break; }
}
if(state != SyntaxParseState::End && _M_result->code == SyntaxCode::Success && (*_M_cur) == _M_end)
{
_M_result->code = SyntaxCode::MissingTerminator;
--(*_M_cur);
_M_result->row = (*_M_cur)->row;
_M_result->col = (*_M_cur)->col;
return null;
}
SyntaxTreeNode *node = _M_arg_stack.top();
_M_arg_stack.pop();
return node;
}
SyntaxTreeParser::SyntaxParseState SyntaxTreeParser::P1()
{
switch((*_M_cur)->type)
{
case LexicalType::Operator:
// + - 可以用于表示正负号,在其前面补一个常数0
if((*_M_cur)->value == "+" || (*_M_cur)->value == "-")
{
SyntaxTreeNode *tmp = AllocTreeNode();
tmp->value = AllocEmptyToken();
tmp->value.row = (*_M_cur)->row;
tmp->value.col = (*_M_cur)->col;
_M_arg_stack.push(tmp);
_M_oper_stack.push(**_M_cur);
return SyntaxParseState::PS1;
}
else
{
_M_result->code = SyntaxCode::MissingOperator;
return SyntaxParseState::Invalid;
}
break;
case LexicalType::Constant:
case LexicalType::Variable:
{
SyntaxTreeNode *tmp = AllocTreeNode();
tmp->value = **_M_cur;
_M_arg_stack.push(tmp);
return SyntaxParseState::PS2;
}
case LexicalType::UpParentheses:
_M_oper_stack.push(**_M_cur);
++_M_parentheses_layer;
return SyntaxParseState::PS1;
default:
_M_result->code = SyntaxCode::MissingTerminator;
return SyntaxParseState::Invalid;
}
}
SyntaxTreeParser::SyntaxParseState SyntaxTreeParser::P2()
{
switch((*_M_cur)->type)
{
case LexicalType::Operator:
// 优先级不足,先构建前面的树枝
if(!_M_oper_stack.empty() &&
_M_oper_stack.top().type != LexicalType::UpParentheses &&
CompPriority((*_M_cur)->value, _M_oper_stack.top().value) <= 0)
{
HandleTop();
}
_M_oper_stack.push(**_M_cur);
return SyntaxParseState::PS1;
case LexicalType::Equal:
// 括号不匹配
if(_M_parentheses_layer != 0)
{
_M_result->code = SyntaxCode::ParenthesesMismatch;
return SyntaxParseState::Invalid;
}
// 等号一边为空
if(_M_arg_stack.empty())
{
_M_result->code = SyntaxCode::EmptySide;
return SyntaxParseState::Invalid;
}
while(!_M_oper_stack.empty())
{
HandleTop();
}
_M_oper_stack.push(**_M_cur);
return SyntaxParseState::PS3;
case LexicalType::DownParentheses:
if(_M_parentheses_layer == 0)
{
_M_result->code = SyntaxCode::ParenthesesMismatch;
return SyntaxParseState::Invalid;
}
while(!_M_oper_stack.empty())
{
if(_M_oper_stack.top().type == LexicalType::UpParentheses)
{
_M_oper_stack.pop();
break;
}
HandleTop();
}
--_M_parentheses_layer;
return SyntaxParseState::PS2;
case LexicalType::End:
{
if(_M_parentheses_layer == 0)
{
_M_result->code = SyntaxCode::ParenthesesMismatch;
return SyntaxParseState::Invalid;
}
HandleTop();
}
return SyntaxParseState::End;
default:
_M_result->code = SyntaxCode::MissingTerminator;
return SyntaxParseState::Invalid;
}
}
SyntaxTreeParser::SyntaxParseState SyntaxTreeParser::P3()
{
switch((*_M_cur)->type)
{
case LexicalType::Operator:
// + - 可以用于表示正负号,在其前面补一个常数0
if((*_M_cur)->value == "+" || (*_M_cur)->value == "-")
{
SyntaxTreeNode *tmp = AllocTreeNode();
tmp->value = AllocEmptyToken();
tmp->value.row = (*_M_cur)->row;
tmp->value.col = (*_M_cur)->col;
_M_arg_stack.push(tmp);
_M_oper_stack.push(**_M_cur);
return SyntaxParseState::PS3;
}
else
{
_M_result->code = SyntaxCode::MissingOperator;
return SyntaxParseState::Invalid;
}
break;
case LexicalType::Constant:
case LexicalType::Variable:
{
SyntaxTreeNode *tmp = AllocTreeNode();
tmp->value = **_M_cur;
_M_arg_stack.push(tmp);
return SyntaxParseState::PS4;
}
case LexicalType::UpParentheses:
_M_oper_stack.push(**_M_cur);
++_M_parentheses_layer;
return SyntaxParseState::PS3;
case LexicalType::End:
if(!_M_oper_stack.empty() && _M_oper_stack.top().type == LexicalType::Equal)
{
_M_result->code = SyntaxCode::EmptySide;
return SyntaxParseState::Invalid;
}
default:
_M_result->code = SyntaxCode::MissingTerminator;
return SyntaxParseState::Invalid;
}
}
SyntaxTreeParser::SyntaxParseState SyntaxTreeParser::P4()
{
switch((*_M_cur)->type)
{
case LexicalType::Operator:
// 优先级不足,先构建前面的树枝
if(_M_oper_stack.top().type != LexicalType::UpParentheses &&
CompPriority((*_M_cur)->value, _M_oper_stack.top().value) <= 0)
{
HandleTop();
}
_M_oper_stack.push(**_M_cur);
return SyntaxParseState::PS3;
case LexicalType::Equal:
_M_result->code = SyntaxCode::RepeatEqual;
return SyntaxParseState::Invalid;
case LexicalType::DownParentheses:
if(_M_parentheses_layer == 0)
{
_M_result->code = SyntaxCode::ParenthesesMismatch;
return SyntaxParseState::Invalid;
}
while(!_M_oper_stack.empty())
{
if(_M_oper_stack.top().type == LexicalType::UpParentheses)
{
_M_oper_stack.pop();
break;
}
HandleTop();
}
--_M_parentheses_layer;
return SyntaxParseState::PS4;
case LexicalType::End:
if(_M_parentheses_layer != 0)
{
_M_result->code = SyntaxCode::ParenthesesMismatch;
return SyntaxParseState::Invalid;
}
while(!_M_oper_stack.empty())
{
HandleTop();
}
return SyntaxParseState::End;
default:
_M_result->code = SyntaxCode::MissingTerminator;
return SyntaxParseState::Invalid;
}
}
SyntaxAnalysisResult ToAST(SeqTreeNode &trees, const SeqToken &token_list)
{
SyntaxAnalysisResult result;
result.row = 0;
result.col = 0;
result.code = SyntaxCode::Success;
SyntaxTreeParser parser;
for(SeqToken::const_iterator it = token_list.begin(); it != token_list.end(); ++it)
{
SyntaxTreeNode *node = parser.Parse(it, token_list.end(), result);
if(is_null(node) || result.code != SyntaxCode::Success)
{
ClearSeqTreeNode(trees);
result.row = it->row;
result.col = it->col;
break;
}
trees.push_back(node);
}
return result;
}
四、测试案例
#include
#include
#include "lexical_analysis.h"
#include "syntax_analysis.h"
template
static void PrintToken(_Stream &s, const SyntaxToken &token)
{
switch(token.type)
{
case LexicalType::Operator:
s << "";
break;
case LexicalType::Constant:
s << "";
break;
case LexicalType::Variable:
s << "";
break;
case LexicalType::Equal:
s << "";
break;
case LexicalType::UpParentheses:
s << "";
break;
case LexicalType::DownParentheses:
s << "";
break;
case LexicalType::End:
s << "";
break;
default:
s << "";
break;
}
}
template
static void PrintTokens(_Stream &s, const SeqToken &token_list)
{
for(SeqToken::const_iterator it = token_list.begin(); it != token_list.end(); ++it)
{
PrintToken<_Stream>(s, *it);
s << "\n";
}
}
template
static void PutSpace(_Stream &s, unsigned int count)
{
while(count-- > 0)
{
s << ' ';
}
}
template
static void PrintTree(_Stream &s, const SyntaxTreeNode *node)
{
std::stack nodeq;
std::stack layerq;
nodeq.push(node);
layerq.push(0);
while(!nodeq.empty())
{
unsigned int layer = layerq.top();
layerq.pop();
node = nodeq.top();
nodeq.pop();
PutSpace<_Stream>(s, layer * 2);
PrintToken<_Stream>(s, node->value);
s << "\n";
if(NULL != node->right)
{
nodeq.push(node->right);
layerq.push(layer + 1);
}
if(NULL != node->left)
{
nodeq.push(node->left);
layerq.push(layer + 1);
}
}
}
template
static void PrintTrees(_Stream &s, const SeqTreeNode &node_list)
{
for(SeqTreeNode::const_iterator it = node_list.begin(); it != node_list.end(); ++it)
{
PrintTree<_Stream>(s, *it);
}
}
// 正确示范
static std::string str1 = "10 + 20 * (1 + b) = a;";
static std::string str2 = "a + b - 5 * (e + f / 10) = g;";
static std::string str3 = "a + b - 5 * ((e + f) / 10) = g;";
// 错误示范
static std::string str4 = "1 + 1 = 2";
static std::string str5 = "a + 200b = c;";
static std::string str6 = "a + c - (d - e));";
static std::string str7 = "a + c - ((d - e))=;";
static std::string str8 = "1 + 1 = a = b;";
static void Proc(const std::string &str)
{
std::cout << "===========" << str << "===========" << std::endl;
SeqToken token_list;
LexicalAnalysisResult result = LexicalParse(str.c_str(), str.size(), token_list);
if(result.code != LexicalCode::Success)
{
return;
}
PrintTokens(std::cout, token_list);
std::cout << std::endl;
SeqTreeNode trees;
SyntaxAnalysisResult sa_result = ToAST(trees, token_list);
if(sa_result.code != SyntaxCode::Success)
{
std::cout << ErrorDescribe(sa_result.code) << " at row: " << sa_result.row << " col: " << sa_result.col << std::endl;
}
else
{
PrintTrees(std::cout, trees);
}
std::cout << std::endl;
}
int main()
{
Proc(str1);
Proc(str2);
Proc(str3);
Proc(str4);
Proc(str5);
Proc(str6);
Proc(str7);
Proc(str8);
return 0;
}
输出结果:

代码未经优化,如有问题,欢迎指出!