Bilinear CNN:细粒度图像分类网络,对Bilinear CNN中矩阵外积的解释。
文章目录
-
- 一、Bilinear CNN 的网络结构
- 二、矩阵外积(outer product)
-
- 2.1 外积的计算方式
- 2.2 外积的作用
- 三、PyTorch 网络代码实现
细粒度图像分类(fine-grained image recognition)的目的是区分类别的子类,如判别一只狗子是哈士奇还是柴犬。细粒度图像分类可以分为基于强监督信息(图像类别、物体标注框、部位标注点等)和基于弱监督信息(只有图像类别),具体可以参考 细粒度图像分类
Bilinear CNN 是2015在论文 《Bilinear CNN Models for Fine-grained Visual Recognition》中提出来的,是一种基于弱监督信息的细粒度图像分类模型。
一、Bilinear CNN 的网络结构
Bilinear CNN 的网络结构如下:
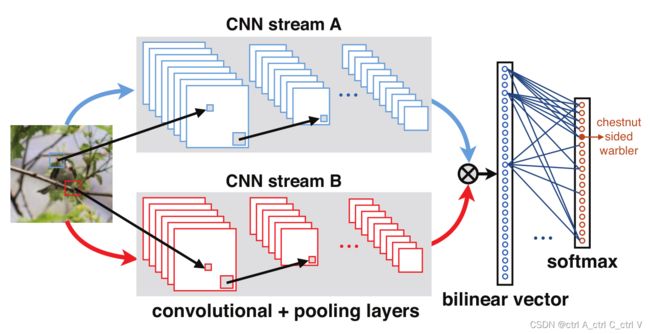
Bilinear CNN 由两个 CNN 特征提取网络组成,它们的输出做外积(outer product)获得双线性向量(可称为图像描述符 image descriptor),再进行分类。
需要注意的是两个 CNN 其实是完全相同的,代码中用的就是一个网络(一般用预训练的 vgg16 或 ResNet18 网络),只是对网络输出值 x 计算了 x 和 xT 的矩阵乘积实现特征交互。
当然也可以使用两个不同的 CNN 网络。
双线性网络用于模拟图像的双因素变化。有一种说法是:网络A的作用是对图像中对象的特征部位进行定位,网络B则是用来对网络A检测到的特征区域进行特征提取。两个网络相互协调作用,实现细粒度图像分类。但如果用一个网络来实现,这种说法也太荒谬了。
由于模型对两个 CNN 的输出的操作是线性的(矩阵相乘是线性运算,因为只有加法和乘法操作),所以网络称为 bilinear CNNs。
二、矩阵外积(outer product)
2.1 外积的计算方式
网上很多博客说 矩阵外积就是克罗内克积,但是Bilinear CNN代码实现中的外积其实就是普通的矩阵相乘(就是线性代数中最常规的矩阵相乘),并非克罗内克积。
代码可见本文第三部分“PyTorch 网络代码实现”。
计算外积的代码为:
x = torch.bmm(x, torch.transpose(x, 1, 2)) / (28 * 28)
这里的 torch.bmm(a,b) 就是普通的矩阵相乘,举个例子证明:
import torch
a = torch.randint(low=0, high=5, size=(1, 2, 2))
b = torch.randint(low=0, high=5, size=(1, 2, 2))
c = torch.bmm(a, b)
print(f"a = {a}")
print(f"b = {b}")
print(f"c = {c}")
"""
a = tensor([[[4, 0],
[4, 1]]])
b = tensor([[[1, 4],
[2, 4]]])
c = tensor([[[ 4, 16], 4 = 4 * 1 + 0 * 2, 16 = 4 * 4 + 0 * 4
[ 6, 20]]]) 6 = 4 * 1 + 1 * 2, 20 = 4 * 4 + 1 * 4
"""
如果这个版本的 PyTorch 代码没有错误的话,这里的外积就是普通的矩阵相乘。当然我没有看 Bilinear CNN 的 Matlab 源码,源码地址为 Bilinear CNNs for Fine-grained Visual Recognition,欢迎大家批评指正(对于内积外积我也没分清楚)。
2.2 外积的作用
外积其实只是一种特征融合的方式,其他常用的特征融合方法还有:最大值融合、平均值融合、相加、concat 等。
但外积可以通过矩阵运算捕捉不同通道之间的特征相关性。由于描述向量的不同维度对应卷积特征的不同通道,而不同通道提取了不同的语义特征,因此,通过双线性操作,可以同时捕获输入图像的不同语义特征之间的关系。
三、PyTorch 网络代码实现
基于 vgg16:
import torch
import torch.nn as nn
import torchvision
class BCNN_fc(nn.Module):
def __init__(self):
super(BCNN_fc, self).__init__()
# VGG16的卷积层和池化层
self.features = torchvision.models.vgg16(pretrained=True).features
# 去除最后一个 pooling 层
self.features = nn.Sequential(*list(self.features.children())[:-1])
# 线性分类层
self.fc = nn.Linear(512 * 512, 200)
# 冻结以前的所有层
for param in self.features.parameters():
param.requres_grad = False
# 初始化fc层
nn.init.kaiming_normal_(self.fc.weight.data)
if self.fc.bias is not None:
nn.init.constant_(self.fc.bias.data, val=0)
def forward(self, x):
N = x.size()[0]
assert x.size() == (N, 3, 448, 448)
# 特征提取
x = self.features(x)
assert x.size() == (N, 512, 28, 28)
x = x.view(N, 512, 28 * 28)
# 双线性矩阵相乘
# 对于 c=torch.bmm(a,b),其中 a.shape=[b,m,n], b.shape=[b,n,p], 则 c.shape=[b,m,p]
# 这里其实是对 x 和 x^T 进行了相乘
# 除以 28 * 28 是为了防止最后 softmax 的梯度过小
x = torch.bmm(x, torch.transpose(x, 1, 2)) / (28 * 28)
assert x.size() == (N, 512, 512)
# 有符号平方根,y = sign(x) * sqrt(|x|)
x = torch.sign(x) * torch.sqrt(torch.abs(x) + 1e-10)
x = x.view(N, 512 * 512)
assert x.size() == (N, 512 * 512)
# L2归一化
x = torch.nn.functional.normalize(x)
assert x.size() == (N, 512 * 512)
# 全连接分类层
x = self.fc(x)
assert x.size() == (N, 200)
return x
if __name__ == '__main__':
input = torch.randn(16, 3, 448, 448)
model = BCNN_fc()
output = model(input)
print(output.shape) # torch.Size([16, 200])
基于 ResNet18:
import torch
import torch.nn as nn
from torchvision.models import resnet18
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.features = nn.Sequential(resnet18().conv1,
resnet18().bn1,
resnet18().relu,
resnet18().maxpool,
resnet18().layer1,
resnet18().layer2,
resnet18().layer3,
resnet18().layer4)
self.classifiers = nn.Sequential(nn.Linear(512**2,14))
def forward(self,x):
x=self.features(x)
batch_size = x.size(0)
feature_size = x.size(2)*x.size(3)
x = x.view(batch_size , 512, feature_size)
x = (torch.bmm(x, torch.transpose(x, 1, 2)) / feature_size).view(batch_size, -1)
x = torch.nn.functional.normalize(torch.sign(x)*torch.sqrt(torch.abs(x)+1e-10))
x = self.classifiers(x)
return x