python:异常处理与文件操作(知识点详解+代码展示)
文章目录
- 一、异常处理
-
- 1、try...except语句
- 2、finally语句
- 二、断言
-
- 1、定义
- 2、举例
-
- 例一:
- 例二:
- 三、文件操作
-
- 1、写文件操作
- 2、读文件操作
学习目标:
1、掌握异常处理的方法
2、掌握断言的使用
3、掌握打开文件、读文件和写文件的方法
一、异常处理
引言:我们在java中也学过相关异常处理机制,那这里的异常处理与Java是否相同呢?
python语言编写代码时,会出现三种错误——语法错误、语义错误和运行时错误。那我们对这些错误,有何应对措施?
答:我们先要知道何为异常,异常就是运行过程中可能会出现导致代码不正常运行的问题。对此,我们需要先要捕捉异常(即为先找到异常在哪里),之后如果再次运行到异常时,应该做出什么响应。
有些人可能会有疑惑,既然知道有异常,那么为什么不一开始就解决。当我们写就几十行代码时候,还好发现错误,那如果我们写几百行,或者上千行时候,如果此时运行错误,是很难发现的,并且一出现异常,我们整个代码就会断掉,如果引入处理机制,那么程序则会正常运行。
那么异常处理机制就是给出错误提示,并且提出修改建议的机制。
1、try…except语句
(1)格式
try:
<语句块1> #这里写可能出错的代码
except<异常>: #这里的异常可写可不写
<语句块2> #如果遇到该异常时候,给出提示
(2)实例
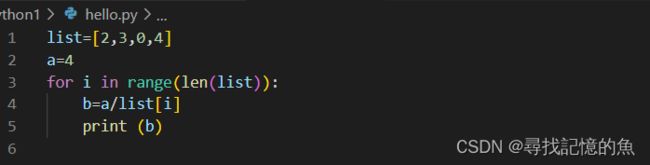
大家看上面的代码,我的vscode软件并未识别到错误,现在来运行一下。
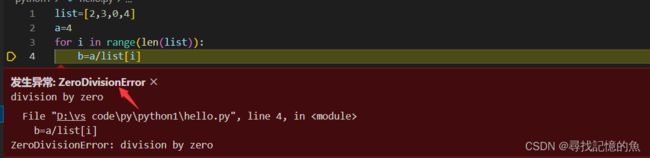
这里出现了分母为0的运算,出现了 ZeroDivisionError异常,那么如何改动让我们知道这里出错了呢。
修改:
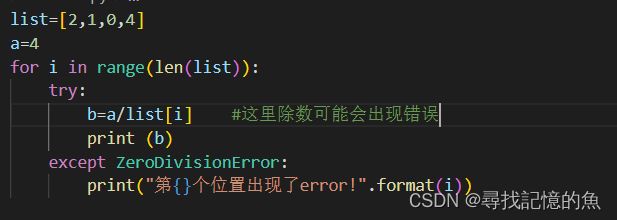
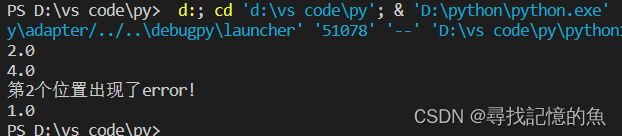
那么此时就达到我们想要的结果,既能正常运行,又能报错!
(3)多异常
如果出现多个异常,应该如何,我们约定,在出现多个异常时候,则需要用异常名来区分;
看代码:
list=[2,1,0,4]
a=4
for i in range(5):
try:
b=a/list[i] #这里除数可能会出现错误
print (b)
except ZeroDivisionError:
print("第{}个位置出现了error!".format(i))
except IndexError:
print("已超出列表范围!")

2、finally语句
我们还需要考虑一种情况,当try中语句没有正常执行完毕时,那么可能会导致其他错误,因而还要给异常机制加一个善后功能,使用finally语句,无论前面执行怎么样,最后一定要走finally语句。finally语句包含的代码块通常是用来释放try语句块所占用的各类计算机资源,防止资源耗尽,导致整个计算机系统崩溃。
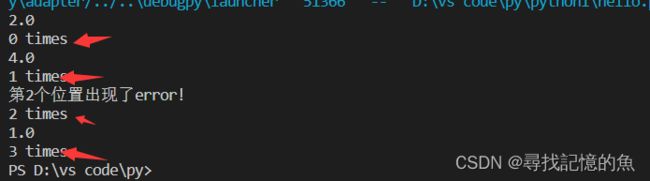
来看代码:
list=[2,1,0,4]
a=4
for i in range(4):
try:
b=a/list[i] #这里除数可能会出现错误
print (b)
except ZeroDivisionError:
print("第{}个位置出现了error!".format(i))
finally:
print("%d times"%i)
二、断言
1、定义
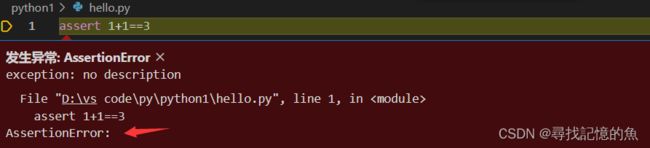
(1)书中:我们不知道程序会在哪里出错,与其让他运行时候崩溃,不如在出现错误条件时,就让他崩溃,这时候就需要assert断言的帮助。
可能不是很好理解,我是这么理解的,assert断言是相当于“及时止损”的作用,这里的assert断言就相当于代码的“朋友”,代码犯了错误,作为“朋友”的assert断言,就要阻止他,不要让代码再“执迷下去”。
(2)规则:如果断言成功(即为无错时),则不采取任何措施;否则就触发AssertionError(断言错误)的异常。
2、举例
例一:
例二:
list=[2,1,0,4]
a=4
assert len(list)>=5 #这里来判断list的长度是否大于等于5,符合就继续执行
for i in range(5):
try:
b=a/list[i] #这里除数可能会出现错误
print (b)
except ZeroDivisionError:
print("第{}个位置出现了error!".format(i))
finally:
print("%d times"%i)

三、文件操作
一个完整的文件操作步骤为:
- 打开文件
- 读文件或写文件
- 关闭文件
注意:我们来写一个文件路径时,通常用“/”来隔开
如:C:/list/list1
因为python中转义字符是用“\”来定义,这样可以区分两者,避免歧义性。
1、写文件操作
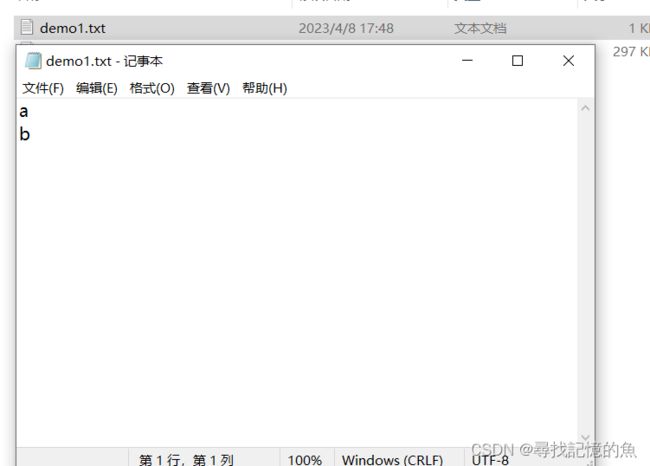
(1)a:
# 写文件操作
wFile=open("E:/demo1.txt",'w')
wFile.write("a\n")
wFile.write("b\n")
wFile.close()
b:
# 写文件操作
wFile=open("E:/demo1.txt",'w')
wFile.write("a")
wFile.write("b")
wFile.close()
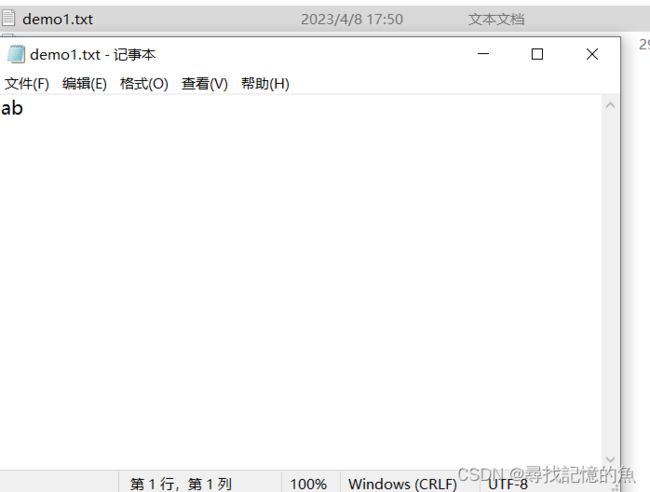
总结1:我们通过这两个代码了解到了两个性质:
1、写文件操作不会跳行,必须加入“\n”。
2、第一个写的文件,如果再次写的时候,会对第一个的文件内容就像覆盖(即为每次写的文件都不同)。
(2)那么我们应该如何写代码才能再前面的文件内容继续写呢?
这时候就引入了append,我们以'a'的方式打开,即为追加。
注意:以'a'来打开文件时候,如果没有此文件,则会自动创建该文件。
# 写文件操作
wFile=open("E:/demo1.txt",'a')
wFile.write("c")
wFile.write("d")
wFile.close()

2、读文件操作
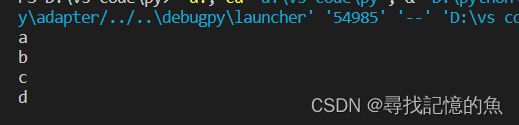
(1)用read函数是读取全部
# 读文件操作
rfile=open("E:/demo1.txt",'r')
text=rfile.read()
rfile.close()
print(text)
(2)用readline是读取行
# 读文件操作
rfile=open("E:/demo1.txt",'r')
line1=rfile.readline()
line2=rfile.readline()
rfile.close()
print(line1)
print(line2)
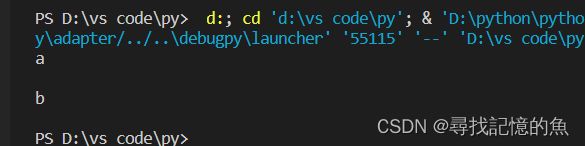
调用一次就列出第一行,调用2次,则列出前两行,以此类推。
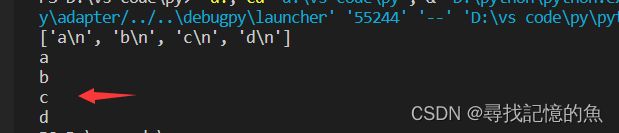
(3)用readlines调用所有行
注意:读取行时,默认为跳行来输出,如果不需要跳行,则要调用replace()来输出;
# 读文件操作
rfile=open("E:/demo1.txt",'r')
line2=rfile.readlines()
print(line2)
for lines in line2:
lines=lines.replace('\n','')
print(lines)
总结:对于一个文件要有open与close,不能光开不关,这样子会导致下次运行时候,出错。