STL——string(二)
目录
string类迭代器
遍历数组
反向遍历
const迭代器
[ ]重载
at
back&&front
insert
erase
replace
string::swap
c_str
find
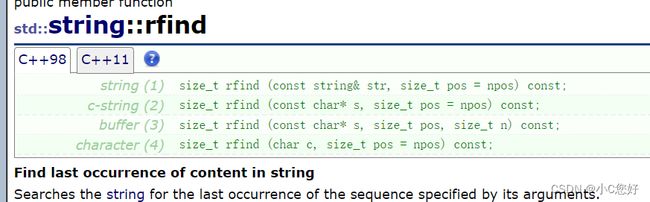
rfind
find_last_of
运算符重载
前面我们简单介绍了string的一些常用成员函数,今天我们接着选择性地讲解string类,不常用的不代表没用,我们得知道,常用的是必须掌握的。
string类迭代器

遍历数组
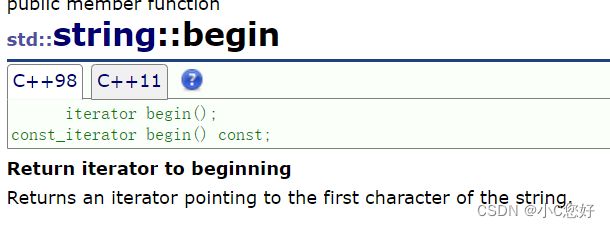
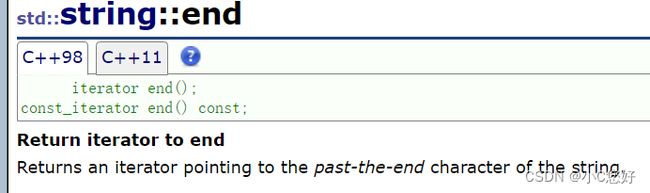 除了用size()遍历数组,这里我简单介绍一下用迭代器访问数组每个元素的操作,也为我们后面的学习做铺垫。
除了用size()遍历数组,这里我简单介绍一下用迭代器访问数组每个元素的操作,也为我们后面的学习做铺垫。
string a("hello world");
string::iterator it = a.begin();
while (it != a.end())
{
cout << *it << " ";
++it;
}
cout << endl;iterator作为一个独立的类型,需要指定string::才能被解析成string内部的迭代器。这里的begin和end我们先肤浅地理解为指针,大概像下图这个样子。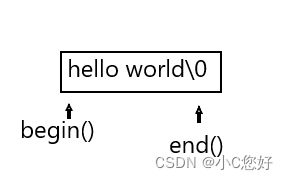
除了用这种方式,我们还可以用范围for,底层还是迭代器。
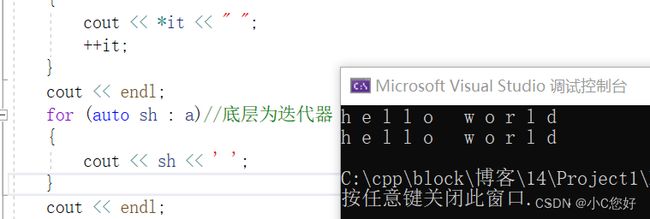
反向遍历
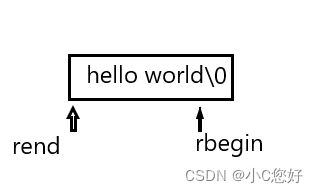
反向遍历通过反向迭代器的方式实现,这里我们使用rbegin和rend。
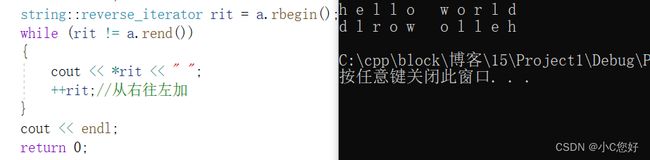
遍历结构应该是这样:
const迭代器
顾名思义,const迭代器用于返回const对象,我们遍历数组的时候因为不涉及改动对象就可以加上const。
void Func(const string& s)
{
string::const_iterator it = s.begin();//只能读不能写
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}此时名称发生了变化,注意这里的const有一个下划线,是一个名称不是一个关键字,真正被const修饰的是对象,而不是 it(begin的返回值)
const正向迭代器声明:
const_iterator begin() const;//修饰this指针我们也可以这样理解:
const int* p;//指向的对象不能改变反向迭代器也同理。
如果觉得麻烦,可以使用auto自动推导类型: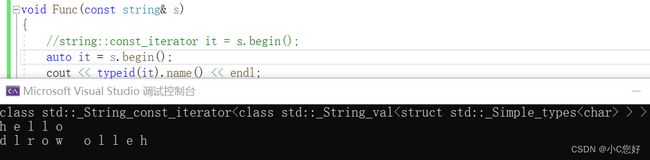
这里auto推导的类型为对象返回类型,这里我们定义的是const类型的对象。
为了区分const和普通迭代器,string类添加了这样的函数:

用法基本一致,大家可按照自己的规范去使用。

[ ]重载

注意区分const和普通对象
迭代器看起起来没有直接用[ ]重载来的方便,但他的出现能解决以后一些很复杂的数据结构,希望大家对此有个清晰的认识。
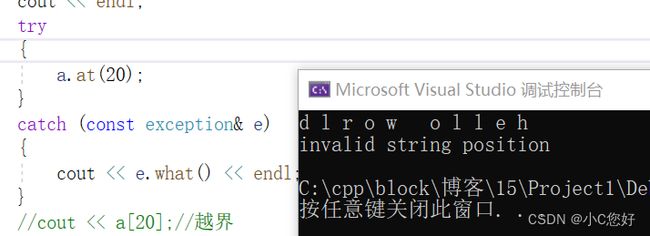
at

与[ ] 不同的是对越界的检查,前者是assert,后者是抛出异常的方式,我们可以通过捕获的方式发现异常。
back&&front
back和front是返回string数组的第一个和最后一个元素(不包括\0)

insert
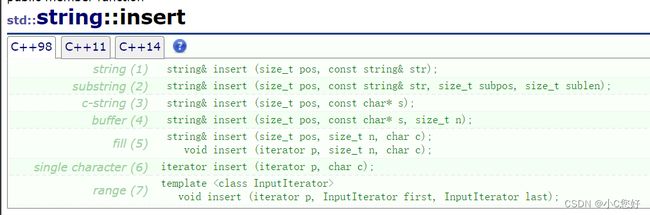
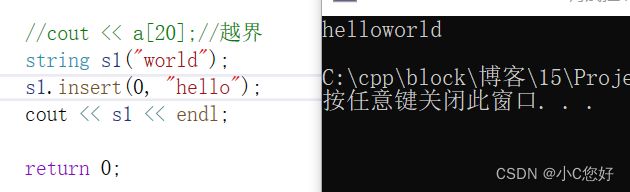
我们简单写几个insert实例
c-string (3) string& insert (size_t pos, const char* s);意为在第pos个位置插入字符串(数组下标)
string& insert (size_t pos, size_t n, char c);意为在第pos个位置插入n个字符c

iterator insert (iterator p, char c); 迭代器插入:
一般情况下我们不推荐使用insert插入数据,结合数据结构的知识,我们知道插入是需要移动空间并提高复杂程度的,需要时可以查文档使用。
erase
与insert相对的就是erase,删除元素。
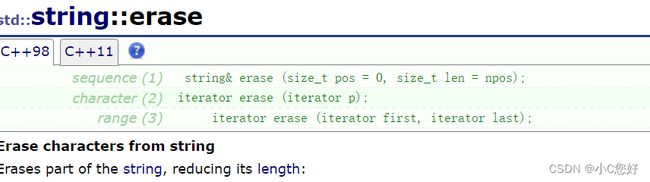
这里我们介绍前面两个:
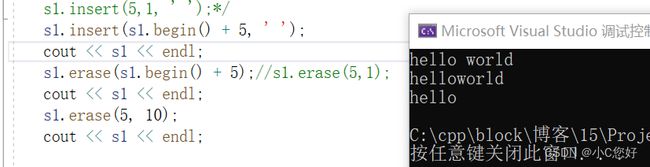
迭代器单参可以删除pos位置的一个元素。如果删除长度len大于数组自身长度,就会删除其后的所有元素。同样地,erase也不推荐经常使用。
replace
replace能替换指定位置的字符或字符串,但使用replace有两个弊端,第一是空间不够需要扩容,其次是需要挪动数据。我们举个填充字符串中的空格的例子来看一下replace的常用用法。
在这之前,我们需要引入find来查找空格的位置:
size_t find (char c, size_t pos = 0) const;遍历string,我们可以用string::npos(静态成员)的方式循环:

意为匹配失败则返回-1(整形的最大值)
用到的replace:
string& replace (size_t pos, size_t len, const char* s);意为用字符串替换第pos个位置的后len个字符。
这里我们用reserve进行提前开空间,避免了扩容重新分配空间和复制内容的消耗。接着我们用循环来遍历string,因为填充后的内容早已不是空格,为了避免无用的查找,我们直接跳过该字符串,提升了查找的效率。
string s2("i love you more than you will ever know");
size_t num = 0;
for (auto ch : s1)
{
if (ch == ' ')
{
num++;
}
}
//提前开空间,避免扩容
s2.reserve(s2.size() + 2 * num);
size_t i = s2.find(' ');
while (i != string::npos)
{
s2.replace(i, 1, "%20");
i = s2.find(' ',i+3);
}输出结果:

虽然经过了细致的处理,但还是少不了数据的移动,这里我们简单介绍一下空间换时间的做法:
string New_s2;
New_s2.reserve(s2.size() + 2 * num);
for (auto ch : s2)
{
if (ch != ' ')
New_s2 += ch;
else
New_s2 += "%20";
}
s2 = New_s2;
cout << New_s2 << endl;string::swap

为什么要在前面特别写出string类域呢?那是因为在std中也有一个类模板的swap函数,但是用法不同,那他们的差别在哪呢?
效率对比:
string中的swap交换只需改变指针的指向,就能实现元素的交换。而类模板的swap涉及深拷贝,其实现逻辑可能更为复杂,之后我们会谈到。
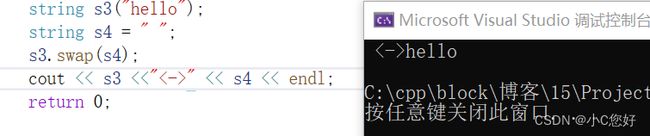
c_str
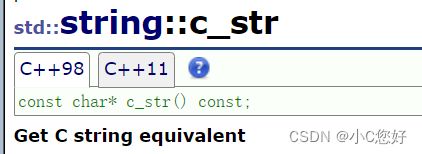
这个接口的出现主要是为了兼容c风格返回的字符串,什么意思呢,我们举例说明。
可以看到第一次打印并没什么区别,第二次s3遇到\0没有终止继续输出后面的内容,而c_str结束了打印。在c语言中,\0作为char*类型的结束的标志,而c_str继承了这一特性,以常量指针的方式记录string的值,而直接使用重载了cout的string则会输出它全部的size大小,不需要管\0是否存在。
当我们在使用c的接口打开string类型的文件名时,为了区分c++的接口,需要用到这个c接口。
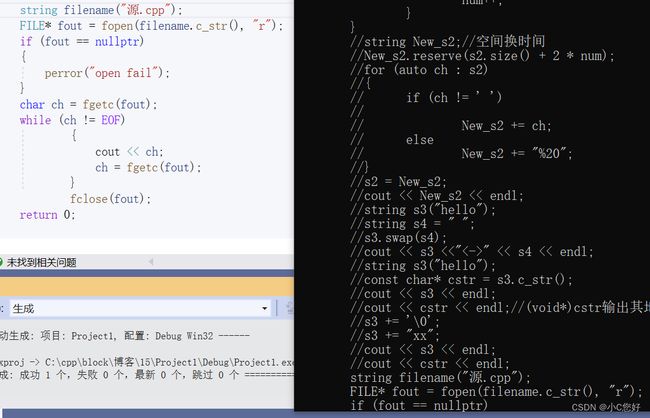
成功读取内容
find
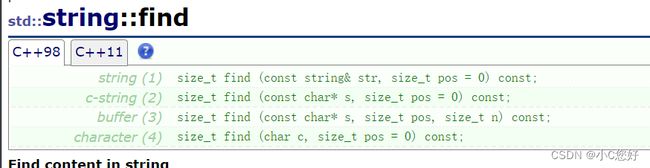
可以看到,find能查找常量字符串,string类型和单个字符。
我们以查找文件后缀为例讲解
这里我们用到substr接口来保存后缀名

用法就是保留第pos个位置后npos个字符串。
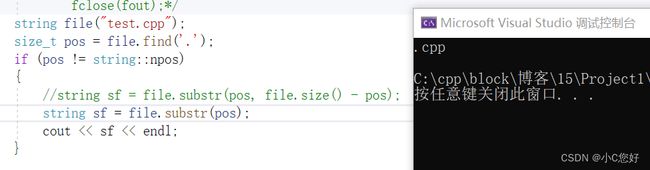
这里可以直接用substr的缺省npos,直接取到 .后到文件名结束。
思考如果有多个后缀想取它真实的后缀(最后一个后缀)怎么办呢?
除了有find接口,string还提供了rfind接口,意为反向查找。
rfind
利用npos从最后一个向前找的功能,我们可以这样修改代码:
string file("test.cpp.zip");
size_t pos = file.rfind('.');
if (pos != string::npos)
{
string sf = file.substr(pos);
cout << sf << endl;
}下面有一段查找网址的代码,大家可以自行领悟
string url("http://www.cplusplus.com/reference/string/string/find/");
cout << url << endl;
size_t start = url.find("://");
if (start == string::npos)
{
cout << "invalid url" << endl;
}
else
{
start += 3;
size_t end = url.find('/', start);
string address = url.substr(start,end-start);
cout << address << endl;
}find_fisrt_of
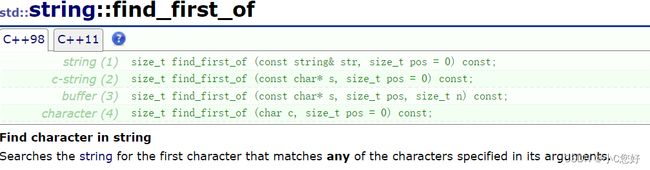
注意这里的first容易被误解成查找第一个字符串,实际他是将查找出现的任何字符或字符串。只要找到其中任意一个字符,它就会返回。
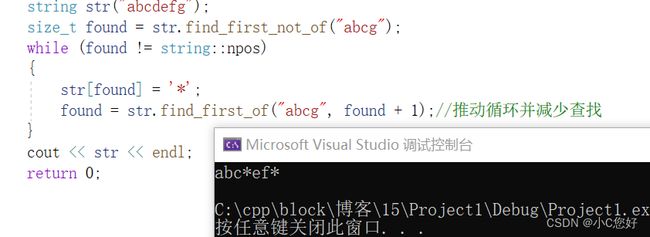 found第一次的值时=是匹配字串的数量,这里found的初值为3。
found第一次的值时=是匹配字串的数量,这里found的初值为3。
find_last_of
与find_first_of相反,find_last_of是倒着找。大家可以看看官方文库理解
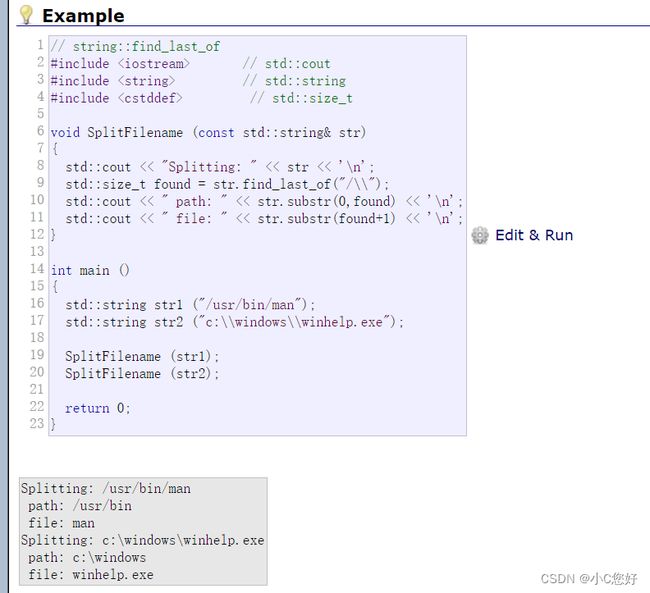
除此之外还有下面两个接口与它们作用相反,大家了解一下。![]()
运算符重载
在运算符重载那一张我们模拟实现了日期类的运算符,相信大家也不陌生了。需要注意的是,string类没有-运算符重载,存在+重载,但尽量少用(涉及拷贝)。
希望大家通过今天的学习,对string有个更深的认识,之后我会将这部分的习题写成博客上传,喜欢的别忘了一键三连!