中国大学MOOC“淘宝商品信息定向爬虫”实例(2022版)
目标:
获取淘宝搜索页面的信息
提取其中的商品名称和价格
(一)程序的结构设计:
1:提交商品搜索请求,循环获取页面
2:对于每个页面,提取商品名称和价格信息
3:将信息输出到屏幕上
(二)代码实现:
1:先构建出函数的整体框架
2: 对每一个函数具体的代码进行设计和编写
(三)解决只打印表头问题
(后续反爬虫问题)
嵩天老师
小数据孩儿来交笔记喽!!!
#淘宝商品信息定向爬虫
import requests #引入requests库获得链接
import re #引入正则表达式库获得相关内容
def getHTMLText(url): #爬取网页的通用代码框架
try:
r=requests.get(url,timeout=30) #获取页面的url链接
r.raise_for_status() #如果状态不是200,引发HTTP Error异常
r.encoding=r.apparent_encoding #修改编码
return r.text #将网页的信息内容返回给其他部分
except: #异常部分(如果出现错误,将返回一个空字符串)
return ""
def parsePage(ilt,html): #设计和开发parsePage函数,是整个函数的关键
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html) #re 库的主要功能函数 ,反斜杠代表引用
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price , title])
except:
print("")
def printGoodsList(ilt): #输出商品信息
tplt = "{:4}\t{:8}\t{:16}" #设计打印模板叫做tplt,大括号定义槽函数,第一个位置长度给4,中间位置长度为8,最后位置长度为16
print(tplt.format("序号", "价格", "商品名称")) #打印表头
count = 0 #定义一个输出信息的计数器
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1])) #count代表商品序号,后面的分别代表商品的价格和商品的名称
def main(): #定义主函数
goods = '书包' #搜索关键词,定义一个变量
depth = 3 #向下一页爬取的深度
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = [] #对整个的输出结果定义一个变量叫做infoList
for i in range(depth): #不同的页面是不同的url
try:
url = start_url + '&s=' + str(44*i) #对每一个页面的url链接进行一个设计
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList) #这时候的结果信息保存在infoList中
main() #最后通过调用主函数来使整个程序运行这样程序是写完了(嵩天老师原版代码)
但是打印出来的只有表头并没有商品信息
如何解决只打印表头的问题呢?
1、在淘宝官网搜索框中搜索“书包”
按“ctrl+shift+i”打开“开发人员工具”
(快捷键也许不同,自行查阅)
如下图:
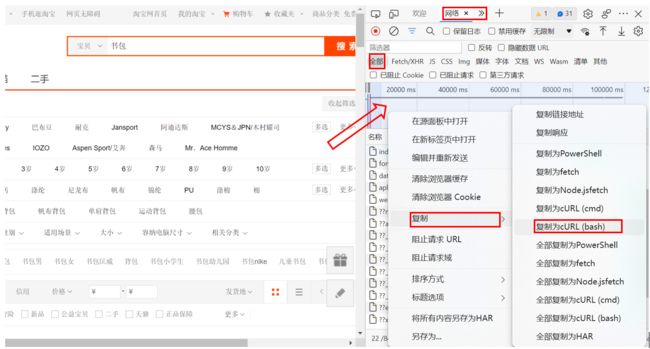
网络、全部、选中箭头指向位置
(如果箭头位置不变
就去左面的搜索栏点击一下搜索)
在箭头下面的名称位置选择第一个
并右击弹出有复制的菜单
再选择复制为cURL(bash)
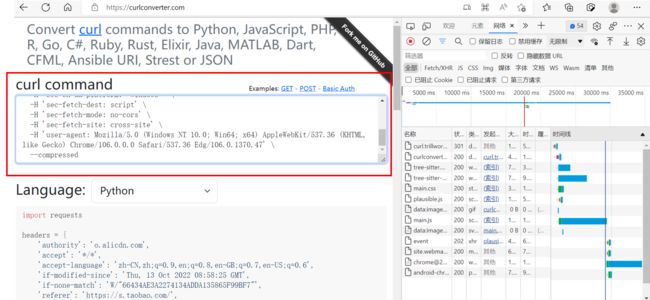
2、打开一个新的网址:https://curl.trillworks.com/
将上面复制的内容粘贴到下图红框的位置
(附图为粘贴完的效果)
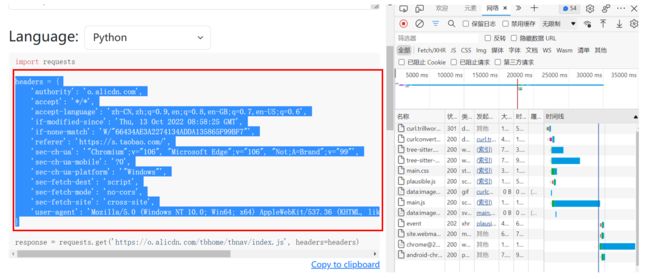
3、将页面往下滑
将python requests框内的headers={**}
内容复制到如下下图位置
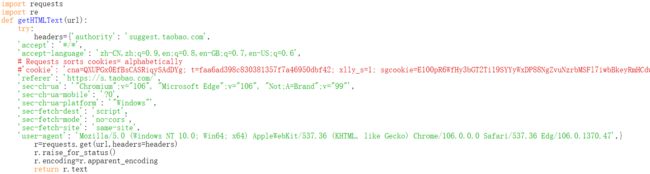 除了以上的变动外还要有以下变动
除了以上的变动外还要有以下变动
r=requests.get(url,timeout=30)
#改成
r=requests.get(url,headers=headers)4、最终代码(我将代码'cookie','referer'隐藏了,每个人的都不一样,大家在上述操作中直接复制自己的headers内容即可,记得将cookie前的#号去掉,否则还是打印不出内容)
#爬取淘宝页面
import requests
import re
def getHTMLText(url):
try:
headers={'authority': 'suggest.taobao.com',
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
# Requests sorts cookies= alphabetically
'cookie': '**********',
'referer': '*********',
'sec-ch-ua': '"Chromium";v="106", "Microsoft Edge";v="106", "Not;A=Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'script',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.47',}
r=requests.get(url,headers=headers)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt,html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price , title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 3
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()5、 运行成功
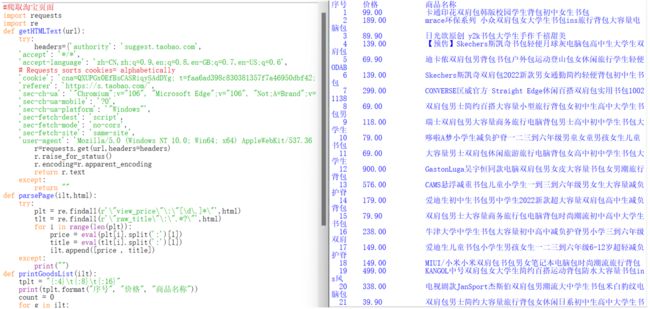
笔记就到这里了,希望对大家有所帮助!!!
网络爬虫盗亦有道!!!
不要不加节制的爬取该网页呦!!!