fastsocket优化网络性能原理
fastsocket是一个fastos的一个网络方面的优化,由新浪开源。fastsocket主要优化内核中的accept因为锁而导致的串行,对于短连接会极大的提高其性能,cpu核越多性能提升越明显。基于内核模块和一个动态链接库,对于某些应用程序不需修改就可使用。但是并非所有应用都能通过fastsocket获得性能提升。 fastsocket比较适用于一下场景:
Ø 系统至少不少于8个cpu
Ø 系统的很大一部分开销用于处理网络软中断以及socket相关系统调用
Ø tcp短连接很多
Ø 应用使用了epool处理网络io
Ø 应用使用了多进程接收连接
计划增加特性:(改善长连接的性能)
Ø direct-tcp:接收数据跳过路由处理
Ø 每一个核维护一个skb pool
Ø 投递packet到应用运行的核上,类似于rfs,(声称更加精确)
Ø 位rps增加用户定义接口
这里特别说明的是,应用必须是多进程accept连接进行处理,并且每个进程采用epoll的方式才能通过fastsocket获得性能提升。
fastsocket主要由一个内核模块和一个用户态动态链接库,通过LD_PRELOAD拦截系统调用,经过libfsocket.so处理后,采用ioctl的形式和fastsocket内核模块进行通信,内核模块进行实际的优化工作。
2.
fastsocket环境搭建
目前fastsocket只在2.6.x版本上实现,高版本需要移植才能使用。
kernel version = 2.6.x
fastsocket安装
下载fastsocket项目源代码,包括内核和用户态部分代码。
git clone https://github.com/fastos/fastsocket.git
代码目录介绍:
Ø kernel :fastsocket优化定制过的内核
Ø module :fastsocket内核模块代码,真实代码在kernel的net下
Ø library :fastsocket用户态库代码
Ø scripts :用于系统配置或者网卡配置的脚本
Ø demo :fastsocket示范用例
家下来编译fastsocket内核,编译之前检查内核选项的fastsocket相关选项是否配置:
>fastsocket/kernel
>make defconfig
>make
>make modules_install
>make install
编译用户态的库
>cd library
>make
fastsocket配置
enable_listen_spawn
使能该选项将会是连接本地化,对于多核多接收队列来说,linux原生的协议栈只能listen在一个socket上面,并且所有完成三次握手还没来得及被应用accept的套接字都会放入其附带的accept队列中,accept系统调用必须串行的从队列取出,当并发量较大时这将成为性能瓶颈。fastsocket将会通过copy listen socket在每个cpu上建立一个local cpu的listen socket,这样accept队列将会是local cpu的,将会大大改善accept性能,缩短连接建立的时间。事实上,如果设置了backlog,协议栈的accept数量将会受到限制,由于accept的串行将会导致大量连接不能建立,此项措施可以大大改善这个状况。(事实上2014 nsdi论文mtcp也提到了相关的优化措施)。应用将会绑定到同一个cpu core上。
enable_listen_spawn=0
enable_listen_spawn=1
enable_listen_spawn=2 (default)
0:完全禁止这个特性;1:需要程序自己绑定到cpu核上;2:程序允许fastsocket模块进行cpu的绑定。
enable_fast_epoll
使能该选项fastsocket将会缓存file结构到epoll的映射关系,仅针对fastsocket的socket句柄,从而避免epoll对自身维护的tree进行查找带来的消耗,但这要求socket fd必须只关联了一个epoll实例,否则不要设置这个选项。
enable_fast_epoll=0
enable_fast_epoll=1 (default)
0:禁止特性;1:开启特性。
enable_receive_flow_deliver
使能该选项,建立连接的时候其建立该连接的cpu id将会封装到连接的port端口中,数据包到达时将会解析出cpu id并将包投递到该cpu上,配合上面的listen local,将会是一个连接建立,中断处理和数据接受都发生在同一个核上。该特性比较适合与长连接应用,同时如果启用了rps,rps将会失效。(如果长连接的数据很不均衡,将会造成cpu负载不均衡)。
enable_receive_flow=0 (default)
enable_receive_flow=1
0:禁止特性;1:开启特性。
fastsokcet使用
LD_PRELOAD=a/libfsocket.so program
a代表libfsocket.so的目录,program代表需要运行的程序。
4.
首先分析下linux kernel 3.9之前的tcp常用api的实现,这里涉及到google的reuse port的一个patch,这个在3.9内核之前是没有的,由于fastsocket是基于2.6.32内核的,所以这里先大概描述下3.9内核之前tcp相关的实现。
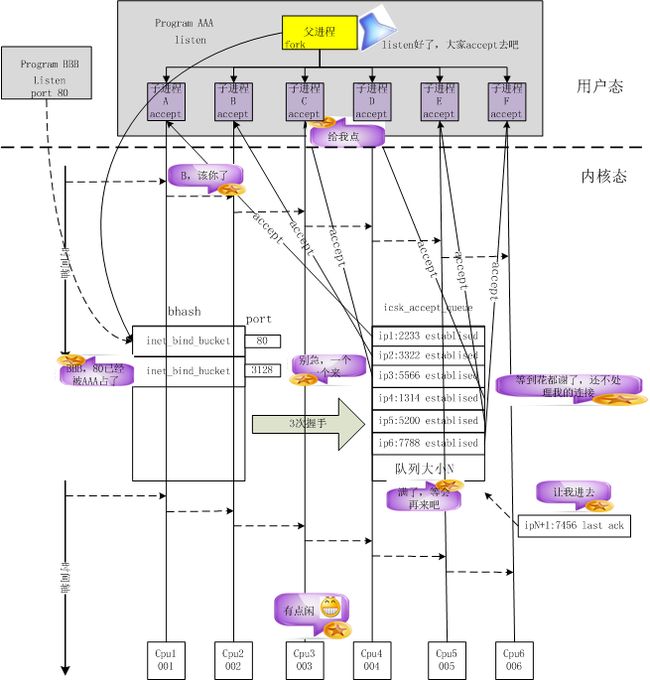
上图大概描述了老内核的tcp socket的实现,bind系统调用会将socket和port进行绑定,并加入全局tcp_hashinfo的bhash中,所有bind调用都会查询这个hash链表,如果port被占用,很显然老的内核会导致bind失败。listen则是根据用户设置的队列大小预先为tcp连接分配内存空间。也就是说,一个应用在同一个port上只能listen一次,那么也就只有一个队列来保存已经建立的连接。根据nginx的实现,在listen之后会fork处多个worker,每个worker会继承listen的socket,然后每个worker会创建一个epoll fd,并将listen fd和accept的新连接的fd加入epoll fd。但是一旦新的连接到来,多个worker也只能排队接收连接进行处理。对于大量的短连接,accept显然成为了一个瓶颈。
fastsocket的实现建立在google的reuse port的patch之上,也就是说同一个user id,net namespace,ip,port可以被多个进程listen,多个进程可以同时listen在同一个port上,当然前提是满足前面提到的条件。fastsocket在用户态实现了一个动态链接库libfsocket.so,socket、bind、listen等系统调用在启用fastsocket的时候会被拦截并进入这个链接库进行处理,对于listen系统调用,fastsocket会记录下这个fd,当应用通过epoll将这个fd加入到epoll fdset中时,libfsocket.so会通过ioctl为该进程clone listen fd关联的socket、sock、file的系统资源,并将clone的socket再次调用bind和listen,这些都是在内核态实现的,bind系统调用检测到另外一个进程绑定到已经被绑定的port时,会进行相关检查,如果通过检查那么这个sock将会被记录到port相关联的一个链表中,通过该链表可以知道所有bind同一个port的sock,而sock是关联到fd的,进程则持有fd,那么所有的资源就已经关联到一起了,而新的进程再次调用listen系统调用的时候,内核会再次为其关联的sock分配accept队列。那么多个进程也就拥有了多个accept 队列,为了避免cpu cache miss导致的性能损失,fastsocket提供将每个listen和accept的进程绑定到用户指定的cpu core上,如果用户未指定,fastsocket将会为该进程默认绑定一个空闲的cpu 核。fastsocket的实现原理图如下所示。
