计算机视觉——SFM与三位重建
第五章:SFM与三维重建
-
-
- 1. 三维重建简述
- 2. 对极几何
-
- 2.1 对极几何简述
- 2.2 五点共面约束
- 2.3 几个相关概念
- 2.4 对应点的约束
- 3. 两种矩阵
-
- 3.1 基础矩阵F(对极几何的代数表达式)
- 3.2 本质矩阵E
- 4. 八点算法估计基础矩阵F
- 5. SFM概述
- 6. 实验内容
-
- 6.1 实验一(画出极点和极线)
-
- 6.1.1 场景一(左右)
- 6.2.1 场景二(水平)
- 6.3.1 场景三(前后)
- 6.2 实验二(用不同匹配点计算基础矩阵)
-
- 6.2.1 场景一(左右)
- 6.2.2 场景二(水平)
- 6.2.3 场景三(前后)
- 7. 总结
-
1. 三维重建简述
-
计算机视觉包含两个基本方向,物体识别和三维重建。图像识别的突破性进展源自于2012年卷积神经网络(CNN)的兴起。在此之前,计算机视觉的核心研究方向是三维重建。因为在当时,对于图像的特征提取主要是通过三维重建的方法来定义和实现的。自2012年以来,图像的特征便逐渐由神经网络来自动学习。
-
三维重建的应用是很广泛的,对于自动驾驶、VR、AR等应用领域应用来讲,三维重建是核心技术,并且实时三维重建是必然趋势,因为我们生活在三维空间里,必须将虚拟世界恢复到三维,我们才可以和环境进行交互。所以仅仅研究识别肯定是不够的,计算机视觉下一步必须走向三维重建,并且把三维重建和识别融为一体。
-
古建筑修复与重建是三维重建的一个具有代表性的应用,比如近期被烧毁的巴黎圣母院,如果通过三维模型网址进行数字重建,应该能够达到原汁原味还原其真实面貌的目的。目前在我们的三维重建项目中,名胜古迹的三维电子存档是很重要的一部分。从表面上看,三维重建似乎没有自动驾驶那么复杂,其实它比自动驾驶更难,因为自动驾驶的三维感知是给车识别,而VR、AR中的三维重建场景是提供给人类感知的,所以对三维重建的结果要求非常高。
总体来讲,三维重建是计算机视觉的灵魂。
2. 对极几何
2.1 对极几何简述
先思考一个问题:用两个相机在不同的位置拍摄同一物体,如果两张照片中的景物有重叠的部分,我们有理由相信,这两张照片之间存在一定的对应关系,本节的任务就是如何描述它们之间的对应关系,描述工具是对极几何 ,它是研究立体视觉的重要数学方法。
- 对极几何(Epipolar Geometry)描述的是两幅视图之间的内在射影关系,与外部场景无关,只依赖于摄像机内参数和这两幅试图之间的的相对姿态
- 提到对极几何,一定是对二幅图像而言,对极几何实际上是“两幅图像之间的对极几何”,它是图像平面与以基线为轴的平面束的交的几何(这里的基线是指连接摄像机中心的直线),以下图为例:对极几何描述的是左右两幅图像(点x和x’对应的图像)与以CC’为轴的平面束的交的几何

直线CC’为基线,以该基线为轴存在一个平面束,该平面束与两幅图像平面相交,下图给出了该平面束的直观形象,可以看到,该平面束中不同平面与两幅图像相交于不同直线;

上图中的灰色平面[Math Processing Error],只是过基线的平面束中的一个平面(当然,该平面才是平面束中最重要的、也是我们要研究的平面);
2.2 五点共面约束
对极几何相关的一个重要约束·5点共面约束
空间点X在两幅图像中的像分别为x和x’,这两个投影点之间存在的关系:
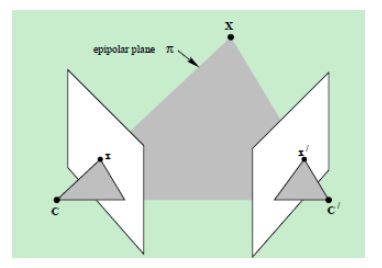
- 点x、x’与摄像机中心C和C’是共面的,并且与空间点X也是空面的,这5个点共面于平面π。这是一个最本质的约束,即5个点决定了一个平面π。
- 由该约束,可以推导出一个重要性质:由图像点x和x’反投影的射线共面,并且,在平面π上,在搜索点对应中,该性质非常重要。
2.3 几个相关概念
-
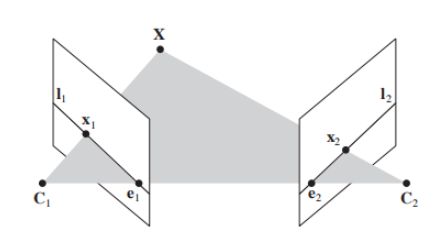
对极点(epipole):摄像机的基线与每幅图像的交点;即下图中的点e和e’(对极点=基线与像平面的交点=光心在另一幅图像中的投影)
-
对极线(epipolar line):对极平面与图像的交线;即下图中的直线l和l’(对极线=对极平面与像平面的交线)
-
对极平面(epipolar plane):任何包含基线的平面都称为对极平面,或者说是对极平面束中的平面;即下图中的平面就是一个对极平面
(对极平面=包含基线的平面)

2.4 对应点的约束
问题:当只知道图像点x,那么它的对应点x’如何约束?
- 点x和x’一定位于平面π上,而平面π可以利用基线CC’和图像点x的反投影射线确定
- 点x’又是右侧图像平面上的点,所以,点x’一定位于平面π与右侧图像平面的交线l’上
- 直线l’为点x的对极线,也就是说,点x的对应点x’一定位于它的对极线上

3. 两种矩阵
这里先说一下关于矩阵中的秩之前一直不是很理解,知乎上的解答:
-
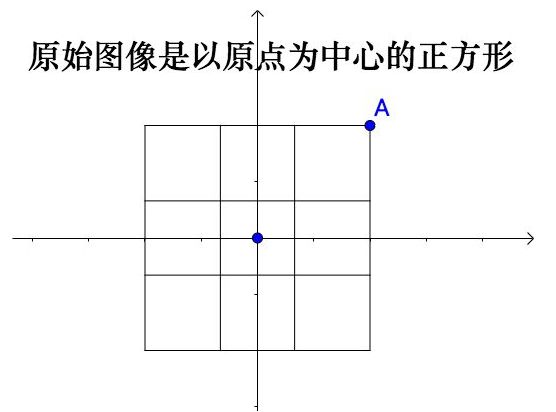
「秩」是图像经过矩阵变换之后的空间维度
「秩」是列空间的维度
前者更直观,而后者是前者的原因- 1 「秩」是图像经过矩阵变换之后的空间维度
通过旋转矩阵进行变换:
[ c o s θ − s i n θ s i n θ c o s θ ] \begin{gathered} \begin{bmatrix} cos\theta & -sin\theta \\ sin\theta & cos\theta \end{bmatrix} \end{gathered} [cosθsinθ−sinθcosθ]

因此,旋转矩阵的「秩」为2。
通过矩阵 [ 1 − 1 1 − 1 ] \begin{gathered} \begin{bmatrix} 1 & -1 \\ 1 & -1 \end{bmatrix} \end{gathered} [11−1−1]进行变换:

因此,此矩阵的「秩」为1通过矩阵 [ 0 0 0 0 ] \begin{gathered} \begin{bmatrix} 0 & 0 \\ 0 & 0\end{bmatrix} \end{gathered} [0000] 进行变换:

因此,此矩阵的秩为0
所以,秩是图像经过矩阵变换之后的空间维度。 - 1 「秩」是图像经过矩阵变换之后的空间维度
可以从另一维度来解释为什么
2 「秩」是列空间的维度
- 2.1 什么是列空间
我们通过旋转矩阵来解释什么是列空间:

通过改变 a i ′ ⃗ + b j ′ ⃗ \vec{ai'}+\vec{bj'} ai′+bj′的值,可以用 [公式] 来表示二维平面上的所有点:

所以,列空间就是矩阵的列向量所能张成的空间(即能通过 a i ′ ⃗ + b j ′ ⃗ \vec{ai'}+\vec{bj'} ai′+bj′来表示)的空间
列空间的维度就是秩,旋转矩阵的列空间是二维的,所以秩就为2
那么这种定义方式怎么和之前说的秩是图像经过矩阵变换之后的空间维度联系起来呢?
- 2.2 矩阵的变换目标是列空间
有一个矢量
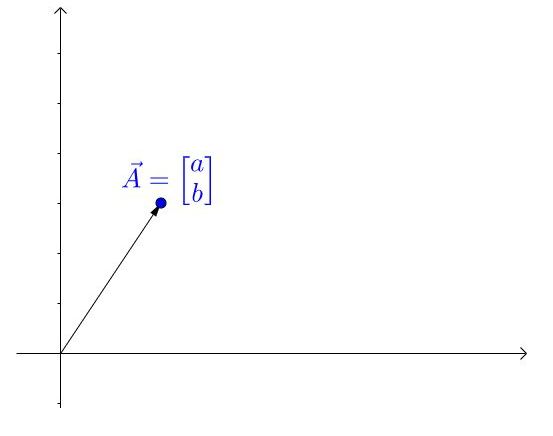

矩阵变换的其实是基
比如旋转矩阵

实际上:


2.3 两种定义方式的联系
用旋转矩阵对二维的正方形进行线性变换,实际上是一个二维空间到另外一个二维空间的变换:
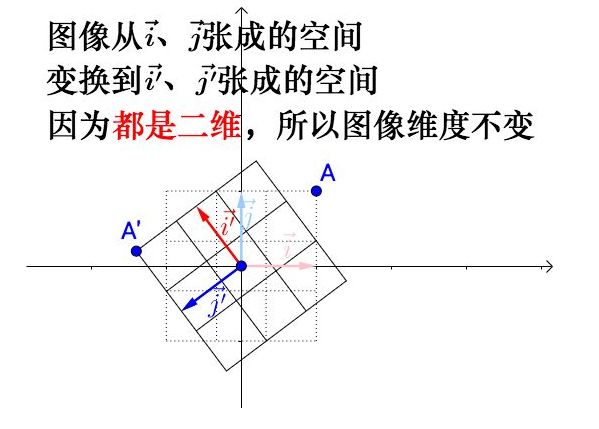

对于矩阵 [ 1 − 1 1 − 1 ] \begin{gathered} \begin{bmatrix} 1 & -1 \\ 1 & -1 \end{bmatrix} \end{gathered} [11−1−1],他的列空间是一维的

因此,这个矩阵的秩就是1,用它对二维的正方形进行线性变换,实际上是一个二维空间到另外一个一维空间的变换:
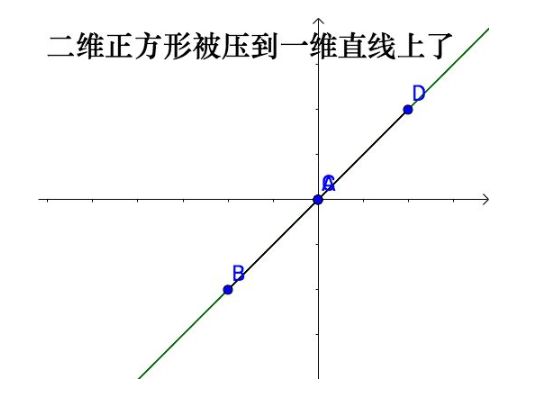
同理,矩阵 [ 0 0 0 0 ] \begin{gathered} \begin{bmatrix} 0 &0 \\ 0 & 0\end{bmatrix} \end{gathered} [0000]的列空间是个点,因此它的「秩」就是0。
这里来自知乎:什么是矩阵的秩
3.1 基础矩阵F(对极几何的代数表达式)
-
基础矩阵可以用来:
1)简化匹配
2)去除错匹配特征 -
基础矩阵描述了空间中的点在2个像平面中的坐标对应关系
x ′ T F x = 0 \mathbf{x'}^\mathrm{T}Fx=0 x′TFx=0

-
什么是双目立体视觉(Binocular Stereo Vision):是机器视觉的一种重要形式,它是基于视差原理并利用成像设备从不同的位置获取被测物体的两幅图像,通过计算图像对应点间的位置偏差,来获取物体三维几何信息的方法。
基础矩阵F的应用
-
立体视觉几何中有以下问题:
1)已知一幅图像中一点,如何寻找另一幅图像中这个点的对应点(可用光流法、特征点匹配法)
2)已知两幅图像中两点是对应关系,如何求解两相机的相对位置和姿态【R|t】
3)已知多幅图像中同一3D点的对应点,如何求解该3D点的3D坐标
对极几何/基础矩阵 的出现可以解决问题2。即求出R|t. -
给定一对同一场景不同视角得到的图像,对于第一幅图像上的任一像点x,在第二幅图像中都有一条与之对应的对极线l′,该对极线是像点x与过第一个相机中心C射线在第二幅图像上的投影,第二幅图像中与x相匹配的像点x′必定在该对极线上。因此,存在一个像点x到另一个图像上对极线l′的映射:x→l′
基础矩阵F表示的就是这种从点到直线的映射。 -
基础矩阵F的性质:
1)3*3且自由度为7的矩阵
2)F矩阵的秩为2
3)基本矩阵依赖内部和外部参数(Intrinsic and Extrinsic Parameters) (f, R & T)决定。
4)使用像素坐标系 -
自己对基本矩阵的理解:基本矩阵是很有用的一个工具,在三维重建和特征匹配上都可以用到。基本矩阵提供了三维点到二维的一个约束条件。举个例子,现在假设我们不知道空间点X的位置,只知道X在左边图上的投影x的坐标位置,也知道基本矩阵,首先我们知道的是X一定在射线Cx上,到底在哪一点是没法知道的,也就是X可能是Cx上的任意一点(也就是轨迹的意思),那么X在右图上的投影肯定也是一条直线。也就是说,如果我们知道一幅图像中的某一点和两幅图的基本矩阵,那么就能知道其对应的右图上的点一定是在一条直线上,这样就约束了两视角下的图像中的空间位置一定是有约束的,不是任意的。
-
于是VSLAM中相机的相对位姿可以通过特征点匹配估计出来:
1)提取两幅图像的特征点,并进行匹配
2)利用匹配得像点计算两视图的基础矩阵F
3 )从基础矩阵F中分解得到相机的旋转矩阵R和平移向量t
3.2 本质矩阵E
-
本质矩阵描述了空间中的点在两个坐标系中坐标对应关系
p ′ T E p = 0 \mathbf{p'}^\mathrm{T}Ep=0 p′TEp=0
-
本质矩阵E:E矩阵同样表示的是对极约束的关系,但它不再涉及相机内参,只由两视图之间的姿态关系决定。
1)描述空间中一点在不同帧之间的几何约束关系
2)注意这里的图像坐标是空间点在相机平面投影点的齐次坐标(摄像机坐标系下表示)
3)本质矩阵和相机外参有关系,和内参无关 -
本质矩阵E的性质:
1)3*3且自由度为5的矩阵
2)因为只包含R,t共有6个自由度,又因为尺度等价去掉一个自由度
3)本质矩阵E的奇异值必定为 [ σ , σ , 0 ] T [\sigma ,\sigma ,0]^{T} [σ,σ,0]T的形式
4)本质矩阵的秩为2
5)本质矩阵仅依赖外部参数(Extrinsic Parameters) (R & T)决定。
6) 使用摄像机(Camera)坐标系 -
自己对本质矩阵的理解:为了获取本质矩阵,首先计算基础矩阵F。(本质矩阵是基础矩阵的一个子集,不知道这样理解对不对?)根据本质矩阵E,就可恢复得到运动的状态R和T。
4. 八点算法估计基础矩阵F
-
基本矩阵的方程定义:
x ′ − T F x = 0 \mathbf{x'}^\mathrm{-T}F_x=0 x′−TFx=0
其中 x x x与 x ′ x' x′是两幅图像的任意一堆匹配点。
由于每一组的匹配提供了计算 F F F系数的一个线性方程,当给定至少7个点,方程就可以计算出未知的方程。我们记点的坐标为 x = ( x ′ , y ′ , 1 ) T x=\mathbf{(x',y',1)}^\mathrm{T} x=(x′,y′,1)T, x ′ = ( x ′ , y ′ , 1 ) − T x'=\mathbf{(x',y',1)}^\mathrm{-T} x′=(x′,y′,1)−T,则对应的方程为
[ x y 1 ] [ f 11 f 12 f 13 f 21 f 22 f 23 f 31 f 32 f 33 ] [ x ′ y ′ 1 ] = 0 \begin{gathered} \begin{bmatrix} x&y&1\end{bmatrix} \end{gathered}\begin{gathered} \begin{bmatrix} f_{11}&f_{12}&f_{13}\\f_{21}&f_{22}&f_{23}\\f_{31}&f_{32}&f_{33}\end{bmatrix} \end{gathered}\begin{gathered} \begin{bmatrix} x'\\y'\\1\end{bmatrix} \end{gathered}=0 [xy1]⎣⎡f11f21f31f12f22f32f13f23f33⎦⎤⎣⎡x′y′1⎦⎤=0
展开后:
x x ′ f 11 + x ′ y f 12 + x ′ f 13 + y ′ x f 21 + y ′ y f 22 + y ′ f 23 + x f 31 + y f 32 + f 33 = 0 xx'f_{11}+x'yf_{12}+x'f_{13}+y'xf_{21}+y'yf_{22}+y'f_{23}+xf_{31}+yf_{32}+f_{33}=0 xx′f11+x′yf12+x′f13+y′xf21+y′yf22+y′f23+xf31+yf32+f33=0
把矩阵F写成列向量的有
[ x ′ x x ′ y x ′ y ′ x y ′ y y ′ x y 1 ] f = 0 \begin{gathered} \begin{bmatrix} x'x&x'y&x'&y'x&y'y&y'&x&y&1\end{bmatrix} \end{gathered}f=0 [x′xx′yx′y′xy′yy′xy1]f=0
给定n组合的几何,我们有如下方程:
A f = [ x ′ x x ′ y x ′ y ′ x y ′ y y ′ x y 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . x ′ x x ′ y x ′ y ′ x y ′ y y ′ x y 1 ] f = 0 Af=\begin{gathered} \begin{bmatrix} x'x&x'y&x'&y'x&y'y&y'&x&y&1\\...&...&...&...&...&...&...&...&...\\x'x&x'y&x'&y'x&y'y&y'&x&y&1\end{bmatrix} \end{gathered}f=0 Af=⎣⎡x′x...x′xx′y...x′yx′...x′y′x...y′xy′y...y′yy′...y′x...xy...y1...1⎦⎤f=0
如果存在确定(非零)解,则系数矩阵 A A A的自由度最多是8。由于 F F F是齐次矩阵,所以如果矩阵 A A A的自由度为8,则在差一个尺度因子的情况下解是唯一的。可以直接用线性算法解得。 -
八点算法:
两个步骤:
1)求线性解 :由系数矩阵A最小奇异值对应的奇异矢量f‘求的F
2)奇异性约束:是最小化 ∣ ∣ F − F ′ ∣ ∣ ||F-F'|| ∣∣F−F′∣∣的F’代替F
八点法概述:
如果由于点坐标存在噪声则矩阵 A A A的自由度可能大于8也就是等于9,由于 A A A是n*9的矩阵)。这时候就需要求最小二乘解,这里就可以用SVD来求解,f的解就是系数矩阵 A A A最小奇异值对应的奇异向量,也就是 A A A奇异值分解后$A=UD V T \mathbf{V}^\mathrm{T} VT 中矩阵 V V V的最后一列矢量,这是在解矢量 f f f在约束 ∥ f ∥ ∥f∥ ∥f∥下取 ∥ A f ∥ ∥Af∥ ∥Af∥最小解,以上算法是解矩阵的基本方法,称为8点算法。
由于基本矩阵有一个重要的特点就是奇异性
- 奇异矩阵:奇异矩阵是线性代数的概念,就是该矩阵的秩不是满秩。
首先,看这个矩阵是不是方阵(即行数和列数相等的矩阵,若行数和列数不相等,那就谈不上奇异矩阵和非奇异矩阵)。然后,再看此矩阵的行列式|A|是否等于0,若等于0,称矩阵A为奇异矩阵;若不等于0,称矩阵A为非奇异矩阵。
F矩阵的秩是2。如果基本矩阵是非奇异的,那么所计算的对极线将不重合。所以在上述算法解得基本矩阵后,会增加一个奇异性约束。最简便的方法就是修正上述算法中求得的矩阵 F F F。设最终的解为 ′ F ′ ′F' ′F′,令 d e t F ′ = 0 detF′=0 detF′=0下求得Frobenius范数(二范数) ∥ F − F ′ ∥ ∥F−F′∥ ∥F−F′∥最小的 F ′ F' F′ 。这种方法的实现还是使用了SVD分解,若 F = U D V T F=\mathbf{UDV}^\mathrm{T} F=UDVT,此时的对角矩阵 D = d i a g ( r , s , t ) D=diag(r,s,t) D=diag(r,s,t),满足 r > = s > = t r>=s>=t r>=s>=t,则 F ‘ = U d i a g ( r , s , 0 ) V T F‘=Udiag(r,s,0)\mathbf{V}^\mathrm{T} F‘=Udiag(r,s,0)VT最小化范数 ∣ ∣ F − F ′ ∣ ∣ ||F-F'|| ∣∣F−F′∣∣,也就是最终的解。
为了提高解的稳定性和精度,往往会对输入点集的坐标先进行归一化处理。
-
归一化八点算法:
1997年,Hartley对原始8点算法进行改进,在构造解的方程之前对输入的数据进行适当的归一化。即在形成8点算法的线性方程组之前,图像点的一个简单变换(平移或变尺度)将使这个问题的条件极大地改善,从而提高结果的稳定性。而且进行这种变换所增加的计算复杂性并不显著。算法具体过程具体如下:1)对原始图象坐标做一个平移变换,使原来以左上角为原点的图象坐标变成以所有图像点的重心为原点的图像坐标;
2)再对图象坐标做一个尺度变换,使得点到原点的平均距离为 2 \sqrt{2} 2分别对两幅图像进行以上两步变换,然后将变换后的图像坐标作为输入数据计算基础矩阵。
计算过程如下:
1)设两个独立的图像坐标变换分别为 T , T ′ T,T' T,T′则变换后的图像坐标为 x i ~ = T x i \widetilde{x_i}=Tx_i xi =Txi, x i ′ ~ = T x i ′ \widetilde{x_i'}=Tx_i' xi′ =Txi′
2)基于转换后的匹配点对 p − > p ′ p->p' p−>p′,利用八点算法计算基础矩阵 F ~ \widetilde{F} F
3)解除归一化,令 F = T T F ~ T F=\mathbf{T}^\mathrm{T}\widetilde{F}T F=TTF T,矩阵F是对应于原始数据 x i − > x i ′ x_i->x_i' xi−>xi′的基本矩阵。
注意:此时求得的F阵的秩并不保证严格为2。而且,由于噪声影响计算得到的F一般都是满秩的。进而,根据相机的内参信息得到本质矩阵E。
5. SFM概述
-
SfM(Structure from motion) 是一种三维重建的方法,用于从motion中实现3D重建。也就是从时间系列的2D图像中推算3D信息。
人的大脑可以从动的物体中取得其三维的信息,是因为大脑在动的2D图像中找到了匹配的地方,即Corresponding area (points)。然后通过匹配点之间的视差得到相对的深度信息,在这一点上,原理和基于Stereo的三维重建相同。
SfM的输入是一段motion或者一时间系列的2D图群,不需要任何相机的信息。然后通过2D图之间的匹配可以推断出相机的各项参数。
6. 实验内容
准备了三组场景:
1)左右拍摄

2)水平拍摄

3)前后拍摄
- 相机方向相反的前后

- 相机方向相同的前后

6.1 实验一(画出极点和极线)
6.1.1 场景一(左右)
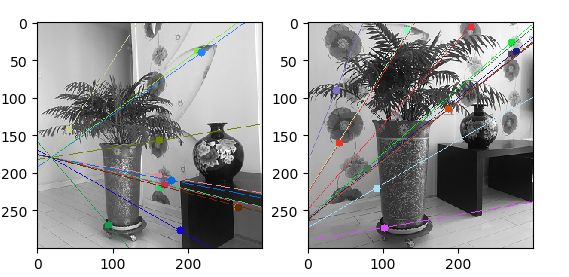
![]()
6.2.1 场景二(水平)

![]()
6.3.1 场景三(前后)
- 相机相反方向的前后


- 相机相同方向的前后


小结
- 1)实验中彩色的线是对极线,彩色的点代表匹配点。可以观察到左右视图的对极线都响应地汇聚到一点,那点就是极点。
- 2)首先再次明确概念,再分析结果(因为之前一直很朦胧,没法分析的很清楚,所以又去看了很久概念)
基线:左右像机光心连线;(所以也不是随便选取的,是唯一确定的一条)
极平面:空间点,两像机光心决定的平面;
极点:基线与两摄像机图像平面的交点(所以一幅图像只有一个)
极线:极平面与图像平面交线
极线约束:匹配点必须在极线上
从实验结果来看,每个点都在极线上,说明实验的效果不错。 - 3)当场景为左右拍摄时,极点应该汇聚在像平面,但是不一定在图像上,因为图像只是平面的一部分。看了ppt后自己分析,如果是严格相同角度的左右拍摄的话,极线应该平行,并且极点汇聚在图片外与图片同平面的某点,但是我的左右角度并不严格相同,所以导致,会有极点汇聚在图像上的情况,且实验情况一种还有不是很平行的时候。
- 4)当场景为平行拍摄时,因为基线平行于像平面,所以极点应该在无限远处,所以极线应该严格平行,但从我的实验结果看,我的推测是极线仍然会汇聚于一点。因为我拍摄的场景中,物品很明显,移动幅度有些大,没办法控制住相机是否有真的平行拍摄到,现在回看我拍摄的图片,感觉竖直方向来看,相机并不是平行的,可见误差来自于我的拍摄情况,但如果严格平行,可以推测出极点将汇聚在无线远处。

- 5)当场景为前后拍摄时,刚开始没有正确理解前后的意思,对着一个花瓶的正面拍了一张,反面拍了一张。等做完实验再回看,发现ppt上的前后就只是镜头前后移动,与物品的距离关系。于是我又加了一组相机镜头同向位的实验。刚好可以对比一下结果。
发现,不论是相机方向是同向还是反向,极点都汇聚在图像上的同一点而不是图像外,从这个角度来看实验结果是成功的。原理就是因为极点是基线与图像平面的交点,当相机为前后拍摄时,基线是垂直于图像平面的,所以交点就会在图像平面上。

- 6)已知x在第一视图的投影点x1,不能找到x在第二视图的投影点x2,只能根据已知条件只能知道x位于xC1所在直线上,并不能确定x的位置,但可知道x2位于外极线 I2 上。
6.2 实验二(用不同匹配点计算基础矩阵)
6.2.1 场景一(左右)
- 七个特征点计算基础矩阵


6.2.2 场景二(水平)
- 七个特征点计算基础矩阵
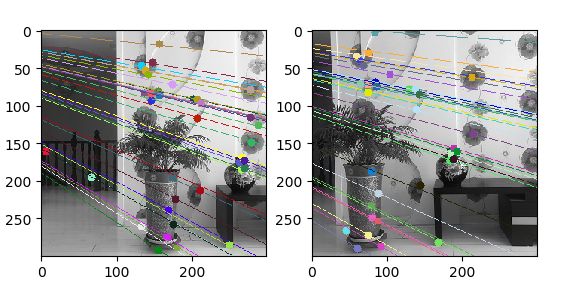

6.2.3 场景三(前后)
- 七个特征点计算基础矩阵
- 相机相反方向的前后
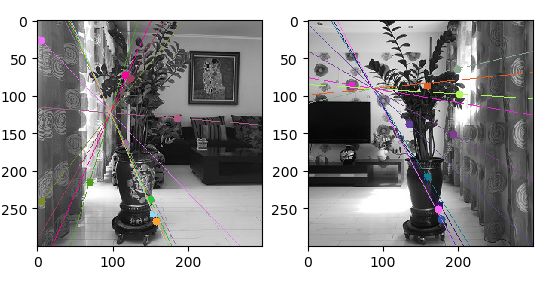

- 相机相同方向的前后


小结:
- 1)因为这里使用的代码只能分成7点和大于等于8点的计算矩阵方法,所以这里只比较了7与8时的基础矩阵。
- 2)可以从实验结果中发现,有时7个匹配点和8分匹配点算出的基础矩阵 会有差别,但计算次数多了以后会完全一样。(因为7点计算并不稳定)
- 3)因为这个代码用的是opencv里面的自带函数 f i n d F u n d a m e n t a l M a t findFundamentalMat findFundamentalMat来计算基础矩阵,我的推测是他之所以只分为7和8点,因为本来7点的时候就已经可以计算了,但是为了稳定性和精确性所以又加了一个约束点。所以从这里来看 ,只有7点和8点的时候是会有些区别,但是从我本人的实验结果来看,当7点的代码运行次数多了以后,也会与八点的代码算出一模一样的结果(这里还不清楚为什么)。8点和10点应该差别不会非常多(因为有归一化所以让结果的差别看起来更小了)所以该算法只区分了7点和>=8点的情况,并没有写10,11,12这样更多的点。
7. 总结
- 立体视觉(大于一个摄像机)可以解决在使用针孔相机时,丢失的信息,比如图像的深度。
- 通过对极几何一幅图像上的点可以确定另外一幅图像上的一条直线,这种情况用基础矩阵来表示。
- 基础矩阵F和极点 e / e ′ e/e' e/e′,极线 l / l ′ l/l' l/l′的关系结论:

左相机: l = F T m ′ , F e = 0 l=\mathbf{F}^\mathrm{T}m',Fe=0 l=FTm′,Fe=0
右相机: l ′ = F m ′ , F T e ′ = 0 l'=Fm',\mathbf{F}^\mathrm{T}e'=0 l′=Fm′,FTe′=0
基础矩阵和极点,极线关系推导:
其中
l l l:左相机图像平面的极线
e e e:左相机图像平面的极点,左相机平面的所有极线都经过极点e
l ′ l' l′:右相机图像平面的极线
e / e/ e/:右相机图像平面的极点,右相机平面的所有极线都经过极点e‘
基础矩阵F满足下列等式:
( m ) ′ T F m = 0 \mathbf{(m)'}^\mathrm{T}Fm=0 (m)′TFm=0
m T F T m ’ = 0 \mathbf{m}^\mathrm{T}\mathbf{F}^\mathrm{T}m’=0 mTFTm’=0
-
对于左相机平面:
点m在极线l上,所以有 m T l = 0 \mathbf{m}^\mathrm{T}l=0 mTl=0,根据, m T F T m ’ = 0 \mathbf{m}^\mathrm{T}\mathbf{F}^\mathrm{T}m’=0 mTFTm’=0可知, 相差一个常数因子时,对直线方程无影响,因此可以将极线l 表示为: l = F T m ’ l=\mathbf{F}^\mathrm{T}m’ l=FTm’
相差一个常数因子时,对直线方程无影响,因此可以将极线l 表示为: l = F T m ’ l=\mathbf{F}^\mathrm{T}m’ l=FTm’
极点e在极线l上,所以有 e T l = e T F T m ′ = 0 \mathbf{e}^\mathrm{T}l=\mathbf{e}^\mathrm{T}\mathbf{F}^\mathrm{T}m'=0 eTl=eTFTm′=0因为左相机图像平面上的所有极线都过极点e,因此 m ′ m' m′可以为任意值,只能有
e T F T = ( F e ) T = 0 − > F e = 0 \mathbf{e}^\mathrm{T}\mathbf{F}^\mathrm{T}=\mathbf{(Fe)}^\mathrm{T}=0->Fe=0 eTFT=(Fe)T=0−>Fe=0 -
对于右相机平面:
点 m ’ m’ m’在极线 l ′ l' l′上,所以有 m ′ T l ′ = 0 \mathbf{m'}^\mathrm{T}l'=0 m′Tl′=0,根据, ( m ) ′ T F m = 0 \mathbf{(m)'}^\mathrm{T}Fm=0 (m)′TFm=0可知,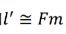 相差一个常数因子时,对直线方程无影响,因此可以将极线l 表示为: l ′ = F m l'=Fm l′=Fm
相差一个常数因子时,对直线方程无影响,因此可以将极线l 表示为: l ′ = F m l'=Fm l′=Fm
极点 e ′ e' e′在极线 l ′ l' l′上,所以有 ( e ′ ) T l = ( e ′ ) T F m = 0 \mathbf{(e')}^\mathrm{T}l=\mathbf{(e')}^\mathrm{T}Fm=0 (e′)Tl=(e′)TFm=0因为右相机图像平面上的所有极线都过极点 e e e’,因此 m m m可以为任意值,只能有
( e ′ ) T F = ( F T e ′ ) T = 0 − > F T e ′ = 0 \mathbf{(e')}^\mathrm{T}F=\mathbf{(\mathbf{F}^\mathrm{T}e')}^\mathrm{T}=0->\mathbf{F}^\mathrm{T}e'=0 (e′)TF=(FTe′)T=0−>FTe′=0