人工智能-实验四
第四次实验
一.实验目的
了解深度学习的基本原理。能够使用深度学习开源工具。学习使用深度学习算法求解实际问题。
二.实验原理
1.深度学习概述
深度学习源于人工神经网络,本质是构建多层隐藏层的人工神经网络,通过卷积,池化,误差反向传播等手段,进行特征学习,提高分类或预测的准确性。深度学习通过增加网络的深度,减小每层需要拟合的特征个数,逐层提取底层到高层的信息,达到更好的预测和分类性能。强调模型结构的深度,通常有5层以上的隐藏层。
神经元是深度学习模型中的基本单位,对相邻前向神经元输入信息进行加权累加,再加上一个偏差值,对结果进行非线性变换,输出最终的结果。常用的非线性变换激活函数有Sigmoid,Tanh,ReLU,Softmax。
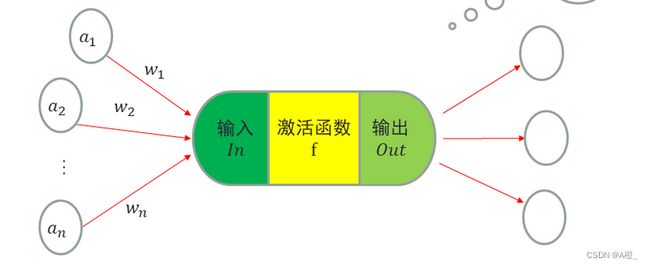
深度学习的神经网络中有多层,每一层都包含一些神经元,不同层次之间神经元的连接关系构成了不同的神经网络。每一层每个神经元都有不同的权重和偏差值,这些都是神经网络的参数。通过训练对参数进行调整,最终得到具有高分类和预测准确性的神经网络。参数优化的算法涉及梯度下降,误差反向传播等。
梯度下降
梯度下降算法是使损失函数最小化的方法。在多元函数中,梯度是对每一变量所求偏导数所组成的向量。梯度的反方向是函数值下降最快的方向。梯度下降算法用于最小化损失函数,找到使损失函数下降最快的方向进行参数调优。
误差反向传播
误差反向传播是损失函数对于参数的梯度通过网络反向流动的过程。

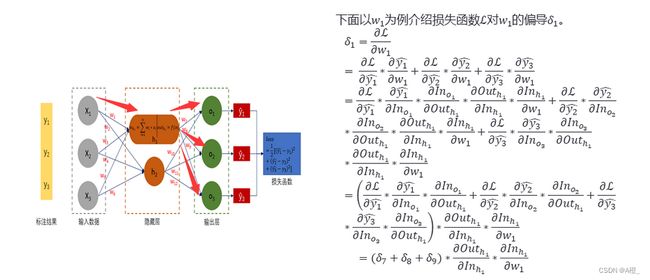
为了使损失函数减小,求损失函数相对于参数w1的偏导,按照损失函数梯度的反方向选取一个增量,调整w1的权值,就能够保证损失函数取值减少。参数w1不是直接在损失函数中直接出现的,需要通过链式求导得到对w1的偏导:
d L d w 1 = d L d O d O d X d X d w 1 \frac{dL}{dw1} = \frac{dL}{dO}\frac{dO}{dX}\frac{dX}{dw1} dw1dL=dOdLdXdOdw1dX
按照顺序,分别为损失函数对输出的偏导(和损失函数的定义有关),对激活函数的偏导,最后一个是对加权累加函数的求导(w1*out1+w2*out2+w3*out3,求导结果为out1)。三者累乘就是损失函数对某个参数的偏导。每个神经元都据此对参数进行更新,在这个过程中,误差也从输出端向输入端逐层传播。并且误差传播的路径有多条时,误差反向传播时神经元也会从多个方向得到误差并进行参数调整。
2.卷积神经网络CNN
卷积神经网络CNN是人工神经网络的一种,常用于图像识别。卷积神经网络是识别二维形状的一个多层感知器,对于平移,比例缩放,旋转,或者其他形式的变相具有一定的不变性。
卷积神经网络的核心思想是将局部感知,权值共享以及下采样这三种结构结合,达到图像降维的特征学习。卷积神经网络通常有多个卷积,池化隐藏层,进行特征的提取和降维。
卷积
卷积是通过一个带权滑动窗口(称为卷积核),在图像上从左到右,从上到下扫描。将窗口值与图像被覆盖的部分进行矩阵内积。最终计算后的结果称为特征图。特征图体现了每个卷积核大小的部分与卷积核的相似程度。卷积在提取特征时考虑到特征只占图像的一小部分,并且同样的特征可能出现在不同图像的不同位置。卷积核的值是通过对模型的训练得到的。
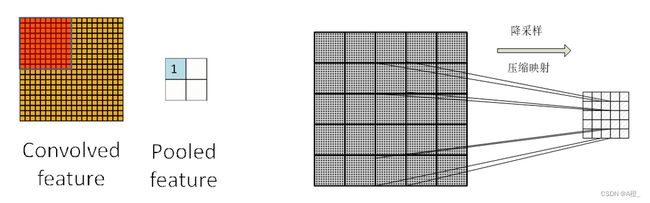
池化
池化的目的是降低特征维度,方式是对不同位置的特征进行聚合统计。聚合的方法有多种,包括平均池化和最大池化等。
全连接层
卷积神经网络上下层之间采用局部连接的方式构建网络,模拟了神经细胞只对局部区域有响应的现象。但在卷积和池化后,通常通过全连接层得到最终的结果。全连接神经网络是指对于n层和n-1层,n-1层的任意一个节点,都和第n层所有节点连接。

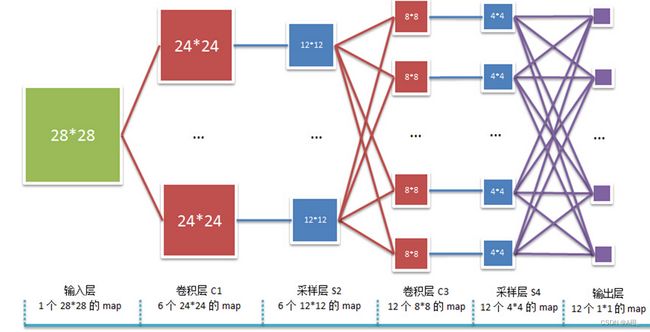
卷积神经网络
将卷积层、池化层、全连接网络进行组合,就能得到完整的卷积神经网络。通常卷积和池化会有许多层,进行特征的低层次到高层次的提取,最后通过一个全连接神经网络来进行分类。
3.循环神经网络RNN
循环神经网络通常用于自然语言处理。语言处理的特点是存在上下文的关联,因此神经网络必须要建立时序上的关系。RNN神经网络中,每个神经元既有当前得到输入,也接收之前的输出,通过共同作用来计算输出结果。通常使用循环神经网络来提取特征,最后通过全连接层实现目标输出。

三.实验内容
Keras是一个深度学习框架,封装了许多高层的神经网络模块,包括全连接层、卷积层等。本实验中的内容都是基于Keras实现的。
1.Keras构建CNN/RNN
构建CNN
Keras提供了一些简易的接口,能够快速构建卷积神经网络。步骤如下:
- 实例化Sequential对象(模型)
- 向模型中逐个添加层,对于CNN来说,要添加卷积层、池化层、全连接层等
- 编译模型,指定损失函数,参数的更新方法等
- 使用fit函数传入训练集进行训练,设定训练迭代次数和batch数量
- 使用训练好的模型进行预测
创建一个模型的示例如下:
model = keras.Sequential()
model.add(Conv2D(32, kernel_size=3, activation='relu', input_shape=[IMAGE_HEIGHT, IMAGE_WIDTH, 3]))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(32, kernel_size=3, activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Flatten())
model.add(Dense(96, activation='relu'))
model.add(Dense(2, activation='softmax'))
该模型包含两个卷积层,每个卷积层后有一个池化层,然后连接了一个扁平层,扁平层的作用是将多维的输入一维化,用在从卷积层到全连接层的过渡,最后连接了两个全连接层,输出结果。
该模型的结果是一个两位的向量。这个模型是用于分类问题的,由于图像共有两类,因此最后有两个值,这两个值就是图像属于其中一类的概率,选择概率大的作为分类的结果。在训练时的目标输出也要转换为这种形式,称为onehot编码,将分类值映射到整数值,将整数值表示为二进制向量,然后进行训练。

构建RNN
类似于构建CNN,Keras构建RNN的过程也很简单:
model = Sequential()
# 对输入的影评进行word embedding,一般对于自然语言处理问题需要进行word embedding
model.add(Embedding(1000, 64))
# 构建一层有40个神经元的RNN层
model.add(SimpleRNN(40))
# 将RNN层的输出接到只有一个神经元全连接层
model.add(Dense(1, activation='sigmoid'))
其中有一层Embedding层,这个层实现语义空间到向量空间的映射,把每个词语都转换为固定维数的向量,并且使语义接近的两个词转化为向量后,这两个向量的相似度也高。
2.基于Keras的人脸识别
实验使用的数据集由多张灰度图像组成,分辨率为284*286,标记为BioID_xxxx.pgm,平台以转换为JPG格式,xxxx为索引。共有16类人物,用字母A-V来表示。每个人物有20-50个样本。
读入数据
要构建一个图像分类的模型,图像的信息要分为两部分,一部分是图像本身的像素信息,另一类是图片的类别信息。使用OpenCv读入的图像信息是以BGR顺序读取的,需要转成RGB,并且要将图片裁剪成统一的大小。
加载图片:
def load_pictures():
pics = []
labels = []
for key, v in map_characters.items():
pictures = [k for k in glob.glob(imgsPath + "/" + v + "/*")]
for pic in pictures:
img = cv2.imread(pic)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (img_width, img_height))
pics.append(img)
labels.append(key)
return np.array(pics), np.array(labels)
其中map_characters存储了人物类别到数值的映射,A-V映射到0-15,作为图像的类别label信息。这个信息还需要转换为OneHot编码,在划分训练集和验证集时完成。
划分训练集和测试集,测试集比例为0.15。
def get_dataset():
X, Y = load_pictures()
Y = keras.utils.to_categorical(Y, num_classes) #转为OneHot编码
X_train, X_test = train_test_split(X, test_size=0.15)
y_train, y_test = train_test_split(Y, test_size=0.15)
return X_train, X_test, y_train, y_test
构建模型
实验构建的CNN模型有6个带有ReLU激活函数的卷积层和一个全连接的隐藏层,每两层卷积层后有池化层来减少参数,并有Dropout层来防止过拟合,将池化层的部分输出舍弃。最终的输出层输出图像属于各个类别的概率。
def create_model_six_conv(input_shape):
# ********** Begin *********#
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=input_shape))
#特征提取
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
#特征提取
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
#特征提取
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
#经过扁平层和全连接层,最终在输出层输出结果
model.add(Flatten()) #扁平层进行降维
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
return model;
模型训练
开始模型训练前需要设定一些参数。主要有以下部分:
- 优化器:模型使用随机梯度下降算法进行训练,优化器的相关参数有:
- 学习率lr:梯度下降法中调整参数的参数
- decay:大或等于0的浮点数,每次更新后的学习率衰减值
- nesterov:布尔值,确定是否使用Nesterov动量(动量方法可以在加速学习(加快梯度下降的速度),特别是处理高曲率、小但一致的梯度,或是带噪声的梯度。动量算法累积了之前梯度指数级衰减的移动平均,并且继续沿该方向移动。)。测试时发现如果不使用的话,在有限的训练时间内无法得到准确率足够高的模型。
- momentum:大或等于0的浮点数,动量参数
- loss:损失函数,对于分类问题,可以采用交叉熵损失函数(categorical_crossentropy)
- metrics:性能指标,采用准确率
- batch_size:一次训练采用的样本数据数量
- epochs:训练轮次
在训练过程中,可以随着训练循环次数的增加,对权重调整的学习率进行衰减。可以在保持一个恒定学习速率一段时间后立即降低,借助callbacks模块的一个方法 LearningRateScheduler [ 1 ] ^{[1]} [1]实现:
def lr_schedule(epoch):
initial_lrate = 0.01
drop = 0.5
epochs_drop = 10.0
lrate = initial_lrate * math.pow(drop, math.floor((1+epoch)/epochs_drop))
return lrate
此外,在测试时为了保证长时间的训练可以中途保存,使用callbacks模块的保存点来存储模型的权重,保存最好的模型。
lr = 0.01
sgd = SGD(lr=lr, decay=0.0 , momentum=0.9 , nesterov= True)
model.compile(loss= 'categorical_crossentropy' ,
optimizer= sgd,
metrics=['accuracy'] )
def lr_schedule(epoch):
lr = 0.01
drop = 0.5
epochs_drop = 10.0
lrate = lr * math.pow(drop, math.floor((1+epoch)/epochs_drop))
return lrate
batch_size = 32
epochs = 20
filepath = "model.h5"
history = model.fit(X_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(X_test, y_test),
shuffle=True, #打乱数据集
verbose = 0,
callbacks=[LearningRateScheduler(lr_schedule),
ModelCheckpoint(filepath, save_best_only=True)])
验证与评估
有了训练好的模型后,就可以进行模型的测试,测试数据的读入和训练时读入数据类似,包含图像的像素信息和label,并将label转换为onehot编码。
imgsPath = "/opt/test/"
def load_test_set(path):
pics, labels = [], []
map_characters = {0: 'A', 1: 'C', 2: 'D',
3: 'F', 4: 'G', 5: 'H', 6: 'I',
7: 'J', 8: 'K', 9: 'L', 10:'M',
11:'P', 12:'R', 13:'S', 14:'T', 15:'V'}
num_classes = len(map_characters)
img_width = 42
img_height = 42
map_characters = {v:k for k,v in map_characters.items()}
for pic in glob.glob(path+'*.*'):
name = "".join(os.path.basename(pic).split('_')[0])
if name in map_characters:
img = cv2.imread(pic)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (img_height,img_width)).astype('float32') / 255.
pics.append(img)
labels.append(map_characters[name])
X_test = np.array(pics)
y_test = np.array(labels)
y_test = keras.utils.to_categorical(y_test, num_classes) # one-hot编码
return X_test, y_test
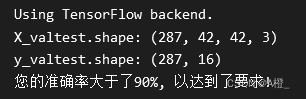
载入测试数据后,载入训练好的模型,使用模型对测试数据进行分类,并将分类结果与正确的类别进行比较,计算模型测试的准确率。
def acc():
model = load_model("model.h5")
# 预测与对比
y_pred = model.predict_classes(X_valtest)
acc = np.sum(y_pred==np.argmax(y_valtest, axis=1))/np.size(y_pred)
return(acc)
3.思考题-深度学习算法参数的设置对算法性能的影响
深度学习中的超参数是控制模型结构、训练效率、训练效果的关键。常见的超参数及对模型训练的影响如下:
-
学习率(Learning rate):决定在优化算法中更新参数权重的幅度。学习率可以是恒定的,逐渐降低的,基于动量的等 [ 2 ] ^{[2]} [2]。学习率的值应该设定在合适的范围内,过小会降低收敛速度,增加训练时间,过大则可能导致参数在最优解两侧振荡。学习率可以进行动态调整,一般在开始时较大,随着迭代次数的增加减小学习率,提高稳定性
-
迭代次数(Epoch):训练次数,次数少则训练效果可能不够好,次数过多可能导致过拟合
-
一次训练选取的样本数(Batch size):影响训练时间,过小则可能存在梯度振荡,过大则梯度准确,收敛快但容易陷入局部最优
-
优化器:常见的有SGD(随机梯度下降),Adagrad(自适应梯度下降,不同参数学习率不同 [ 3 ] ^{[3]} [3])等
-
激活函数:增加神经网络模型的非线性,要根据具体问题选择合适的激活函数。
-
损失函数:影响收敛速度和模型整体性能。回归模型常用的损失函数有均方损失函数MSE,平滑L1损失Huber,平均绝对误差MAE,分类问题常用交叉熵损失函数。
参考资料
[1] TEAM K. Keras documentation: LearningRateScheduler[EB/OL]//keras.io. https://keras.io/api/callbacks/learning_rate_scheduler/.
[2]深度学习中的超参数,以及对模型训练的影响_rnn模型超参数的影响_weixin_41783077的博客-CSDN博客[EB/OL]//blog.csdn.net. [2023-05-28]. https://blog.csdn.net/weixin_41783077/article/details/104022476.
[3]深度学习中的超参数调节(learning rate、epochs、batch-size…)[EB/OL]//知乎专栏. [2023-05-28]. https://zhuanlan.zhihu.com/p/433836153.
ng_rate_scheduler/.
[2]深度学习中的超参数,以及对模型训练的影响_rnn模型超参数的影响_weixin_41783077的博客-CSDN博客[EB/OL]//blog.csdn.net. [2023-05-28]. https://blog.csdn.net/weixin_41783077/article/details/104022476.
[3]深度学习中的超参数调节(learning rate、epochs、batch-size…)[EB/OL]//知乎专栏. [2023-05-28]. https://zhuanlan.zhihu.com/p/433836153.