OS实验之玩转linux内核
文章目录
- linux内核的编译初体验~
-
- 实验环境准备
- 编译linux内核
- 避免采坑
- 设计一个系统调用!
-
- 啥叫系统调用
- 加入自己的Hello World系统调用
- 避免采坑
- 设计一个动态调用模块!
-
- 啥叫动态模块
- 加入自己的Hello Module动态模块
- 避免采坑
-
- 模块签名
- \n!\n!\n!
- 实验一——设计一个系统调用
-
- 实验内容
- 前导知识
- 实验思路
- 代码实现
- 避免采坑
-
- vfs_read……
- 用户空间和系统空间
- sys_call_table地址
- 获取文件大小
- for_each_process
- 实验2-1——进程的软中断通信
-
- 实验内容
- 前导知识
-
- fork()
- signal()
- kill()
- 实验思路
- 代码实现
- 避免采坑
-
- while语句
- 信号忽略SIG_IGN
- 实验2-2——进程的管道通信
-
- 实验内容
- 前导知识
-
- 管道
- read()
- write()
- sprintf()
- lockf()
- 实现思路
- 代码实现
- 避免采坑
- 实验2-3——内存的分配与回收
-
- 实验内容
- 前导知识
-
- FF、BF、WF算法
- 链表
- 实现思路
- 代码实现
-
- 主要数据结构
-
- 内存空闲分区的描述
- 已分配内存块的描述
- 常量定义
- 函数模块
-
- 主函数及菜单
-
- 主函数
- 显示菜单
- 初始化内存
-
- 初始化空闲块
- 设置内存大小
- 设置内存算法
-
- 显示设置菜单
- 按指定算法重新排列空闲区链表
- 创建进程载入内存
-
- 创建新进程,获取内存申请数量
- 分配内存模块
- 紧缩处理
- 删除进程移出内存
-
- 删除进程
- 找到进程
- 归还分配区并合并
- 释放ab数据结构节点
- 显示内存状态
- 三种算法
-
- FF算法
- BF算法
- WF算法
- 退出程序
- 避免采坑
虽然用过linux系统,但是内核却一直没接触过。正好这学期的操作系统有实验课,要玩内核,就通过这门课好好学习一下内核相关的知识。在这里记录一下自己的linux内核学习过程和遇到的各种坑。如果写的有什么问题欢迎各位大佬指正。我会把源代码放到 GitHub上,有些代码(例如内存分配)比较长,因此可以直接从GitHub上下载下来,便于阅读。
linux内核的编译初体验~
编译实验第一个题目是要添加一个系统调用。但是不管什么题目,都得重新编译内核,所以首先我得学习如何编译linux内核。
实验环境准备
我用的环境是VM Ware + Ubuntu Server18.04.3 LTS(没有图形化界面,操作方便且占用内存较小)。给的配置为4GB内存,50GB硬盘,4核处理器。
声明:我所有的命令没有特殊说明都是在root用户下执行的,因此没有sudo,如果你在非root用户下执行可能需要sudo。
首先查看当前使用的linux版本:
uname -r
![]()
可以看到我初始的版本是4.15.0-66,然后下载你想要的内核,在 https://mirrors.edge.kernel.org/pub/linux/kernel/ 上找到你想要的内核并下载,例如我下载的是linux-4.16.10.tar.xz:
wget https://mirrors.edge.kernel.org/pub/linux/kernel/v4.x/linux-4.16.10.tar.xz
下载完成后解压到linux-4.16.10文件夹:
tar xvJf linux-4.16.10.tar.xz
解压完成后就是修改并编译linux啦。
编译linux内核
编译linux内核前首先我们要配置相应的环境。要求至少给虚拟机50G的磁盘空间(没有50G也尽量越多越好),不然编四五个小时最后提示你没有空间了要重新编译那直接原地裂开。
然后安装相应的依赖包和软件工具:
apt-get install libncurses5-dev libssl-dev zlibc minizip build-essential openssl libidn11-dev libidn11
apt-get install git fakeroot ncurses-dev xz-utils bc flex libelf-dev bison
安装完之后cd linux-4.16.10进入文件夹内,如果你是第一次编译,那么使用:
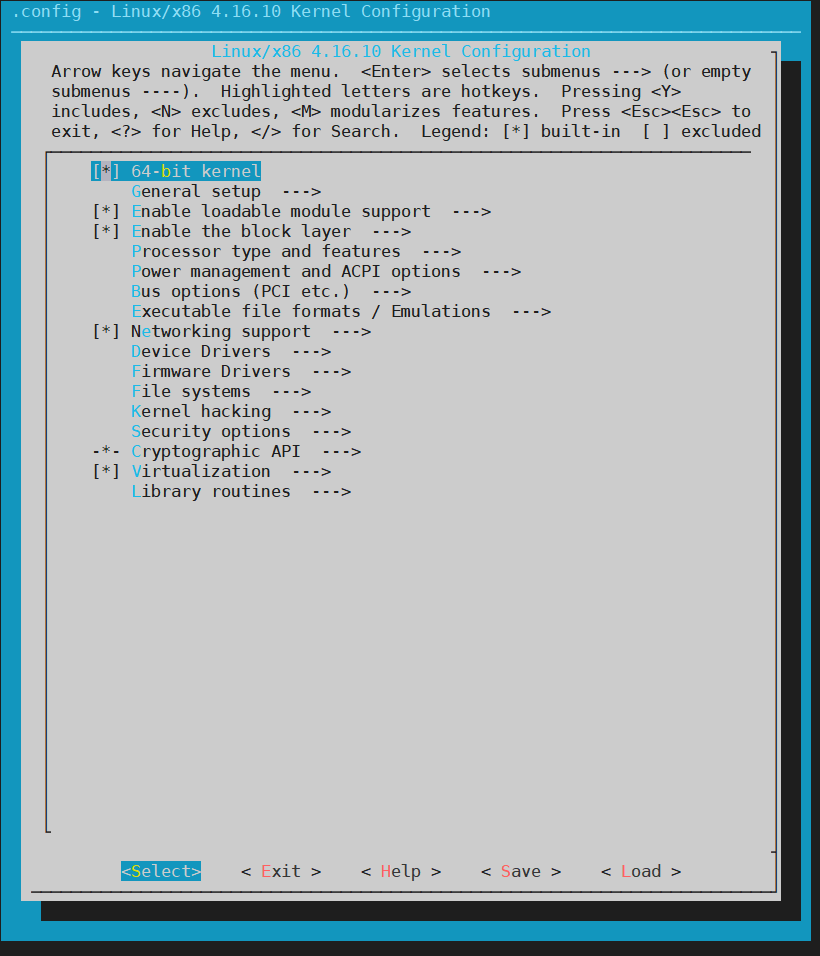
make menuconfig
进行配置,这个命令打开一个配置工具,允许我们定制自己的内核。
如果不是第一次编译,那么首先要清除之前编译产生的中间文件。输入以下指令:
make mrproper
mrproper是清除编译过程中产生的所有文件、配置和备份文件(Remove all generated files + config + various backup files)或者你也可以用:
make clean
这是清除编译过程中产生的大多数文件,但会保留内核的配置文件,同时还有足够的编译支持来建立扩展模块( Remove most generated files but keep the config and enough build support to build external modules)。
由于是第一次并且是以学习编译为目的,因此我们使用默认配置就好。直接save->ok->exit->exit。
配置完了之后就可以开始编译了
直接输入make就可以开始编译。当然,你可以采用多线程编译,这样速度会快一点。命令是:
make -j8
-jx中的x是make并行编译的线程数,给多少随意,一般这个数值为内核数*2比较合适,比如说我给了虚拟机4核,那么我就-j8。
但是需要注意的是:如果你修改了内核,而且不知道对不对,那么最好不要多线程编译。因为如果一个线程出错了的话,编译不会停止,其他线程会继续编译,其他线程编译的内容就会把出错的信息刷掉,这样一来你就无法知道自己编译的是否正确以及出错的位置在哪(血的教训)。
由于是编译整个内核,因此编译时间很长,接下来就是耐心的等待了。
编译过程如图:
编译完成后开始安装之前启用的模块:
make modules_install
安装完成之后接着安装内核:
make install
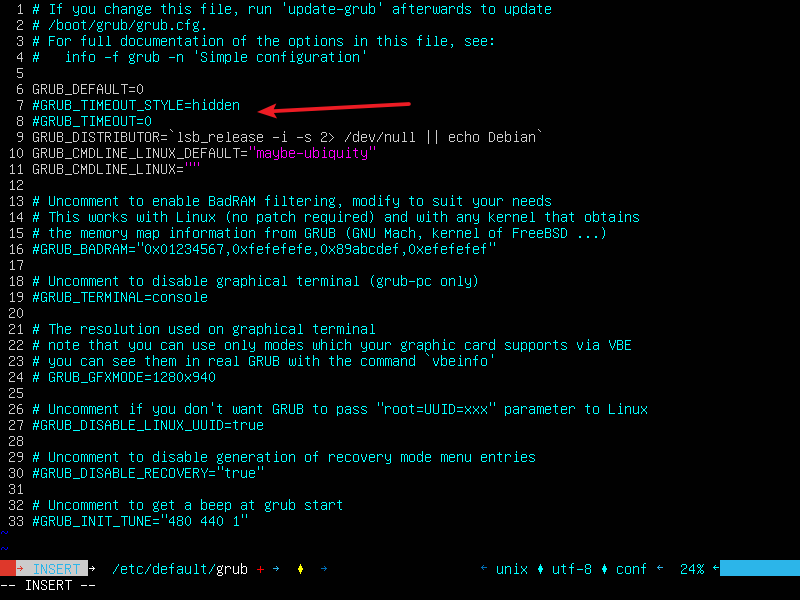
安装完内核之后我们需要启用编译好的内核,打开/etc/default/grub:
vim /etc/default/grub
按i进行编辑,找到并注释掉GRUB_TIMEOUT_STYLE=hidden和GRUB_TIMEOUT=0,如图所示:
修改完成后先按esc退出编辑模式,再按:wq保存退出,然后更新配置并重新启动:
update-grub
reboot
重启后出现菜单:
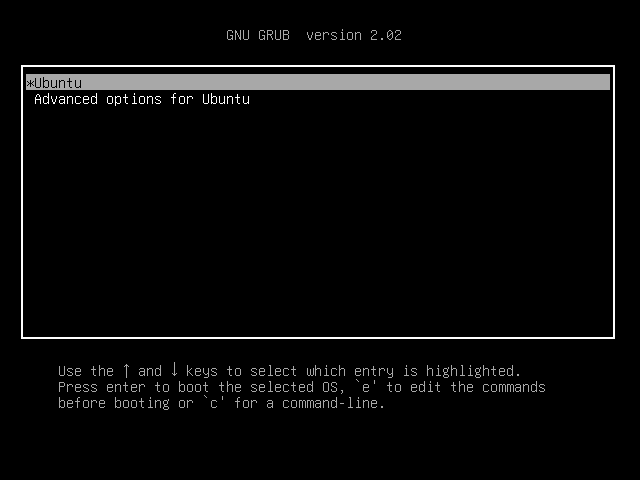
直接进入就启用了我们编译好的内核了。如果想要切换内核,就选Advanced options for Ubuntu,这一栏就可以选择想要使用的内核了:

避免采坑
正常操作到这就完成了。但是这时候我遇到了问题,我在编译完成之后发现无法使用新内核进入系统,如图:
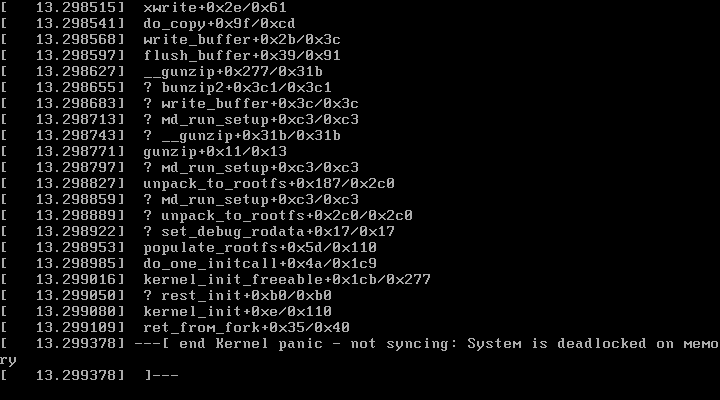
后来在网上查找发现造成这种错误的一个可能的原因是内存太小,我本来的配置是2GB(我寻思也不小啊),改成4GB之后就能正常启动了。
打开之后用uname -r看看内核版本:
![]()
是4.16.10,我们成功了!至此,我们第一个内核就算正是编译完成了,撒花!
下面我们就可以对新鲜出炉的内核动手动脚啦hiahiahia。
设计一个系统调用!
光会编译内核,还不能算入门,只能算看到了门。真正想要“玩”内核,就必须要学会修改内核,让内核变得更加个性化。一开始我们举一个最简单的例子,也是编译实验原理课的第一个实验,设计一个系统调用!
啥叫系统调用
系统调用,听着很高大上,但千万不要被它的名字吓到,其实简单理解它就是一内核调用的函数,而不是用户调用的。
维基百科是这样定义的:系统调用(英语:system call),指运行在用户空间的程序向操作系统内核请求需要更高权限运行的服务。系统调用提供用户程序与操作系统之间的接口。
举个简单的例子,我去别人家做客,我想玩他家的乐低,但是乐高在人家卧室里,我没有权限进去,那咋办嘞?我就给主人说,“我想玩你的乐低,请帮我拿一下。”主人说没问题,起身进去帮我拿了出来,然后我开心的玩起了乐低。这时候,“我”就是用户,“主人”就是内核,而“玩乐低”是需要更高权限运行的服务,“帮我拿乐低”就是一个接口,由于这个动作是“主人”发出的(这个函数是内核调用的),那么这就是一个系统调用。
加入自己的Hello World系统调用
参考《操作系统作业:给linux系统增加一个系统调用》。
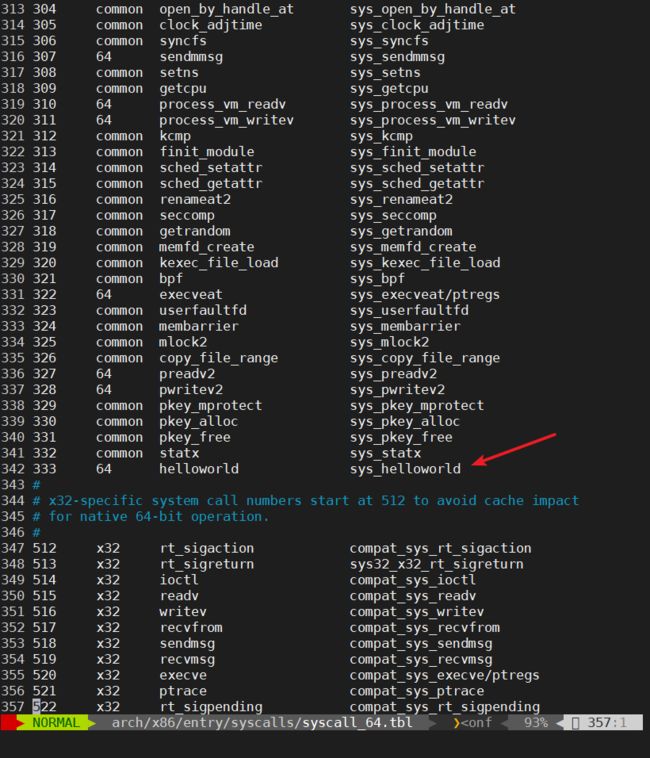
首先在系统调用表linux-4.16.10/arch/x86/entry/syscalls/syscall_64_tbl中定义自己的系统调用的调用号和系统调用函数的映射。
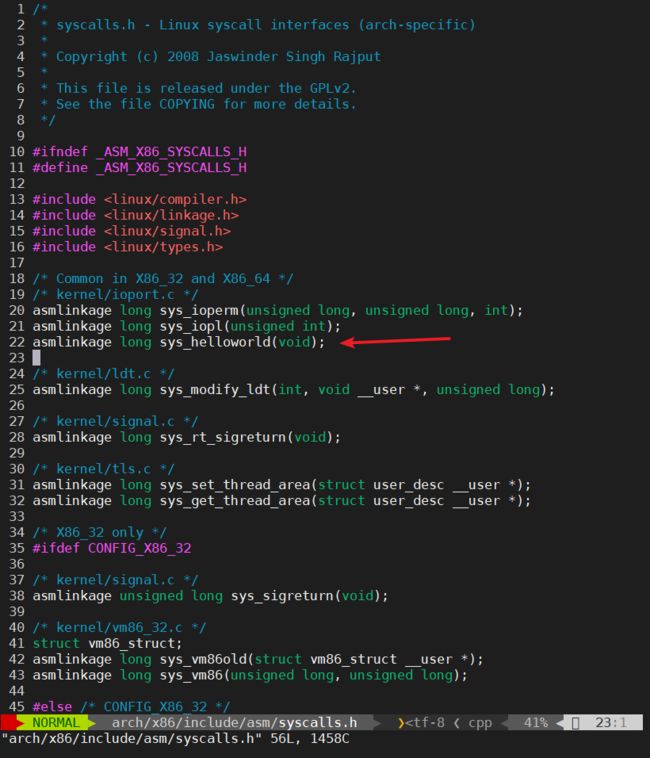
然后在头文件linux-4.16.10/arch/x86/include/asm/syscalls.h中声明自己的系统调用
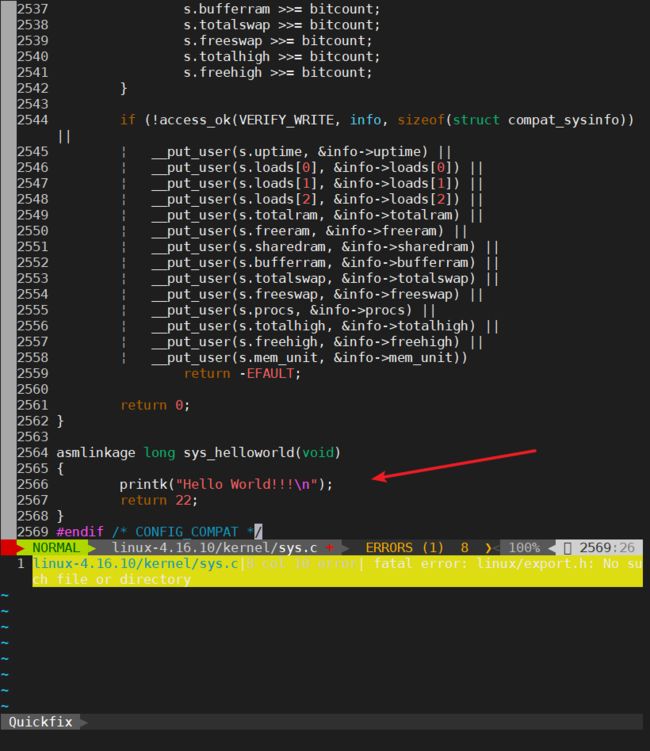
然后在把具体调用的实现函数写在linux-4.16.10/kernel/sys.c里:
然后重新编译内核,不要忘了重启。编译好了之后我们写一个测试代码test.c来看看能否成功执行我们的系统调用:
//test.c
#include 用gcc -o test test.c来编译,编译完成后用./test来运行:
![]()
可以看到输出了22,证明我们的系统调用成功的被执行了!
但是为什么没有“Hello World!!!”呢?是因为printk函数输出的信息具有日志级别,简单来说就是printk输出的内容输出到了内核日志里,我们可以通过dmesg命令查看内核日志:
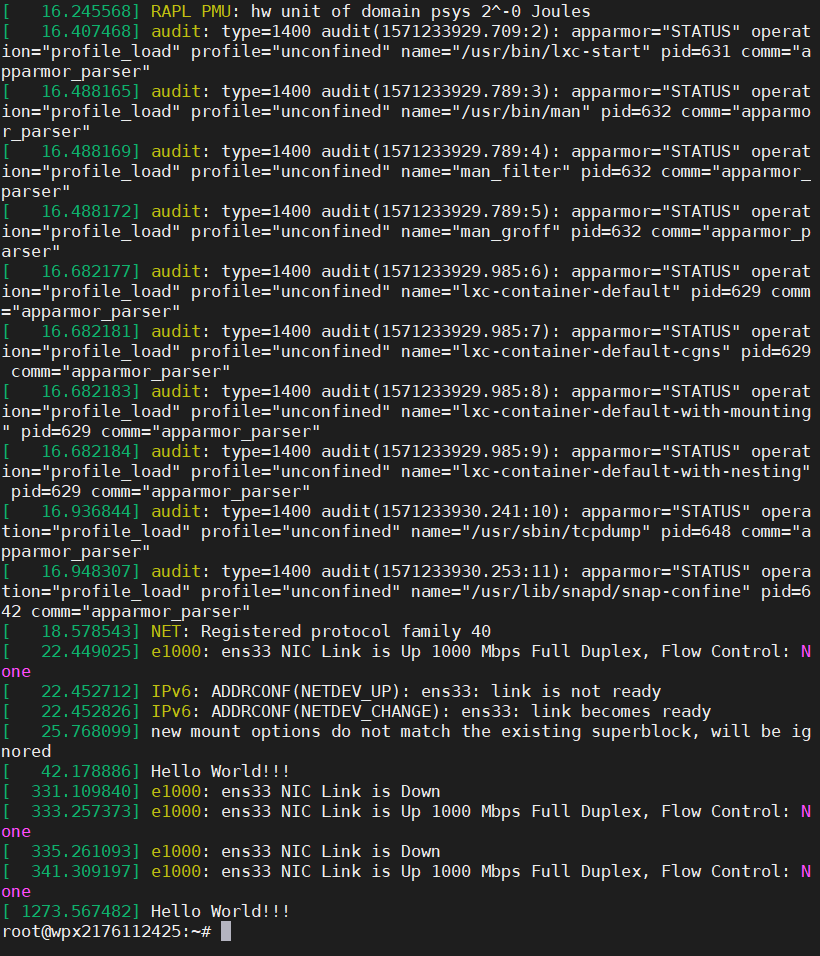
可以看到最后一行就是我们输出的信息“Hello World!!!”,也同样证明我们的系统调用成功实现了!
那如果我们就想让它输出到终端可以吗?也是可以的,这就涉及到printk的知识点了。
内核通过 printk() 输出的信息具有日志级别,内核中共提供了八种不同的日志级别,在 linux/kernel.h 中有相应的宏对应。
#define KERN_EMERG "<0>" /* system is unusable */
#define KERN_ALERT "<1>" /* action must be taken immediately */
#define KERN_CRIT "<2>" /* critical conditions */
#define KERN_ERR "<3>" /* error conditions */
#define KERN_WARNING "<4>" /* warning conditions */
#define KERN_NOTICE "<5>" /* normal but significant */
#define KERN_INFO "<6>" /* informational */
#define KERN_DEBUG "<7>" /* debug-level messages */
未指定日志级别的 printk() 采用的默认级别是 DEFAULT_MESSAGE_LOGLEVEL,这个宏在 kernel/printk.c 中被定义为整数 4,即对应KERN_WARNING。
当printk中指定的级别(级别越小优先级越高)小于当前控制台日志级别时,printk的信息就会在控制台上显示。
所以如果我们想把Hello World打印到控制台上,可以在输出的文本前加上KERN_ALERT(其他也可以只要优先级大于控制台日志级别):
printk(KERN_ALERT "Hello World!\n");
但是这种方法要求每次输出前都要加上,比较麻烦。还有一种一劳永逸的方法,输入以下命令:
echo 4 3 > /proc/sys/kernel/printk
如果你不是root用户,那么使用如下命令:
echo 4 3 | sudo dd of=/proc/sys/kernel/printk
在 /proc/sys/kernel/printk中会显示4个数值(可由 echo 修改),分别表示:
- 当前控制台日志级别;
- 未明确指定日志级别的默认消息日志级别;
- 最小(最高)允许设置的控制台日志级别;
- 引导时默认的日志级别;
上述命令就将默认消息日志级别改为了3,而控制台日志级别为4,这样就可以输出到屏幕了。

注意:修改用echo修改,不能用vim(但好像个别可以),否则会报Fsync failed错。因为vim编辑文件是首先创建该文件的一个副本,当保存的时候就用这个副本替换掉原文件。而proc文件系统下的文件并不是真的文件,都是内存中的影像,因此不支持这种编辑方式,所以不能用vim。
避免采坑
我的实验是基于4.16.10版本的。内核版本不同,系统调用的修改可能也略有不同。
缩进最好使用tab键(就是键盘q左边的那个),不要用空格,否则可能有不可预料的错误。
设计一个动态调用模块!
相信很多初学者和我一样,每次修改一下系统调用就要重新编译整个内核,这样做既耗费时间,效率也非常非常低。所以我们现在来一起学习一下动态模块,这样以后我们想加什么功能就直接以动态模块的形式加入到内核,修改之后只用编译我们这个模块就行了。
啥叫动态模块
维基百科是这样定义的:可加载内核模块(英语:Loadable kernel module,缩写为 LKM),又译为加载式核心模块、可装载模块、可加载内核模块,或直接称为内核模块,是一种目标文件(object file),在其中包含了能在操作系统内核空间运行的代码。它们运行在核心基底(base kernel),通常是用来支持新的硬件,新的文件系统,或是新增的系统调用(system calls)。当不需要时,它们也能从存储器中被卸载,清出可用的存储器空间。
由于 Linux属于单内核,单内核扩展性与维护性都很差(大家编译了这么多次内核应该已经深有体会{{xiaoku}}),所以就引入了这么个动态模块,这样一来就大大方便我们添加和修改自己想要的功能。一般动态模块主要是用来写驱动的。
加入自己的Hello Module动态模块
那么废话少说,现在就让我们来写一个动态模块吧。
首先mkdir mod_hello新建一个文件夹,然后在里面创建我们的动态模块源码mod_a.c:
//mod_a.c
//动态模块必须要的三个头文件
#include现在我们就写好了一个模块。这个模块的功能就是在安装的时候输出“Hello Module!”,卸载的时候输出“Goodbye Module!”。下面我们开始写Makefile:
CONFIG_MODULE_SIG=n
ifneq ($(KERNELRELEASE),)
obj-m :=mod_a.o
else
KERNELDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
modules:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
clean:
$(MAKE) -C $(KERNELDIR) M=$(PWD) clean
endif
关于Makefile的语法这里就不细讲了,有兴趣的同学可以自己学习一下,不难。写好了之后就可以make编译啦:
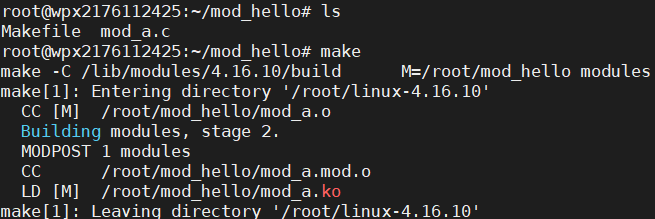
生成mod_a.ko文件就说明成功啦。下面就是如何装载和卸载模块了
insmod mod_a.ko //装载模块
rmmod mod_a //卸载模块
装载模块之后我们可以通过lsmod查看系统已装载的模块:

可以看到我们的模块已经加载到了系统中。现在看看系统日志测试一下我们的语句有没有输出:
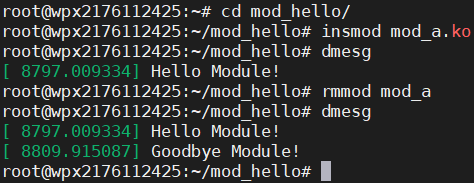
可以看到已经成功输出了,说明我们成功的完成了动态模块的加载!
如果你在加载模块的时候出现以下错误:
![]()
那是因为你之前已经装载过了该模块,所以先卸载这个模块再重新装载就可以了。
避免采坑
模块签名
我刚开始测试的时候,发现日志中报错,然后没有输出:
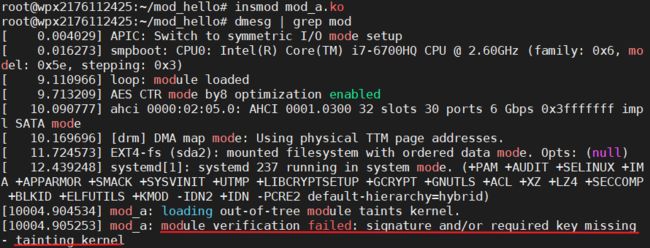
这个报错是因为在3.7版本后内核有了模块签名机制,如果模块没有签名在加载的时候就会报这个错。这个有两种解决办法,一种是给模块签名,一种是关掉签名检查机制。这里给出第二种。
关掉签名检查机制一种说法是在Makefile的开头加上CONFIG_MODULE_SIG=n,但是在我测试的时候发现好像没啥用。第二种方法是直接修改内核配置文件,在make menuconfig后修改linux-4.16.10/.config(这是一个隐藏文件):
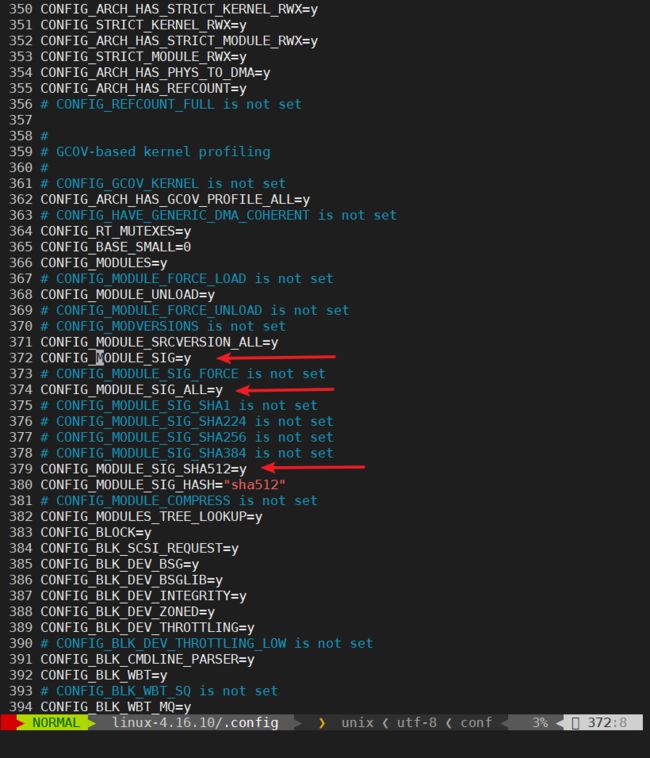
将CONFIG_MODULE_SIG=y、CONFIG_MODULE_SIG_ALL=y和CONFIG_MODULE_SIG_SHA512=y的y都改成n,然后重新编译内核,经过测试这种方法可以解决问题。
但是经过测试我发现这个签名的报错好像也没什么影响,还是可以正常的输出“Hello Module!”……有点迷,不是很懂。
\n!\n!\n!
在我还没有解决上面报错的问题时,我又发现一个很奇怪的现象:

我加载内核的时候输出的是Goodbye我卸载内核的时候输出的是Hello。
我百思不得其解,查了大量的资料,都没找到答案。后来发现……
原因竟然是的因为我printk中没有换行符\n所以实际上输出了但是没有显示在日志里,所以看不见。等到我再加载的时候hello就把goodbye顶上来了所以我只能看见hello。{{tuxue}}{{tuxue}}{{tuxue}}
我就说为啥测试的时候第一遍加载没有输出,卸载输出hello,然后加载输出goodbye,卸载输出hello开始循环。我在这个\n上吃了不少苦头,在上面设计系统调用的时候我一开始也没有加\n,上面那个图加了换行符是我做到这才反应过来换上去的,实际上上面那个图中输出的“Hello World!!!”是我在截图之前测试了两次,把第一次的顶上来了,我当时以为是输出了,写的时候我还纳闷怎么突然又输出来了{{tuxue}}
这个换行符坑了我不知道多少时间,来来回回我因为测试结果有问题又重新编译了好几次内核{{outu}}
实验一——设计一个系统调用
知道了如何设计系统调用,我们就可以开始做第一个实验了。
实验内容
设计一个系统调用,功能是将系统的相关信息(CPU型号、操作系统的版本号、系统中的进程等类似于Windows的任务管理器的信息)以文本形式列表显示于屏幕,并编写用户程序予以验证。
前导知识
要输出CPU型号,操作系统的版本号和系统中的进程,首先得知道我们去哪里找这些信息。
CPU型号和操作系统我们可以在/proc文件夹下找到:
cat /proc/cpuinfo #cpu信息
cat /proc/version #系统版本信息
关于/proc文件夹,在“加入自己的Hello Module动态模块”的最后我提到了一下。实际上/proc是一个位于内存的伪文件系统,通过/proc我们可以运行时访问内核内部数据结构、改变内核设置的机制。用户和应用程序可以通过/proc得到系统的信息,并可以改变内核的某些参数。由于系统的信息,如进程,是动态改变的,所以用户或应用程序读取/proc文件时,/proc文件系统是动态从系统内核读出所需信息并提交的。 注意/proc里面的文件不是真的存在于硬盘中的文件,它们只是内存中的映像。
系统中的进程相关信息记录在task_struct结构体中。task_struct是Linux内核的一种数据结构,它会被装载到RAM中并且包含着进程的信息。每个进程都把它的信息放在 task_struct这个数据结构体。具体使用在代码中就可以看到。
这两部分内容这里都只是简单提了一下,如果要是深入讲解那又可以写两篇文章了,秉着知识屏蔽的原则,这里不展开讲了。各位读者感兴趣可以自学一下。
实验思路
我们要设计一个系统调用,如果直接修改内核添加系统调用然后编译内核进行调试,那效率实在是太低(一次写成的大佬当我没说),因此我首先用动态模块把程序写好,然后再添加到系统调用里并重新编译,这样就大大提高了效率。
实际上,也可以用动态模块直接写一个钩子来修改系统调用(注意是修改不是添加,动态模块没法添加系统调用,但是可以修改现有的系统调用),但是由于要利用sys_call_table表,而在实验过程中发现4.16.10版本中获取sys_call_table表的地址存在许多问题,由于我目前水平太菜还没有解决,所以这种方法先暂时不用,以后应该会更新这个方法。
这个实验思路很直接,就是找到所需要的信息并打印出来。
代码实现
知道了信息的位置,那剩下的就是代码实现了。这里给出我的动态模块源代码:
#include需要注意的是第一个输出CPU型号的buf和pos需要自己设置成适合自己的,因为每个人的CPU型号不同,我设置测试的最终结果如图,正好把我的型号输出出来:

现在加载我们的模块看看效果(长图预警):

看上去还不错!那么现在我们就可以把它添加到系统调用里去了,添加方法上文已经说了。(修改sys.c的时候不要忘了添加头文件哦!)
最终添加的系统调用号为334,调用具体代码如下:
asmlinkage long sys_getinfo(void)
{
static char buf[41];
static char buf1[1024];
struct task_struct *p;
struct file *fp;
mm_segment_t fs;
loff_t pos;
//准备打印CPU型号
printk("/***************cpu info****************/\n");
fp = filp_open("/proc/cpuinfo",O_RDONLY,0);//打开文件并存到结构体中,准备进行后续操作
if(IS_ERR(fp)) //判断文件是否正常打开
{
printk(KERN_ALERT "create file error\n");
return -1;
}
fs = get_fs();
set_fs(KERNEL_DS);
pos = 79; //文件操作的起始位置
kernel_read(fp,buf,sizeof(buf),&pos);
printk(KERN_ALERT "%s\n",buf);
filp_close(fp,NULL);
set_fs(fs);
//准备打印系统版本信息
printk(KERN_ALERT "/***************system version****************/\n");
fp = filp_open("/proc/version",O_RDONLY,0);//open file
if(IS_ERR(fp))
{
printk(KERN_ALERT "create file error\n");
return -1;
}
fs = get_fs();
set_fs(KERNEL_DS);
pos = 0;
kernel_read(fp,buf1,sizeof(buf1),&pos);
printk(KERN_ALERT "%s\n",buf1);
filp_close(fp,NULL);
set_fs(fs);
//准备打印进程信息
printk(KERN_ALERT "/*************processes information**************/\n");
printk(KERN_ALERT "%-20s%-10s%-15s%-15s%-10s\n","name","pid","time(userM)","time(kernelM)","state");
for_each_process(p)
{
printk(KERN_ALERT "%-20s%-10d%-15lld%-15lld%-5ld\n",p->comm,p->pid,(p->utime)/60,(p->stime)/60,p->state);
}
return 334;
}
用上次测试系统调用的程序测试一下:
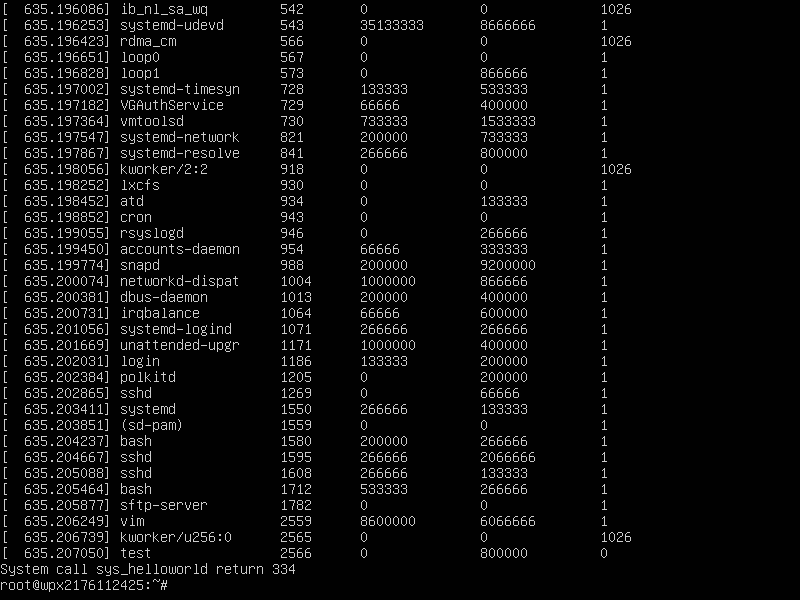
输出到了控制台中,系统调用成功!
注意:我使用的是ubuntu server,使用的终端是物理终端,而printk输出的位置就是物理终端,如果你使用的是图形化界面,那么你可能会发现信息没有输出到你的终端上,因为图形化界面使用的不是物理终端,需要用户更改为物理终端,更改方法可以在网上查找资料。
避免采坑
vfs_read……
我看网上说内核用vfs_read、vfs_write等函数来操作文件,但是我写的时候报错说未定义的函数。我找了半天最后发现是在4.14版本以后,内核不再支持vfs_read、vfs_write等函数,而是改用kernel_read、kernel_write等函数。如果使用vfs_read、vfs_write等函数会报错。把vfs改成kernel就好了。
用户空间和系统空间
在对文件进行操作的时候,我直接使用了kernel_read函数,然后报错了。后来发现是因为kernel_read等函数它们默认的参数(buf)是指向用户空间的内存地址,而现在buf在内核空间,因此会出错。这个可以通过get_fs和set_fs修改。简单来说就是这样:
mm_segment_t fs = get_fs();
set_fs(KERNEL_DS);
//然后开始文件操作例如kernel_read()
filp_close(fp,NULL);
set_fs(fs);
具体的知识点这里不讲了,有兴趣的可以自行上网学习,这里给一篇参考文章:《在linux内核中读写文件》。
sys_call_table地址
本来我想直接用动态模块写个钩子修改系统调用,结果获得地址之后运行发现永远不对,后来发现在linux2.6版本之后,出于保护系统的目的,不能直接导出sys_call_table的地址,因此使用如下命令得到的地址不是真实的物理地址,不能直接使用:

否则会报错,而且模块无法通过rmmod命令卸载,会显示正在使用,非常棘手(有解决办法,但很麻烦,所以我每次都是直接恢复快照)。
获取文件大小
在写代码的时候因为cpuinfo太长了打印不完,我一开始想动态获取文件大小然后再打印整个文件。在网上找了很多办法,看到别人用f->f_dentry->d_inode,但是我每次都报错,后来发现是在3.19版本之后内核不支持f->f_dentry->d_inode了,需要使用file_inode(f)替换掉f->f_dentry->d_inode。具体如下:
Linux 3.19 compat: file_inode was added
struct access f->f_dentry->d_inode was replaced by accessor function
file_inode(f)
Signed-off-by: Joerg Thalheim
Signed-off-by: Brian Behlendorf
修改之后编译成功了发现获取的大小是0,后来才反应过来/proc中的文件不是真的文件因此没有大小可言……再后来反应过来要求不是要CPU型号嘛,那我直接光输出个型号不就可以了吗{{xieyanxiao}}
for_each_process
在使用 for_each_process时,有很多资料显示需要添加的头文件为linux/sched.h,但我编译的时候发现报错:
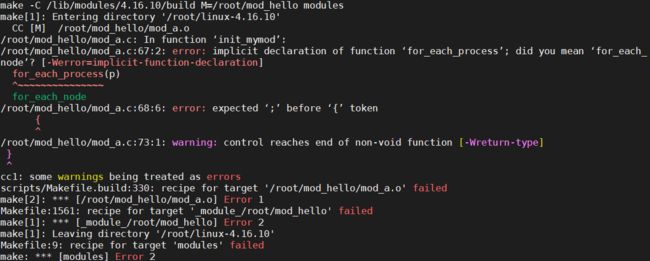
后来发现在 4.11以后,该方法都放在了include/linux/sched/signal.h中 ,因此需要修改头文件,修改之后就好了。
实验2-1——进程的软中断通信
实验内容
编制实现软中断通信的程序。使用系统调用fork()创建两个子进程,再用系统调用signal()让父进程捕捉键盘上发出的中断信号(即按delete键),当父进程接收到这两个软中断的某一个后,父进程用系统调用kill()向两个子进程分别发出整数值为16和17软中断信号,子进程获得对应软中断信号,然后分别输出下列信息后终止:
- Child process 1 is killed by parent !!
- Child process 2 is killed by parent !!
父进程调用wait()函数等待两个子进程终止后,输出以下信息,结束进程执行:
- Parent process is killed!!
多运行几次编写的程序,简略分析出现不同结果的原因。
前导知识
fork()
这里简单说一下,fork()的作用就是创建一个子进程,fork把父进程复制一份给子进程,需要注意的是fork返回值是两个。在子进程中返回0,父进程中返回子进程的pid,还有一种情况是创建失败时会返回-1。
如果想深入了解推荐一个大佬的博客,写的有多好呢?这么说吧,我第一次见到CSDN光评论就几百条的(可能是我见识太少):《linux中fork()函数详解(原创!!实例讲解)》
signal()
捕捉中断信号sig后执行function规定的操作。就有点像if语句,捕获到信号之后就调用指定的函数。
用法如下:
#include sig一个有19个值:
| 值 | 名字 | 说明 |
|---|---|---|
| 01 | SIGHUP | 挂起 |
| 02 | SIGINT | 中断,当用户从键盘键入“del”键时 |
| 03 | SIGQUIT | 退出,当用户从键盘键入“quit”键时 |
| 04 | SIGILL | 非法指令 |
| 05 | SIGTRAP | 断点或跟踪指令 |
| 06 | SIGIOT | IOT指令 |
| 07 | SIGEMT | EMT指令 |
| 08 | SIGFPE | 浮点运算溢出 |
| 09 | SIGKILL | 要求终止进程 |
| 10 | SIGBUS | 总线错误 |
| 11 | SIGSEGV | 段违例,即进程试图去访问其地址空间以外的地址 |
| 12 | SIGSYS | 系统调用错 |
| 13 | SIGPIPE | 向无读者的管道中写数据 |
| 14 | SIGALARM | 闹钟 |
| 15 | SIGTERM | 软件终止 |
| 16 | SIGUSR1 | 用户自定义信号 |
| 17 | SIGUSR2 | 用户自定义信号 |
| 18 | SIGCLD | 子进程死 |
| 19 | SIGPWR | 电源故障 |
kill()
一个进程向同一用户的其他进程pid发送信号。
用法为:
#include pid:可能选择有以下四种
- pid大于零时,pid是信号欲送往的进程的标识。
- pid等于零时,信号将送往所有与调用kill()的那个进程属同一个组的进程。
- pid等于-1时,信号将送往所有调用进程有权给其发送信号的进程,除了进程1(init)。
- pid小于-1时,信号将送往以-pid为组标识的进程。
sig:准备发送的信号代码,假如其值为零则没有任何信号送出,但是系统会执行错误检查,通常会利用sig值为零来检验某个进程是否仍在执行。
返回值说明: 成功执行时,返回0;失败返回-1。
实验思路
要求很明确,很直接。需要注意的就是在代码实现的时候注意写父进程和子进程的运行语句的位置,有的时候很容易把人绕进去。
代码实现
/* ex2.c
* Copyright (c) wpx
*/
#include 运行程序,键盘输入Quit信号(ctrl+\),子进程12退出,父进程等待3秒后退出:
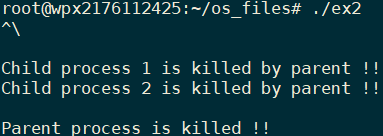
多次执行会发现子进程结束时间不确定:

原因可能是因为子进程之间是彼此并行的,两个子进程同时获得信号,因此结束时间不确定。
避免采坑
while语句
我在创建子进程的时候少加了一个括号,我是这样写的:
while(p1 = fork() == -1);
在运行程序的时候死活没结果,输入啥也不行,ctrl+\没有反应只能ctrl+c强制退出
后来发现其实我在这一步就有问题了,正确的写法是这样的:
while((p1 = fork()) == -1);
加个括号之后,程序就成功运行了。
信号忽略SIG_IGN
我的代码在子进程中有一句signal(SIGQUIT,SIG_IGN),实际上在一开始我并没有加这句代码。在我运行的过程中我发现,不管我试了多少次,子进程都没有输出,只有父进程输出了:
后来我发现如果我不用键盘输入quit,而是在一个新的终端中用kill命令给父进程quit信号,那么就能正常输出。
先通过ps -a获取父进程pid号(pid最小的就是父进程),然后使用kill -QUIT 父进程pid号给进程发送信号:
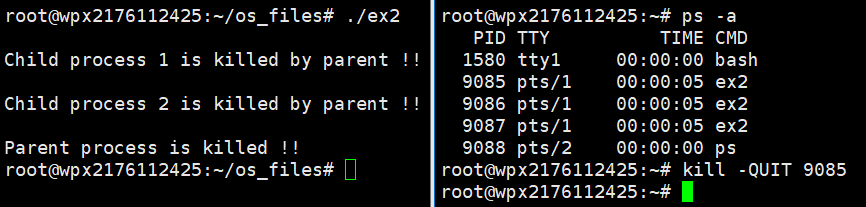
可以看到通过这种方式成功输出了我们想要的结果。我想了半天,但是还是没懂到底是怎么回事。我猜测可能是因为键盘直接输入的方式同时作用于三个进程,直接杀死了剩下两个子进程导致没有输出。所以在子进程中加上忽略Quit信号,这样quit只作用于父进程,子进程就可以收到父进程的信号打印语句了。
实验2-2——进程的管道通信
实验内容
创建一条管道完成下述工作:
- 分配一个隶属于root文件系统的磁盘和内存索引结点inode.
- 在系统打开文件表中分别分配一读管道文件表项和一写管道文件表项。
- 在创建管道的进程控制块的文件描述表(进程打开文件表u-ofile) 中分配二表项,表项中的偏移量filedes[0]和filedes[1]分别指向系统打开文件表的读和写管道文件表项。
系统调用所涉及的数据结构如下图所示:

前导知识
管道
所谓“管道”,是指用于连接一个读进程和一个写进程以实现他们之间通信的一个共享文件,又名pipe文件。管道分为匿名管道和命名管道。向管道(共享文件)提供输入的发送进程(即写进程),以字符流形式将大量的数据送入管道;而接受管道输出的接收进程(即读进程),则从管道中接收(读)数据。由于发送进程和接收进程是利用管道进行通信的,故又称为管道通信。
管道分为匿名管道和命名管道,匿名管道只能用于有亲缘关系的进程(这是由管道利用fork的实现机制所决定的),而命名管道可以用于任意两个进程。由于本实验不涉及命名管道,所以暂且不提,有兴趣的读者可以自行学习。
匿名管道通过int pipe(int fd[2])创建。管道通过read和write函数进行读写。fd[0]是读端,fd[1]是写端。两个进程分别使用读和写端,就可以实现通信。注意在读或写的时候需要用lockf锁定当前端,或者用close关闭另一端
read()
头文件:#include
函数定义: ssize_t read(int fd, void * buf, size_t count);
函数说明:read从fd中读取count个字节存入buf中。
write()
头文件:#include
函数定义:ssize_t write(int fd, void * buf, size_t count);
函数说明:write把buf中的count个字节写入fd中。
sprintf()
和printf类似,只不过printf把格式化内容打印到屏幕上,而sprintf把格式化的内容保存到字符串中。例如:sprintf(s,“%d”,123); //把123保存在s中
lockf()
头文件:#include
函数定义: int lockf(int fd, int function, long size)
函数说明:fd是文件描述符,function表示锁状态,1表示锁定,0表示解锁,size是锁定或解锁的字节数,若为0则表示整个文件。
实现思路
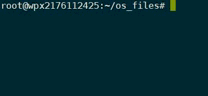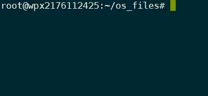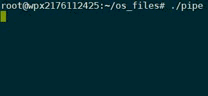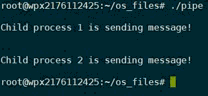
这个实验实际上意思就是父进程创建两个子进程,子进程分别通过管道给父进程发送一条信息“Child process 1 is sending message!”、“Child process 2 is sending message!”,父进程获取并打印消息然后退出。
代码实现
使用lockf,如果要用close的话就把lockf删了,然后把close的注释符删掉
#include 实验结果如图:

但有趣的是,使用lockf和close的运行结果有些许差异,使用lockf是先输出p1再输出p2,而使用close则几乎同时输出。
使用lockf:
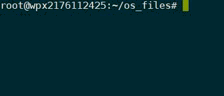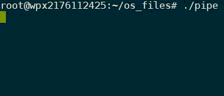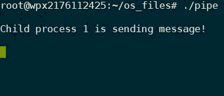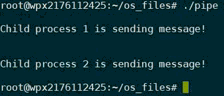
使用close:
具体原因不是很懂,如果有知道的大佬请教教小弟。
避免采坑
这个实验比较简单,我在做的时候没有什么困扰我很久的坑。就是注意几个函数的用法、参数的位置就行了。
实验2-3——内存的分配与回收
实验内容
通过深入理解内存分配管理的三种算法,定义相应的数据结构,编写具体代码。 充分模拟三种算法的实现过程,并通过对比,分析三种算法的优劣。
(1)掌握内存分配FF,BF,WF策略及实现的思路;
(2)掌握内存回收过程及实现思路;
(3)参考给出的代码思路,实现内存的申请、释放的管理程序,调试运行,总结程序设计中出现的问题并找出原因,写出实验报告。
主要功能:
1 - Set memory size (default=1024) 设置内存的大小
2 - Select memory allocation algorithm 设置当前的分配算法
3 - New process 创建新的进程,主要是获取内存的申请数量
4 - Terminate a process 删除进程,归还分配的存储空间,并删除描述该进程内存分配的节点
5 - Display memory usage 显示当前内存的使用情况,包括空闲区的情况和已经分配的情况
0 - Exit
前导知识
FF、BF、WF算法
这三个算法是这次实验的核心。具体的东西课上都讲过,网上也一大堆。简单说一下。FF就是把进程分给第一个匹配的内存块;BF就是把进程分给能容纳进程的最小的内存块,WF和BF相反,就是把进程分给能容纳进程的最大的内存块。
链表
这次实验中内存的数据结构使用的是链表(更准确的说是单链表),因此需要对链表以及链表的操作有一定了解。链表的操作很多,鉴于篇幅问题这里不赘述了,网上很多相关资料,不熟悉的童鞋可以自行搜索。
实现思路
这个实验涉及的模块很多,结果比较复杂,我在编写的过程中经常把自己绕晕,因此我画了一张思维导图,便于理解:
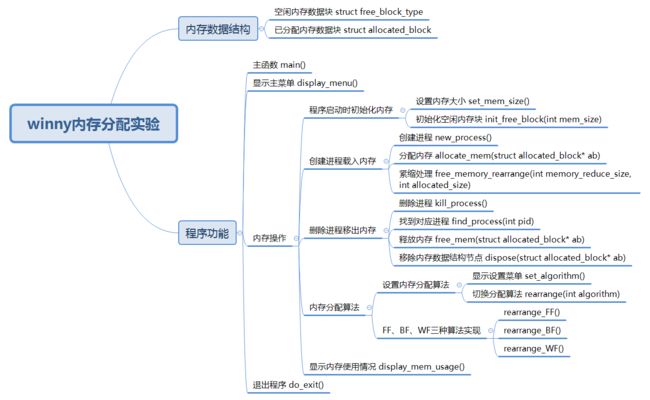
下面我们就按照这个结构来依次实现各个模块。
代码实现
程序在windows平台使用VS 2019编写,经测试windows和linux平台均可正常运行
注意:
- 如果使用VS编写scanf会报错,这是VS的安全检查机制导致的,取消报错的方法网上很多,这里就不赘述了。
- 函数之间可能存在调用关系,因此注意函数之间的顺序或者提前进行函数声明。
友情提示:有的模块代码较长,如果看着不方便可点击代码块全屏浏览哦
主要数据结构
内存空闲分区的描述
//描述每一个空闲块的数据结构
struct free_block_type
{
int size;
int start_addr;
struct free_block_type* next;
};
//指向内存中空闲块链表的首指针
struct free_block_type* free_block_head = NULL;
已分配内存块的描述
struct allocated_block
{
int pid;
int size;
int start_addr;
char process_name[PROCESS_NAME_LEN];
struct allocated_block* next
};
//进程分配内存块链表的首指针
struct allocated_block* allocated_block_head = NULL;
常量定义
#define PROCESS_NAME_LEN 32 //进程名长度
#define MIN_SLICE 10 //最小碎片大小
#define DEFAULT_MEM_SIZE 1024 //默认内存大小
#define DEFAULT_MEM_START 0 //内存起始位置
#define MA_FF 1
#define MA_BF 2
#define MA_WF 3
int mem_size = DEFAULT_MEM_SIZE; //可用内存大小,初始化为默认内存大小
int mem_size_total = DEFAULT_MEM_SIZE; //总共内存大小,初始化为默认大小
int ma_algorithm = MA_FF; //当前内存分配算法,初始化为FF
static int pid = 0; //进程pid号,初始值为0
int flag = 0; //设置内存大小标志,防止重新设置
函数模块
主函数及菜单
主函数
#include 显示菜单
void display_menu()
{
printf("\n");
printf("----------------------------------------\n");
printf(" Memory Management Experiment\n");
printf(" (c) WPX 2176112425\n");
printf(" 2019.11.3\n");
printf("----------------------------------------\n\n");
printf("current algo: %d\tcurrent mem_size: %d\n\n", ma_algorithm, mem_size_total);
printf("Please enter a number to select the appropriate function:\n\n");
printf("1 -- Set memory size(default=%d)\n", DEFAULT_MEM_SIZE);
printf("2 -- Select memory allocation algorithm\n");
printf("3 -- New process\n");
printf("4 -- Terminate a process\n");
printf("5 -- Display memory usage\n");
printf("0 -- Exit\n\n");
printf(">> ");
}
初始化内存
初始化空闲块
struct free_block_type* init_free_block(int mem_size)
{
struct free_block_type* fb;
fb = (struct free_block_type*)malloc(sizeof(struct free_block_type));
if (fb == NULL)
{
printf("No memory!\n");
return NULL;
}
fb->size = mem_size;
fb->start_addr = DEFAULT_MEM_START;
fb->next = NULL;
return fb;
}
设置内存大小
void set_mem_size()
{
int size;
if (flag) //检查是否重复设置
{
printf("Cannot set memory size again!\n");
return;
}
printf("\nTotal memory size = ");
fflush(stdin);
scanf("%d", &size);
if (size >= 0) //检查内存大小是否合法
{
mem_size = size;
mem_size_total = size;
free_block_head->size = mem_size;
flag = 1;
}
else printf("Memory size is not valid!\n");
}
设置内存算法
显示设置菜单
void set_algorithm()
{
int algorithm;
printf("Please enter a number to select the appropriate algorithm:\n\n");
printf("1 -- First Fit\n");
printf("2 -- Best Fit\n");
printf("3 -- Worst Fit\n");
printf(">> ");
scanf("%d", &algorithm);
if (algorithm >= 1 && algorithm <= 3)
{
ma_algorithm = algorithm;
rearrange(ma_algorithm);
}
else
printf("Invalid choice!\n");
}
按指定算法重新排列空闲区链表
void rearrange(int algorithm)
{
switch (algorithm)
{
case MA_FF: rearrange_FF(); break;
case MA_BF: rearrange_BF(); break;
case MA_WF: rearrange_WF(); break;
}
}
创建进程载入内存
创建新进程,获取内存申请数量
void new_process()
{
struct allocated_block* ab;
int size;
//给进程分配内存的结果
int allocate_ret;
//创建一个进程
ab = (struct allocated_block*)malloc(sizeof(struct allocated_block));
if (!ab) exit(1);
//确定进程属性
ab->next = NULL;
pid++;
sprintf(ab->process_name, "PROCESS-%02d", pid);
ab->pid = pid;
printf("\nPlease input the memory for PROCESS-%02d: ", pid);
scanf("%d", &size);
if (size > 0) ab->size = size;
else
{
printf("\nInvalid memory size!\n");
return;
}
//从空闲区分配内存,返回分配结果。1表示分配成功,-1表示分配失败
allocate_ret = allocate_mem(ab);
if ((allocate_ret == 1) && (allocated_block_head == NULL)) //如果是第一个节点
{
allocated_block_head = ab;
}
else if ((allocate_ret == 1) && (allocated_block_head != NULL)) //如果不是第一个节点
{
ab->next = allocated_block_head;
allocated_block_head = ab;
}
else if (allocate_ret == -1) //如果分配失败
{
printf("\nAllocation failed!\n");
free(ab);
return;
}
printf("\nAllocation success!\n");
}
分配内存模块
int allocate_mem(struct allocated_block* ab)
{
struct free_block_type* fbt, * pre, * ne, * p1, * p2;
int request_size = ab->size;
fbt = pre = ne = p1 = p2 = free_block_head;
int allocate_flag = 0; //判断是否已经找到匹配空闲块
//根据当前算法在空闲分区链表中搜索合适空闲分区进行分配,分配时注意以下情况:
// 1. 找到可满足空闲分区且分配后剩余空间足够大,则分割
// 2. 找到可满足空闲分区且但分配后剩余空间比较小,则一起分配
// 3. 找不到可满足需要的空闲分区但空闲分区之和能满足需要,则采用内存紧缩技术,进行空闲分区的合并,然后再分配
// 4. 在成功分配内存后,应保持空闲分区按照相应算法有序
// 5. 分配成功则返回1,否则返回-1
if (mem_size <= 0) return -1;
//遍历查找匹配空闲块
if (ne->next) //如果空闲块不止一个
{
if (ma_algorithm == 1) //如果是FF算法,遍历每一个空闲块
{
while (ne)
{
if (ne != free_block_head) p2 = p1;
p1 = ne;
ne = ne->next;
if (request_size <= p1->size)
{
fbt = p2;
pre = p1;
allocate_flag = 1;
}
}
}
else if (ma_algorithm == 2) //如果是BF算法,则遍历每一个大小满足要求的空闲块
{
while ((ne != NULL) && (request_size <= ne->size))
{
if (allocate_flag) fbt = pre;
pre = ne;
ne = ne->next;
allocate_flag = 1;
}
}
else if (ma_algorithm == 3) //如果是WF算法,则直接查找最后一个空闲块
{
while (ne)
{
if (ne != free_block_head) fbt = pre;
pre = ne;
ne = ne->next;
}
if (pre->size >= request_size) allocate_flag = 1;
}
}
else
{
if (request_size <= pre->size)
allocate_flag = 1;
}
if (allocate_flag) //找到可用空闲区,判断需不需要一起分配剩余内存空间
{
if ((pre->size - request_size) >= MIN_SLICE) //找到可满足空闲分区且分配后剩余空间比较大,则正常分配
{
pre->size = pre->size - request_size;
ab->start_addr = pre->start_addr;
pre->start_addr += ab->size;
}
else //找到可满足空闲分区且分配后剩余空间比较小,则一起分配,删除该节点
{
if (fbt == pre) //如果头块满足条件
{
fbt = pre->next;
free_block_head = fbt;
}
else //中间空闲块满足条件
fbt->next = pre->next;
ab->start_addr = pre->start_addr;
ab->size = pre->size;
free(pre); //释放节点
}
mem_size -= ab->size;
rearrange(ma_algorithm);
return 1;
}
else //找不到空闲区,则进行内存紧缩
{
if (mem_size >= request_size)
{
if (mem_size >= request_size + MIN_SLICE) //分配完内存后还留有空闲内存
free_memory_rearrange(mem_size - request_size, request_size);
else //分配完内存后无空闲内存
free_memory_rearrange(0, mem_size);
return 0;
}
else
return -1;
}
}
紧缩处理
void free_memory_rearrange(int memory_reduce_size, int allocated_size)
{
struct free_block_type* f1, * f2;
struct allocated_block* a1, * a2;
//空闲块处理
if (memory_reduce_size != 0) //分配完剩余空间大于最小内存碎片
{
f1 = free_block_head;
f2 = f1->next;
f1->start_addr = mem_size_total - memory_reduce_size;
f1->size = memory_reduce_size;
f1->next = NULL;
mem_size = memory_reduce_size;
}
else
{
f2 = free_block_head;
free_block_head = NULL;
mem_size = 0;
}
while (f2 != NULL) //逐一释放空闲内存块节点
{
f1 = f2;
f2 = f2->next;
free(f1);
}
//加载块处理
a1 = (struct allocated_block*)malloc(sizeof(struct allocated_block));
a1->pid = pid;
a1->size = allocated_size;
a1->start_addr = mem_size_total - memory_reduce_size - a1->size;
sprintf(a1->process_name, "PROCESS-%02d", pid);
a1->next = allocated_block_head;
a2 = allocated_block_head;
allocated_block_head = a1;
while (a2 != NULL) //逐一将加载块相邻放置
{
a2->start_addr = a1->start_addr - a2->size;
a1 = a2;
a2 = a2->next;
}
}
删除进程移出内存
删除进程
void kill_process()
{
struct allocated_block* ab;
int pid;
printf("\nKill Process, pid = ");
scanf("%d", &pid);
ab = find_process(pid); //找到要删除的块
if (ab != NULL)
{
free_mem(ab); //释放ab所表示的分配区
dispose(ab); //释放ab数据结构节点
}
}
找到进程
struct allocated_block* find_process(int pid)
{
struct allocated_block* p;
p = allocated_block_head;
while (p) //遍历链表找pid对应进程
{
if (p->pid == pid)
return p; //找到则返回struct
p = p->next;
}
printf("\nProcess not found!\n"); //没有找到则报错并返回NULL
return NULL;
}
归还分配区并合并
int free_mem(struct allocated_block* ab)
{
int algorithm = ma_algorithm;
struct free_block_type* fbt, * left, * right; //链表结构认为从左指向右,fbt存储要释放的分区
//left为插入后左边(靠近表头)的空闲分区、right为插入后右边(远离表头)的空闲分区
mem_size += ab->size;
fbt = (struct free_block_type*)malloc(sizeof(struct free_block_type));
if (!fbt) return -1;
//回收内存4种情况:
// 1. 当前空闲分区和右边空闲分区相邻,合并为同一个分区,且释放右边分区
// 2. 当前空闲分区和左边空闲分区相邻,合并为同一个分区,且释放当前分区
// 3. 当前空闲分区和左右空闲分区都相邻,合并为同一个分区,且释放当前和右边分区
// 4. 无相邻空闲分区,则插入一个新表项
fbt->size = ab->size;
fbt->start_addr = ab->start_addr;
fbt->next = NULL;
rearrange(MA_FF);
left = NULL;
//从头开始按照起始地址顺序遍历,判断插入链表的位置
right = free_block_head;
while ((right != NULL) && (fbt->start_addr < right->start_addr))
{
left = right;
right = right->next;
}
if (!left) //插入位置为链表头
{
if (!right) //如果释放内存前已经没有空闲分区
free_block_head = fbt;
else
{
fbt->next = right;
free_block_head = fbt;
if (right->start_addr + right->size == fbt->start_addr) //判断释放的空闲区间和右边空闲分区是否相邻,是则合并
{
fbt->next = right->next;
fbt->start_addr = right->start_addr;
fbt->size = fbt->size + right->size;
free(right);
}
}
}
else
{
if (!right) //如果插入的位置在链表尾
{
left->next = fbt;
if (fbt->start_addr + fbt->size == left->start_addr) //判断释放的空闲区间和左边空闲分区是否相邻,是则合并
{
left->next = right;
left->size = fbt->size + left->size;
left->start_addr = fbt->start_addr;
free(fbt);
}
}
else //如果插入的位置在链表中间
{
fbt->next = right;
left->next = fbt;
if ((fbt->start_addr + fbt->size == left->start_addr) && (right->start_addr + right->size == fbt->start_addr)) //和左右都相邻
{
left->next = right->next;
left->size += fbt->size + right->size;
left->start_addr = right->start_addr;
free(fbt);
free(right);
}
else if (fbt->start_addr + fbt->size == left->start_addr) //和左边相邻
{
left->next = right;
left->size = fbt->size + left->size;
left->start_addr = fbt->start_addr;
free(fbt);
}
else if (right->start_addr + right->size == fbt->start_addr) //和右边相邻
{
fbt->next = right->next;
fbt->start_addr = right->start_addr;
fbt->size = fbt->size + right->size;
free(right);
}
}
}
rearrange(ma_algorithm);
return 1;
}
释放ab数据结构节点
int dispose(struct allocated_block* free_ab)
{
struct allocated_block* pre, * ab;
if (free_ab == allocated_block_head) //如果释放头节点
{
allocated_block_head = allocated_block_head->next;
free(free_ab);
return 1;
}
pre = allocated_block_head;
ab = allocated_block_head->next;
while (ab != free_ab) //遍历链表找到要释放的节点
{
pre = ab;
ab = ab->next;
}
pre->next = ab->next;
free(ab);
return 2;
}
显示内存状态
int display_mem_usage()
{
struct free_block_type* fbt = free_block_head;
struct allocated_block* ab = allocated_block_head;
printf("-------------------------------------------------------------\n");
//显示空闲区
printf("Free Memory:\n");
printf("%20s %20s\n", "start_addr", "size");
while (fbt != NULL)
{
printf("%20d %20d\n", fbt->start_addr, fbt->size);
fbt = fbt->next;
}
//显示已分配区
printf("\nUsed Memory:\n");
printf("%10s %20s %10s %10s\n", "PID", "Process Name", "start_addr", "size");
while (ab != NULL)
{
printf("%10d %20s %10d %10d\n", ab->pid, ab->process_name, ab->start_addr, ab->size);
ab = ab->next;
}
printf("-------------------------------------------------------------\n");
return 0;
}
三种算法
FF算法
void rearrange_FF()
{
struct free_block_type* p, * p1, * p2;
struct free_block_type* last_block;
p1 = (struct free_block_type*)malloc(sizeof(struct free_block_type));
p1->next = free_block_head;
free_block_head = p1;
if (free_block_head != NULL)
{
for (last_block = NULL; last_block != free_block_head; last_block = p) //冒泡排序,按起始地址从大到小排
{
for (p = p1 = free_block_head; p1->next != NULL && p1->next->next != NULL && p1->next->next != last_block; p1 = p1->next)
{
if (p1->next->start_addr < p1->next->next->start_addr)
{
p2 = p1->next->next;
p1->next->next = p2->next;
p2->next = p1->next;
p1->next = p2;
p = p1->next->next;
}
}
}
}
p1 = free_block_head;
free_block_head = free_block_head->next;
free(p1);
}
BF算法
void rearrange_BF()
{
struct free_block_type* p, * p1, * p2;
struct free_block_type* last_block;
p1 = (struct free_block_type*)malloc(sizeof(struct free_block_type));
p1->next = free_block_head;
free_block_head = p1;
if (free_block_head != NULL)
{
for (last_block = NULL; last_block != free_block_head; last_block = p) //冒泡排序,按块大小从大到小排
{
for (p = p1 = free_block_head; p1->next != NULL && p1->next->next != NULL && p1->next->next != last_block; p1 = p1->next)
{
if (p1->next->size < p1->next->next->size)
{
p2 = p1->next->next;
p1->next->next = p2->next;
p2->next = p1->next;
p1->next = p2;
p = p1->next->next;
}
}
}
}
p1 = free_block_head;
free_block_head = free_block_head->next;
free(p1);
p1 = NULL;
}
WF算法
void rearrange_WF()
{
struct free_block_type* p, * p1, * p2;
struct free_block_type* last_block;
p1 = (struct free_block_type*)malloc(sizeof(struct free_block_type));
p1->next = free_block_head;
free_block_head = p1;
if (free_block_head != NULL) {
for (last_block = NULL; last_block != free_block_head; last_block = p) //冒泡排序,按块大小从小到大排
{
for (p = p1 = free_block_head; p1->next != NULL && p1->next->next != NULL && p1->next->next != last_block; p1 = p1->next)
{
if (p1->next->size > p1->next->next->size)
{
p2 = p1->next->next;
p1->next->next = p2->next;
p2->next = p1->next;
p1->next = p2;
p = p1->next->next;
}
}
}
}
p1 = free_block_head;
free_block_head = free_block_head->next;
free(p1);
p1 = NULL;
}
退出程序
void do_exit()
{
struct free_block_type* p1, * p2;
struct allocated_block* a1, * a2;
p1 = free_block_head;
if (p1 != NULL)
{
p2 = p1->next;
for (; p2 != NULL; p1 = p2, p2 = p2->next)
{
free(p1);
}
free(p1);
}
a1 = allocated_block_head;
if (a1 != NULL)
{
a2 = a1->next;
for (; a2 != NULL; a1 = a2, a2 = a2->next)
{
free(a1);
}
free(a1);
}
}
避免采坑
写了好几天,调了无数的bug,很多都由于当时沉迷分析调试改bug忘了记录了,只记几个问题吧。
给了个测试用例发现相邻空闲内存没有合并,如图:
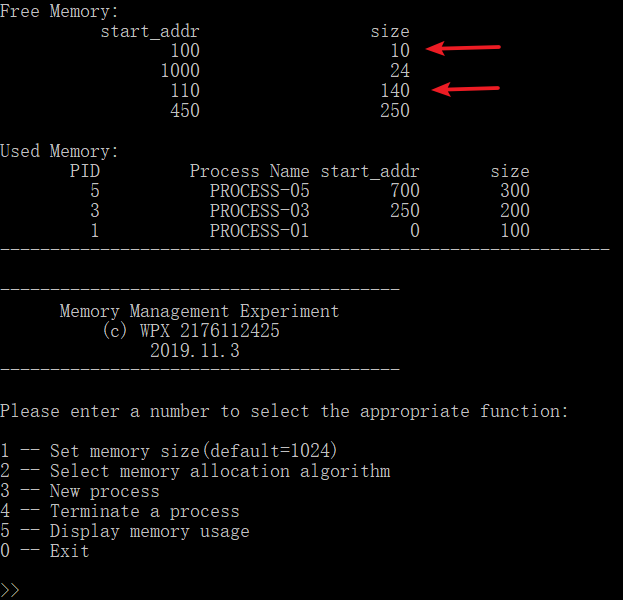
经过调试发现是我排序算法写反了,本来FF排完序之后应该是从头开始起始地址从大到小排列,结果我写成从小到大排列了,而我合并的时候又是把起始地址按照从大到小的顺序插入,这样就导致相邻比较的时候是大的比小的,所以出错,改正之后就好了。
可是改正了之后又发现FF算法实际输出的效果是WF算法,经过分析发现是分配内存的时候出现了问题。我在遍历空闲块的时候直接找的是第一个满足条件的空闲块,而我的链表是从大到小排的,所以出现了问题。修改之后就发现程序一创建进程就崩溃,后来发现我的条件是pre!=NULL,当我所以空闲块都满足条件的时候最终的pre就越界,所以改成pre->next!=NULL就避免了越界。但是这样又发现程序报错。后来发现这样写的话,在一开始只有一个头结点的时候就会出错,因此又加了一个判断是否只有一个节点,这样就解决了问题。
再次调试的时候又发现内存紧缩模块有问题。
本来内存状态如下:
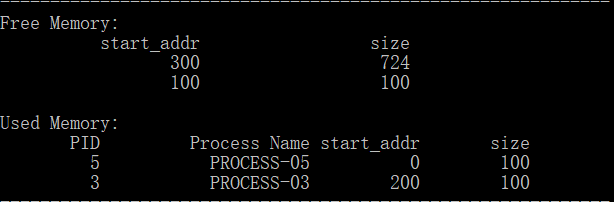
加了一个大小为800的PROCESS-06,结果如下:

调试发现是内存紧缩模块中处理加载块的时候把起始地址填错了
a1->start_addr = mem_size_total - memory_reduce_size改成a1->start_addr = mem_size_total - memory_reduce_size - a1->size就对了
再次调试发现在内存紧缩后,显示内存状态程序就会崩溃,后来发现我在释放节点的时候把f1、f2写反了,这样导致在释放后free_block_head也被释放了,所以显示的时候就会出现问题。修改后就可以了。
后来发现内存紧缩在合并左右两个相邻块时会出问题,调试发现内存大小写错了,left->size = fbt->size + right->size;这样少了左边节点自身的大小,所以出问题。写成left->size += fbt->size + right->size;就没有问题了。
后来又发现内存紧缩的时候出现问题,算法是WF,状态如下:

我给了一个200的进程发现触发了内存紧缩。经过调试发现在分配内存的时候便利空闲块出现了问题,在WF算法下空闲块链表的排序为size从小到大排,而我在遍历的时候由于第一个小于200,所以程序认为没有合适的空闲块。所以为WF算法设置一个专门的分配方式,直接判断最后一个空闲块是否满足要求。再次调试发现FF算法又出问题了,所以干脆给每个算法都写出特定的空闲块查找算法。最终解决问题。
写完了之后我想了一下,好像如果我把内存的结构改成按照内存大小从小到大排会简单很多,在分配算法的时候直接找头结点就行了……