nginx调优第一章
1、进程优化
1.1、nginx进程
![]()
这里我们可以看到再查看的时候,worker进程式www程序用户,但是master进程还是root。其中,master是监控进程,也叫做主进程,worker是工作进程,可以直接理解为master进程是管理worker进程的,而worker进程是为用户提供服务的
1.1.1、设置nginx运行进程个数
nginx进程个数一般我们设置CPU的核心或者核心数×2,如果你不了了解,top命令之后按1也可以看出来。也可以查看/proc/cpuinfo 文件
grep processor /proc/cpuinfo | wc -l #统计cpu个数![]()
可以也使用top 然后按1 下面显示的就是cpu的数量

1.1.2、设置nginx中进程数
在nginx.conf的全局设置中修改
vim /usr/local/nginx/conf/nginx.conf
将worker porcesses 1; 改为自己cpu的数量
1.1.3、重载nginx配置文件
ningx -s reload1.14、然后再次查看nginx进程数
ps -aux | grep nginx | grep -v "grep"1.2、nginx运行cpu亲和力
这个需要根据你的cpu线程数配置,在高并发的情况下,通过设置cpu亲和力来降低由于多cpu切换带来的性能损耗
1.2.1、4核4线程配置
在nginx.conf文件全局配置中增加
![]()
上面的配置表示:4核cpu,开启4个进程。0001表示开启第一个cpu内核0010表示开启第二个cpu内核,依次类推;有多少个核,就有几位数,1表示该内核开启,0表示该内核关闭。
1.2.2、要是四个线程执行跑两个进程
worker_processes 2;
worker_cpu_affinity 0101 1010;表示第一个进程在第一个和第三个cpu上运行,第二个进程在第二个和第四个cpu上运行,两个进程分别在两个组合上轮询!
补充:
2核cpu,开启2个进程
worker_processes2;
worker_cpu_affinity 01 10;
2核CPU,开启4进程
worker_processes 4;
worker_cpu_affinity 01 10 01 10;
2核CPU,开启8进程
worker_processes8;
worker_cpu_affinity 01 10 01 10 01 10 01 10;
8核CPU,开启2进程
worker_processes2;
worker_cpu_affinity 10101010 01010101;
说明:10101010表示开启了第2,4,6,8内核,01010101表示开始了1,3,5,7内核
通过 apache 的ab测试查看nginx对CPU的使用状况:
2、优化nginx最多可以打开的文件数
2.1设置nginx最大可打开的文件数
在nginx.conf文件全局配置中增加
worker_rlimit_nofile 102400当一个nginx进程打开的最多文件数目,理论值可以是最多打开文件数(ulimit -n) 与nginx进程数相除,但是nginx分配请求并不是那么均匀,所以最好与ulimit -n的值保持一致。
2.1.1、永久修改系统可以打开的最大文件数
vim /etc/security/limits.conf
在文件的尾部增加
* soft nofile 102400
* hard nofile 102400
用户重新登录生效
ulimit -n #查看是否更改3、nginx事件处理模型
3.1在nginx.conf配置文件中修改

nginx次啊用epoll事件模型,处理效率高
worker_connections是单个worker进程允许客户端最大连接数,这个数值一般根据服务器性能和内存来制定,实际最大值就是worker进程数乘以work_connections
实际我们填入一个65535,足够了
3.2单个进程允许客户端最大并发连接数
worker_connections 65535;
这个数值一般根据服务器性能和内存来制定,也就是单个进程最大连接数,实际最大并发值就是work进程数乘以这个数。
如何设置,可以根据一个进程启动所占内存,top -u www(www表示nginx程序用户名),但是实际我们填入一个65535,足够了,这些都算并发值
top -u www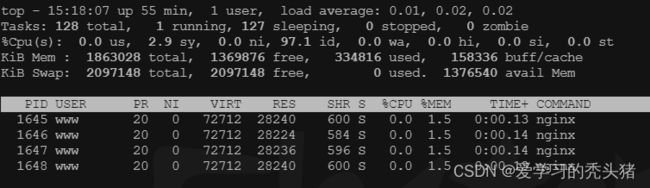
4、http主题优化
4.1、开启高效传输模式
修改nginx配置文件nginx.conf
http {
include mime.types; #媒体类型
default_type application/octet-stream; #默认媒体类型足够
sendfile on;
tcp_nopush on; #取消注释
sendfile on;
开启高效文件传输模式,sendfile指令指定nginx是否调用sendfile函数来输出文件,当nginx是一个静态文件服务器的时候,开启sendfile配置项能大大提高nginx的性能。
tcp_nopush on;
必须在sendfile开启模式才有效,防止网络阻塞,积极的减少网络报文段的数量(将响应头和响应体两部分一起发送,而不一个接一个的发送。)
4.2长连接超时时间
主要是保护服务器资源、CPU、内存、控制连接数,因为创建连接也是需要消耗资源的
![]()
客户端与服务器多长时间没有数据传输65秒后断开连接,长连接可以减少重建连接开销,如果设置时间过长,用户又多,长时间保持连接会占用大量资源。
4.3、文件上传大小限制
在配置文件中增加
client_max_body_size 10m; #在40行增添5、location匹配
Nginx的location通过指定模式来与客户端请求的URI相匹配,location可以把网站的不同部分,定位到不同的处理方式上,基本语法如下:
location [=|~|~*|^~] pattern {
……
}
注:中括号中为修饰符,即指令模式。Pattern为url匹配模式
= 表示做精确匹配,即要求请求的地址和匹配路径完全相同
~:正则匹配,区分大小写
~*:正则匹配”不区分大小写
注:nginx支持正则匹配,波浪号(~)表示匹配路径是正则表达式,加上*变成~*后表示大小写不敏感
^~:指令用于字符前缀匹配。例如:location ^~ /images/ {…}
5.1、精确匹配
= 用于精确字符匹配,不能使用正则,区分大小写。
实例: 精准匹配,浏览器输入ip地址/text.html,定位到服务器/var/www/html/text.html文件
mkdir -p /var/www/html #创建目录
echo "abc" > /var/www/html/text.html #将abc写入text.html中
vim /usr/local/nginx/conf/nginx.conf #进入配置文件
在配置文件中增加下面内容
location = /text.html {
root /var/www/html;
index text.html;
}
nginx -s reload #重载nginx
测试:
5.2、前缀匹配
^~ 指令用于字符前缀匹配,和=精确匹配一样,也是用字符确定匹配,不能使用正则且区分大小写。和=不同的在于,^~指令下,访问url无需url匹配模式一摸一样,只需要其开头前缀和url匹配日模式一样即可。
实例:只要匹配/demo开头的就跳转到百度首页
location ^~ /demo {
rewrite ^ http://baidu.com;
}
对于该模式只要是开头是/demo的都能匹配。与该模式后的是否大小写无关。^~ 不支持正则。模式/demo$中的$并不表示字符模式结束,而是一个实实在在的$
5.3、正则匹配
nginx支持正则匹配。所使用的指令是~和~*,前者表示使用正则,区分大小写,后者表示使用正则,不区分大小写
实例1:匹配任何以gif、jpg、或jpeg结尾的请求
location ~* \.(gif|jpg|swf)$ {
}
实例2:只要是数字0-9emo之间的任意数就匹配
location ~ /[0-9]emo {
rewrite ^ http://google.com;
}
5.4、正常匹配
正常匹配的指令为空,即没有指定匹配指令的即为正常匹配。其形式类似 /XXX/YYY.ZZZ正常匹配中的url匹配模式可以使用正则,不区分大小写
location /demo {
rewrite ^ http://baidu.com;
}
上述模式指的是匹配/demo的url,下面的都能匹配
http://192.168.33.10/demo
http://192.168.33.10/demo/
http://192.168.33.10/demo/aaa
http://192.168.33.10/demo/aaa/bbb
http://192.168.33.10/demo/AAA
http://192.168.33.10/demoaaa
http://192.168.33.10/demo.aaa
正常匹配和前缀匹配的差别在于优先级。前缀的优先级高于正常匹配。
5.5、全匹配
全匹配与正常匹配一样,没有匹配指令,匹配的url模式仅一个斜杠/
location / {
rewrite ^ http://google.com;
}
匹配任何查询,因为所有请求都已 / 开头。但是正则表达式规则和一些较长的字符串将被优先查询匹配。
5.6、命名匹配
命名匹配指的是使用@绑定一个模式,类似变量替换的用法。
error_page 404 = @not_found;
location @not_found {
rewrite ^ http://google.com;
}
上述的作用是如果访问没有匹配的url会触发404指令,然后就匹配到@not_found 这个 location上。
5.7、匹配优先级
nginx的匹配优先级遵循一个大原则和一个小细节。
大原则是关于匹配模式的优先级:
精确匹配 > 前缀匹配 > 正则匹配 > 正常匹配 > 全匹配
小细节则是同级的优先级:
面对一个location,先判断是否是正则匹配,如果是正则匹配,遇到匹配的模式,则命中。如果不是正则,则把匹配的模式放到一边,继续往下阅读配置,阅读完毕所有的匹配模式,查看哪一种的匹配模式更长,则是最终命中的模式。
同级的匹配需要注意两个关键细节,是否是正则匹配,是否是最长匹配。
6、gzip调优
6.1启动gzip
Nginx启用压缩功能需要你来ngx_http_gzip_module模块
优点:1、节约带宽 2、加快传输速度 3、客户有更好的体验
一般我们需要压缩的内容有:文本,js,html,css,对于图片,视频,flash不压缩,同时也要注意,我们使用gzip的功能是需要消耗CPU的!
在配置文件中的http{}区域中增加
gzip on;
gzip_min_length 1k;
gzip_buffers 4 32k;
gzip_http_version 1.1;
gzip_comp_level 6;
gzip_types text/css text/xml application/javascript;
gzip_vary on;
nginx -s reload #重载nginx
参数说明:
| gzip on; | 开启压缩功能 |
| gzip_min_length 1k; | 设置允许压缩的页面最小字节数,页面字节数从header头的Content-Length(内容长度)中获取,默认值是0,不管页面多大都进行压缩,建议设置成大于1K,如果小于1K可能会越压越大。 |
| gzip_buffers 4 32k; | 压缩缓冲区,表示申请四个单位为32k的内存为压缩结果流缓存。 |
| gzip_http_version 1.1; | 压缩版本,用于设置识别HTTP协议版本,默认是1.1, |
| gzip_comp_level 6; | 压缩比例,用来指定GZIP压缩比, |
| gzip_types text/css text/xml application/javascript; | 指定压缩的类型,text.html,类型总是会被压缩 |
| gzip_vary on; |
启用应答头"Vary: Accept-Encoding"。和http头有关系,加个vary头,给代理服务器用的,有的浏览器支持压缩,有的不支持,所以避免浪费不支持的也压缩,所以根据客户端的HTTP头来判断,是否需要压缩。其实cdn,代理服务器,原理上都是代理服务器。他们一般以url为key值进行缓存。而vary属性的设置,告诉了代理根据url缓存的同时,vary的信息也作为key。比如客户端(浏览器)请求的信息里带上了Accept-Encoding:gzip 则返回压缩副本。如果没有带这个头信息,默认返回非压缩副本。 |
测试:
拷贝测试文件
cp /etc/passwd /usr/local/nginx/html/passwd.html
cd /usr/local/nginx/html/
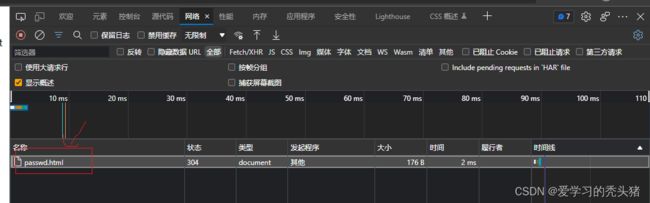
ll -h 浏览器输入自己的ip地址
http://192.168.1.16/passwd.html
按f12然后刷新页面,在开发人员工具里可以看到,passwd.html大小为176B,在网页标头里可以看到,Accept-Encoding: gzip, deflate启用了gzip压缩

7、expires缓存调优
缓存,主要针对于图片,css,js等元素更改机会比较少的情况下使用,特别是图片,占用带宽大,我们完全可以设置图片在浏览器本地缓存365d,css,js,html可以缓存个10来天,这样用户第一次打开加载慢一点,第二次,就非常快了!缓存的时候,我们需要将需要缓存的扩展名列出来!Expires缓存配置在server字段里面。
7.1、以扩展名区分
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$
{
expires 365d;
}
location ~ .*\.(js|css)?$
{
expires 30d;
}
7.2、对目录及其进行判断
location ~ ^/(images|javascript|js|css|flash|media|static)/ {
expires 360d;
}
location ~ (robots.txt) {
expires 7d;
break;
}
注:用于中断当前相同作用域中的Nginx配置,和循环语句中的break语法类似,可以在server块和location以及if块中使用。
expire功能优点
(1)expires可以降低网站购买的带宽,节约成本
(2)同时提升用户访问体验
(3)减轻服务的压力,节约服务器成本,甚至可以节约人力成本,是web服务非常重要的功能。
7.3、expire功能缺点
被缓存的页面或数据更新了,用户看到的可能还是旧的内容,反而影响用户体验。
解决办法:
第一个 缩短缓存时间,例如:1天,不彻底,除非更新频率大于1天
第二个 对缓存的对象改名
a.图片,附件一般不会被用户修改,如果用户修改了,实际上也是更改文件名重新传了而已
b.网站升级对于js,css元素,一般可以改名,把css,js,推送到CDN。
网站不希望被缓存的内容
1)广告图片
2)网站流量统计工具
3)更新频繁的文件(google的logo)