Linux内核Netfilter与iptables的原理
Linux内核Netfilter与iptables的原理
Linux网络 Netfilter之钩子函数注册
《精通Linux内核网络》
linux 内核版本:5.4.215
一、Netfilter 挂载点
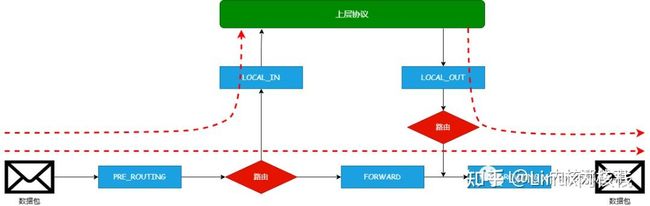
相关钩子点:
NF_INET_PRE_ROUTING
NF_INET_FORWARD
NF_INET_POST_ROUTING
NF_INET_LOCAL_IN
NF_INET_LOCAL_OUT
二、Netfilter 钩子函数链
Netfilter 是通过在网络协议中的不同位置挂载钩子函数来对数据包进行过滤和处理,而且每个挂载点能够挂载多个钩子函数,所以 Netfilter 使用链表结构来存储这些钩子函数,
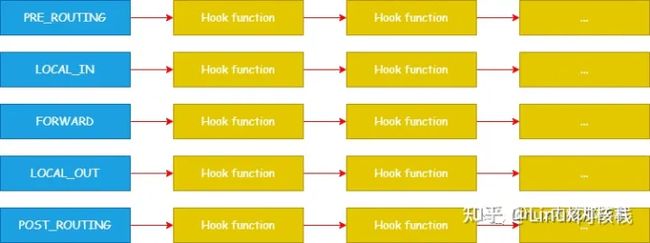
Netfilter 的每个挂载点都使用一个链表来存储钩子函数列表。在内核中,定义了一个名为 nf_hooks 的数组来存储这些链表,如下代码:
// net/netfilter/core.c
#ifdef CONFIG_JUMP_LABEL
struct static_key nf_hooks_needed[NFPROTO_NUMPROTO][NF_MAX_HOOKS];
EXPORT_SYMBOL(nf_hooks_needed);
#endif
//include/net/netns/netfilter.h
struct netns_nf {
#if defined CONFIG_PROC_FS
struct proc_dir_entry *proc_netfilter;
#endif
const struct nf_queue_handler __rcu *queue_handler;
const struct nf_logger __rcu *nf_loggers[NFPROTO_NUMPROTO];
#ifdef CONFIG_SYSCTL
struct ctl_table_header *nf_log_dir_header;
#endif
struct nf_hook_entries __rcu *hooks_ipv4[NF_INET_NUMHOOKS];
struct nf_hook_entries __rcu *hooks_ipv6[NF_INET_NUMHOOKS];
#ifdef CONFIG_NETFILTER_FAMILY_ARP
struct nf_hook_entries __rcu *hooks_arp[NF_ARP_NUMHOOKS];
#endif
#ifdef CONFIG_NETFILTER_FAMILY_BRIDGE
struct nf_hook_entries __rcu *hooks_bridge[NF_INET_NUMHOOKS];
#endif
#if IS_ENABLED(CONFIG_DECNET)
struct nf_hook_entries __rcu *hooks_decnet[NF_DN_NUMHOOKS];
#endif
#if IS_ENABLED(CONFIG_NF_DEFRAG_IPV4)
bool defrag_ipv4;
#endif
#if IS_ENABLED(CONFIG_NF_DEFRAG_IPV6)
bool defrag_ipv6;
#endif
};
三、钩子函数
nf_hook_ops是注册的钩子函数的核心结构,字段含义如下所示,一般待注册的钩子函数会组成一个nf_hook_ops数组,在注册过程中调用nf_register_net_hooks将所有规则加入到指定的钩子点;
struct nf_hook_ops {
/* User fills in from here down. */
nf_hookfn *hook; //钩子函数指针,就是用于处理或者过滤数据包的函数。
struct net_device *dev; //设备
void *priv; //私有数据
u_int8_t pf; //协议族
unsigned int hooknum; //钩子函数所在链(挂载点),如 NF_IP_PRE_ROUTING。
/* Hooks are ordered in ascending priority. */
int priority; //钩子函数的优先级,用于管理钩子函数的调用顺序。
};
钩子函数nf_hookfn的原型为:
typedef unsigned int nf_hookfn(void *priv,
struct sk_buff *skb,
const struct nf_hook_state *state);
四、注册钩子函数
当定义好一个钩子函数结构后,需要调用 nf_register_hook 函数来将其注册到 nf_hooks 数组中,nf_register_hook 函数的实现如下:
static int __nf_register_net_hook(struct net *net, int pf,
const struct nf_hook_ops *reg)
{
struct nf_hook_entries *p, *new_hooks;
struct nf_hook_entries __rcu **pp;
if (pf == NFPROTO_NETDEV) {
#ifndef CONFIG_NETFILTER_INGRESS
if (reg->hooknum == NF_NETDEV_INGRESS)
return -EOPNOTSUPP;
#endif
if (reg->hooknum != NF_NETDEV_INGRESS ||
!reg->dev || dev_net(reg->dev) != net)
return -EINVAL;
}
//获取entry的head
pp = nf_hook_entry_head(net, pf, reg->hooknum, reg->dev);
if (!pp)
return -EINVAL;
//加锁
mutex_lock(&nf_hook_mutex);
//找到钩子应该插入的位置并插入链表
p = nf_entry_dereference(*pp);
new_hooks = nf_hook_entries_grow(p, reg);
if (!IS_ERR(new_hooks)) {
hooks_validate(new_hooks);
rcu_assign_pointer(*pp, new_hooks);
}
//解锁
mutex_unlock(&nf_hook_mutex);
if (IS_ERR(new_hooks))
return PTR_ERR(new_hooks);
#ifdef CONFIG_NETFILTER_INGRESS
if (pf == NFPROTO_NETDEV && reg->hooknum == NF_NETDEV_INGRESS)
net_inc_ingress_queue();
#endif
#ifdef CONFIG_JUMP_LABEL
static_key_slow_inc(&nf_hooks_needed[pf][reg->hooknum]);
#endif
BUG_ON(p == new_hooks);
nf_hook_entries_free(p);
return 0;
}
int nf_register_net_hook(struct net *net, const struct nf_hook_ops *reg)
{
int err;
if (reg->pf == NFPROTO_INET) {
err = __nf_register_net_hook(net, NFPROTO_IPV4, reg);
if (err < 0)
return err;
err = __nf_register_net_hook(net, NFPROTO_IPV6, reg);
if (err < 0) {
__nf_unregister_net_hook(net, NFPROTO_IPV4, reg);
return err;
}
} else {
err = __nf_register_net_hook(net, reg->pf, reg);
if (err < 0)
return err;
}
return 0;
}
EXPORT_SYMBOL(nf_register_net_hook);
在看一下nf_hook_entry_head 函数,结合 钩子函数链定义部分,可以看到钩子点的查找。
static struct nf_hook_entries __rcu **
nf_hook_entry_head(struct net *net, int pf, unsigned int hooknum,
struct net_device *dev)
{
switch (pf) {
case NFPROTO_NETDEV:
break;
#ifdef CONFIG_NETFILTER_FAMILY_ARP
case NFPROTO_ARP:
if (WARN_ON_ONCE(ARRAY_SIZE(net->nf.hooks_arp) <= hooknum))
return NULL;
return net->nf.hooks_arp + hooknum;
#endif
#ifdef CONFIG_NETFILTER_FAMILY_BRIDGE
case NFPROTO_BRIDGE:
if (WARN_ON_ONCE(ARRAY_SIZE(net->nf.hooks_bridge) <= hooknum))
return NULL;
return net->nf.hooks_bridge + hooknum;
#endif
case NFPROTO_IPV4:
if (WARN_ON_ONCE(ARRAY_SIZE(net->nf.hooks_ipv4) <= hooknum))
return NULL;
return net->nf.hooks_ipv4 + hooknum;
case NFPROTO_IPV6:
if (WARN_ON_ONCE(ARRAY_SIZE(net->nf.hooks_ipv6) <= hooknum))
return NULL;
return net->nf.hooks_ipv6 + hooknum;
#if IS_ENABLED(CONFIG_DECNET)
case NFPROTO_DECNET:
if (WARN_ON_ONCE(ARRAY_SIZE(net->nf.hooks_decnet) <= hooknum))
return NULL;
return net->nf.hooks_decnet + hooknum;
#endif
default:
WARN_ON_ONCE(1);
return NULL;
}
#ifdef CONFIG_NETFILTER_INGRESS
if (hooknum == NF_NETDEV_INGRESS) {
if (dev && dev_net(dev) == net)
return &dev->nf_hooks_ingress;
}
#endif
WARN_ON_ONCE(1);
return NULL;
}
五、触发调用钩子函数
要触发调用某个挂载点上(链)的所有钩子函数,需要使用 NF_HOOK 宏来实现,其定义如下:
static inline int
NF_HOOK(uint8_t pf, unsigned int hook, struct net *net, struct sock *sk, struct sk_buff *skb,
struct net_device *in, struct net_device *out,
int (*okfn)(struct net *, struct sock *, struct sk_buff *))
{
int ret = nf_hook(pf, hook, net, sk, skb, in, out, okfn);
if (ret == 1)
ret = okfn(net, sk, skb);
return ret;
}
首先介绍一个NF_HOOK宏的各个参数的作用:
hook:要调用哪一条链(挂载点)上的钩子函数,比如NF_INET_PRE_ROUTING
in: 接受数据包的设备对象
out:发送数据包的设备对象,在有些情况下,输出设备位置,因此为NULL。 例如在执行路由选择查找之前调用的方法 ip_rcv 中,因为不知道要使用的输出设备,所以将输出设备设置为NULL
okfn: 当链上的所有钩子函数都处理完成,将会调用此函数对数据包进行处理。
再详细看一下nf_hook的函数实现:
static inline int nf_hook(u_int8_t pf, unsigned int hook, struct net *net,
struct sock *sk, struct sk_buff *skb,
struct net_device *indev, struct net_device *outdev,
int (*okfn)(struct net *, struct sock *, struct sk_buff *))
{
struct nf_hook_entries *hook_head = NULL;
int ret = 1;
//上锁
rcu_read_lock();
//根据pf找到hook_head
switch (pf) {
case NFPROTO_IPV4:
hook_head = rcu_dereference(net->nf.hooks_ipv4[hook]);
break;
case NFPROTO_IPV6:
hook_head = rcu_dereference(net->nf.hooks_ipv6[hook]);
break;
case NFPROTO_ARP:
#ifdef CONFIG_NETFILTER_FAMILY_ARP
if (WARN_ON_ONCE(hook >= ARRAY_SIZE(net->nf.hooks_arp)))
break;
hook_head = rcu_dereference(net->nf.hooks_arp[hook]);
#endif
break;
case NFPROTO_BRIDGE:
#ifdef CONFIG_NETFILTER_FAMILY_BRIDGE
hook_head = rcu_dereference(net->nf.hooks_bridge[hook]);
#endif
break;
#if IS_ENABLED(CONFIG_DECNET)
case NFPROTO_DECNET:
hook_head = rcu_dereference(net->nf.hooks_decnet[hook]);
break;
#endif
default:
WARN_ON_ONCE(1);
break;
}
//如果钩子函数链表不为空
if (hook_head) {
struct nf_hook_state state;
nf_hook_state_init(&state, hook, pf, indev, outdev,
sk, net, okfn);
//调用nf_hook_slow处理数据包
ret = nf_hook_slow(skb, &state, hook_head, 0);
}
rcu_read_unlock();
return ret;
}
主要就看一下nf_hook_slow函数的实现:
int nf_hook_slow(struct sk_buff *skb, struct nf_hook_state *state,
const struct nf_hook_entries *e, unsigned int s)
{
unsigned int verdict;
int ret;
//遍历entry
for (; s < e->num_hook_entries; s++) {
//调用钩子函数对数据包进行处理
verdict = nf_hook_entry_hookfn(&e->hooks[s], skb, state);
switch (verdict & NF_VERDICT_MASK) {
case NF_ACCEPT:
//如果处理结果为 NF_ACCEPT, 表示数据包通过所有钩子函数的处理, 那么就调用 okfn 函数继续处理数据包
break;
case NF_DROP:
//如果处理结果为 NF_DROP, 表示数据包被拒绝, 应该丢弃此数据包
kfree_skb(skb);
ret = NF_DROP_GETERR(verdict);
if (ret == 0)
ret = -EPERM;
return ret;
case NF_QUEUE:
ret = nf_queue(skb, state, s, verdict);
if (ret == 1)
continue;
return ret;
default:
/* Implicit handling for NF_STOLEN, as well as any other
* non conventional verdicts.
*/
return 0;
}
}
return 1;
}
netfilterf钩子函数的返回值必须是以下值之一:
NF_DROP: 默默地丢弃数据包
NF_ACCEPT: 数据包像通常那样继续在内核协议栈中传输
NF_STOLEN: 数据包不继续传输,由钩子方法进行处理
NF_QUEUE:将数据包排序,供用户空间使用
NF_REPEAT:再次调用钩子函数
六、NF_HOOK 调用点
NF_INET_PRE_ROUTING:在IPV4中,这个挂载点位于方法 ip_rcv() 中。这个是所有入站数据包遇到的第一个挂载点,他处于路由选择子系统查找之前。
NF_INET_FORWARD:在IPV4中,这个挂载点位于方法 ip_forward() 中。对于所有要转发的数据包,经过挂载点 NF_INET_PRE_ROUTING 并执行路由子系统查找后,都将到达这个查找点。
NF_INET_LOCAL_IN:在IPV4中,这个挂载点位于方法 ip_local_deliver() 中,对于所有发送给当前主机入站数据包,经过挂载点 NF_INET_PRE_ROUTING 并执行路由子系统查找后,都将到达这个查找点。
NF_INET_LOCAL_OUT:在IPV4中,这个挂载点位于方法 __ip_local_out() 中,当前主机生成的所有出站数据包都在经过这个挂载点后到达挂载点 NF_INET_POST_ROUTING
NF_INET_POST_ROUTING:在IPV4中,这个挂载点位于方法 ip_output() 中。所有要转发的数据包都在经过挂载点 NF_INET_FORWARD 后到达这个挂载点。另外,当前主机生成的数据包经过挂载点 NF_INET_LOCAL_OUT 后到达这个挂载点。
代码分析:
NF_INET_PRE_ROUTING
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
struct net *net = dev_net(dev);
skb = ip_rcv_core(skb, net);
if (skb == NULL)
return NET_RX_DROP;
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
}
NF_INET_LOCAL_IN
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
struct net *net = dev_net(skb->dev);
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,
net, NULL, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
NF_INET_LOCAL_OUT
int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct iphdr *iph = ip_hdr(skb);
iph->tot_len = htons(skb->len);
ip_send_check(iph);
/* if egress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_out(sk, skb);
if (unlikely(!skb))
return 0;
skb->protocol = htons(ETH_P_IP);
return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT,
net, sk, skb, NULL, skb_dst(skb)->dev,
dst_output);
}
NF_INET_FORWARD
int ip_forward(struct sk_buff *skb)
{
u32 mtu;
struct iphdr *iph; /* Our header */
struct rtable *rt; /* Route we use */
struct ip_options *opt = &(IPCB(skb)->opt);
struct net *net;
/* that should never happen */
if (skb->pkt_type != PACKET_HOST)
goto drop;
if (unlikely(skb->sk))
goto drop;
if (skb_warn_if_lro(skb))
goto drop;
if (!xfrm4_policy_check(NULL, XFRM_POLICY_FWD, skb))
goto drop;
if (IPCB(skb)->opt.router_alert && ip_call_ra_chain(skb))
return NET_RX_SUCCESS;
skb_forward_csum(skb);
net = dev_net(skb->dev);
/*
* According to the RFC, we must first decrease the TTL field. If
* that reaches zero, we must reply an ICMP control message telling
* that the packet's lifetime expired.
*/
if (ip_hdr(skb)->ttl <= 1)
goto too_many_hops;
if (!xfrm4_route_forward(skb))
goto drop;
rt = skb_rtable(skb);
if (opt->is_strictroute && rt->rt_uses_gateway)
goto sr_failed;
IPCB(skb)->flags |= IPSKB_FORWARDED;
mtu = ip_dst_mtu_maybe_forward(&rt->dst, true);
if (ip_exceeds_mtu(skb, mtu)) {
IP_INC_STATS(net, IPSTATS_MIB_FRAGFAILS);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_FRAG_NEEDED,
htonl(mtu));
goto drop;
}
/* We are about to mangle packet. Copy it! */
if (skb_cow(skb, LL_RESERVED_SPACE(rt->dst.dev)+rt->dst.header_len))
goto drop;
iph = ip_hdr(skb);
/* Decrease ttl after skb cow done */
ip_decrease_ttl(iph);
/*
* We now generate an ICMP HOST REDIRECT giving the route
* we calculated.
*/
if (IPCB(skb)->flags & IPSKB_DOREDIRECT && !opt->srr &&
!skb_sec_path(skb))
ip_rt_send_redirect(skb);
if (net->ipv4.sysctl_ip_fwd_update_priority)
skb->priority = rt_tos2priority(iph->tos);
return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD,
net, NULL, skb, skb->dev, rt->dst.dev,
ip_forward_finish);
sr_failed:
/*
* Strict routing permits no gatewaying
*/
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_SR_FAILED, 0);
goto drop;
too_many_hops:
/* Tell the sender its packet died... */
__IP_INC_STATS(net, IPSTATS_MIB_INHDRERRORS);
icmp_send(skb, ICMP_TIME_EXCEEDED, ICMP_EXC_TTL, 0);
drop:
kfree_skb(skb);
return NET_RX_DROP;
}
NF_INET_POST_ROUTING
int ip_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb_dst(skb)->dev;
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUT, skb->len);
skb->dev = dev;
skb->protocol = htons(ETH_P_IP);
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING,
net, sk, skb, NULL, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
}