Spark安装和编程实践(Spark2.4.0)
系列文章目录
Ubuntu常见基本问题
Hadoop3.1.3安装(单机、伪分布)
Hadoop集群搭建
HBase2.2.2安装(单机、伪分布)
Zookeeper集群搭建
HBase集群搭建
Spark安装和编程实践(Spark2.4.0)
Spark集群搭建
文章目录
- 系列文章目录
- 前置条件
- 一、安装 Spark2.4.0
-
- 1、配置spark-env.sh
- 2、启动
- 二、使用 Spark Shell 编写代码
-
- 1、启动Spark Shell
- 2、加载text文件
- 3、简单RDD操作
- 4、退出
- 三、独立应用程序编程
-
- 1、使用sbt对Scala独立应用程序进行编译打包
-
- ① 安装sbt
- ② Scala应用程序代码
- ③ 使用 sbt 打包 Scala 程序
- ④ 通过 spark-submit 运行程序
- 2、使用Maven对Java独立应用程序进行编译打包
-
- ① 安装Maven
- ② Java应用程序代码
- ③ 使用 Maven 打包 Java 程序
- ④ 通过 spark-submit 运行程序
- 3、 使用Maven对Scala独立应用程序进行编译打包
-
- ① 安装Maven
- ② Scala应用程序代码
- ③ 使用 Maven 打包 Scala 程序
- ④ 通过 spark-submit 运行程序
前置条件
- Hadoop伪分布
- JDK
一、安装 Spark2.4.0
- 先把压缩格式的文件spark-2.4.0-bin-without-hadoop.tgz下载到本地电脑,然后保存在“下载”中
- 解压安装包spark-2.4.0-bin-without-hadoop.tgz至路径 /usr/local,命令如下
sudo tar -zxf ~/下载/spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-2.4.0-bin-without-hadoop/ ./spark
sudo chown -R hadoop:hadoop ./spark # 此处的 hadoop 为你的用户名
1、配置spark-env.sh
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vim ./conf/spark-env.sh
在第一行增加
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
2、启动
cd /usr/local/spark
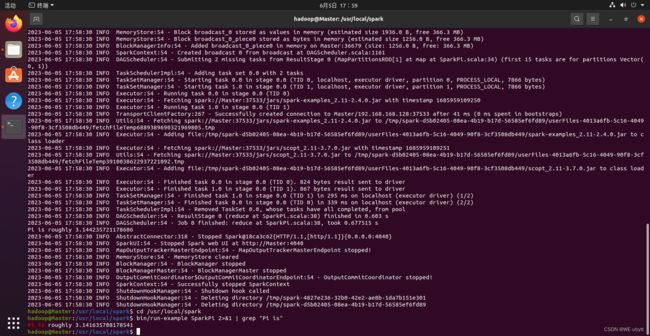
bin/run-example SparkPi
成功啦!!!

执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中):
cd /usr/local/spark
bin/run-example SparkPi 2>&1 | grep "Pi is"
成功啦!!!
二、使用 Spark Shell 编写代码
1、启动Spark Shell
cd /usr/local/spark
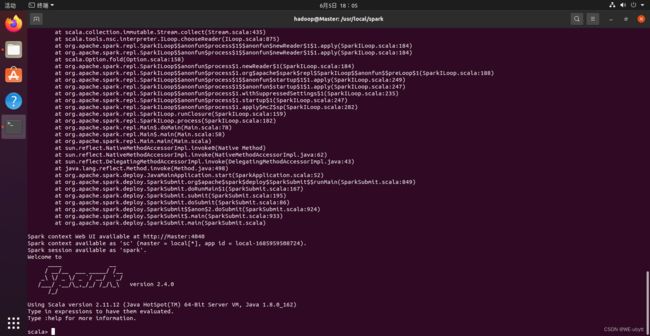
bin/spark-shell
成功啦!!!启动spark-shell后,会自动创建名为sc的SparkContext对象和名为spark的SparkSession对象:
2、加载text文件
spark创建sc,可以加载本地文件和HDFS文件创建RDD。这里用Spark自带的本地文件README.md文件测试。
val textFile = sc.textFile("file:///usr/local/spark/README.md")
加载HDFS文件和本地文件都是使用textFile,区别是添加前缀(hdfs://和file:///)进行标识。
3、简单RDD操作
//获取RDD文件textFile的第一行内容
textFile.first()
//获取RDD文件textFile所有项的计数
textFile.count()
//抽取含有“Spark”的行,返回一个新的RDD
val lineWithSpark = textFile.filter(line => line.contains("Spark"))
//统计新的RDD的行数
lineWithSpark.count()
可以通过组合RDD操作进行组合,可以实现简易MapReduce操作
//找出文本中每行的最多单词数
textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)
4、退出
:quit
三、独立应用程序编程
1、使用sbt对Scala独立应用程序进行编译打包
① 安装sbt
- 先把压缩格式的文件sbt-1.3.8.tgz下载到本地电脑,然后保存在“下载”中
- 解压安装包sbt-1.3.8.tgz至路径 /usr/local,命令如下
sudo mkdir /usr/local/sbt # 创建安装目录
cd ~/下载
sudo tar -zxvf ./sbt-1.3.8.tgz -C /usr/local
cd /usr/local/sbt
sudo chown -R hadoop /usr/local/sbt # 此处的hadoop为系统当前用户名
cp ./bin/sbt-launch.jar ./ #把bin目录下的sbt-launch.jar复制到sbt安装目录下
- 接着在安装目录中使用下面命令创建一个Shell脚本文件,用于启动sbt:
vim /usr/local/sbt/sbt
内容为:
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"
- 保存后,还需要为该Shell脚本文件增加可执行权限:
chmod u+x /usr/local/sbt/sbt
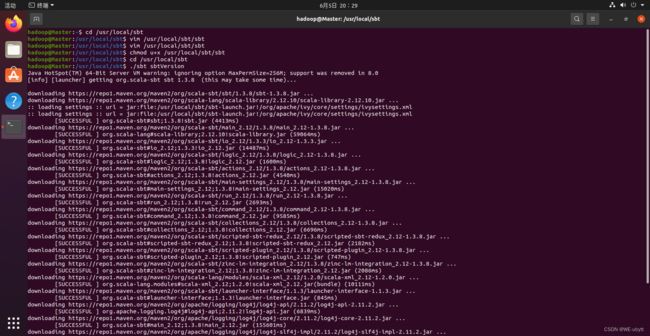
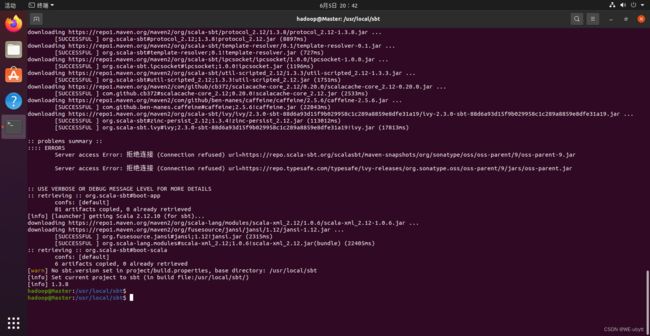
- 使用如下命令查看sbt版本信息
cd /usr/local/sbt
./sbt sbtVersion
成功啦!!!(第一次时间可能有点长)
② Scala应用程序代码
- 先创建结构
cd ~ # 进入用户主文件夹
mkdir ./sparkapp # 创建应用程序根目录
mkdir -p ./sparkapp/src/main/scala # 创建所需的文件夹结构
- 在 ./sparkapp/src/main/scala 下建立一个名为 SimpleApp.scala 的文件(vim ./sparkapp/src/main/scala/SimpleApp.scala),添加代码如下:
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
该程序计算 /usr/local/spark/README 文件中包含 “a” 的行数 和包含 “b” 的行数。
代码第8行的 /usr/local/spark 为 Spark 的安装目录,如果不是该目录请自行修改。
不同于 Spark shell,独立应用程序需要通过 val sc = new SparkContext(conf) 初始化 SparkContext,SparkContext 的参数 SparkConf 包含了应用程序的信息。
- 该程序依赖 Spark API,因此我们需要通过 sbt 进行编译打包。 在~/sparkapp这个目录中新建文件simple.sbt,命令如下:
cd ~/sparkapp
vim simple.sbt
增加如下内容:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.0"
文件 simple.sbt 需要指明 Spark 和 Scala
的版本。在上面的配置信息中,scalaVersion用来指定scala的版本,sparkcore用来指定spark的版本,这两个版本信息都可以在之前的启动
Spark shell 的过程中,从屏幕的显示信息中找到。
③ 使用 sbt 打包 Scala 程序
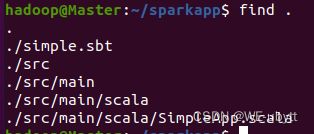
- 为保证 sbt 能正常运行,先执行如下命令检查整个应用程序的文件结构:
cd ~/sparkapp
find .
如下图所示:
- 接着,我们就可以通过如下代码将整个应用程序打包成 JAR(首次运行同样需要下载依赖包 )
/usr/local/sbt/sbt package
成功啦!!!
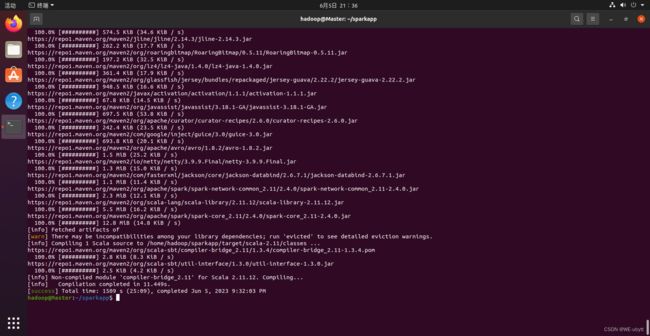
如果打包很慢,可以进行更换为国内源:Ubuntu常见基本问题
④ 通过 spark-submit 运行程序
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
# 上面命令执行后会输出太多信息,可以不使用上面命令,而使用下面命令查看想要的结果
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar 2>&1 | grep "Lines with a:"
成功啦!!!

2、使用Maven对Java独立应用程序进行编译打包
① 安装Maven
- 先把压缩格式的文件apache-maven-3.6.3-bin.zip下载到本地电脑,然后保存在“下载”中
- 解压安装包apache-maven-3.6.3-bin.zip至路径 /usr/local,命令如下
sudo unzip ~/下载/apache-maven-3.6.3-bin.zip -d /usr/local
cd /usr/local
sudo mv apache-maven-3.6.3/ ./maven
sudo chown -R hadoop ./maven
② Java应用程序代码
- 创建结构
cd ~ #进入用户主文件夹
mkdir -p ./sparkapp2/src/main/java
- 在 ./sparkapp2/src/main/java 下建立一个名为 SimpleApp.java 的文件(vim ./sparkapp2/src/main/java/SimpleApp.java),添加代码如下:
/*** SimpleApp.java ***/
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.SparkConf;
public class SimpleApp {
public static void main(String[] args) {
String logFile = "file:///usr/local/spark/README.md"; // Should be some file on your system
SparkConf conf=new SparkConf().setMaster("local").setAppName("SimpleApp");
JavaSparkContext sc=new JavaSparkContext(conf);
JavaRDD<String> logData = sc.textFile(logFile).cache();
long numAs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("a"); }
}).count();
long numBs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("b"); }
}).count();
System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs);
}
}
- 通过Maven进行编译打包。在./sparkapp2目录中新建文件pom.xml,命令如下:
cd ~/sparkapp2
vim pom.xml
- 在pom.xml文件中添加内容如下,声明该独立应用程序的信息以及与Spark的依赖关系:
<project>
<groupId>cn.edu.xmugroupId>
<artifactId>simple-projectartifactId>
<modelVersion>4.0.0modelVersion>
<name>Simple Projectname>
<packaging>jarpackaging>
<version>1.0version>
<repositories>
<repository>
<id>jbossid>
<name>JBoss Repositoryname>
<url>http://repository.jboss.com/maven2/url>
repository>
repositories>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.4.0version>
dependency>
dependencies>
project>
③ 使用 Maven 打包 Java 程序
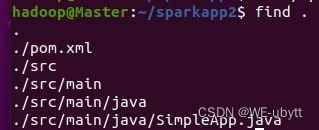
- 为了保证maven能够正常运行,先执行如下命令检查整个应用程序的文件结构:
cd ~/sparkapp2
find .
如下图所示:
- 接着,我们可以通过如下代码将这整个应用程序打包成Jar(注意:电脑需要保持连接网络的状态,而且首次运行同样下载依赖包,同样消耗几分钟的时间):
cd ~/sparkapp2
/usr/local/maven/bin/mvn package
成功啦!!!
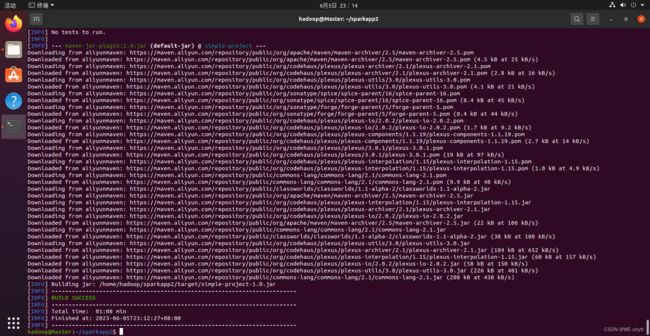
如果打包很慢,可以进行更换为国内源:Ubuntu常见基本问题
④ 通过 spark-submit 运行程序
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp2/target/simple-project-1.0.jar
# 上面命令执行后会输出太多信息,可以不使用上面命令,而使用下面命令查看想要的结果
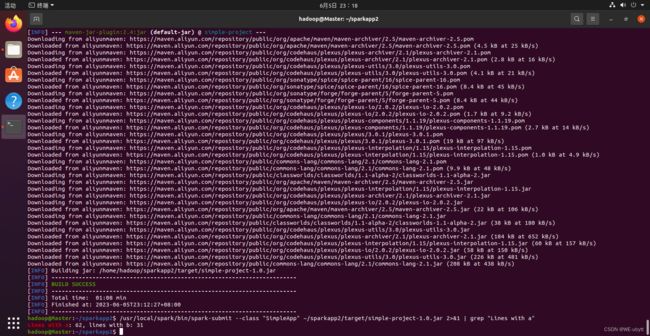
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp2/target/simple-project-1.0.jar 2>&1 | grep "Lines with a"
成功啦!!!
3、 使用Maven对Scala独立应用程序进行编译打包
① 安装Maven
同上
② Scala应用程序代码
- 创建结构
cd ~ # 进入用户主文件夹
mkdir ./sparkapp3 # 创建应用程序根目录
mkdir -p ./sparkapp3/src/main/scala # 创建所需的文件夹结构
- 在 ./sparkapp3/src/main/scala 下建立一个名为 SimpleApp.scala 的文件(vim ./sparkapp3/src/main/scala/SimpleApp.scala),添加代码如下:
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
该程序计算 /usr/local/spark/README 文件中包含 “a” 的行数 和包含 “b” 的行数。
代码第8行的 /usr/local/spark 为 Spark 的安装目录,如果不是该目录请自行修改。
不同于 Spark shell,独立应用程序需要通过 val sc = new SparkContext(conf) 初始化 SparkContext,SparkContext 的参数 SparkConf 包含了应用程序的信息。
③ 使用 Maven 打包 Scala 程序
- 在./sparkapp3目录中新建文件pom.xml,命令如下:
cd ~/sparkapp3
vim pom.xml
修改为:
<project>
<groupId>cn.edu.xmugroupId>
<artifactId>simple-projectartifactId>
<modelVersion>4.0.0modelVersion>
<name>Simple Projectname>
<packaging>jarpackaging>
<version>1.0version>
<repositories>
<repository>
<id>jbossid>
<name>JBoss Repositoryname>
<url>http://repository.jboss.com/maven2/url>
repository>
repositories>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.4.0version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<executions>
<execution>
<goals>
<goal>compilegoal>
goals>
execution>
executions>
<configuration>
<scalaVersion>2.11.12scalaVersion>
<args>
<arg>-target:jvm-1.8arg>
args>
configuration>
plugin>
plugins>
build>
project>
- 为了保证maven能够正常运行,先执行如下命令检查整个应用程序的文件结构:
cd ~/sparkapp3
find .
结果如下:

- 接下来,我们可以通过如下代码将整个应用程序打包成JAR包(注意:计算机需要保持连接网络的状态,而且首次运行打包命令时,Maven会自动下载依赖包,需要消耗几分钟的时间):
cd ~/sparkapp3 #一定把这个目录设置为当前目录
/usr/local/maven/bin/mvn package
④ 通过 spark-submit 运行程序
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp3/target/simple-project-1.0.jar
#上面命令执行后会输出太多信息,可以不使用上面命令,而使用下面命令查看想要的结果
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp3/target/simple-project-1.0.jar 2>&1 | grep "Lines with a:"