Flink on K8s 概述
总结下来就几点:
1、Native模式比Standalone模式好
Standalone模式需要提前确认好每个任务需要使用的资源,并在配置文件里面配置,每一个任务都是固定资源大小,申请多了浪费,少了怕出问题。
Native模式不需要预先确定需要使用的资源数量,系统会实时根据任务需要自动去k8s集群申请能申请到的资源。
2、Application和Session模式各有优劣,不同情况使用不同模式
Application模式资源隔离性强,每个人物都是单独的集群,不会出现并发问题。每个任务都需要启动一个集群,会先启动JobManager,然后启动TaskManager,效率会比较低。适合流处理任务
对比yarn环境下的perjob提交任务速度快很多,大约是十几秒就能提交执行;yarn环境下提交任务需要一分多钟。
Session模式需要提前创建好集群,所有任务共享集群资源,并发下可能会有问题。共用集群,只需要启动TaskManager,效率高。适合批处理任务
operator模式的利弊
还有一种方式叫operator模式,这种方式的优点是有一个开源服务,这个服务来帮你管理yml配置文件,你不需要自己去管理各种资源的配置。但是需要单独启动这个服务,然后调用这个服务的api去管理yml文件的配置功能。
优点:
管理 Flink 集群更加便捷
flink-operator 更便于我们管理 Flink 集群,我们不需要针对不同的 Flink 集群维护 Kubenretes 底层各种资源的部署脚本,唯一需要的,就是 FlinkCluster 的一个自定义资源的描述文件。用户只需要在该文件中声明期望的 Flink 集群配置,flink-operator 会自动完成 Flink 集群的创建和维护工作。如果创建 Per Job 集群,也只需要在该 yaml 中声明 Job 的属性,如 Job 名称,Jar 包路径即可。通过 flink-operator,上文提到的四种 Flink 运行模式,分别对应一个 yaml 文件即可,非常方便。
声明式
通过执行脚本命令式的创建 Flink 集群各个底层资源,需要用户保证资源是否依次创建成功,往往伴随着辅助的检查脚本。借助 flink operator 的控制器模式,用户只需声明所期望的 Flink 集群的状态,剩下的工作全部由 Flink operator 来保证。在 Flink 集群运行的过程中,如果出现资源异常,如 JobMaster 意外停止甚至被删除,Flink operator 都会重建这些资源,自动的修复 Flink 集群。
自定义保存点
用户可以指定 autoSavePointSeconds 和保存路径,Flink operator 会自动为用户定期保存快照。
自动恢复
流式任务往往是长期运行的,甚至 2-3 年不停止都是常见的。在任务执行的过程中,可能会有各种各样的原因导致任务失败。用户可以指定任务重启策略,当指定为 FromSavePointOnFailure,Flink operator 自动从最近的保存点重新执行任务。
Ingress 集成
用户可以定义 Ingress 资源,flink operator 将会自动创建 Ingress 资源。云厂商托管的 Kubernetes 集群一般都有 Ingress 控制器,否则需要用户自行实现 Ingress controller。
Prometheus 集成
通过在 Flink 集群的 yaml 文件里指定 metric exporter 和 metric port,可以与 Kubernetes 集群中的 Prometheus 进行集成。
缺点:
需要单独启动一个服务
它的很多优点基于api的方式也能实现
3、启动方式
Standalone模式:定义好配置文件,然后通过kubectl命令去创建集群,目前没找到api方式创建
Native模式:
通过flink客户端去创建集群
也可以使用api的方式去创建
Flink On Kubernetes 的部署演进
Flink 在 K8s 上最简单的方式是以 Standalone 方式进行部署。这种方式部署的好处在于不需要对 Flink 做任何改动,同时 Flink 对 K8s 集群是无感知的,通过外部手段即可让 Flink 运行起来。
Standalone Session On K8s
Standalone方式在k8s运行步骤:
如图所示:
-
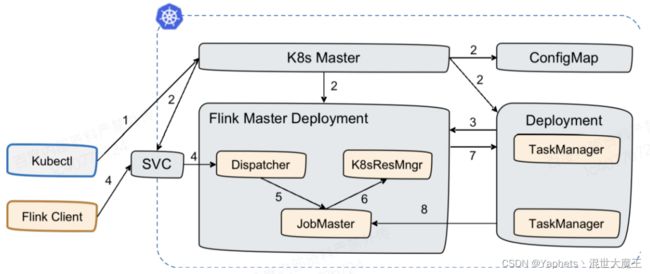
步骤1, 使用 Kubectl 或者 K8s 的 Dashboard 提交请求到 K8s Master。
- 步骤2, K8s Master 将创建 Flink Master Deployment、TaskManager Deployment、ConfigMap、SVC 的请求分发给 Slave 去创建这四个角色,创建完成后,这时 Flink Master、TaskManager 启动了。
- 步骤3, TaskManager 注册到 JobManager。在非 HA 的情况下,是通过内部 Service 注册到 JobManager。
- 至此,Flink 的 Sesion Cluster 已经创建起来。此时就可以提交任务了。
- 步骤4,在 Flink Cluster 上提交 Flink run 的命令,通过指定 Flink Master 的地址,将相应任务提交上来,用户的 Jar 和 JobGrapth 会在 Flink Client 生成,通过 SVC 传给 Dispatcher。
- 步骤5,Dispatcher 会发现有一个新的 Job 提交上来,这时会起一个新的 JobMaster,去运行这个 Job。
- 步骤6,JobMaster 会向 ResourceManager 申请资源,因为 Standalone 方式并不具备主动申请资源的能力,所以这个时候会直接返回,而且我们已经提前把 TaskManager 起好,并且已经注册回来了。
- 步骤7-8,这时 JobMaster 会把 Task 部署到相应的 TaskManager 上,整个任务运行的过程就完成了。
//创建session集群 kubectl create -f flink-configuration-configmap.yaml kubectl create -f jobmanager-service.yaml kubectl create -f jobmanager-rest-service.yaml kubectl create -f jobmanager-deployment.yaml kubectl create -f taskmanager-deployment.yaml //提交任务到集群 ./bin/flink run -m localhost:8081 ./examples/streaming/WordCount.jar |
Standalone perjob on K8s
现在我们看一下 Perjob 的部署,因为 Session Cluster 和 Perjob 分别都有不同的适用场景,一个 Session 里面可以跑多个任务,但是每个任务之间没有办法达到更好的隔离性。而 Perjob 的方式,每个job都会有一个自己独立的 Flink Cluster 去运行,它们之间相互独立。
■ Perjob 的特点:
- 用户的 Jar 和依赖都是在镜像里提前编译好,或者通过 Init Container 方式,在真正 Container 启动之前进行初始化。
- 每个 Job 都会启动一个新的 Cluster。
- 一步提交,不需要像 Session Cluster 一样先启动集群再提交任务。
- 用户的 main 方法是在 Cluster 里运行。在特殊网络环境情况下,main 方法需要在 Cluster 里运行的话,Session 方式是无法做到的,而 Perjob 方式是可以执行的。
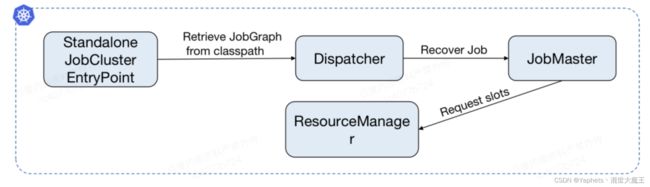
■ 执行步骤:
由 Standalone JobCluster EntryPoint 执行,从 classpath 找到用户 Jar,执行它的 main 方法得到 JobGrapth 。再提交到 Dispathcher,这时候走 Recover Job 的逻辑,提交到 JobMaster。JobMaster 向 ResourceManager 申请资源,请求 slot,执行 Job。
kubectl create -f flink-configuration-configmap.yaml kubectl create -f jobmanager-service.yaml kubectl create -f jobmanager-rest-service.yaml kubectl create -f jobmanager-job.yaml kubectl create -f taskmanager-job-deployment.yaml |
Navtive Integration 的技术细节
为什么叫 Native 方式?包括如下几个含义。
- 资源申请方式:Flink 的 Client 内置了一个 K8s Client,可以借助 K8s Client 去创建 JobManager,当 Job 提交之后,如果对资源有需求,JobManager 会向 Flink 自己的 ResourceManager 去申请资源。这个时候 Flink 的 ResourceManager 会直接跟 K8s 的 API Server 通信,将这些请求资源直接下发给 K8s Cluster,告诉它需要多少个 TaskManger,每个 TaskManager 多大。当任务运行完之后,它也会告诉 K8s Cluster释放没有使用的资源。相当于 Flink 用很原生的方式了解到 K8s Cluster 的存在,并知晓何时申请资源,何时释放资源。
- Native 是相对于 Flink 而言的,借助 Flink 的命令就可以达到自治的一个状态,不需要引入外部工具就可以通过 Flink 完成任务在 K8s 上的运行。
具体如何工作?主要分 Session 和 Perjob 两个方面来给大家介绍。
Native Kubernetes Session 方式
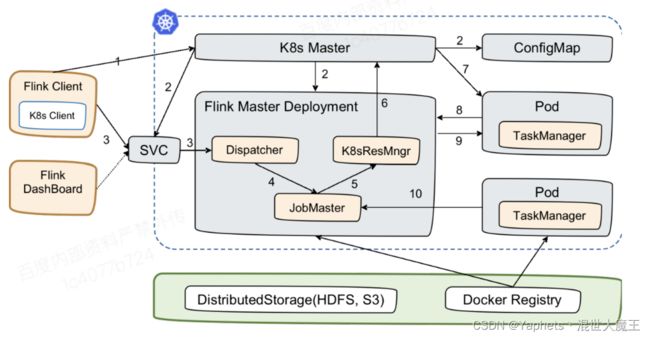
首先 Session 的方式。
- 第一个阶段:启动 Session Cluster。Flink Client 内置了 K8s Client,告诉 K8s Master 创建 Flink Master Deployment,ConfigMap,SVC。创建完成后,Master 就拉起来了。这时,Session 就部署完成了,并没有维护任何 TaskManager。
- 第二个阶段:当用户提交 Job 时,可以通过 Flink Client 或者 Dashboard 的方式,然后通过 Service 到 Dispatcher,Dispatcher 会产生一个 JobMaster。JobMaster 会向 K8sResourceManager 申请资源。ResourceManager 会发现现在没有任何可用的资源,它就会继续向 K8s 的 Master 去请求资源,请求资源之后将其发送回去,起新的 Taskmanager。Taskmanager 起来之后,再注册回来,此时的 ResourceManager 再向它去申请 slot 提供给 JobMaster,最后由 JobMaster 将相应的 Task 部署到 TaskManager 上。这样整个从 Session 的拉起到用户提交都完成了。
- 需注意的是,图中 SVC 是一个 External Service。必须要保证 Client 通过 Service 可以访问到 Master。在很多 K8s 集群里,K8s 和 Flink Client 是不在同一个网络环境的,这时候可以通过 LoadBalancer 的方式或者 NodePort 的方式,使 Flink Client 可以访问到 Jobmanager Dispatcher,否则 Jar 包是无法提交的。
Session方式代码
// 启动session集群,可以指定clusterId,image地址,还有一些CPU,内存的设定
./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=k8s-session-1 \
-Dkubernetes.container.image=flink-on-kubernetes-job:1.0.2 \
-Dkubernetes.container.image.pull-policy=Always \
-Djobmanager.heap.size=4096m \
-Dtaskmanager.memory.process.size=4096m \
-Dtaskmanager.numberOfTaskSlots=4 \
-Dkubernetes.jobmanager.cpu=1 -Dkubernetes.taskmanager.cpu=2
// 提交任务到session集群,需要指定clusterId,而且session集群的service必须暴露为8081端口,应该是flink客户端默认值就是提交到8081端口
./bin/flink run \
--target kubernetes-session \
-Dkubernetes.cluster-id=flink-session-first-cluster-v1 \
./examples/streaming/WordCount.jar |
Native Kubernetes Perjob 方式
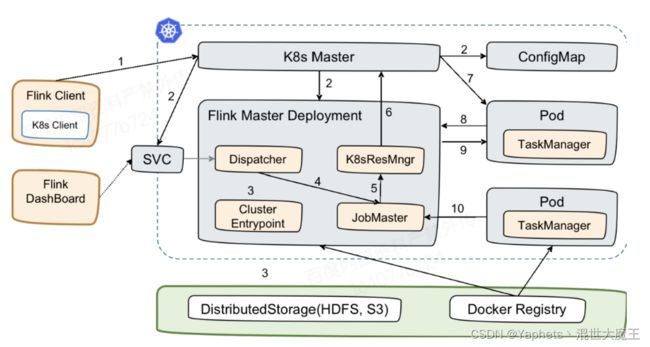
我们再来看一下 Perjob 的方式,如图所示,Perjob 方式其实和之前是有一些类似,差别在于不需要先去起一个 Session Cluster,再提交任务,而是一步的。
- 首先创建出了 Service、Master 和 ConfigMap 这几个资源以后,Flink Master Deployment 里面已经带了一个用户 Jar,这个时候 entrypoint 就会从用户 Jar 里面去提取出或者运行用户的 main,然后产生 JobGraph。之后再提交到 Dispatcher,由 Dispatcher 去产生 Master,然后再向 ResourceManager 申请资源,后面的逻辑的就和 Session 的方式是一样的。
- 它和 Session 最大的差异就在于它是一步提交的。因为没有了两步提交的需求,如果不需要在任务起来以后访问外部 UI,就可以不用外部的 Service。可直接通过一步提交使任务运行。通过本地的 port-forward 或者是用 K8s ApiServer 的一些 proxy 可以访问 Flink 的 Web UI。此时,External Service 就不需要了,意味着不需要再占用一个 LoadBalancer 或者占用 NodePort。这就是 perjob 方式。
Application模式提交任务
// 不需要提前启动集群,直接提交任务创建集群执行任务 ./bin/flink run-application -p 10 -t kubernetes-application \ -Dkubernetes.cluster-id=k8s-app1 \ -Dkubernetes.container.image=flink-on-kubernetes-job:1.0.2 \ -Dkubernetes.container.image.pull-policy=Always \ -Djobmanager.heap.size=4096m -Dtaskmanager.memory.process.size=4096m \ -Dkubernetes.jobmanager.cpu=1 -Dkubernetes.taskmanager.cpu=2 \ -Dtaskmanager.numberOfTaskSlots=4 \ local:///opt/flink/examples/streaming/WindowJoin.jar |
Session 与 Perjob 方式的不同
我们来看一下 Session 和 Perjob 方式有哪些不同?

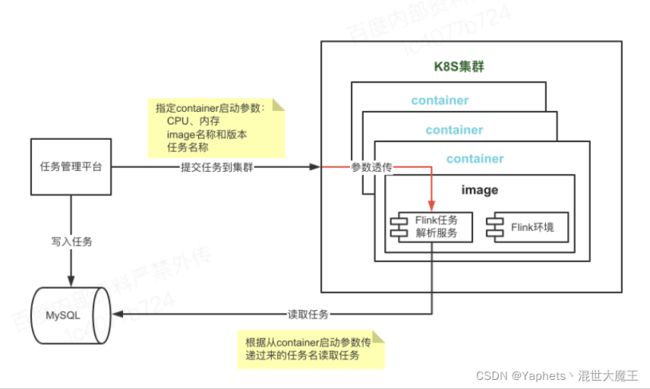
flink基于K8s云原生的方式部署方案详情
背景:目前大多数服务都基于k8s去一键部署,可以解决环境带来的问题并大大提高部署效率,更优的方案是基于云原生的方式去部署,解决动态扩缩容问题,提高资源利用率。所以大数据服务也需要能基于k8s云原生的方式去部署。
调研:目前比较常见的解决方案都是基于k8s上面部署yarn,然后在yarn里面启动flink集群。这个方案解决了k8s部署问题,但是没办法解决资源利用率问题,任务启动的时候必须指定资源数量,资源少了不够用,资源多了浪费,没法实现动态扩缩容。
实现方案:直接基于k8s的云原生方案去实现,去除yarn层,而且可以基于API的方式启动任务,还可以动态配置容器资源,目前可以设置CPU和内存参数。但是还有一个比较棘手的问题需要解决:APP方式提交任务,需要提前把任务代码的jar包打到镜像里面,启动任务的时候指定jar包路径和名称,而且需要一个任务一个jar包,N个任务N个jar包。这种方式比较麻烦,而且没法动态实现任务的启动。
方案一:网上找了一下方案,都是说任务启动的时候动态去下载需要的jar包,这样也需要提前把一个任务打成jar包,放到可以下载的服务上,还是不够灵活。
方案二:翻看源码,发现flink1.11到1.12版本支持一个特殊参数:kubernetes.container-start-command-template,defaultValue:"%java% %classpath% %jvmmem% %jvmopts% %logging% %class% %args% %redirects%",参数说明:"Template for the kubernetes jobmanager and taskmanager container start invocation.",通过参数说明可以发现,这个参数可以配置k8s启动容器时执行jar服务的命令。其中包括classpath设置、jvm相关的参数设置、日志配置,启动类class设置、main函数的args参数设置等等。基于这个发现,大胆做了一个设想方案,开发一个jar服务,获取java服务启动jvmopts里面或者args里面的参数,两种方式都可以,然后根据参数去数据库读取任务信息,根据获取到的信息执行任务。
最终采取了方案二实现,方案一不符合整体FlinkSP架构的易用性这一点,方案二更符合我们整体架构的思路,通过任务管理平台去创建任务,任务数据保存到MySQL数据库,然后Flink任务解析服务通过任务名称去获取任务详情,并提交任务到Flink环境执行任务。
方案实现图: