机器学习聚类——DBSCAN(Density-based spatial clustering of applications with noise,基于密度的聚类算法)
系列文章目录
机器学习集成学习——Adaboost分离器算法
机器学习聚类算法——BIRCH算法、DBSCAN算法、OPTICS算法
机器学习的一些常见算法介绍【线性回归,岭回归,套索回归,弹性网络】
机器学习集成学习——GBDT(Gradient Boosting Decision Tree 梯度提升决策树)算法
机器学习之SVM分类器介绍——核函数、SVM分类器的使用
机器学习——随机森林算法、极端随机树和单颗决策树分类器对手写数字数据进行对比分析_极端随机森林算法
机器学习——聚类算法的评分函数
文章目录
系列文章目录
DBSCAN算法简介
1. 导入必要的库
2. 生成样本数据
3. 对数据进行标准化
4. 创建 DBSCAN 对象并进行聚类
5. 绘制聚类结果
6.补充——使用DBSCAN算法实现聚类
总结
前言
本文主要介绍聚类——DBSCAN(Density-based spatial clustering of applications with noise,基于密度的聚类算法),以下案例仅供参考
DBSCAN算法简介
DBSCAN(Density-based spatial clustering of applications with noise,基于密度的聚类算法)是一种常用的聚类算法,它可以发现任意形状的聚类,并且可以区分噪声点。
DBSCAN 是一种基于密度的聚类算法,它的主要思想是将高密度的数据点聚成一类,低密度的数据点视为噪声或离群点。在 DBSCAN 中,密度被定义为在某个半径范围内的数据点个数。具体来说,该算法需要指定两个参数:半径 ε 和最小邻居数 minPts。对于某个数据点,如果它的 ε-邻域(即距离该点不超过 ε 的所有点)中包含不少于 minPts 个数据点,则该点被视为一个核心点;如果某个数据点在某个核心点的 ε-邻域中,但它自身不是核心点,则该点被视为边界点;如果某个数据点的 ε-邻域中没有包含不少于 minPts 个数据点,则该点被视为噪声或离群点。通过以上定义,DBSCAN 可以将数据点分成三类:核心点、边界点和噪声点。该算法的优点是可以处理任意形状的簇,并且可以有效地过滤噪声和离群点。
下面是使用 Python 实现 DBSCAN 聚类的步骤:
1. 导入必要的库
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
%matplotlib inline2. 生成样本数据
X, y = make_blobs(n_samples=500, centers=5, random_state=42)3. 对数据进行标准化
X = StandardScaler().fit_transform(X)4. 创建 DBSCAN 对象并进行聚类
dbscan = DBSCAN(eps=0.5, min_samples=5)
dbscan.fit(X)其中,`eps` 是邻域半径的大小,`min_samples` 是邻域内最少的样本数。
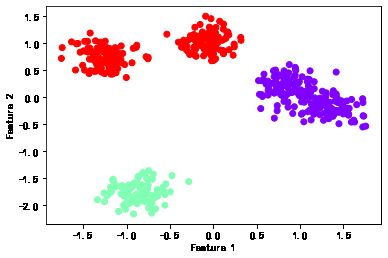
5. 绘制聚类结果
plt.scatter(X[:,0], X[:,1], c=dbscan.labels_, cmap='rainbow')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()其中,`dbscan.labels_` 是聚类结果的标签,用于区分不同的聚类簇。完整代码如下:
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
%matplotlib inline
# 生成样本数据
X, y = make_blobs(n_samples=500, centers=5, random_state=42)
# 对数据进行标准化
X = StandardScaler().fit_transform(X)
# 创建 DBSCAN 对象并进行聚类
dbscan = DBSCAN(eps=0.5, min_samples=5)
dbscan.fit(X)
# 绘制聚类结果
plt.scatter(X[:,0], X[:,1], c=dbscan.labels_, cmap='rainbow')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()运行结果:
6.补充——使用DBSCAN算法实现聚类
#使用DBSCAN算法实现聚类
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
from sklearn.datasets import make_moons
from sklearn.datasets import make_circles
from sklearn import cluster
noises = [0.05,0.1,0.15]
for noise in noises:
X,labels = make_moons(n_samples = 500,noise = noise)
plt.figure(figsize=(15,5))
plt.subplot(121)
plt.scatter(X[:,0],X[:,1],color = "black",s=20)
plt.title("原始数据发布(噪声方差%.2f)"%noise)
db = cluster.DBSCAN(eps = 0.15,min_samples = 10)
db.fit(X)
print('DBSCAN算法参数:',db.get_params())
result = np.unique(db.labels_)
print('DBSCAN类别标签:',result)
plt.subplot(122)
colors = ["b","g","c","m","y","k","r"]
markers = ["<",">","s","+","*","^","o"]
labels = ['簇1','簇2','簇3','簇4','簇5','簇6','噪声']
for i,j in enumerate(db.labels_):
plt.scatter(X[i][0],X[i][1],color = colors[j],marker = markers[j],s = 20)
plt.title("DBSCAN聚类结果")
plt.show()运行结果:
DBSCAN算法参数: {'algorithm': 'auto', 'eps': 0.15, 'leaf_size': 30, 'metric': 'euclidean', 'metric_params': None, 'min_samples': 10, 'n_jobs': None, 'p': None} DBSCAN类别标签: [0 1]
DBSCAN算法参数: {'algorithm': 'auto', 'eps': 0.15, 'leaf_size': 30, 'metric': 'euclidean', 'metric_params': None, 'min_samples': 10, 'n_jobs': None, 'p': None} DBSCAN类别标签: [-1 0 1 2]
DBSCAN算法参数: {'algorithm': 'auto', 'eps': 0.15, 'leaf_size': 30, 'metric': 'euclidean', 'metric_params': None, 'min_samples': 10, 'n_jobs': None, 'p': None} DBSCAN类别标签: [-1 0 1 2 3 4]



总结
以上就是今天的内容~
最后欢迎大家点赞,收藏⭐,转发,
如有问题、建议,请您在评论区留言哦。