【论文翻译】:(arxiv 2022)PS-NeRV: Patch-wise Stylized Neural Representations for Videos
PS-NeRV: Patch-wise Stylized Neural Representations for Videos (arxiv 2022)
2022/11/30:除了基金不想写,其他什么都想写
Paper:https://arxiv.org/abs/2208.03742
No Code
Abstract
我们研究如何用隐式神经表示(INRs)来表示视频。经典的INRs方法通常利用mlp将输入坐标映射到输出像素。而最近的一些研究则尝试用cnn直接重建整个图像。然而,我们认为上述两种基于像素的策略和基于图像的策略都不利于视频数据。相反,我们提出了一个补丁式的解决方案,
PS-NeRV,表示视频作为补丁和对应补丁坐标的函数。它自然继承了基于图像的方法的优点,在解码速度快的情况下获得了良好的重构性能。整个方法包括传统的位置嵌入、mlp和cnn等模块,同时引入AdaIN增强中间特征。这些简单而必要的改变可以帮助网络轻松地适应高频细节。大量的实验证明了该算法在视频压缩和视频嵌入等视频相关任务中的有效性。
1. Introduction
随着流媒体的快速发展,大量的视频数据已经广泛地填充在我们的日常生活中。然而,大文件,特别是高分辨率(1080p-4k)视频,正在成为存储和传输的沉重负担。传统的视频表示将视频显式地表示为帧序列,其效率不足以满足这一挑战。最近,隐式神经表示1,2,3,4作为一种新颖有效的表示方法受到越来越多的关注,它能够为各种数据类型(如图像[5]、3D形状[6]和场景[2])产生高保真的结果。特别地,利用神经网络隐式表示视频也显示了其巨大的潜力。
对于隐式视频表示,基于像素的方法(如SIREN[5])根据时空坐标(x,y,t)输出每个像素的RGB值。相比之下,NeRV[7]被提出作为一种图像方面的表示方法,它将视频表示为时间的函数。它将每个时间戳t映射到整个帧,并显示出比像素化表示方法更高的效率。然而,无论是像素型还是图像型表示都不是最适合视频数据的策略。它们会以不同的方式增加网络负担,导致重构结果不理想。具体来说,基于像素的方法需要对每一帧进行大量的采样,这对于编码和解码都是低效的。这种基于图像的方法可能难以表示复杂的信号,比如高分辨率视频。它需要一个更大的网络来过度拟合整个框架的内容和细节,带来额外的计算成本。因此,我们需要一种更合适、更有效的方法来隐式表示视频数据。
受局部相邻像素相似性(在现实信号[8]中广泛存在)的启发,我们提出了一种视频的补丁级别隐式表示方法。由于相邻斑块的特征具有很大的相似性,它们可以很容易地用单个网络表示。 在我们的实现中,视频的每一帧都被划分为分割的补丁,这样每个补丁都有相应的空间坐标。我们以补丁坐标和时间戳作为网络的输入,网络通过卷积网络输出对应的图像补丁。该方法不仅具有图像化方法较快的编解码速度,而且能重构出生动的高频细节。注意,基于patch的表示并不是基于像素的方法和基于图像的方法之间的权衡,而是一种更适合视频数据的解决方案。
另一个值得注意的是,卷积神经网络中广泛使用的归一化层会降低网络的拟合能力,这在NeRV中也有体现。作为一种替代方法,我们是否可以通过将特征的均值和方差与目标帧对齐来提高拟合能力?基于以上考虑,我们进一步引入自适应实例规范化层(AdaIN)[9]来调制特征。通过MLP网络可以直接从输入坐标中获取帧特征的均值和方差。 这个简单的策略类似于StyleGAN,可以显著提高网络的拟合能力,特别是对细节的拟合能力。最后,我们将整个方法命名为补丁级风格的视频神经表示(PS-NeRV)。我们还探讨了该方法的一些应用,如视频压缩和视频嵌入任务。与NeRV相比,我们的方法具有更好的压缩潜力。当输入视频被屏蔽时,我们的方法可以生成高质量的嵌入输出,甚至优于最先进的视频嵌入方法。综上所述,本工作的主要贡献如下:
- 设计了一种新的视频隐式表示方法,将视频表示为图像斑块,并验证了该方法在细节表示方面的有效性。
- 我们发现在基于卷积神经网络的INR中引入AdaIN层可以显著提高模型的拟合效果。
- 我们的方法在一些视频相关的应用中显示了良好的性能,包括视频压缩和视频嵌入。
2. Related Work
2.1 Implicit Neural Representation
隐式神经表示(INR)方法最近得到了越来越多的关注,并被用于一些任务,如图像[5],3D形状[6]和新视图合成[2]。在后来的一些工作中发现,使用周期激活函数[5]和所谓的傅里叶特征[4]编码像素(或体素)坐标可以有效地重构信号的精细细节。然而,INR方法基本上是基于坐标的方法。这意味着对于像素较多的数据,如视频数据,需要使用神经网络建立从坐标到RGB值的映射。大量的样本也会导致训练和测试的效率低下,使得INR方法无法在一些实际场景中应用。NeRV[7]探索了一种图像方面的表示,它构建了从时间戳t到整个帧的映射,并展示了与像素方面的表示相比其出色的效率。但NeRV[7]增加了网络的负担,要表示一整帧的复杂信号,其神经网络的体系结构设计也比较粗糙。相比之下,我们使用神经网络来表示补丁中更简单的信号,既保证了效率,又进一步提高了精度。
2.2 Video Compression
视频压缩是一项长期研究的基础任务。在过去的几十年里,许多传统的视频压缩算法被提出并取得了巨大的成功,如H.264[11]、MPEG[12]和HEVC[13]。最近,一些基于深度学习的方法尝试利用神经网络来改进视频压缩。DVC[14]利用神经网络替换了H.264中的所有关键组件,并实现了与传统视频压缩算法相当或略好于传统视频压缩算法的压缩率。后来,胡等人[15]通过在特征空间中执行所有主要操作(即运动估计、运动压缩、运动补偿和残差压缩),提出了一种特征空间视频编码网络。SRVC[16]在传统的压缩方法上增加了另一种模型流,将解压缩后的低分辨率视频帧通过(时变)超分辨率模型对视频进行解码,重构出高分辨率视频帧。Li等人[17]提出利用特征域中的上下文来帮助编码和解码。然而,传统压缩的整体管道仍然限制了这些方法的能力。相反,NeRV[7]采用INR方法将视频压缩任务转化为模型压缩问题,具有很大的潜力。在大多数情况下,一个视频编码一次,但将需要解码多次。因此,像NeRV[7]这样的INR方法由于解码效率高而显示出很大的优势。另一方面,与其他视频压缩方法在重建各自的关键帧后需要顺序解码相比,INR方法使得并行解码非常容易。
2.3 Local Implicit Functions
最近,一些基于坐标的方法也使用局部特征来表示精度更高的复杂信号,如图像[18],形状[19]和亮度场[20,1]。这些方法首先将目标域分解为一个显式网格,并在每个网格上估计一个局部连续表示。然后,解码器将根据这种表示输出每个坐标的值。由于每个网格单元都需要存储本地网络所约束的潜在代码或特征向量,这些方法的内存效率会较低。相反,我们将网格坐标直接映射到整个网格输出值,这是有效的,效率更高。与我们的方法类似,COCO-GAN[21]以图像的空间坐标为条件,按部件生成图像。然而,他们的方法很难保证每个生成部分之间的正确空间连接,降低了灵活性。我们的方法是用补丁级方法来拟合复杂的信号。
3. Proposed Method
3.1 Motivation
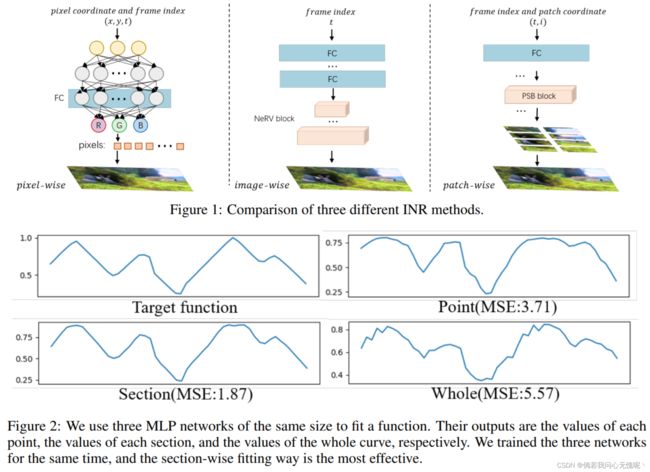
在各种现实信号中存在着局部相似性,这使得局部特征的结构易于表示,如局部线性嵌入(LLE)[8]。因此,我们认为用局部模式表示信号是最有效的方法。为了便于理解,我们进行了如图2所示的玩具实验。具体来说,我们尝试用三种不同的方法拟合非线性函数(曲线),即像素点级方法、分段级方法和整体级别方法。使用相同的MLP对这三种方法进行训练。实现细节可以在补充文件中找到。从图2的结果可以清楚地观察到,分段方法达到了最佳的拟合性能。相比之下,基于像素的方法无法重建正确的趋势。而整体方法策略倾向于添加一些不需要的高频细节,这可以被认为是工件伪影。这部分证明了我们的原始假设。点型、截面型和整体型可以分别类比为像素型、斑块型和图像型。上述现象可以启发我们使用补丁策略作为一种更有效的内隐表示方式。接下来我们将详细描述我们的PS-NeRV方法。

3.2 Represent videos as images patchs
对于任意视频 V = { v t } t = 1 T ∈ R T × H × W × 3 V = \{v^t\}^T_{t=1} \in \R^{T \times H \times W \times 3} V={vt}t=1T∈RT×H×W×3,我们将每一帧分为 N ∗ N N * N N∗N的补丁,于是得到 { v p t } p = 1 N 2 ∈ R N 2 × H / N × W / N × 3 \{v_p^t\}_{p=1}^{N^2} \in \R^{N^2 \times H/N \times W/N \times 3} {vpt}p=1N2∈RN2×H/N×W/N×3。接着,这些被切片的补丁将可以用一个函数隐式表示 f θ : R → R H / N × W / N × 3 f_\theta: \R \to \R^{H/N \times W/N \times 3} fθ:R→RH/N×W/N×3,通过一个深度神经网络 θ \theta θ参数化得到, v p i t = f θ ( t , i ) v_{p_i}^t = f_\theta (t,i) vpit=fθ(t,i),这个函数有两个输入分别是帧索引 t t t和补丁坐标 i i i,其输出是相应的补丁图像 v p i t ∈ R H / N × W / N × 3 v_{p_i}^t \in \R^{H/N \times W/N \times 3} vpit∈RH/N×W/N×3。因此,我们通过该神经网络 f θ f_θ fθ构造了从时空坐标到图像斑块的映射。在得到所有的补丁后,我们可以直接将它们拼接成一个完整的帧 v t ∈ R H × W × 3 v^t \in \R^{H×W ×3} vt∈RH×W×3。
3.3 Time-Coordinate Embedding
当将坐标作为神经网络的输入时,研究发现[22,23]将其映射到高嵌入空间,可以有效提高网络的拟合效果。除了补丁坐标 i i i之外,还有另一个输入——时间戳 t t t。我们使用位置编码[23,24,25]函数将这两个输入编码到嵌入中:

其中 b b b和 l l l是网络的超参数。根据视频的长度和补丁的数量,将时间戳t和坐标i归一化在(0;1]。然后,将它们的嵌入连接在一起,作为网络的输入。

3.4 Network Architecture
时间坐标嵌入的输入被发送到mlp的后续层,以获得适合后面块的大小。后一个补丁方面的程式化块(PSB)然后逐渐恢复到图像补丁。我们的PSB由卷积层和上采样层组成。AdaIN模块跟随在每个上采样层之后。在时间和坐标两个条件的共同作用下,网络输出的是小块图像而不是整幅图像。这样的做法大大减轻了网络的负担。实验还表明,该模型比基于图像的NeRV方法更容易拟合细节。
3.5 Time-Coordinate Stylization
训练过程就是对视频进行过拟合。NeRV发现在卷积神经网络中广泛使用的归一化层会降低基于卷积神经网络的INR的拟合能力。相反,我们发现将特征的均值和方差与目标帧对齐可以加快拟合过程,获得更高质量的结果。我们使用自适应实例归一化(AdaIN)[9]来根据时间坐标条件调制后面的卷积层的特征:
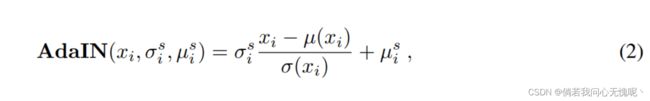
其中, µ ( x i ) µ(x_i) µ(xi)和 σ ( x i ) σ(x_i) σ(xi)分别表示第i个特征图的均值和方差。我们使用另一个MLP网络来学习后期AdaIN所需要的 σ s σ^s σs和 μ s \mu ^s μs
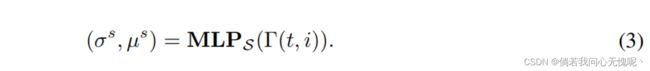
3.6 Objective Function
对于PS-NeRV,我们采用类似[7]的损耗函数,将L1和SSIM损耗结合起来进行网络优化。这个函数计算输出补丁和地面真实补丁之间的损失。为了减小同一帧内patch之间的差异,我们增加了一个额外的总变异正则化 L t v L_{tv} Ltv。最后的函数如下:

T T T是所有帧数量, N 2 N^2 N2是每个帧的所有补丁数量, f θ ( t , i ) ∈ R H / N × W / N × 3 f_\theta (t,i) \in \R^{H/N \times W/N \times 3} fθ(t,i)∈RH/N×W/N×3是PS-NeRV的预测结果, v p i t ∈ R H / N × W / N × 3 v_{p_i}^t \in \R^{H/N \times W/N \times 3} vpit∈RH/N×W/N×3是地面真值图像, α \alpha α是一个用于平衡各个损失组件权重的超参数。
4. Experiments
4.1 Datasets and Implementation Details
我们使用720 × 1080分辨率的132帧“大巴克兔”序列作为训练数据进行实验,并将结果与其他INR方法进行比较。在广泛使用的UVG[26]数据集上进行视频压缩实验,该数据集共有7个视频,3900帧,总帧数为1920 × 1080。我们使用Adam[27]优化器来训练整个网络。学习率设置为5e-4。在训练过程中,我们使用余弦宣布学习速率表[28],并设置热启动的epoch的数量为所有epoch的30%。我们在Big Buck Bunny上训练了1200个epcoh",以及150个周期的UVG实验。我们的整个模型中有5个PSB块,根据不同的补丁切片数量,会调整上标因子。在接下来的实验中,除非另有说明,补丁号设置为16,1080p视频设置为5、3、2、1、1, 720p视频设置为5、2、2、1、1。对于等式1中嵌入的输入,我们使用b = 1:25和l = 80作为我们的默认设置。对于式4中的损失目标,设α为0:7。我们只使用一层MLP来得到后面AdaIN层的均值和方差,其单位是这些卷积层的通道数的两倍。


4.2 Comparison with other INR methods
我们首先将我们的方法与基于像素和基于图像的INR方法进行比较。所有的模型都在同一时间进行“大巴克兔”序列训练。SIREN[29]和NeRF[23]保持原有结构,分别使用正弦激活函数和位置嵌入。对于NeRV[7],我们也使用它的默认设置。通过调整隐维数得到不同参数的模型。我们通过改变卷积滤波器宽度来构建与上述模型大小相当的PS-NeRV模型,分别命名为PS-NeRV-S、PS-NeRV-M和PS-NeRV-L。将PSNR作为评价重建视频质量的指标。表1显示了比较结果。与基于像素的和基于图像的方法相比,我们的基于patch的表示方法显著提高了图像质量。由于增加了AdaIN和一层MLP,解码速度会略有下降,但与NeRV的数量级保持一致。
4.3 Video Compression
一旦视频拟合完成,就可以通过模型压缩来达到视频压缩的目的。为了保证比较的公正性,我们采用与NeRV视频压缩相同的方式达到视频压缩的目的。模型压缩过程由三个连续的步骤组成:模型修剪、权重量化和权重编码。模型尺寸的缩小是通过全局非结构修剪实现的。当权重低于阈值时,它将被置为0。训练后进行模型量化。通过NeRV中使用的方程,每个参数都可以映射到一个“位”长度值。采用Huffman Coding[30]方案进一步压缩模型尺寸。然后在UVG数据集上与先进的方法进行比较。就像NeRV中的做法一样,我们将7个视频连接成一个视频进行训练。图5显示了速率失真曲线。我们比较H.264 [11], HEVC [13], STAT-SSF-SP [31],HLVC [32], Scale-space [33], Wu等[34]。H.264和HEVC在 m e d i u m medium medium预设模式下执行。我们的方法在任何情况下都优于图像方法。当BPP较小时,我们的方法甚至超过了传统的视频压缩技术和其他基于学习的视频压缩方法。图6显示了解码帧的可视化。在类似的情况下,PS-NeRV可以重建更精确的细节。

4.4 Video Inpainting
视频补强是一种融合时空信息,以合理内容填补视频帧中缺失区域的任务。最近的方法设计了复杂模型来解决这一问题,如Visual transformer[35]和convl - lstm[36]。而我们的方法通过对不完整的视频进行简单的拟合,就可以达到视频嵌入的目的。具体来说,给定一个蒙板视频,在训练过程中,对含有缺失区域的补丁不进行采样。训练完成后,我们可以将这些缺失区域的坐标输入到网络中,得到相应的图像补丁。我们将我们的结果与最先进的基于变压器的方法ViF[35]进行比较。如图7所示,在缺失区域很大的情况下,ViF[35]很难生成有意义的内容,只能填充非常模糊的结果。相比之下,通过建立帧补丁和时空坐标之间的精确映射,我们的方法产生了清晰的结果,几乎与地面真值图像没有区别。
4.5 Ablation Study
该方法的两个关键组成部分是补丁级表示和通过AdaIN实现特征的程式化调制。为了验证各部分的作用,我们还在“大巴克兔”序列进行了消融研究。我们首先研究了补丁数量对结果的影响。
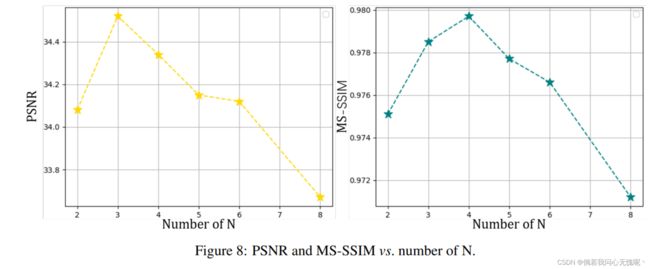
针对不同的贴片数设计不同的上采样因子,并通过改变滤波器宽度得到相同尺寸的模型。如图8所示,当补丁数量增加时,PSNR会下降。这是因为当patch数量增加时,方法会变得更接近像素,导致拟合效率下降。适当的补丁数量可能在不同的视频之间有所不同,而太多的补丁总是会降低质量和效率。
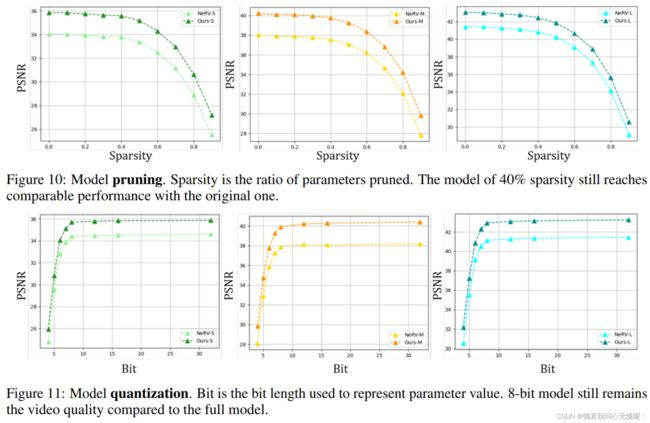
然后,为了研究AdaIN的效果,我们从架构中删除了这一层。此外,我们还将AdaIN引入到NeRV框架中,以同样的方式调制特征。从表2可以看出,这种做法可以提高patch-wise和image-wise方法的质量。图9显示了一个比较示例。右侧PS-NeRV获得的图像细节更加准确和丰富。我们还对模型压缩进行了消融研究,并将结果与NeRV进行了比较。图10和图11分别显示了不同剪枝比和量化步骤的结果。我们的方法在各种压缩条件下都超过了NeRV。

5. Discussion
Limitations and Future Work. 提出的PS-NeRV有一些局限性。首先,我们的patch-wise表示法会增加训练过程中对显存的需求。幸运的是,即使是普通的1080Ti GPU也可以满足1080 p视频小于64个补丁的训练需求。此外,我们还从零开始培训整个网络。为了保证视频重构的质量,我们仍然需要比传统视频压缩方法的编码时间更长的训练时间。在未来的工作中,我们可能会引入一些元学习方法提高网络培训的效率,但这并不是这项工作的目的。最后,模型压缩方法也值得进一步探索。
Conclusion. 在本文中,我们探索了一种更适合视频的隐式表示方法。受到现实信号中广泛存在的局部相似性的启发,我们提出了一种更有效的视频补片INR方法。我们发现,与以往的基于像素和图像的方法相比,基于patch的表示方法兼顾了效率和准确性。大量的实验表明,我们的方法可以应用于视频相关的应用,如视频压缩和视频嵌入。补丁级隐式表示(PS-NeRV)可能是未来视频表示的一种重要方法。此外,考虑到INR方法的巨大潜力,它可能在未来取代传统的视频表示。