JavaSE---字节流
Java—字节流
一.字节流概述
假如我们想用Java程序将C盘中的文件拷贝到D盘中,我们要知道Java程序是运行在内存中的而C盘和D盘属于硬盘,那么我们就要将C盘的二进制文件用java程序读入到内存中然后再写出到D盘,这样就完成了拷贝。这种读入和写出的方式就是使用流的方式。
二.字节流的概念
1.Java对数据的操作是通过流的方式
2.Java用于操作流的类都在IO包中
3.流按流向分为两种:输入流,输出流
4.流按操作类型分为两种:
a.字节流: 可以操作任何数据,因为在计算机中任何数据都是以字节的形式存储的
b.字符流: 只能操作纯字符数据,比较方便。
三.IO流常用父类
1.字节流的抽象父类: InputStream和OutputStream
2.字符流的抽象父类:Reader 和 Writer
(注意:使用前,导入IO包中的类,使用时,进行IO异常处理,使用后,释放资源)
四.FileInputStream的使用
1.read()方法一次读取一个字节并且返回值是一个int
2.
示例:
创建一个文件:
package CSDN;
import java.io.FileInputStream;
import java.io.IOException;
public class StudyFileInputStream {
public static void main(String[] args)throws IOException {
//创建一个字节输入流来读取文件
FileInputStream fis =new FileInputStream("aaa.txt");
int b;
while ((b=fis.read()) !=-1){
System.out.println((char)b);
}
fis.close();
}
}
读取的过程:
fis.read每次读取一个字节也就是八位,它会在高位填上24个0组成一个32位的二进制赋给b,因为b是一个整形是32位的。然后再将b这个32位二进制转换成补码再转换成十进制和-1比较。最后 (char)b 将32位整形的高16位抛弃掉 那么低16位的二进制去unicode编码集中寻找对应的字符。
运行结果:成功读取到了文件中的数据

2.1 read()==-1的含义
* Reads the next byte of data from the input stream. The value byte is * returned as an <code>int</code> in the range <code>0</code> to * <code>255</code>. If no byte is available because the end of the stream * has been reached, the value <code>-1</code> is returned. This method * blocks until input data is available, the end of the stream is detected, * or an exception is thrown.
* * <p> A subclass must provide an implementation of this method.
* * @return the next byte of data, or <code>-1</code> if the end of the * stream is reached.
* @exception IOException if an I/O error occurs.
read();方法源码中写到,read每次从字节流中读取一个字节。如果将全部字节都读完那么就返回-1。
2.2 为什么返回一个int?
因为字节输入流可以操作任意类型的文件,比如图片音频等,这些文件底层都是以二进制形式的存储的,如果每次读取都返回byte,有可能在读到中间的时候遇到111111111,那么这11111111是byte类型的-1,我们的程序是遇到-1就会停止不读了,后面的数据就读不到了,所以在读取的时候用int类型接收,如果11111111会在其前面补上24个0凑足4个字节,那么byte类型的-1就变成int类型的255了这样可以保证整个数据读完.
2.3 为什么文件中的英文字符是GBK编码转换成Unicode不会乱码?
abc
假设字符abc在GBK中对应的八位二进制是
a-- > 1011 1101
b-- > 1011 1111
然后扔到unicod编码集中
读入的时候由于是int类型所以要先填补24个0
a–>24个0 1011 1101
又因为要强转成char类型为并且unicode中16位对应一个英文字符
a–>8个0 1011 1101
这样unicode编码就每次读取八位就获取到了字符。
2.4 为什么中文就会乱码呢?
我们将文件中的字符换为中文
运行结果:
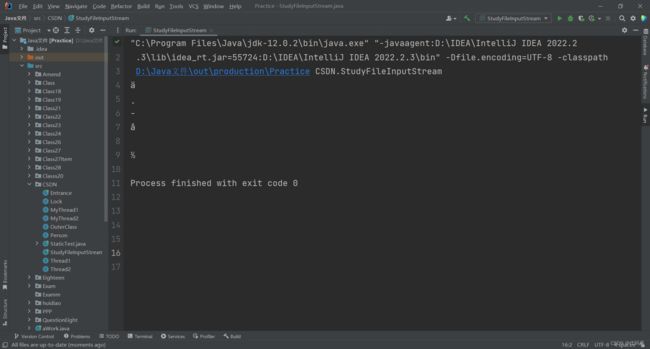
一个中文字符在GBK编码集中对应的是16位二进制和英文的八位不同
中–>1011 1111 1011 1101
然后扔到unicode编码集中:
补24个0
中–>24个0 1011 1111
留下十六位 每次读取八位
中–>8个0 1011 1111
这样只读取到了中字的前八位字符当然会乱码。
五.FileOutPutStream的使用
package CSDN;
import java.io.FileOutputStream;
import java.io.IOException;
public class StudyOutPutStream {
public static void main(String[] args) throws IOException {
FileOutputStream fos =new FileOutputStream("cxk.txt");
fos.write(1);
fos.write(0);
fos.write(3);
}
}
结果生成了一个cxk.txt的文件:
![]()
每次写出一个字节的过程:
1举例
1–>转换成补码的形式–>32位的int–>高24位扔掉—>留下八位读入
(write方法参数列表是一个 int,但是会将前面的24位去掉,所以结果是写出一个byte)
六.拷贝文件
1.效率最低的方法
我们要拷贝klm这张图片到mlk中去

代码:
package CSDN;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class StudyOutPutStream {
public static void main(String[] args) throws IOException {
//生成一个输入流
FileInputStream fis =new FileInputStream("klm.jpg");
//生成一个输出流
FileOutputStream fos =new FileOutputStream("mlk.jpg");
int b;
//每次读入一个字节(在高位填24个0)
while ((b=fis.read()) != -1){
//每次写入一个自己(去掉高位的24个0)
fos.write(b);
}
//关闭流
fis.close();
fos.close();
}
}
结果拷贝成功:
1.1为什么说这种方式是效率太低呢?
因为这种方式是每次从硬盘中读取一个字节再输出一个字节。假如你要拷贝一个很大的音频呢?一个字节一个字节就很慢咯。
2.改进—自定义长度读取
代码:
package CSDN;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class StudyOutPutStream {
public static void main(String[] args) throws IOException {
//生成一个输入流
FileInputStream fis =new FileInputStream("klm.jpg");
//生成一个输出流
FileOutputStream fos =new FileOutputStream("mlk.jpg");
//len代表下面 每次读取到几个字节就返回几个字节
int len;
//2代表每次读取俩个字节(可自定义读取长度)
byte[] arr=new byte[2];
while ((len=fis.read()) !=-1){
//每次从arr数组的第一个位置开始写入len读取到的长度
fos.write(arr,0,len);
}
//关闭流
fis.close();
fos.close();
}
}
3.用jdk给我们装好的类
3.1BufferedInputStream:
- 内置了一个缓冲区(数组)
- 会一次性从文件中读取8192个, 存在缓冲区中
- 直到缓冲区中所有的都被使用过, 才重新从文件中读取8192个
3.2 BufferedOutputStream
- BufferedOutputStream也内置了一个缓冲区(数组)
- BufferedInputStream会一个字节一个字节将自己的数据赋给BufferedOutputStream的缓冲区(发生在内存中,速度很快)
- 直到缓冲区写满, BufferedOutputStream才会把缓冲区中的数据一次性写到文件里
图示:

代码:
package CSDN;
import java.io.*;
public class StudyOutPutStream {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("致青春.mp3");
BufferedInputStream bis = new BufferedInputStream(fis);
FileOutputStream fos = new FileOutputStream("copy.mp3");
BufferedOutputStream bos = new BufferedOutputStream(fos);
int b;
while((b = bis.read()) != -1) {
bos.write(b);
}
bis.close();
bos.close();
}
}
3.2 注意:小数组的读写和带Buffered的读取哪个更快?
a. 定义小数组如果是8192个字节大小和Buffered比较的话,定义小数组会略胜一筹,因为读和写操作的是同一个数组
b.Buffered操作的是两个数组
七.利用try-finally结构处理IO流中可能产生的异常
希望大家去这样写:保证流关闭的同时去处理空指针等异常
package Amend;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class A {
void test() throws IOException{
//局部变量需要手动初始化
FileInputStream fis = null;
FileOutputStream fos = null;
try {
//创建输入流和输出流
fis = new FileInputStream("aaa.txt");
fos = new FileOutputStream("bbb.txt");
int b;
while((b = fis.read()) != -1) {
fos.write(b);
}
//第一个finally:无论如何都要进行关闭流的操作
} finally {
try {
//假如14行出现异常那么 fis可能还是null 会报空指针异常所以需要一个判断
if(fis != null)
//假如fis.close抛出异常那么fos.close就无法运行所以需要第二个finally
fis.close();
//第二个finally
}finally {
if(fos != null)
fos.close();
}
}
}
}