《ArchSummit:从珍爱微服务框架看架构演进》

1、前言
今年的ArchSummit的主题是“数字化转型下的架构升级”,主要聚焦:云原生、研效提升、IoT 系统架构、微服务架构、低代码系统、出海业务架构、人工智能与机器学习、企业数字化转型、前端 Serverless 研发体系、金融领域数字化转型、大数据实践与应用等领域。
笔者从事互联网行业4年有余了,今年是第二次参加ArchSummit全球架构师峰会,主要关注点是“微服务架构”板块下的各位老师的技术分享,这里对珍爱网CTO彭万亮老师的《珍爱微服务底层框架演进》进行一些总结,欢迎大家一起补充交流~~
2、讲师介绍
彭老师是位非常资深的技术人,在互联网行业有接近20年的从业经验,目前在珍爱网担任CTO。

3、珍爱微服务框架编年史
珍爱网的微服务框架的演进,是逐步进化的结果:
-
2018年经历了业务微服务拆分:解耦业务并解决复杂度难题
-
2019年完成了数据层改造:解决业务数据层痛点
-
2020年完成了容器化部署和DevOps流水线设计:提升系统可扩展和高可用的云原生能力
-
2021年实现业务异地多活(双云双活):提升了系统容灾能力和服务安全性

4、珍爱微服务框架演进
4.1 面临问题
彭老师介绍到,自2018年珍爱网业务规模爆发性增长,研发团队存在着四个方面的问题:
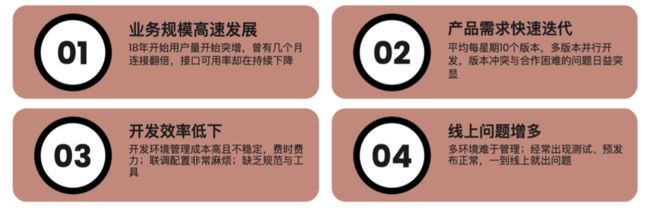
4.2 突破方向
因此他们的团队开始着重建设基础架构,并在四个维度进行集中突破,即:服务架构、基础组件、研发流程、研发规范;

在珍爱长达4年的架构演进之路上,开发团队经历了微服务拆分、链路优化、上云、容器化、双云双活等,并在每个环节都有相应的思考,在反复地暴露问题、解决问题之后,最终沉淀出一套珍爱特色的微服务治理架构,即形成最终的一套底层框架,这套框架有以下几个特点:
-
整合开源框架,结合业务二次开发
-
构建一套技术规范
-
统一技术底层
4.3 架构演进
4.3.1 微服务拆分
4.3.1.1 业务拆分
虽然每个企业的业务大不相同,但是微服务拆分的方法论大致一样,所以彭老师在这个题目下,并没有作过多的展开;但是从介绍的PPT里,我们还是可以清晰了解到珍爱在拆分微服务的思路是,按照业务模型去切割,并垂直拆分为了多个微服务,包括了:unify-pay、core-user、verify等等;
4.3.1.2 微服务框架
珍爱的微服务拆分,在技术层面有以下四个特点:

主流的Java商业项目,都会以SpringCloud开源框架作为底层支撑,而珍爱的微服务框架则是巧妙的将SpringCloud和Dubbo两个框架一起整合并为其所用,这应该是珍爱框架的一大亮点了。

4.3.1.3 DDD与降本增效
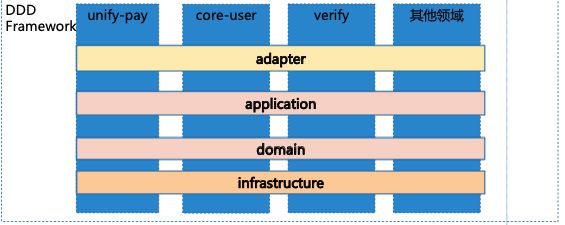
此外,彭老师还很着重的提到一个技术实现要点:基于DDD领域模型的业务拆分,在部署上,将原api层和 provider层合并在一个节点上,能提高调用开销并节省硬件资源,进而实现“降本增效”。

那么珍爱是具体怎么做到的呢?
通过引入DDD领域模型,业务API降低了耦合性;这里涉及到垂直拆分(从下往上设计),各业务领域实现 以分层分包的方式进行代码组织,结构更清晰,更合理。
-
adapter:每个领域的对外接口实现,每个业务在每一层的接口实现不一样(OpenApi、客户端、web端等)
-
application:业务组合
-
domain:领域层
-
infrastructure:最基础服务的支撑
2022年,互联网企业最流行的一个话题就是--降本增效了,而珍爱研发团队的落地实践,恰好给业界提供了一个研发思路:在把DDD领域拆分,结合业务粒度做到极致之后,不仅仅可以做到业务领域边界更清晰,更能通过优化部署方式实现降本增效,降低服务器维护成本。
4.3.2 微服务网关层改造
珍爱微服务网关层的改造是一个非常独具特点的工程。
-
一方面,它基于SpringCould-Gateway开源框架进行拓展,实现了网关层基础的能力:请求验证、黑白名单、基于sentinel的熔断限流(二次开发);
-
另一方面,珍爱网关对业务侧提供非常多的能力支撑,比如:合并请求、重试优化(Connection异常,服务不幂等解决不了)、优雅停机、启动预热、访问日志上报等。

4.3.2.1 合并请求
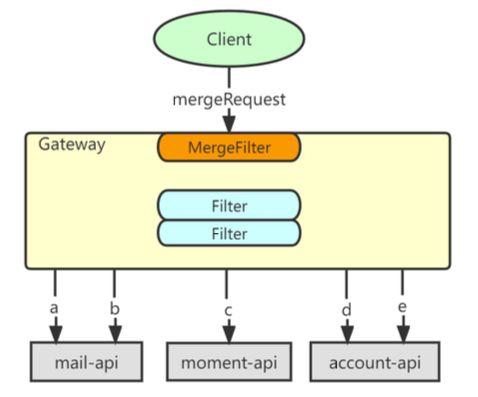
网关MergeFilter在不改动原接口前提下,允许客户端对请求组合编排,将多个请求合并为一,其目的是减少页面初始化时请求数过多的问题。其功能如下:
-
拆分请求:解析自定协议,将合并请求拆分为实际请求组。
-
并行执行:并行执行实际请求组,设置监听返回。
-
合并响应:改写response,以合并请求组下游服务响应。
-
降级和重试:配置超时和异常降级,并对失败请求执行重试。
-
请求监控:监控耗时差异过大的请求组,以优化编排。
4.3.3 数据层改进
4.3.3.1 面临问题
复杂业务系统最容易遇到瓶颈的环节就是数据库,同样,DB正是珍爱业务系统稳定性和性能最关键的一环,因此珍爱借助业务上云,对DB展开了多方面的优化。

4.3.3.2 数据拆分
第一步,分库分表:团队遵循微服务“一应用一数据库”的原则,对原有DB进行拆分。
之前未做是因为数据库管理成本较大,而业务上云后使用了云数据库,这个基础设施能力的提升,有助于快速实现目标架构。
4.3.3.3 去掉数据中间层
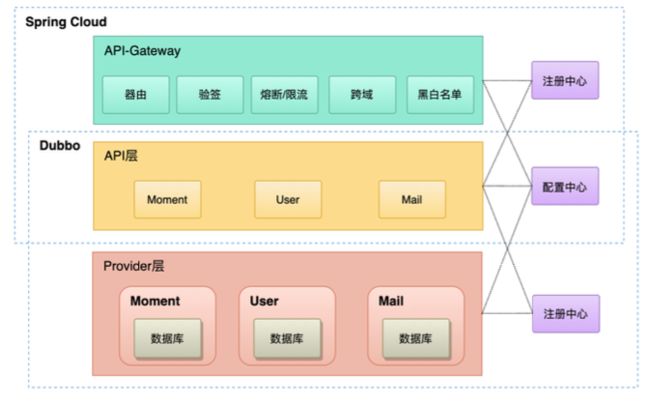
第二步,去掉中间件Mycat,应用直连数据库;zhenai-framework(珍爱底层框架)管理公共配置:分库分表算法、id生成规则、路由工具类等。整体架构如下:
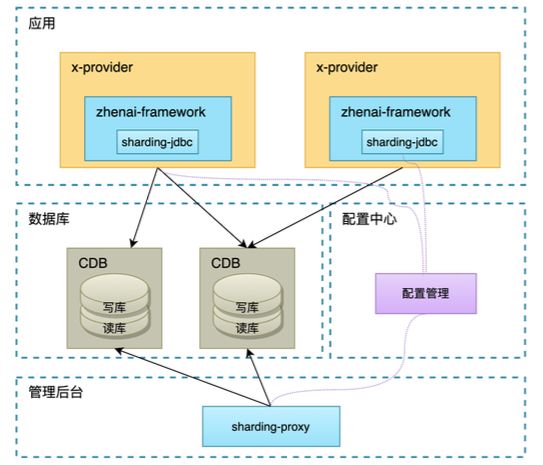
1)分库分表实现
珍爱底层通过对 sharding-jdbc 和 sharding-proxy 两个组件的引入,实现了上云之后的分库分表能力。
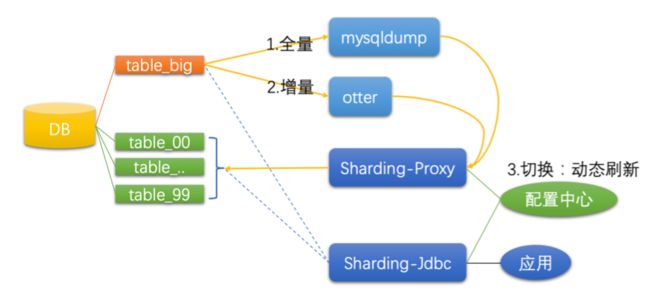
做到上面这一步骤的关键是:
sharding-jdbc是在代码层面解决分库分表问题,需要自行配置分库分表策略等;
sharding-proxy是一种数据库中间件,从数据库层面解决分库分表问题
2)配置隔离
读者到这一步容易产生疑惑:为什么同时引入了这两个组件呢?
彭老师给我们解答了这个问题:因为正式环境是需要不停机进行大表拆分,同时为了将DB配置等风险等级高的配置集中管理(使用了git系统保存)。
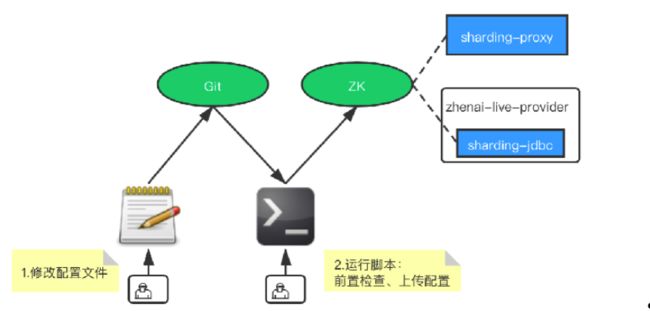
正式环境下,系统数据层与业务层配置,有着不同的风险等级;
-
业务层配置:页面组件配置等;
-
数据层配置:DB账号密码、连接超时等;
3)不停机连接切换
因为需要正式环境有不停机的要求,所以需要考虑到“数据库连接切换的实现”,这里彭老师也进行了详细的步骤拆分:
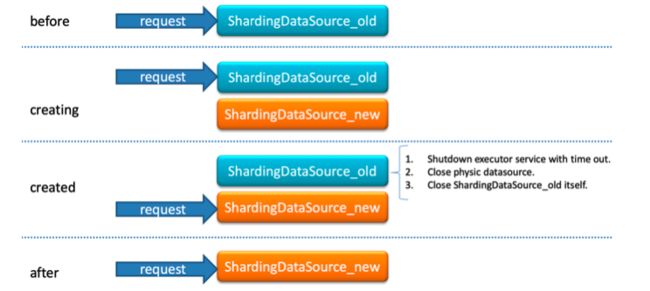
特别注意:这里,大家需要对自己的业务场景去思考,由于珍爱那边比较少遇到,类似大订单交易这种连接数量巨大的场景,因此最终选择了使用这种双倍连接的方式。
4.4 框架能力升级
珍爱在下面四个方面进行持续升级:
-
链路级熔断降级
-
单IP熔断
-
全链路优雅停机
-
启动预热

4.4.1 熔断降级
服务监控需要做的更加完善,否则服务降级不能暴露问题,因为在上层业务看,HTTP相应是正常的,但是底层是有异常的。
另外,服务重试这个环节,由于业务很难幂等,我们一般对连接异常进行重试就足够了,这个做法至少能够让我们的系统比没做重试,要好很多。
4.4.2 全链路优雅停机
珍爱的全链路优雅停机,整体上分为3个步骤:
-
服务下线
-
余下的业务逻辑处理完
-
销毁资源(线程池、调度任务、数据库连接、已有请求处理等等)
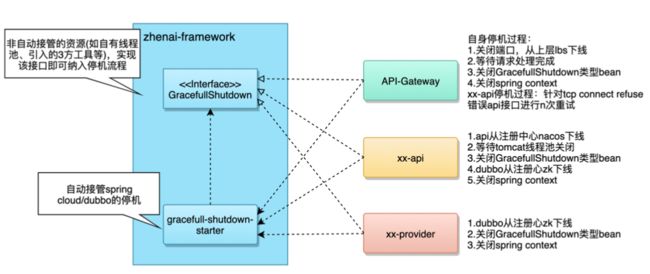
彭老师给了我们一些做优雅停机的经验:
-
开源组件已经实现了一套优雅停机,比如Dubbo,那么这套框架可以直接复用它们的实现;
-
如果自行封装了一套珍爱接口,所以需要优雅停机的组件,全部实现某个底层接口,那么就有一套统一规范来确保优雅停机不影响业务的规范。
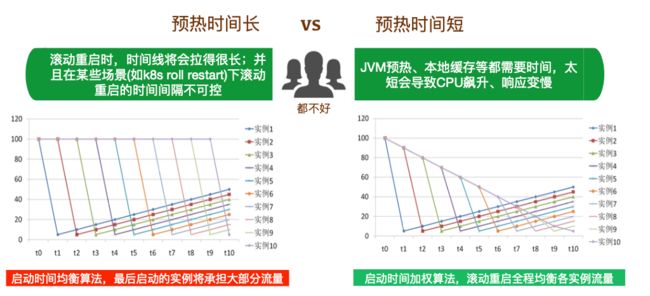
4.4.3 服务重启流量控制
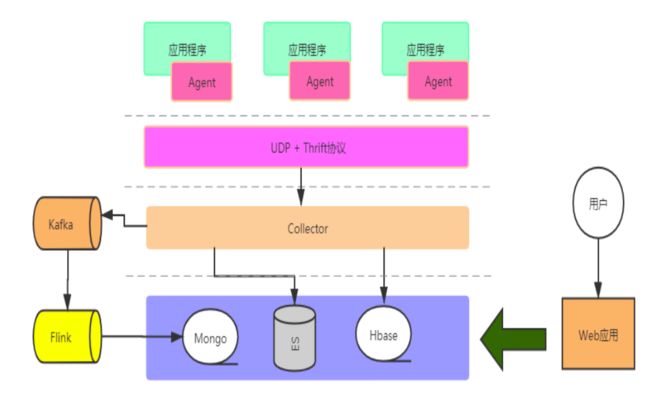
4.4.4 字节码增强-日志监控
Agent使用Java字节码无侵入式采集http访问日志,dubbo访问日志,业务日志,通过UDP上报到collector服务器;然后collector服务器将数据分别写入kafka、es、HBase,实现日志聚合。
4.4.5 Redis封装
框架统一提供API给业务层,借鉴了 MyBatis Mapper的思想,在定义的时候先声明存储结构和存储对象类型。
4.4.6 web层能力封装
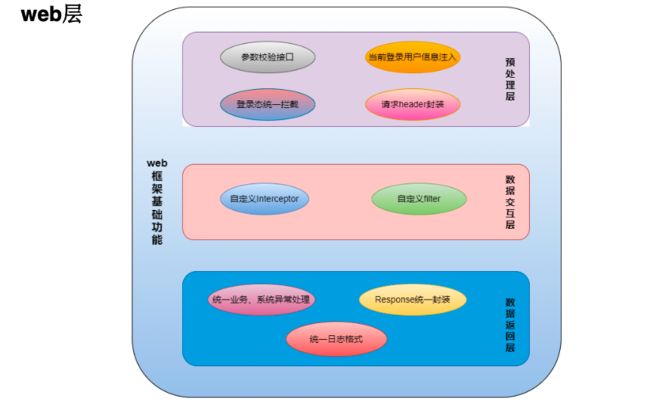
5、架构赋能与研效提升
5.1 面临问题
珍爱研发团队内部,也面临着一些问题:
-
资源隔离不充分
-
并行需求联调/测试困难
-
部署流程过多人为参与
-
多套环境难于管理
5.2 研发流水线搭建

5.2 容器化插件
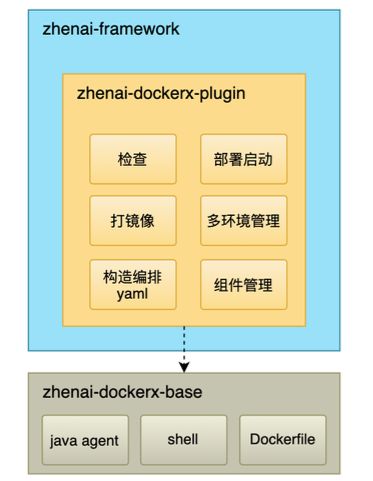
zhenai-dockerx-plugin是自研的一个maven插件,使应用透明接入docker、k8s。
其功能有以下六个点:
-
检查:分支检查、k8s ns检查
-
打镜像:使用zhenai-dockerx-base作为基础docker镜像
-
构造编排yaml:模拟模板渲染出k8s deploy/svc的yaml
-
部署启动:调用k8s接口部署
-
多环境管理:编排文件区分环境
-
组件管理:根据mvn参数判定是否部署对应组件,如nginx,主要用在开发、测试环境
5.3 请求染色

5.4 DevOps全周期

5.5 双云双活
zhenai-framework封装数据接入与适配中间件,同时中间件也支持双云模式。
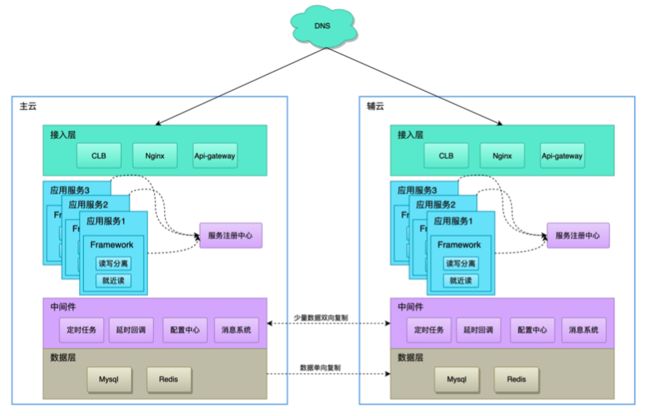
5.5.1 双云优势

6、架构经验分享
马云曾经说过,成功的经验千千万万,失败的原因就那么几个。在整个技术分享的过程里面,彭老师经常穿插提到,他们团队在架构演进过程中踩过的坑,下面进行一个梳理:
-
架构师团队:
-
在业务型企业做架构,高性价比的做法是:结合业务痛点找框架,能解决业务难题的框架就是好框架 ;
-
做方案设计优先看开源组件,避免重复造轮子和过度设计;
-
解决现有问题不是终点,技术架构必须要有前瞻性;
-
只有清楚系统承载量,才能更好知道如何去做微服务化;
-
自研框架的定制,应该基于本身业务,对开源框架进行二次开发;
业务框架:
-
优先考虑的是业务接入的易用性,然后是接入成本;
-
最理想的效果是,跟业务结合后,能解决90%的业务问题;
业务开发:
-
遇到的80%问题是数据库的问题,20%的问题是应用部署,10%是其他;
7、总结
最后用彭老师的架构演进理论来结束这次的总结,业务架构一定是伴随着业务的发展而不断完善的,前期可能是业务持续发展时不断暴露的问题,随之而来是一个个针对性的专项突破,最后是上升到框架层面的调整。

2022年全球架构师峰会PPT下载:链接
2021年全球架构师峰会PPT下载:链接