工程swift与OC混编改造
最近公司项目准备引入swift,由于目前工程已经完成了组件化不再是简单的单仓工程,所以需要进行混编改造。下面记录一下自己对工程进行混编改造的思考以及过程。
混编原理
看了很多文档,比较少有讲混编原理的,这里简单介绍一下语言进行混编的基本逻辑,因为我们都知道swift和OC可以混编,但是他们为啥能混编呢?
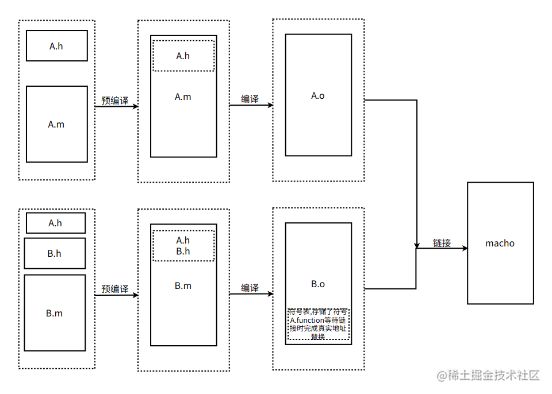
首先简单的过一下编译以及静态链接的流程:
-
预编译阶段,B.m将引入A.h以及B.h全部copy到B.m(这种预编译方式我们称它为文本模型)
-
编译阶段,B.m将B自身的方法地址全部编入符号表,但是编译的过程会碰到对A.function的调用,这个时候编译器检查A.function是否有声明,明确有(跟着A.h头文件copy过来的),但是并没有相应的实现,因此会将A.function的引用做一个特殊标记,并在重定位表中记录,等待静态链接成功后修改为指向A.function真实所在的地址
-
完成所有.o文件的符号表的合并,根据重定位表中的记录需要重新修改符号的地址,完成真实的A.function地址的特殊标记替换。
整个过程中只要生成的A.o以及B.o中间文件是按照编译器预期的格式组织的,那么静态链接器ld的就能根据格式缝合成最终产物:可运行的app。因此无论A和B是用什么语言编写的,只要编译器B本身能够识别出对应的语言A的声明,那么就可以在B的编译过程中标记A.function,并产出规定格式的.o文件。最终在静态链接器的帮助下完成对A.function的调用。(由上也可以看出头文件其实仅仅承担了符号标记的作用,其余的编译部分都是在实现文件中完成的)
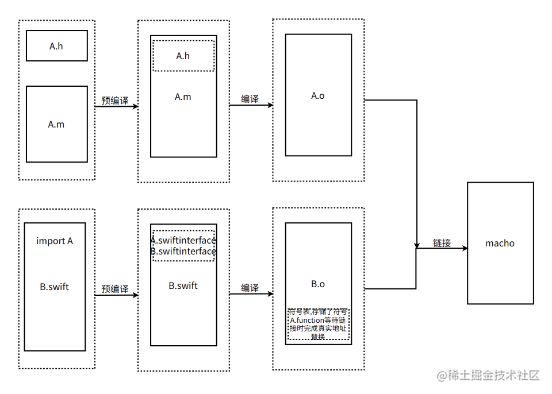
以上就是语言混编的基础。
备注:JAVA的编译逻辑稍有不同,这里只讨论java转class,不讨论class通过虚拟机变成真实地址的过程,java不像c系语言一样由链接器寻找最终符号地址,他们是由写代码的人直接使用全限定词指定符号在哪个文件,因此java编译成class以后符号地址就确定了,这也是java不需要头文件的逻辑,java与kotlin混编只需要保证编译出来的字节码标准统一即可混编,因为编译某个文件对其他文件有引用,编译器会立刻对引用文件进行编译生成class,由于java和kotlin都可以识别出字节码的规则,因此可以识别出相应的方法调用从而完成混编
swift与OC混编
了解了语言混编的基础之后我们再来落实到具体的语言:swift与OC的混编。
1. swift调用OC
swift的编译器swiftc包含了clang编译器的大量的功能,因此swift调用OC,其实就是依赖于swiftc将OC文件的声明转成swift的声明(.swiftiinterface),然后swift直接使用swift语法的OC方法声明,完成了对OC方法实现的调用。如下图所示(都是xcode自动生成的)

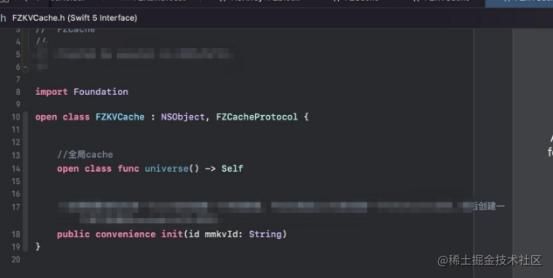
2. OC调用swift
因为历史原因,OC的编译器clang是无法识别swift语言的,因此要想让OC可以识别swift的声明需要依赖于swiftc编译器将swift声明转成OC声明(FZCache-swift.h),然后OC直接使用OC语法的swift方法声明,完成对swift方法实现的调用。
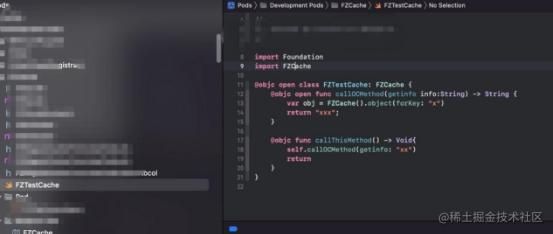
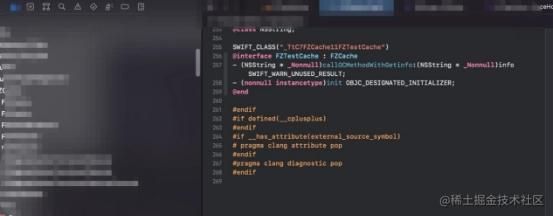
不管是swift声明转OC声明,还是OC声明转swift声明,以上两个过程中都暗含了一个关键的因素:头文件的查找,只有找到相应的声明转换后的头文件的位置,才能访问到方法声明。才能最终完成混编。
头文件查找
1. 基于文本模型的头文件查找
就是我们常规使用的方案#import头文件,跟#include本身区别不大,除了会自动去重,但是他们处理头文件的逻辑是一样的,每次编译一个.m文件都要重新对此.m文件中的头文件引入进行复制粘贴,因此理论上时间复杂度为O(m*n),另外由于采用的是复制粘贴替换的逻辑,因此在处理一些宏定义的时候容易出错,比如可能会存在某个定义
#define nonatomic @"nonatomic"
这个宏定义可能在某个文件中是没有任何问题的,但是如果有人使用了@property (nonatomic)这样的属性的时候就会导致代码出现错误,关键由于预编译采用的是复制的方式,即便是编译器再次报错,也会让间接引入了这个宏定义声明的开发者一下子难以查找到真正的问题位置
2. clang module
基于以上的问题,苹果提出了clang module的头文件查找方案,该方案声明了一种特定的文件组织形式,以静态库为例,静态库分成两种.a和framework,clang module规定静态库必须以如下方式进行资源的组织
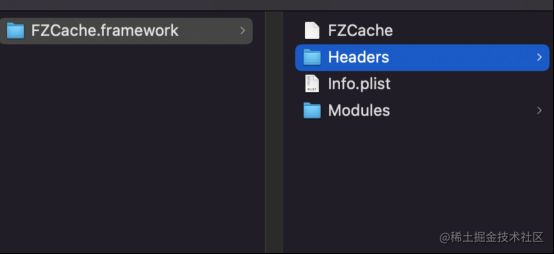

module使用以下方案对头文件进行访问:
@import FZCache.FZKVCache
当编译器读取到FZCache的时候就会从特定存储路径中查看是否存在有FZCache这个组件空间(也就是这里说的module),然后查询其中是否有FZKVCache的缓存产物,如果有则直接引用,如果没有就先找到FZCache.framework这个文件夹,然后进入Headers文件夹查询FZKVCache.h头文件,如果可以找到,再进入Modules文件查看是否有modulemap文件,如果有则启用module,在特定存储路径中创建一份单独的编译空间用于存放预编译缓存,否则报错,确认有modulemap文件后继续查看此描述文件中是否包含了FZKVCache.h,
framework module FZCache {
umbrella header "FZCache-umbrella.h"
export *
module * { export * }
}
module FZCache.Swift {
header "FZCache-Swift.h"
requires objc
}
#ifdef __OBJC__
#import
#else
#ifndef FOUNDATION_EXPORT
#if defined(__cplusplus)
#define FOUNDATION_EXPORT extern "C"
#else
#define FOUNDATION_EXPORT extern
#endif
#endif
#endif
#import "FZCache.h"
#import "FZKVCache.h"
FOUNDATION_EXPORT double FZCacheVersionNumber;
FOUNDATION_EXPORT const unsigned char FZCacheVersionString[];
显然FZCache-umbrella.h头文件中是包含FZKVCache.h的,因此编译生成FZKVCache的预编译产物放入FZCache module空间中,以备下次使用。
所以启用了clang module以后,组件只需编译一次,从理论上极大的降低了编译时间。
swiftmodule可以认为是clang module的升级版,基本上逻辑大同小异,但是针对swift的有一些特定的优化,我们可以简单的把swiftmodule和modulemap对应起来。在swiftmodule文件中存储了对整个模块以及模块内部子模块的二进制描述。

由于swiftc编译器只能通过clang module和swiftmodule识别到framework的头文件(如果是本target内部的头文件其实swiftc是能直接识别出来的,比如在主仓中swift通过桥接文件写入#import oc的头文件就可以识别到这些头文件),因此如果需要在swift仓库中引入OC仓库,就必须要对OC仓库进行clang module化。
备注:xcode对#import 做了优化,如果确认能找到modulemap文件,则启用clang module编译,转成@import A.A,如果未能找到则转成我们普通的#include 文本复制替换操作
鉴于目前所有的仓库都有可能需要使用混编,因此需要对所有的组件进行clang module化。
实现方案
我们将基于cocoapods完成所有仓库的module化。开启方法有多种。
1.use_framework!
2.use_modular_headers
3.自己写脚本生成modulemap,并组织好头文件。
这里我们选用use_framework!选项,即在开启所有仓库module化的同时,将生成产物从.a转变为framework.碰到头文件报错的位置就修改引用方式解决问题。要注意的是module化具有传递性,如果A开启了module,但是A依赖的B没有开启module,编译器就会报错。
使用方式
子仓的互相调用模式:
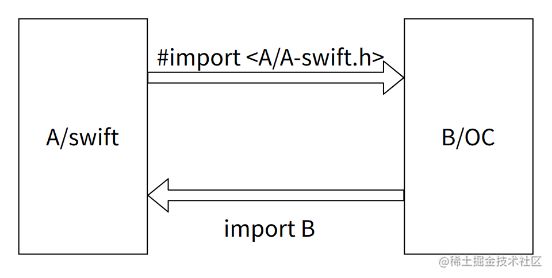
主工程内部调用方式
