【STL(2)】
STL(2)
- 知识点回顾
- 函数对象
-
- 函数对象理解
- 系统的仿函数
- 仿函数应用
- 容器适配器
-
- stack
-
- deque
- queue
- priority_queue
- map
-
- map使用
-
- 插入
- 访问
- 下标访问的应用:计算文件中单词的个数
知识点回顾
在STL库中存在三个容器适配器,stack - queue - priority_queue三种,其中栈和队列底层是由vector和list实现的而优先级队列是由vector实现。
函数对象
函数对象理解
class Add {
public:
int operator()(int a,int b)const{
return a+b;
}
}//函数对象,仿函数,函子
int main() {
Add add;
int x=10,y=20,z=0;
z=add(x,y);
//z=add.operator()(x,y);==》z=operator()(&add,x,y);
cout<<z<<endl;
return 0;
}
我们不看上面Add类的时候就会觉得我们直接调用了函数,实际上是重载了函括号的重载,这就是函数对象,也叫仿函数,有时也叫函子,我们这里的举例因为两个参数,所以是二元仿函数。而怎么让其具有通用性呢?使用模板,如下:
template<class _Ty>
class Add {
public:
_Ty operator()(const _Ty& a,const _Ty& b)const{
return a+b;
}
}
int main() {
Add<int>iadd;
Add<double>dadd;
int x=10,y=20,z=0;
z=Add<int>()(x,y);//z=Add().operator()(x,y);
return 0;
}
上面代码中由z=Add这一语句,代码中Add< int >是类型名加上括号是对象,也就是创建了无名对象,无名对象调用括号的重载函数。
系统的仿函数
系统中存在很多的仿函数,大于,大于等于,小于等,可以直接使用,这样也就很方便。
int main() {
int a,==10,b=20;
std::greater<int> gr;
if(x>y){}
if(gr(x,y)) {}
std::greater_equal<int> geq;
if(x>=y) {}
if(geq(x,y)) {}
}
仿函数应用
vector中没有直接的排序,需要调用系统的排序函数,而且只能是从小到大的排序,但是要是想要从大到小的呢?
int main() {
vector<int> ar={1,4,7,6,3,2,8};
std::sort(ar.begin(),ar.end(),std::less<int>())
for(auto &x:ar) {
cout<<x<<" ";
}
cout<<endl;
std::sort(ar.begin(),ar.end(),std::geater<int>());
for(auto &x:ar) {
cout<<x<<" ";
}
return 0;
}
测试上面代码我们就会发现加上greater< int >()参数之后会进行从大到小的排序,这是为什么呢?
我们模拟一下排序操作和仿函数的调用:
template<class _Ty>
struct my_less {
bool operator()(const _Ty&a,const _Ty &b) const{
return a<b;
}
};
template<class _Ty>
struct my_greater {
bool operator()(const _Ty&a,const _Ty &b) const{
return a>b;
}
};
template<class _BI,class _Fn>
void my_sort(_BI _first,_BI _last,_Fn fn) {
for(_BI i=_first;i!=_last;++i) {
_BI k=i;
for(_BI j=i+1;j!=_last;++j) {
if(fn(*k,*j)) {k=j;}
}
if(k!=i) {std::swap(*k,*i);}
}
}
int main() {
vector<int>ar={1,3,4,5,7,8,3,2,6,4,6,9};
my_sort(ar.begin(),ar.end(),my_less<int>());
for(auto &x:ar) {
cout<<x<<" ";
}
my_sort(ar.begin(),ar.end(),my_geater<int>());
for(auto &x:ar) {
cout<<x<<" ";
}
}
观察上面代码我们就可以看出排序算法实现过程中,大于小于一些运算是通过调动仿函数的比较程序来完成的,所以呢我们该百年其调用仿函数的参数就会使得其排序发生变化。系统调用也是一样的,如果不加入参数默认从小到大排序。
容器适配器
stack
栈中常用操作存在如下:

栈中存在操作如下:
int main() {
stack<int> ar;
for (int i = 9; i > 0; --i) {
ar.emplace(i);
}
while (!ar.empty()) {
int tmp = ar.top();
ar.pop();
cout << tmp << endl;
}
}
栈中默认是双端队列:
一种双开口得“连续”空间得数据结构,可以在头尾两侧进行删除和插入操作,并且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素,与list相比较,空间利用率高。但是其并不是真正得连续空间,是由一段段连续得小空间拼接而成得,实际deque类似于一个动态得二维数组。但是其不适合遍历,遍历时要频繁得使用迭代器频繁得去检测其是否移动到某段小空间得边界,导致效率低下,所以呢要在不同环境使用不同得底层。
int main() {
stack<Ptr,list<int>> is;//链栈
stack<int,vector<int>>vis;//顺序栈
stack<Ptr,deque<int> dis>;//双端栈
}
deque
双端队列可以通过范围for来遍历,但是我们看到的栈,优先级对列是不能用范围for遍历,因为容器适配器没有迭代器,其是随机性迭代器。
int main() {
deque<int> deq;
deq.push_back(12);
deq.push_back(23);
deq.push_front(100);
deq.push_front(200);
for(auto& x:deq) {
cout<<x<<" ";
}//200,100,12,23
}
其插入是从中间插入: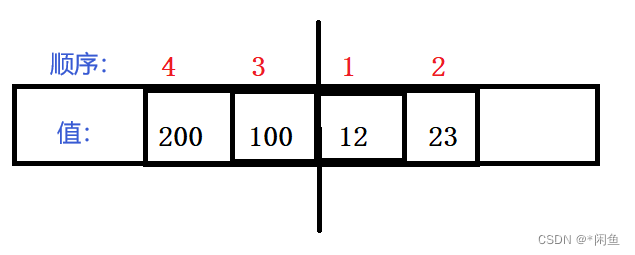
queue
队列得构建默认用双端队列,队列是先进先出,而使用vector,vector没有头删,所以不支持。但是可以通过list来作为底层实现。
int main() {
queue<int,deque<int>>qu;
queue<int,list<int>> lqu;
queue<int,vector<int>> vqu;//崩溃
}
priority_queue
优先级队列不管你插入顺序怎样,其输出顺序都是按照优先级进行输出的,这里数字大的优先级高。我们也可以通过改变参数来改变其优先级。注意双端队列只能通过vector来实现,因为只有vector是连续的空间结构,而优先级队列其实虽然叫队列但是其不满足先入先出的条件,像是数据类型中的堆,和堆排序的结构相同,逻辑上是完全二叉树,但要通过下标访问,所以物理上是顺序表,所以只必须是连续空间(连续空间才可以通过下标访问)。,每次出队是队列中优先级最高的元素出队,而优先级可以通过元素大小进行定义。
int main() {
priority_queue<int>pqu;
//priority_queue,greatrt> pqu;
pqu.push(23);
pqu.push(34);
pqu.push(12);
pqu.push(10);
pqu.push(45);
whiile(!pqu.empty()) {
int val=pqu.top();
pqu.pop();
cout<<val<<endl;
}
}
map
map使用
map的底层实现是一个红黑树。其中数据是是通过对的方式作为存放。
对的演示:
template<class T1,class T2>
struct my_pair {
using first_type=T1;
using second_type=T2;
first_type first;
second_type second;
}
my_pair<int,string>myp{23,"xin"};
template<class _Key,class _val>
class my_map {
using value_type=my_pair<_Key,_Val>;
struct _rbnode {
value_type data;
_rbndoe* leftchild;
_rbndoe* rightchild;
_rbndoe* parent;
int color;
}
}
插入
因为结构所以插入是这样插入的:
int main() {
std::map<std::string,int> simap;
simap.insert(std::map<std::string,int>::value_type("xin",12));
simap.insert(std::map<std::string,int>::value_type("lin",75));
simap.insert(std::map<std::string,int>::value_type("wan",43));
simap.insert(std::map<std::string,int>::value_type("axn",53));
simap.insert(std::map<std::string,int>::value_type("cen",42));
for(auto& x:simap) {
cout<<x.first<<" "<<x.second<<endl;
}
return 0;
}
其中输出结果不是按照插入顺序插入的,会按照字符串大小顺序进行输出。当然其结果也可以通过参数改变函数对象来改变其存放顺序。
但是通常不会这么插入,因为代码过于复杂,
int main() {
using SIMAP=std::map<std::string,int>;
using ValType=std::map<std::string,int>::value_type;
SIMAP simap;
simap.insert(ValType("xin",12));
simap.insert(ValType("lin",75));
simap.insert(ValType("wan",43));
simap.insert(ValType("axn",53));
simap.insert(ValType("cen",42));
for(auto& x:simap) {
cout<<x.first<<" "<<x.second<<endl;
}
SIMAP::iterator it=simap.begin();//迭代器
for(;it!=simap.end();++it) {
cout<<it->first<<" "<<it->second<<endl;
}
return 0;
}
访问
map访问方法仍然有两种:
- at函数查询,
- []下标重载遍历
两种访问方式的不同之处:
at函数仅仅是查找元素,查找不到程序就会报错,抛出异常,而用下标查找遍历,找不到就会自动进行添加该元素,其关键码默认为0.找到就会返回其关键码。
int main() {
using SIMAP=std::map<std::string,int>;
using ValType=std::map<std::string,int>::value_type;
SIMAP simap;
simap.insert(ValType("xin",12));
simap.insert(ValType("lin",75));
simap.insert(ValType("wan",43));
simap.insert(ValType("axn",53));
simap.insert(ValType("cen",42));
cout<<simap.at("cen")<<endl;
cout<<simap["axn"]<<endl;
simap["xa"];//找不到就会添加该字符串,而int值就会使用默认的缺省值0.
std::map<int,string> ma;
cout<<ma[1];
return 0;
}
下标访问的应用:计算文件中单词的个数
统计文件中单词的个数和出现的频率,按出现频率输出单词:这就用到了下标访问
#define BEGIN 0
#define IN_WORD 1
#define OUT_WORD 2
int main() {
FILE* fp = fopen("xxin.cpp", "r");
if (nullptr == fp)exit(EXIT_FAILURE);
int const len = 256;
char buff[len] = {};
int tag = BEGIN;
int posi;
std::map<string,int> mp;
while (!feof(fp)) {
fgets(buff, len, fp);
for (int i = 0; buff[i] != '\0'; ++i) {
switch (tag)
{
case BEGIN:
if (isalpha(buff[i])) {
posi = i;
tag = IN_WORD;
}
else {
tag = OUT_WORD;
}
case IN_WORD:
if (!isalpha(buff[i])) {
std::string word(&buff[posi], i - posi);
mp[word]+=1;
//cout << word << endl;
tag = OUT_WORD;
}
break;
case OUT_WORD:
if (isalpha(buff[i])) {
posi = i;
tag = IN_WORD;
}
default:
break;
}
}
}
fclose(fp);
fp = nullptr;
for (auto& x : mp) {
cout << x.first << "==>" << x.second << endl;
}
std::multimap<int, string,greater<int>>mp1;//多重map,可以重复
for (auto& x : mp) {
mp1.insert(std::multimap<int, string>::value_type(x.second, x.first));
}
for (auto& x : mp1) {
cout << x.first << "==>" << x.second << endl;
}
}