贝叶斯分类-文本分类案例
如何从一条短信内容判断它是垃圾短信(Spam)的可能性?
如何从一份邮件内容判断它是垃圾邮件(Spam)的可能性?
假设已经有大量短信文本,并且已知每条短信是否垃圾短信。那么再给出一条新短信文本,如何根据已有短信信息对这条新短信做出判断?
一、构造词汇表
''' 演示如何构造词汇表
分词工具:jieba分词,ltp分词,ir分词
'''
import numpy as np
# 模拟训练数据
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], # 第1个文本,已拆分成单词
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], # 第2个文本
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], # 第3个文本
['stop', 'posting', 'stupid', 'worthless', 'garbage'], # 第4个文本
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], # 第5个文本
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] # 第6个文本
classVec=[0, 1, 0, 1, 0, 1] # 上述每个文本对应的类型:1表示不当言论,0表示正常言论
return postingList, classVec
# 构造词汇表
def createVocabList(dataSet):
vocabSet = set([]) # set具有保证元素唯一性的特点
for document in dataSet:
# 先从document中取出所有单词(去掉重复的),然后再与之前的vocabSet合并(并且去掉重复性的单词)
vocabSet = vocabSet | set(document) # 集合运算。去重
return list(vocabSet)
listPosts, listClasses = loadDataSet()
myVocabList = createVocabList(listPosts)
print("词汇表总所有元素:", myVocabList)
print("词汇表总长度:", len(myVocabList))![]()
二、将每个文本语句表示成特征向量形式
# 将inputSet(也就是一个语句)拆分成多个单词,并生成一个Feature行,标记每个单词在词汇表中是否存在
def setOfWords2Vec(vocabList, inputSet):
returnVec=np.zeros(len(vocabList)) # 每个元素对应vocabList中的一个单词
for word in inputSet:
if word in vocabList:
# inputSet中的某个单词存在vocabList中,则returnVec中对应单词位置元素值设为1
returnVec[vocabList.index(word)] = 1
else: print('单词【%s】在词汇表中暂不存在,忽略!'% word)
return returnVec
trainMat=[] # 定义训练数据。每行数据代表一个语句的特征向量表达
for postinDoc in listPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
for trainFeature in trainMat:
print(trainFeature)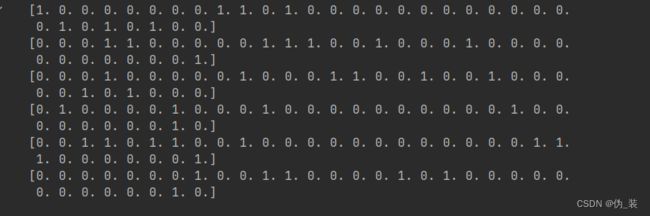
三、计算每个单词在每种文本类别中的先验概率
# 执行训练(计算先验概率),返回统计出来的几个先验概率值:
# p0Vec:正常语句中,每个单词占总单词数的比例(概率)
# p1Vec:不当语句中,每个单词占总单词数的比例(概率)
# pAbusive:不当语句占总语句的比例
def train(trainMatrix, trainCategory):
# trainMatrix中每行都是一个数组(长度为单词表长度),记录了一条语句中的每个单词是否在单词表中存在。
# 如果存在,则数组中对应单词位置元素值为1,否则为0
numTrainDocs = len(trainMatrix) # 语句的数量
numWord = len(trainMatrix[0]) # 单词表的容量
pAbusive = sum(trainCategory) / len(trainCategory) # 计算不当语句占所有语句的比例(p1),注意不当语句类别值设为1
# 初始化为1,实际上是考虑了拉普拉斯平滑中,分子要加Alpha(1)的情形
p0Num = np.ones(numWord) # 存放每个单词在正常语句中出现的次数
p1Num = np.ones(numWord) # 存放每个单词在不当语句中出现的次数
# 分母部分先算上拉普拉斯平滑中应该追加的Lambda*Alpha,其中Lambda取单词表的容量,Alpha设为1
p0Demon = numWord # 存放正常语句中单词的总数
p1Demon = numWord # 存放不当语句中单词的总数
for i in range(numTrainDocs):
if trainCategory[i] == 0: # 正常语句
p0Num += trainMatrix[i] # 向量相加(分别记录每个单词的数量)
p0Demon += sum(trainMatrix[i]) # 累加单词总数
else:
p1Num += trainMatrix[i]
p1Demon += sum(trainMatrix[i])
p0Vec= np.log(p0Num / p0Demon) # 正常语句中,对数形式的单词概率
p1Vec= np.log(p1Num / p1Demon) # 不当语句中,对数形式的单词概率
return p0Vec, p1Vec, pAbusive # 返回正常语句中,对数形式的单词概率;不当语句中,对数形式的单词概率;不当语句占总语句的比例
p0v, p1v, pAb = train(trainMat, listClasses)
print("不当语句占比:", pAb)
print("每个单词在不当语句中出现的概率(对数形式):", p1v)
四、预测新语句所述的类别
# 执行预测分类,用于计算判断分类结果
def classify(vec2Classify, p0Vec, p1Vec, pAb):
p1 = sum(vec2Classify * p1Vec) + np.log(pAb)
p0 = sum(vec2Classify * p0Vec) + np.log(1 - pAb)
if p1 > p0: # 对比哪个类别可能性更高
return 1
else:
return 0
testEntry1 = ['love', 'my', 'dalmation'] # 待预测的语句,以单词数组形式存在
testEntry2 = ['stupid', 'garbage']
thisDoc1 = setOfWords2Vec(myVocabList, testEntry1) # 按照单词表,构造本语句的单词向量形式
thisDoc2 = setOfWords2Vec(myVocabList, testEntry2)
#作业任务:根据上述案例1,2,3,4内容 打印出testEntry1和testEntry2的分类结果
print(testEntry1, 'classified as:',classify(thisDoc1, p0v, p1v, pAb))
print(testEntry2, 'classified as:',classify(thisDoc2, p0v, p1v, pAb))![]()