消息中间件第八讲:消息队列 RocketMQ 版实战、集群及原理
消息中间件第八讲:消息队列 RocketMQ 版实战、集群及原理
文章目录
- 消息中间件第八讲:消息队列 RocketMQ 版实战、集群及原理
-
- 1、MQ实例详情
- 2、MQ的Group管理
- 3、RocketMQ是如何保证消息队列的高可用? (6分)
-
- 3.1 Master/Slave 方案
- Action:在性能和数据可靠性之间选择一个,我们选择的性能,造成的问题
- 4、消息中间件集群情况如何?
-
- 4.1、高可用整体架构
- 4.2、消息存储结构
- 4.3、刷盘机制
- 4.4、主从复制
- 4.5、负载均衡
-
- 1、Producer负载均衡
- 2、Consumer负载均衡
- 4.6、消息重试和死信队列
-
- 1、发送端重试
- 2、消费端重试
- 4.7、重试队列和死信队列
- 5、部署方式
- 6、RocketMQ Dashboard使用教程
-
- 1. 创建主题 Topic
- 2. 创建消费者组 consumer
- 3. 重置消费位点
- 4. 扩容 Topic 队列
- 5. 扩容 Broker
- 6. [发送消息](https://rocketmq.apache.org/zh/docs/deploymentOperations/17Dashboard#6-发送消息)
- 7、RocketMQ Promethus Exporter
-
- 介绍
- 8、基本最佳实践
-
-
- 8.1、[Keys的使用](https://rocketmq.apache.org/zh/docs/bestPractice/15bestpractice#keys的使用)
- 8.2、[日志的打印](https://rocketmq.apache.org/zh/docs/bestPractice/15bestpractice#日志的打印)
- 8.3、[消息发送失败处理方式](https://rocketmq.apache.org/zh/docs/bestPractice/15bestpractice#消息发送失败处理方式)
- 8.4、[消费过程幂等](https://rocketmq.apache.org/zh/docs/bestPractice/15bestpractice#消费过程幂等)
- 消费速度慢的处理方式
- 8.5、[提高消费并行度](https://rocketmq.apache.org/zh/docs/bestPractice/15bestpractice#提高消费并行度)
- 8.6、[批量方式消费](https://rocketmq.apache.org/zh/docs/bestPractice/15bestpractice#批量方式消费)
- 重置位点跳过非重要消息
- 优化每条消息消费过程
- 消费打印日志
-
- Broker
-
- [Broker 角色](https://rocketmq.apache.org/zh/docs/bestPractice/15bestpractice#broker-角色)
- FlushDiskType
- [Broker 配置](https://rocketmq.apache.org/zh/docs/bestPractice/15bestpractice#broker-配置)
- 9、如果让你写一个消息队列,该如何进行架构设计啊?说一下你的思路
- Action1:GID_C_ZCY_ITEM_EXT_INFO_TOPIC_ORDER_Production消息对接了700多万
- Action2:如何监控消息延迟和消息堆积
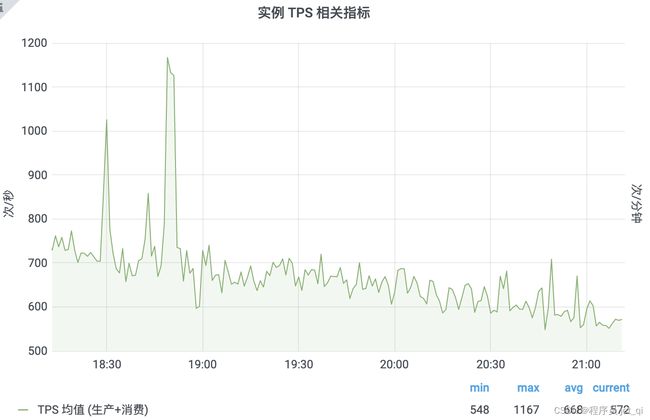
1、MQ实例详情
-
实例名称:ZMQ_INSTANCE_3
-
实例描述:承接DEFAULT_INSTANCE实例需求外溢的业务MQ需求-depart3
-
创建时间:2022年3月24日 14:50:58
-
共享TPS弹性上限 5000次/秒
-
数据统计
- 1、
- 1、
-
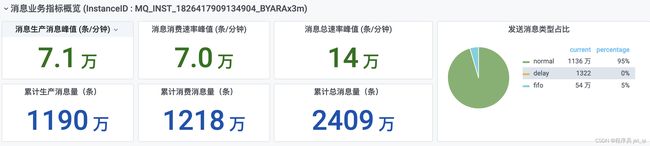
API累计调用次数
- 712万次
-
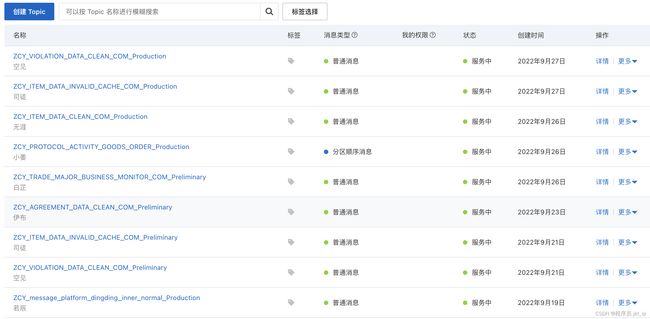
Topic如下所示
-
-
举例:
- topic名称:
ZCY_ITEM_DATA_INVALID_CACHE_COM_Production - 消息类型:普通消息
- 消费模式:广播模式
- 共8台客户端,即im 每台机器默认开启20个线程
- 广播模式不支持查询“消费统计信息”和“重试消费统计信息”
- topic名称:
2、MQ的Group管理
一个 Group ID 代表一个 Consumer 实例群组。同一个消费者 Group ID 下所有的 Consumer 实例必须保证订阅的 Topic 一致,并且也必须保证订阅 Topic 时设置的过滤规则(Tag)一致。否则您的消息可能会丢失。点击这里了解更多内容。
3、RocketMQ是如何保证消息队列的高可用? (6分)
分布式系统遵循CAP原则,即:一致性C、可用性A和分区容错性P 三者无法在分布式系统中被同时满足,并且最多只能满足其中两个,需要根据业务进行衡量取舍。不同的解决方案对各项指标的支持程度各有侧重。基于CAP原则,很难设计出一种高可用方案能同时够满足所有指标的最优值。
RocketMQ由如下几部分构成
-
1、Name Server无状态,可线性扩展,天然高可用。
-
2、生产者和消费者客户端伴随着业务集群部署
-
3、因此下面重点讨论Broker的高可用机制,以下是对RocketMQ高可用方案的调研汇总。
3.1 Master/Slave 方案
部署架构图可参考本文第二章概念介绍图,核心是broker部署的时候指定角色,通过主从复制实现,支持同步和异步两种模式。
- 同步模式见左图,异步模式见右图
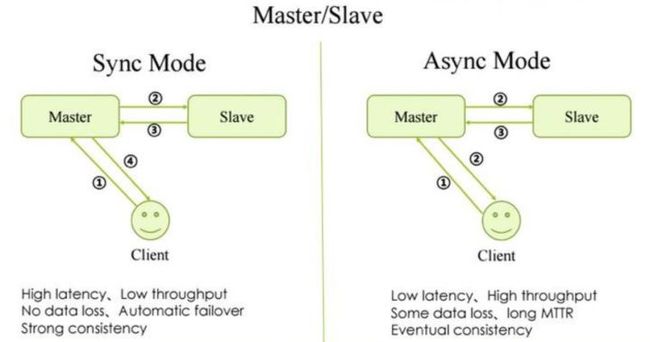
Broker目前仅支持主备复制,Master宕机不可修复。需要手动修改备的配置文件 (此时Slave是Read-Only),然后重启,不具备宕机自动failover能力
Master/Slave 复制模式分为同步和异步,用户可以根据业务场景进行trade-off,在性能和数据可靠性之间选择一个
- 采用同步模式,选择了数据可靠性
- 采用异步模式,选择了性能
RocketMQ 的Topic可以分片在不同的broker上面,一个broker挂了,生产者可以继续投递消息到其他broker,已经挂的broker上的消息必须等人工重启才能进一步处理
Action:在性能和数据可靠性之间选择一个,我们选择的性能,造成的问题
线上问题,江西环境RocketMQ消息堆积,原因是架构组MQ集群 11:00 重启,导致了消费位点回到了昨天下午3点,从而消息堆积了几百万
-
如何解决堆积
-
1、将消费位点重置到10:50,
-
存在的问题,昨天下午3点到今天11:00,存在消息重复发送
- 业务上,没有做幂等的业务都会收到影响
-
我这边排查协议续签、一键审核、协议状态变更
- 协议续签:做了幂等,无影响
- 一键审核:做了幂等,无影响
- 协议状态变更:看了数据,没啥问题,重复的都是状态为-3的数据
-
-
为啥MQ集群 11:00 重启,导致了消费位点回到了昨天下午3点?
-
怀疑是RocketMQ是AP架构,不能保证严格的一致性。
-
https://developer.aliyun.com/article/770355?spm=a2c6h.12873639.article-detail.6.64f476f2xeFvfw
-
受影响的业务(未做幂等的业务),商品上下架,今天得订一天江西的数据
-
4、消息中间件集群情况如何?
4.1、高可用整体架构
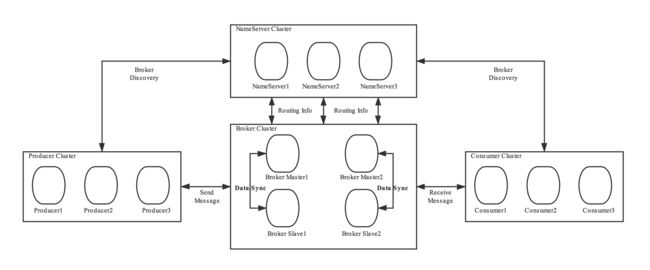
Rocketmq是通过broker主从机制来实现高可用的。相同broker名称,不同brokerid的机器组成一个broker组,brokerId=0表明这个broker是master,brokerId>0 表明这个broker是slave。
-
消息生产的高可用:创建topic时,把topic的多个message queue创建在多个broker组上。这样当一个broker组的master不可用后,producer仍然可以给其他组的master发送消息。 rocketmq目前还不支持主从切换,需要手动切换
-
消息消费的高可用:consumer并不能配置从master读还是slave读。当master不可用或者繁忙的时候,consumer会被自动切换到从slave读。这样当master出现故障后,consumer仍然可以从slave读,保证了消息消费的高可用
4.2、消息存储结构

CommitLog:存储消息的元数据
ConsumerQueue:存储消息在CommitLog的索引
IndexFile:提供了一种通过key或者时间区间来查询消息的方法
4.3、刷盘机制
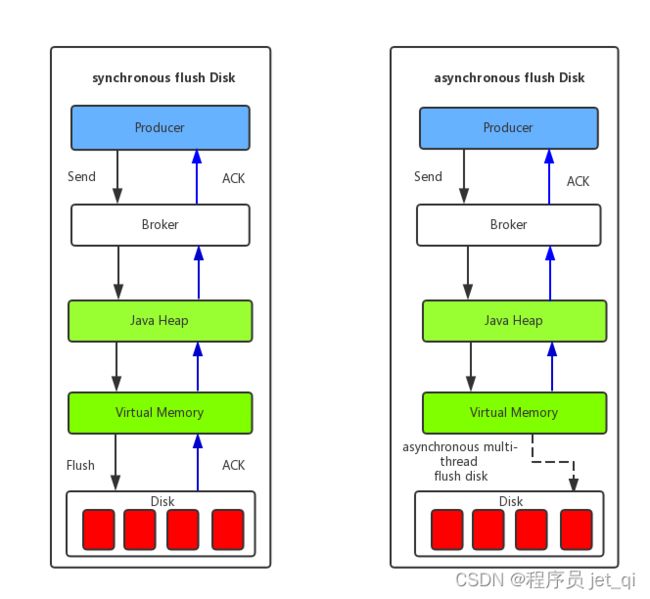
默认是同步吗?
- 同步刷盘:消息被写入内存的PAGECACHE,返回写成功状态,当内存里的消息量积累到一定程度时,统一触发写磁盘操作,快速写入 。吞吐量高,当磁盘损坏时,会丢失消息
- 异步刷盘:消息写入内存的PAGECACHE后,立刻通知刷盘线程刷盘,然后等待刷盘完成,刷盘线程执行完成后唤醒等待的线程,给应用返回消息写成功的状态。吞吐量低,但不会造成消息丢失
- 我猜测是异步的
4.4、主从复制
- 如果一个broker有master和slave时,就需要将master上的消息复制到slave上,复制的方式有两种
- 同步复制:master和slave均写成功,才返回客户端成功。maste挂了以后可以保证数据不丢失,但是同步复制会增加数据写入延迟,降低吞吐量
- 异步复制:master写成功,返回客户端成功。拥有较低的延迟和较高的吞吐量,但是当master出现故障后,有可能造成数据丢失
- 是同步还是异步呢?
- mysql是异步、redis是异步,我猜测:rocketMQ也是异步的
4.5、负载均衡
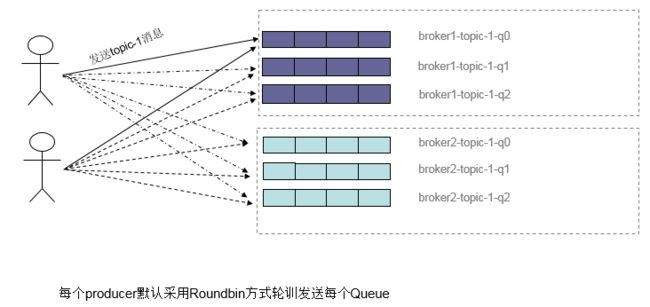
1、Producer负载均衡
- producer在发送消息时,默认轮询所有queue,消息就会被发送到不同的queue上。而queue可以分布在不同的broker上
2、Consumer负载均衡
-
默认的分配算法是AllocateMessageQueueAveragely,如下图
-
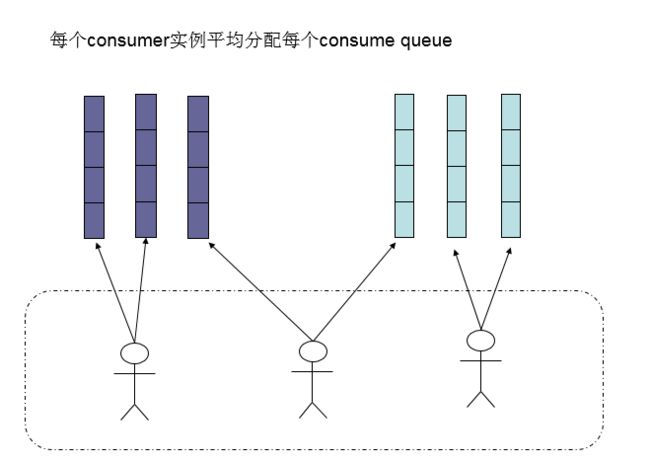
-
还有另外一种平均的算法是 AllocateMessageQueueAveragelyByCircle,也是平均分摊每一条queue,只是以环状轮流分queue的形式,如下图:
-
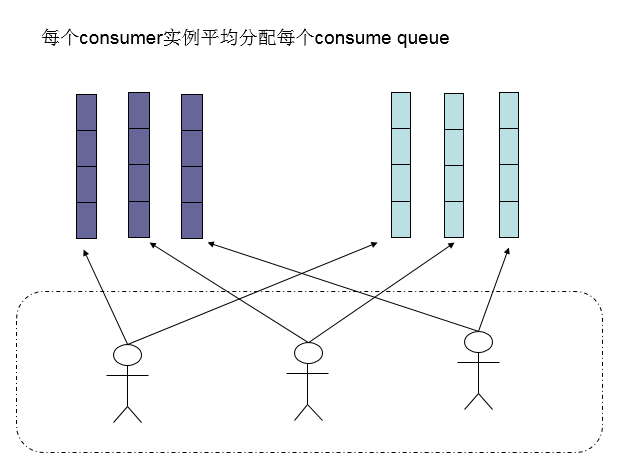
如果consumer数量比message queue还多,则多会来的consumer会被闲置。所以不要让consumer的数量多于message queue的数量
4.6、消息重试和死信队列
1、发送端重试
- producer向broker发送消息后,没有收到broker的ack时,rocketmq会自动重试。重试的最大次数和发送超时时间都可以设置。如设置producer3秒内没有发送成功,则重试,重试的最大次数为3
2、消费端重试
顺序消息的重试
- 对于顺序消息,当Consumer消费消息失败后,RocketMQ会不断进行消息重试,此时后续消息会被阻塞。所以当使用顺序消息的时候,监控一定要做好,避免后续消息被阻塞
无序消息的重试
-
当消费模式为集群模式时,Broker才会自动进行重试,对于广播消息是不会进行重试的
-
当consumer消费消息后返回 ConsumeConcurrentlyStatus.CONSUME_SUCCESS表明消费消息成功,不会进行重试
-
当consumer符合如下三种场景之一时,会对消息进行重试
- 1、返回ConsumeConcurrentlyStatus.RECONSUME_LATER
- 2、返回null
- 3、抛出抛出异常
-
RocketMQ默认每条消息会被重试16次,超过16次则不再重试,会将消息放到死信队列,
每次重试的时间间隔如下

4.7、重试队列和死信队列
当消息消费失败,会被发送到重试队列
当消息消费失败,并达到最大重试次数,rocketmq并不会将消息丢弃,而是将消息发送到死信队列
死信队列有如下特点
- 1、里面存的是不能被正常消费的消息
- 2、有效期与正常消息相同,都是3天,3天后会被删除
重试队列的命名为 %RETRY%消费组名称 死信队列的命名为 %DLQ%消费组名称
一个死信队列包含了一个group id产生的所有消息,不管当前消息处于哪个topic。重试队列和死信队列只有在需要的时候才会被创建出来
5、部署方式
Apache RocketMQ 5.0 版本完成基本消息收发,包括 NameServer、Broker、Proxy 组件。 在 5.0 版本中 Proxy 和 Broker 根据实际诉求可以分为 Local 模式和 Cluster 模式,一般情况下如果没有特殊需求,或者遵循从早期版本平滑升级的思路,可以选用Local模式。
- 在 Local 模式下,Broker 和 Proxy 是同进程部署,只是在原有 Broker 的配置基础上新增 Proxy 的简易配置就可以运行。
- 在 Cluster 模式下,Broker 和 Proxy 分别部署,即在原有的集群基础上,额外再部署 Proxy 即可。
方案:多组节点(集群)单副本模式
一个集群内全部部署 Master 角色,不部署Slave 副本,例如2个Master或者3个Master,这种模式的优缺点如下:
- 优点:配置简单,单个Master宕机或重启维护对应用无影响,在磁盘配置为RAID10时,即使机器宕机不可恢复情况下,由于RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢),性能最高;
- 缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响。
方案1:多节点(集群)多副本模式-异步复制
每个Master配置一个Slave,有多组 Master-Slave,HA采用异步复制方式,主备有短暂消息延迟(毫秒级),这种模式的优缺点如下:
- 优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,同时Master宕机后,消费者仍然可以从Slave消费,而且此过程对应用透明,不需要人工干预,性能同多Master模式几乎一样;
- 缺点:Master宕机,磁盘损坏情况下会丢失少量消息。
方案2:多节点(集群)多副本模式-同步双写
每个Master配置一个Slave,有多对 Master-Slave,HA采用同步双写方式,即只有主备都写成功,才向应用返回成功,这种模式的优缺点如下:
- 优点:数据与服务都无单点故障,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高;
- 缺点:性能比异步复制模式略低(大约低10%左右),发送单个消息的RT会略高,且目前版本在主节点宕机后,备机不能自动切换为主机。
方案3:Cluster模式部署
在 Cluster 模式下,Broker 与 Proxy分别部署,我可以在 NameServer和 Broker都启动完成之后再部署 Proxy。
在 Cluster模式下,一个 Proxy集群和 Broker集群为一一对应的关系,可以在 Proxy的配置文件 rmq-proxy.json 中使用 rocketMQClusterName 进行配置
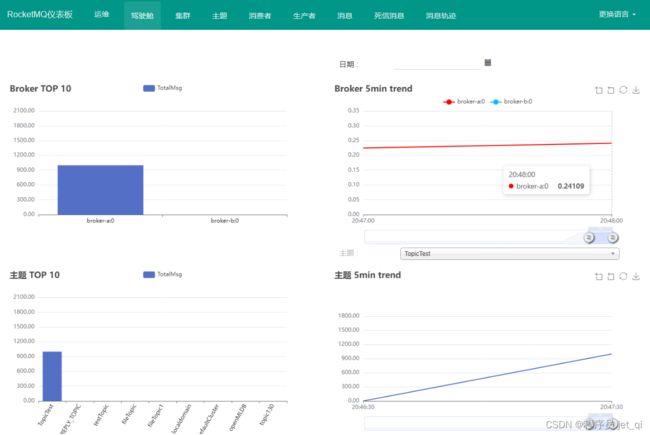
6、RocketMQ Dashboard使用教程
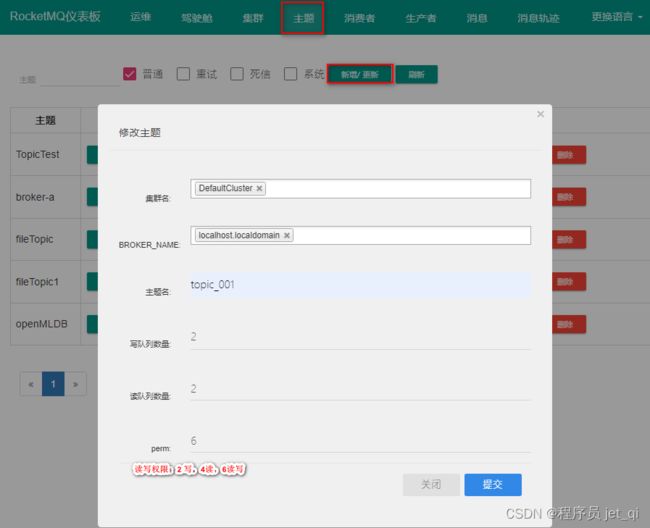
1. 创建主题 Topic
主题 > 新增/更新
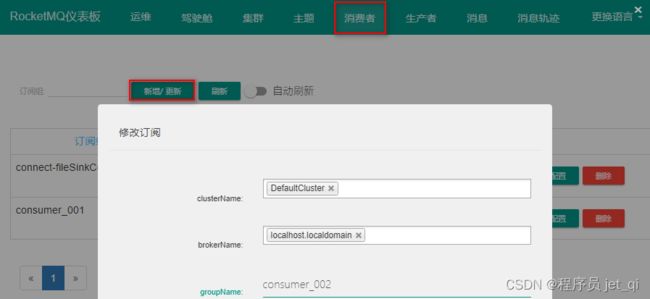
2. 创建消费者组 consumer
消费者 > 新增/更新
3. 重置消费位点
主题 > 重置消费位点
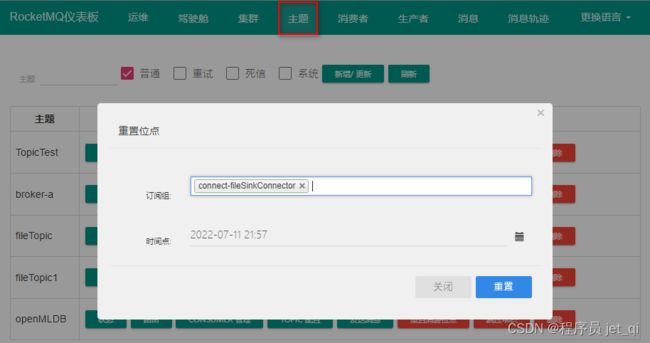
tips:
- 集群消费支持重置消费位点, 广播模式不支持.
- 消费者不在线不能重置消费位点
4. 扩容 Topic 队列
主题 > TOPIC配置

5. 扩容 Broker
-
安装部署一个新的 broker, nameserver 地址和当前集群一样
-
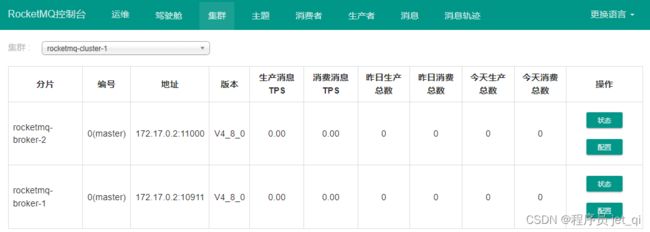
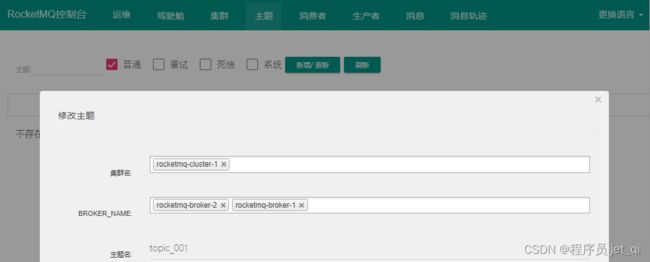
-
更新 Topic 的BROKER_NAME
主题
>新增/更新>BROKER_NAME
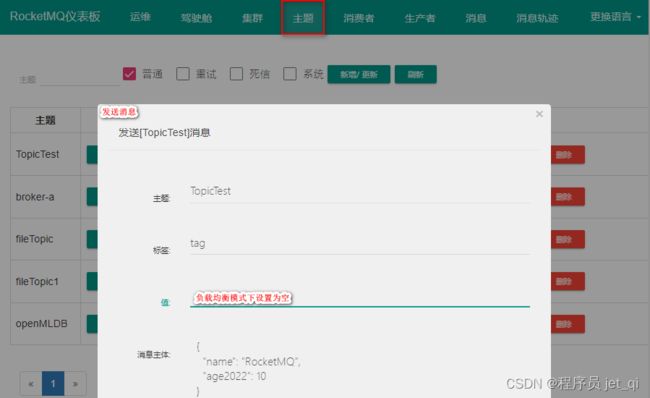
6. 发送消息
-
向指定 Topic 发送消息
主题
>发送消息 -
发送结果
-

7、RocketMQ Promethus Exporter
介绍
Rocketmq-exporter 是用于监控 RocketMQ broker 端和客户端所有相关指标的系统,通过 mqAdmin 从 broker 端获取指标值后封装成 87 个 cache。
Rocketmq-expoter 获取监控指标的流程如下图所示,Expoter 通过 MQAdminExt 向 MQ 集群请求数据,请求到的数据通过 MetricService 规范化成 Prometheus 需要的格式,然后通过 /metics 接口暴露给 Promethus。

8、基本最佳实践
8.1、Keys的使用
每个消息在业务层面一般建议映射到业务的唯一标识并设置到keys字段,方便将来定位消息丢失问题。服务器会为每个消息创建索引(哈希索引),应用可以通过topic、key来查询这条消息内容,以及消息被谁消费。由于是哈希索引,请务必保证key尽可能唯一,这样可以避免潜在的哈希冲突。常见的设置策略使用订单Id、用户Id、请求Id等比较离散的唯一标识来处理。
8.2、日志的打印
消息发送成功或者失败要打印消息日志,用于业务排查问题。Send消息方法只要不抛异常,就代表发送成功
8.3、消息发送失败处理方式
Producer的send方法本身支持内部重试,5.x SDK的重试逻辑参考发送重试策略:
以上策略也是在一定程度上保证了消息可以发送成功。如果业务要求消息发送不能丢,仍然需要对可能出现的异常做兜底,比如调用send同步方法发送失败时,则尝试将消息存储到db,然后由后台线程定时重试,确保消息一定到达Broker。
上述DB重试方式为什么没有集成到MQ客户端内部做,而是要求应用自己去完成,主要基于以下几点考虑:
- 首先,MQ的客户端设计为无状态模式,方便任意的水平扩展,且对机器资源的消耗仅仅是cpu、内存、网络。
- 其次,如果MQ客户端内部集成一个KV存储模块,那么数据只有同步落盘才能较可靠,而同步落盘本身性能开销较大,所以通常会采用异步落盘,又由于应用关闭过程不受MQ运维人员控制,可能经常会发生 kill -9 这样暴力方式关闭,造成数据没有及时落盘而丢失。
- 第三,Producer所在机器的可靠性较低,一般为虚拟机,不适合存储重要数据。综上,建议重试过程交由应用来控制。
消费者
8.4、消费过程幂等
RocketMQ 无法避免消息重复(Exactly-Once),所以如果业务对消费重复非常敏感,务必要在业务层面进行去重处理。可以借助关系数据库进行去重(主键id)。首先需要确定消息的唯一键,可以是msgId,也可以是消息内容中的唯一标识字段,例如订单Id等。在消费之前判断唯一键是否在关系数据库中存在。如果不存在则插入,并消费,否则跳过。(实际过程要考虑原子性问题,判断是否存在可以尝试插入,如果报主键冲突,则插入失败,直接跳过)
msgId一定是全局唯一标识符,但是实际使用中,可能会存在相同的消息有两个不同msgId的情况(消费者主动重发、因客户端重投机制导致的重复等),这种情况就需要使业务字段进行重复消费。
消费速度慢的处理方式
8.5、提高消费并行度
绝大部分消息消费行为都属于 IO 密集型,即可能是操作数据库,或者调用 RPC,这类消费行为的消费速度在于后端数据库或者外系统的吞吐量,通过增加消费并行度,可以提高总的消费吞吐量,但是并行度增加到一定程度,反而会下降。所以,应用必须要设置合理的并行度。 如下有几种修改消费并行度的方法:
- 同一个 ConsumerGroup 下,通过增加 Consumer 实例数量来提高并行度。可以通过加机器,或者在已有机器启动多个进程的方式。
- 提高单个 Consumer 的消费并行线程,5.x PushConsumer SDK 可以通过
PushConsumerBuilder.setConsumptionThreadCount()设置线程数,SimpleConsumer可以由业务线程自由增加并发,底层线程安全;历史版本SDK PushConsumer可以通过修改参数 consumeThreadMin、consumeThreadMax实现。 - 线程数默认为20
8.6、批量方式消费
某些业务流程如果支持批量方式消费,则可以很大程度上提高消费吞吐量,例如订单扣款类应用,一次处理一个订单耗时 1 s,一次处理 10 个订单可能也只耗时 2 s,这样即可大幅度提高消费的吞吐量。建议使用5.x SDK的SimpleConsumer,每次接口调用设置批次大小,一次性拉取消费多条消息。
重置位点跳过非重要消息
发生消息堆积时,如果消费速度一直追不上发送速度,如果业务对数据要求不高的话,可以选择丢弃不重要的消息。建议使用重置位点功能直接调整消费位点到指定时刻或者指定位置。
优化每条消息消费过程
举例如下,某条消息的消费过程如下:
- 根据消息从 DB 查询【数据 1】
- 根据消息从 DB 查询【数据 2】
- 复杂的业务计算
- 向 DB 插入【数据 3】
- 向 DB 插入【数据 4】
这条消息的消费过程中有4次与 DB的 交互,如果按照每次 5ms 计算,那么总共耗时 20ms,假设业务计算耗时 5ms,那么总过耗时 25ms,所以如果能把 4 次 DB 交互优化为 2 次,那么总耗时就可以优化到 15ms,即总体性能提高了 40%。所以应用如果对时延敏感的话,可以把DB部署在SSD硬盘,相比于SCSI磁盘,前者的RT会小很多。
消费打印日志
如果消息量较少,建议在消费入口方法打印消息,消费耗时等,方便后续排查问题。 商品中心就是这样实践的
new MessageListener() {
@Override
public ConsumeResult consume(MessageView messageView) {
LOGGER.info("Consume message={}", messageView);
//Do your consume process
return ConsumeResult.SUCCESS;
}
}
如果能打印每条消息消费耗时,那么在排查消费慢等线上问题时,会更方便。但如果线上环境TPS很高,不建议开启,避免日志太多影响性能。
Broker
Broker 角色
Broker 角色分为 ASYNC_MASTER(异步主机)、SYNC_MASTER(同步主机)以及SLAVE(从机)。如果对消息的可靠性要求比较严格,可以采用 SYNC_MASTER加SLAVE的部署方式。如果对消息可靠性要求不高,可以采用ASYNC_MASTER加SLAVE的部署方式。如果只是测试方便,则可以选择仅ASYNC_MASTER或仅SYNC_MASTER的部署方式。
FlushDiskType
SYNC_FLUSH(同步刷新)相比于ASYNC_FLUSH(异步处理)会损失很多性能,但是也更可靠,所以需要根据实际的业务场景做好权衡。
- 商品中心采用的什么方式呢?
Broker 配置
| 参数名 | 默认值 | 说明 |
|---|---|---|
| listenPort | 10911 | 接受客户端连接的监听端口 |
| namesrvAddr | null | nameServer 地址 |
| brokerIP1 | 网卡的 InetAddress | 当前 broker 监听的 IP |
| brokerIP2 | 跟 brokerIP1 一样 | 存在主从 broker 时,如果在 broker 主节点上配置了 brokerIP2 属性,broker 从节点会连接主节点配置的 brokerIP2 进行同步 |
| brokerName | null | broker 的名称 |
| brokerClusterName | DefaultCluster | 本 broker 所属的 Cluser 名称 |
| brokerId | 0 | broker id, 0 表示 master, 其他的正整数表示 slave |
| storePathCommitLog | $HOME/store/commitlog/ | 存储 commit log 的路径 |
| storePathConsumerQueue | $HOME/store/consumequeue/ | 存储 consume queue 的路径 |
| mapedFileSizeCommitLog | 1024 1024 1024(1G) | commit log 的映射文件大小 |
| deleteWhen | 04 | 在每天的什么时间删除已经超过文件保留时间的 commit log |
| fileReserverdTime | 72 | 以小时计算的文件保留时间 |
| brokerRole | ASYNC_MASTER | SYNC_MASTER/ASYNC_MASTER/SLAVE |
| flushDiskType | ASYNC_FLUSH | SYNC_FLUSH/ASYNC_FLUSH SYNC_FLUSH 模式下的 broker 保证在收到确认生产者之前将消息刷盘。ASYNC_FLUSH 模式下的 broker 则利用刷盘一组消息的模式,可以取得更好的性能。 |
9、如果让你写一个消息队列,该如何进行架构设计啊?说一下你的思路
面试官心理分析
其实聊到这个问题,一般面试官要考察两块:
(1)你有没有对某一个消息队列做过较为深入的原理的了解,或者从整体了解把握住一个mq的架构原理
(2)看看你的设计能力,给你一个常见的系统,就是消息队列系统,看看你能不能从全局把握一下整体架构设计,给出一些关键点出来
说实话,我一般面类似问题的时候,大部分人基本都会蒙,因为平时从来没有思考过类似的问题,大多数人就是平时埋头用,从来不去思考背后的一些东西。类似的问题,我经常问的还有,如果让你来设计一个spring框架你会怎么做?如果让你来设计一个dubbo框架你会怎么做?如果让你来设计一个mybatis框架你会怎么做?
面试题剖析
其实回答这类问题,说白了,起码不求你看过那技术的源码,起码你大概知道那个技术的基本原理,核心组成部分,基本架构构成,然后参照一些开源的技术把一个系统设计出来的思路说一下就好
比如说这个消息队列系统,我们来从以下几个角度来考虑一下
(1)首先这个mq得支持可伸缩性吧,就是需要的时候快速扩容,就可以增加吞吐量和容量,那怎么搞?设计个分布式的系统呗,参照一下 kafka的设计理念,broker -> topic -> partition,每个partition放一个机器,就存一部分数据。如果现在资源不够了,简单啊,给topic 增加 partition,然后做数据迁移,增加机器,不就可以存放更多数据,提供更高的吞吐量了?
(2)**其次你得考虑一下这个mq的数据要不要落地磁盘吧?**那肯定要了,落磁盘,才能保证别进程挂了数据就丢了。那落磁盘的时候怎么落啊?顺序写,这样就没有磁盘随机读写的寻址开销,磁盘顺序读写的性能是很高的,这就是kafka的思路。
(3)**其次你考虑一下你的mq的可用性啊?**这个事儿,具体参考我们之前可用性那个环节讲解的kafka的高可用保障机制。多副本 -> leader & follower -> broker挂了重新选举leader即可对外服务。
(4)能不能支持数据0丢失啊?可以的,参考我们之前说的那个kafka数据零丢失方案
其实一个mq肯定是很复杂的,面试官问你这个问题,其实是个开放题,他就是看看你有没有从架构角度整体构思和设计的思维以及能力。确实这个问题可以刷掉一大批人,因为大部分人平时不思考这些东西。
Action1:GID_C_ZCY_ITEM_EXT_INFO_TOPIC_ORDER_Production消息对接了700多万
- 背景:消费模式,集群模式
- 不同的消费模式适用于不同的场景。当使用集群消费模式时,消息队列 RocketMQ 版认为任意一条消息只需要被集群内的任意一个消费者处理即可。当使用广播消费模式时,消息队列 RocketMQ 版会将每条消息推送给集群内所有注册过的消费者,保证消息至少被每个消费者消费一次。点击这里了解更多信息。
- 原因:
- 解决方案:
Action2:如何监控消息延迟和消息堆积
- 方法1:可以在阿里云rocketMQ工作台看到堆积情况
- 然后可以重置消费位点之类的炒作
- 方法2:使用公司内部提供的工具 RocketMQ Dashboard
RocketMQ Dashboard是 RocketMQ 的管控利器,为用户提供客户端和应用程序的各种事件、性能的统计信息,支持以可视化工具代替 Topic 配置、Broker 管理等命令行操作。