一次采集无需特定目标的LiDAR-相机外参自动化标定工具箱
文章:General, Single-shot, Target-less, and Automatic LiDAR-Camera Extrinsic Calibration Toolbox
作者:Kenji Koide, Shuji Oishi, Masashi Yokozuka, and Atsuhiko Banno
编辑:点云PCL
代码:https://github.com/koide3/direct_visual_lidar_calibration.git
欢迎各位加入知识星球,获取PDF论文,欢迎转发朋友圈。文章仅做学术分享,如有侵权联系删文。
公众号致力于点云处理,SLAM,三维视觉,高精地图等领域相关内容的干货分享,欢迎各位加入,有兴趣的可联系[email protected]。未经作者允许请勿转载,欢迎各位同学积极分享和交流。
摘要
本文介绍了一个开源的LiDAR-相机标定工具箱,适用于通用的LiDAR和相机投影模型,只需要一对LiDAR和相机数据而无需标定目标物,并且完全自动化。对于自动的初始估计,我们采用SuperGlue图像匹配流程,在LiDAR和相机数据之间找到2D-3D对应关系,并通过RANSAC估计LiDAR-相机的变换关系。在得到初始估计后通过基于归一化信息距离的直接LiDAR-相机配准来进一步优化变换估计,该距离度量基于互信息。为了方便的标定过程,我们还提供了几种辅助功能(例如动态LiDAR数据集成和手动进行2D-3D对应的用户界面)。实验结果表明,所提出的工具箱可以标定旋转和非重复扫描的任意组合LiDAR和针孔相机以及全景相机,并且展示出比基于边缘对齐的标定方法更好的标定精度和稳健性。
主要贡献
LiDAR-相机外参标定是估计LiDAR和相机之间坐标系变换的任务。它对于LiDAR-相机传感器融合是必需的,并且在许多应用中都是必要的,包括自动驾驶车辆定位、环境建图和周围物体识别。尽管在过去的十年中对LiDAR-相机标定进行了积极的研究,但机器人学界仍然缺乏一个方便和完整的LiDAR-相机标定工具箱。现有的LiDAR-相机标定框架要么需要准备难以创建的标定目标物,要么需要拍摄大量的LiDAR-相机数据以耗费大量的精力,要么需要精心选择一个具有丰富几何结构的环境。此外,它们很少支持各种LiDAR和相机投影模型,如旋转和非重复扫描LiDAR以及超宽视场和全向相机,我们认为缺乏易于使用的LiDAR-相机标定方法一直以来都是LiDAR-相机传感器融合系统发展的障碍。本文的主要贡献如下:
提出了一种基于2D-3D对应估计的鲁棒初始猜测估计算法,为了利用最近基于图神经网络的图像匹配方法,我们使用虚拟相机生成LiDAR强度图像,并在LiDAR强度图像和相机图像之间找到对应点,通过RANSAC和重投影误差最小化,得到LiDAR-相机变换的估计值。
为了实现鲁棒和准确的标定,将基于归一化信息距离(NID)的直接LiDAR-相机精细配准算法与基于视点的隐藏点剔除算法相结合,过滤掉在相机视点下被遮挡并且不应该可见的点。
整个系统经过精心设计,具有对LiDAR和相机投影模型的通用性,可以应用于各种传感器模型。
我们将开发的方法代码作为开源发布,以造福社区。
图1:本文提出了一个完整的LiDAR-相机标定框架,可以处理各种LiDAR和相机模型,并通过仅使用一对LiDAR点云和相机图像来进行它们之间的变换关系计算。像素级的直接对齐算法实现了高质量的LiDAR-相机数据融合。
主要内容
A. 概述
图2显示了所提出的LiDAR-相机标定工具箱的概述, 为了处理具有统一处理流程的各种LiDAR模型,首先通过合并多个LiDAR帧创建一个稠密点云,对于非重复扫描LiDAR(如Livox Avia),我们简单地累积点以增加点云的密度,对于旋转式LiDAR(如Velodyne和Ouster LiDAR),使用基于连续时间ICP的动态LiDAR点配准技术。从配对的稠密点云和相机图像中,根据使用SuperGlue [4]估计的2D-3D对应关系获得LiDAR-相机变换的粗略估计。我们还提供了直观的用户界面,用于手动创建可容忍错误的对应关系,在给定2D-3D对应关系的情况下,我们执行RANSAC和重投影误差最小化,获得LiDAR-相机变换的初始估计值。在获得LiDAR-camera初始估计的基础上,使用基于视角的隐藏点去除方法,去除在相机视角下不可见的LiDAR点云,然后通过基于NID(归一化信息距离)最小化的精细LiDAR-camera配准,进一步优化LiDAR-camera的变换估计。
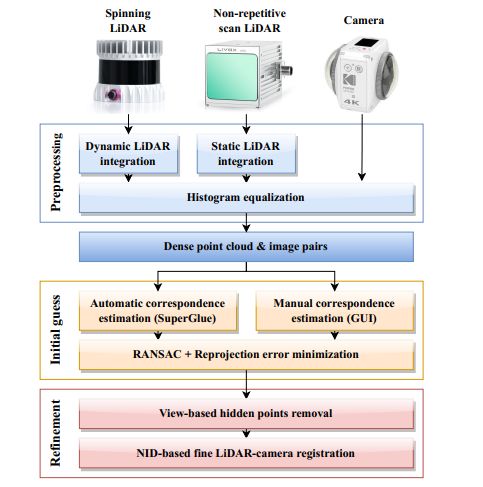
图2:所提出的LiDAR-相机标定过程的概述。输入点云使用静态和动态LiDAR合并以创建密集点云,给定稠密点云和相机图像,使用SuperGlue流程找到2D-3D对应关系,还提供一个易于使用的手动对应关系估计工具,根据2D-3D对应关系,通过RANSAC和重投影误差最小化获得LiDAR-相机变换的粗略估计,最后基于NID最小化进行精细的LiDAR-相机配准。
B. 预处理
旋转式LiDAR呈现出稀疏且重复的扫描模式,仅通过单个扫描提取有意义的几何和纹理信息非常困难(参见图3(a))。对于这样的LiDAR,将LiDAR在垂直方向上移动几秒钟,并在补偿视角变化和点云畸变的同时累积点云。为了估计LiDAR的运动,使用CT-ICP算法,该算法通过最小化当前LiDAR扫描与具有插值LiDAR姿态的模型点云之间的距离,联合优化扫描开始和结束时的LiDAR姿态。为了高效地从过去的观测中创建目标点云,我们使用线性iVox结构,该结构简单地将点保留在每个体素的线性容器中。基于估计的LiDAR扫描开始和结束姿态,校正输入点云上的运动畸变,并通过将所有点在第一个扫描的坐标系中累积来创建稠密点云。图3(b)展示了应用动态LiDAR点积分过程后的稠密点云。可以看到稠密点云展现出了在单次扫描点云中难以观察到的丰富几何和纹理信息, 对于具有非重复扫描机制的LiDAR,我们只需将所有扫描积累到一个帧中,得到稠密点云,如图1(b)所示。对于稠密点云和相机图像,我们应用直方图均衡化,因为在精细配准步骤中使用的NID度量在具有均匀强度分布时效果最佳。
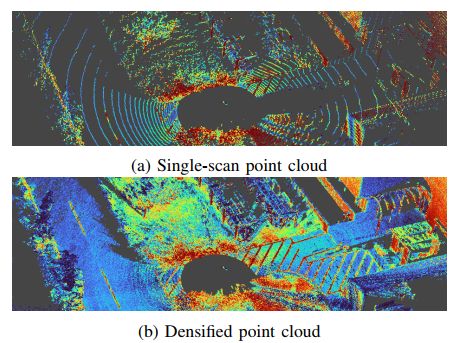
图3:旋转式LiDAR的点云稠密化,LiDAR积分使得从几秒钟的动态LiDAR数据中创建稠密点云成为可能,稠密化后的点云展示了丰富的几何和表面纹理信息。
C. 初始估计
为了获得LiDAR-camera转换的初步估计,首先在输入图像和点云之间获得2D-3D对应关系,然后通过RANSAC和重投影误差最小化来估计LiDAR-camera转换。为了利用基于图神经网络的图像匹配流程,使用虚拟相机模型从稠密点云生成LiDAR强度图像。为了选择最佳的投影模型来渲染整个点云,首先估计LiDAR的视场角(FoV)。使用快速凸壳算法提取输入点云的凸包,然后通过蛮力搜索找到凸包中具有最大角度距离的点对。如果估计的LiDAR视场角小于150°,则使用针孔投影模型创建虚拟相机,否则使用等距投影模型创建虚拟相机,通过虚拟相机将点云渲染为带有强度值的LiDAR强度图像,如图4所示。除了强度图像,我们还生成点索引图,以便在后续的姿态估计步骤中高效地查找像素级的3D坐标,请注意,虽然我们只是简单地渲染每个点而没有插值和填充间隙,但由于密集积累的点云,渲染结果呈现出良好的外观质量。

图4:使用虚拟相机渲染的LiDAR强度图像(由于空间限制,图像被裁剪)。根据LiDAR的视场角,选择针孔投影模型或等距投影模型。
为了在LiDAR和相机强度图像之间找到对应关系,使用SuperGlue流程。首先使用SuperPoint在图像上检测关键点,然后使用图神经网络找到关键点之间的对应关系,本文使用了在MegaDepth数据集上预训练的权重,虽然SuperGlue能够在不同模态的图像之间找到对应关系,但我们发现匹配阈值需要设置为非常小的值(例如0.05)才能获得足够数量的对应关系,然而,使用这个设置时会产生许多错误的对应关系,如图5所示。

图5:SuperGlue能够在不同模态的LiDAR和相机图像之间找到对应关系,且具有非常低的敏感匹配阈值设置。然而,结果中包含许多需要在姿态估计之前进行滤除的错误对应关系(绿色:内点,红色:外点)。
D. 基于NID的直接LiDAR-相机配准
由于视点差异,LiDAR点云中的某些点可能被遮挡,无法从相机中看到,如果我们简单地投影所有的LiDAR点云,这些点可能会造成错误的对应关系,并影响校准结果。为了避免这个问题,采用了高效的基于视图的隐藏点去除方法,过滤掉相机视角下不可见的LiDAR点,根据当前的LiDAR-相机变换估计,在图像中投影LiDAR点云,并仅保留每个像素的最小距离点。通过从保留仅相机可见点的投影图像中获取的3D点云,然后进行精细配准。
实验与分析
使用图6中展示的旋转和非重复扫描LiDAR(Ouster OS1-64和Livox Avia)以及针孔和全景相机(Omron Sentech STC-MBS202POE和Kodak PixPro 4KVR360)的四种组合来评估所提出的校准工具箱。对于每种组合,我们在室内和室外环境中记录了15对LiDAR点云和相机图像,并针对每对运行了所提出的校准过程(即单次校准)。作为参考,使用高精度反射球靶标估计了LiDAR-相机变换,如图7所示。我们手动标注了目标的2D和3D位置,以找到最小化目标重投影误差的LiDAR-相机变换,通过视觉检查确认估计的变换密切描述了相机的投影,我们将估计的变换用作“伪”真值。

图6: LiDAR-camera标定实验的传感器配置。

图7,使用高反射率球形目标测量的参考LiDAR-相机变换;目标的2D和3D位置进行了手动注释,并通过最小化其重投影误差来估计变换。
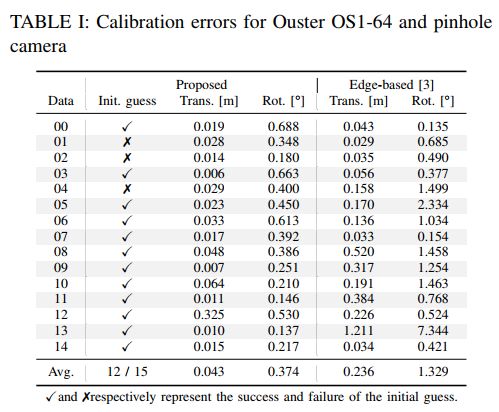
表格I总结了Ouster LiDAR和针孔相机组合的校准结果,所提出的算法对于15个数据对中的12个提供了合理的初始猜测,所提出的精细配准算法对所有数据都表现良好,并平均实现了0.043米和0.374°的校准误差。
如表格II所示,对于Livox LiDAR和针孔相机的组合,初始猜测估计为所有数据配对成功提供了良好的初始LiDAR-相机变换,而精细配准算法实现了平均校准误差为0.069米和0.724°,这比基于边缘的校准(0.323米和3.497°)要好。
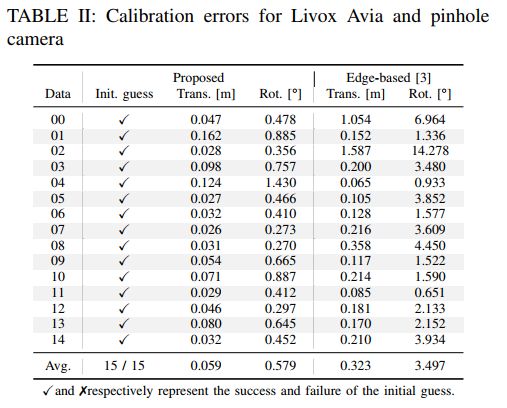
表格III总结了全景相机的校准结果,尽管对于Ouster LiDAR,全景相机显示出良好的初始猜测成功率和低校准误差,但对于Livox LiDAR和全景相机的组合,初始猜测估计和精细LiDAR-相机配准的效果都有所降低。这是因为由于LiDAR和相机的视场(FoV)差异非常大,只使用了全景相机图像的一小部分进行校准,并且图像的分辨率不足以表示有限的FoV下的精细环境细节,我们认为通过使用更高分辨率或多个图像可以提高校准精度。
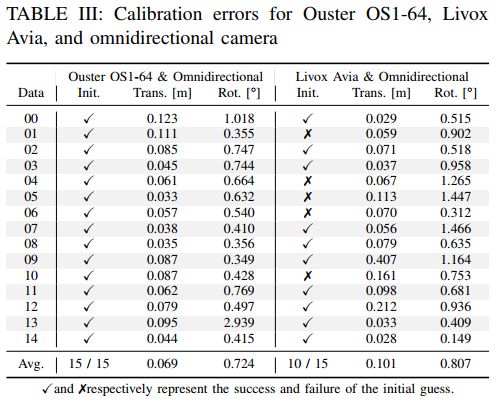
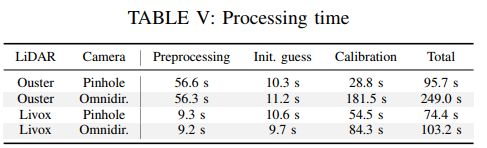
表格V显示了每个标定步骤的处理时间,根据LiDAR和相机模型的组合,从15个数据对中校准LiDAR相机转换所需的时间介于74到249秒之间,虽然Ouster LiDAR和全景相机的组合需要更长的时间,因为这两个传感器都具有360°的视场,并且需要投影大部分点云,但我们认为这在离线标定中是合理的水平。
总结
我们开发了一个通用的LiDAR-相机校准工具箱,对于完全自动的标定过程,使用基于图像匹配的初始估计方法,然后,通过基于NID的直接LiDAR-相机配准算法对初始估计进行了优化,实验结果表明,该工具箱能够准确地校准旋转和非重复扫描LiDAR以及针孔和全景相机之间的外参。
更多详细内容后台发送“知识星球”加入知识星球查看更多。
资源
自动驾驶及定位相关分享
【点云论文速读】基于激光雷达的里程计及3D点云地图中的定位方法
自动驾驶中基于光流的运动物体检测
基于语义分割的相机外参标定
综述:用于自动驾驶的全景鱼眼相机的理论模型和感知介绍
高速场景下自动驾驶车辆定位方法综述
Patchwork++:基于点云的快速、稳健的地面分割方法
PaGO-LOAM:基于地面优化的激光雷达里程计
多模态路沿检测与滤波方法
多个激光雷达同时校准、定位和建图的框架
动态的城市环境中杆状物的提取建图与长期定位
非重复型扫描激光雷达的运动畸变矫正
快速紧耦合的稀疏直接雷达-惯性-视觉里程计
基于相机和低分辨率激光雷达的三维车辆检测
用于三维点云语义分割的标注工具和城市数据集
ROS2入门之基本介绍
固态激光雷达和相机系统的自动标定
激光雷达+GPS+IMU+轮速计的传感器融合定位方案
基于稀疏语义视觉特征的道路场景的建图与定位
自动驾驶中基于激光雷达的车辆道路和人行道实时检测(代码开源)
用于三维点云语义分割的标注工具和城市数据集
更多文章可查看:点云学习历史文章大汇总
SLAM及AR相关分享
TOF相机原理介绍
TOF飞行时间深度相机介绍
结构化PLP-SLAM:单目、RGB-D和双目相机使用点线面的高效稀疏建图与定位方案
开源又优化的F-LOAM方案:基于优化的SC-F-LOAM
【开源方案共享】ORB-SLAM3开源啦!
【论文速读】AVP-SLAM:自动泊车系统中的语义SLAM
【点云论文速读】StructSLAM:结构化线特征SLAM
SLAM和AR综述
常用的3D深度相机
AR设备单目视觉惯导SLAM算法综述与评价
SLAM综述(4)激光与视觉融合SLAM
Kimera实时重建的语义SLAM系统
SLAM综述(3)-视觉与惯导,视觉与深度学习SLAM
易扩展的SLAM框架-OpenVSLAM
高翔:非结构化道路激光SLAM中的挑战
基于鱼眼相机的SLAM方法介绍
3D视觉与点云学习星球:主要针对智能驾驶全栈相关技术,3D/2D视觉技术学习分享的知识星球,将持续进行干货技术分享,知识点总结,代码解惑,最新paper分享,解疑答惑等等。星球邀请各个领域有持续分享能力的大佬加入我们,对入门者进行技术指导,对提问者知无不答。同时,星球将联合各知名企业发布自动驾驶,机器视觉等相关招聘信息和内推机会,创造一个在学习和就业上能够相互分享,互帮互助的技术人才聚集群。
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除

扫描二维码
关注我们
让我们一起分享一起学习吧!期待有想法,乐于分享的小伙伴加入知识星球注入爱分享的新鲜活力。分享的主题包含但不限于三维视觉,点云,高精地图,自动驾驶,以及机器人等相关的领域。
分享与合作方式:微信“cloudpoint9527”(备注:姓名+学校/公司+研究方向) 联系邮箱:[email protected]。
为分享的伙伴们点赞吧!
