深入理解Linux虚拟内存管理(二)

系列文章目录
Linux 内核设计与实现
深入理解 Linux 内核(一)
深入理解 Linux 内核(二)
Linux 设备驱动程序(一)
Linux 设备驱动程序(二)
Linux 设备驱动程序(三)
Linux设备驱动开发详解
深入理解Linux虚拟内存管理(一)
深入理解Linux虚拟内存管理(二)
深入理解Linux虚拟内存管理(三)
文章目录
- 系列文章目录
- 第8章 slab分配器
-
- 8.1 高速缓存
-
- 8.1.1 高速缓存描述符
- 8.1.2 高速缓存静态标志位
- 8.1.3 高速缓存动态标志位
- 8.1.4 高速缓存分配标志位
- 8.1.5 高速缓存着色
- 8.1.6 创建高速缓存
- 8.1.7 回收高速缓存
- 8.1.8 收缩高速缓存
- 8.1.9 销毁高速缓存
- 8.2 slabs
-
- 8.2.1 存储 slab 描述符
- 8.2.2 创建 slab
- 8.2.3 跟踪空闲对象
- 8.2.4 初始化 kmem_bufctl_t 数组
- 8.2.5 查找下一个空闲对象
- 8.2.6 更新 kmem_bufctl_t
- 8.2.7 计算 slab 中对象的数量
- 8.2.8 销毁 slab
- 8.3 对 象
-
- 8.3.1 初始化 slab 中的对象
- 8.3.2 分配对象
- 8.3.3 释放对象
- 8.4 指定大小的高速缓存
-
- 8.4.1 kmalloc()
- 8.4.2 kfree()
- 8.5 per-CPU 对象高速缓存
-
- 8.5.1 描述 per-CPU 对象高速缓存
- 8.5.2 在 per~CPU 高速缓存中添加/移除对象
- 8.5.3 启用 per-CPU 高速缓存
- 8.5.4 更新 per-CPU 高速缓存的信息
- 8.5.5 清理 per~CPU 高速缓存
- 8.6 初始化 slab 分配器
- 8.7 伙伴分配器接口
- 8.8 2.6 中有哪些新特性
-
- 高速缓存描述符
- 高速缓存静态标志位
- 回收高速缓存
- 其他的改变
- 第9章 高端内存管理
-
- 9.1 管理 PKMap 地址空间
- 9.2 映射高端内存页面
- 9.3 解除页面映射
- 9.4 原子性的映射高端内存页面
- 9.5 弹性缓冲区
-
- 9.5.1 磁盘缓冲
- 9.5.2 创建弹性缓冲区
- 9.5.3 通过弹性缓冲区复制数据
- 9.6 紧急池
- 9.7 2.6 中有哪些新特性
-
- 内存池
- 映射高端内存页面
- 进行 I/O
- 第10章 页面帧回收
-
- 10.1 页面替换策略
- 10.2 页面高速缓存
-
- 10.2.1 页面高速缓存哈希表
- 10.2.2 索引节点队列
- 10.2.3 向页面高速缓存添加页面
- 10.3 LRU 链表
-
- 10.3.1 重新填充 inactive_list
- 10.3.2 从 LRU 链表回收页面
- 10.4 收缩所有的高速缓存
- 10.5 换出进程页面
- 10.6 页面换出守护程序(kswapd)
- 10.7 2.6 中有哪些新特性
-
- 守护进程 kswapd
- 平衡管理区
- 页面换出压力
- 控制 LRU 链表
- 第11章 交换管理
-
- 11.1 描述交换区
- 11.2 映射页表项到交换项
- 11.3 分配一个交换槽
- 11.4 交换区高速缓存
- 11.5 从后援存储器读取页面
- 11.6 向后援存储器写页面
- 11.7 读/写交换区域的块
- 11.8 激活一个交换区
- 11.9 禁止一个交换区
- 11.10 2.6 中有哪些新特性
第8章 slab分配器
这一章将介绍一种通用的分配器:slab 分配器。它与 Solaris 系统 [MM01] 上的通用内核分配器在许多方面都很相似。Linux 中 slab 的实现主要是基于 Bonwick[Bon94 ] 的第 1 篇 slab 分配器的论文,并进一步做了大量的改进,这在他最近的论文中 [BA01] 有所描述。这一章我们先对 slab 分配器做一个快速的浏览,然后描述所用到的数据结构,并深入讨论 slab 分配器的每一项功能。
slab 分配器的基本思想是:将内核中经常使用的对象放到高速缓存中,并且由系统保持为初始的可利用状态。如果没有基于对象的分配器,内核将花费更多的时间分配、初始化以及释放一个对象。slab 分配器的目的是缓存这些空闲的对象,保留基本结构,从而能够重复使用它们 [Bon94]。
slab 分配器由多个高速缓存组成,它们通过双向循环链表连接在一起,称为高速缓存链表。在 slab 分配器中,高速缓存可以管理各种不同类型的对象,如 mm_struct 或者 fs_cache,它们由 struct kmem_cache_s 管理,在后面我们将详细讨论这个结构。高速缓存链表是通过字段 next 链接在一起的。
每一个高速缓存包括若干 slab,slab 由连续的页面帧组成,它们被划分成许多小的块以存放由高速缓存所管理的数据结构和对象。不同数据结构之间的关系如图 8.1 所示。
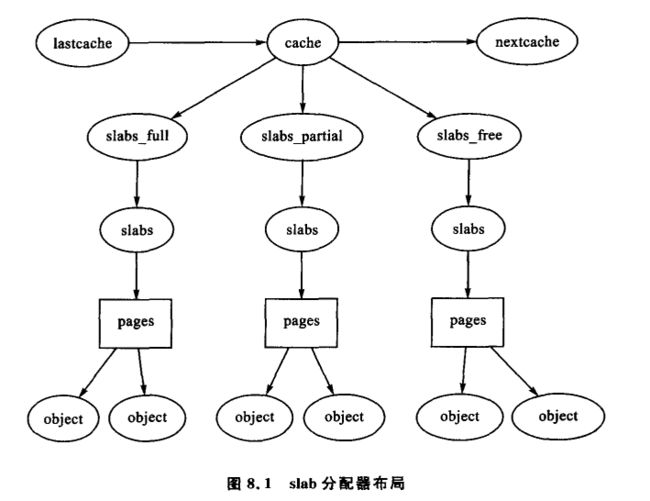
slab 分配器有三个基本目标:
- 减少伙伴系统分配小块内存时所产生的内部碎片。
- 把经常使用的对象缓存起来,减少分配、初始化以及释放对象的时间开销。在 Solaris 上的基准测试表明,使用 slab 分配器后速度有了很大的提高 [Bon94]。
- 调整对象以更好地使用 L1 和 L2 硬件高速缓存。
为减少二进制伙伴分配器所产生的内部碎片,系统需要维护两个由小内存缓冲区所构成的高速缓存集,它们的大小从 25(32) 字节到 217(131 072) 字节。一个高速缓存集适用于使用 DMA 的设备。这些高速缓存叫作 size-N 和 size-N(DMA),N 是分配器的尺寸,而函数 kmalloc()(见 8.4.1 小节)负责分配这些高速缓存。这样就解决了低级页分配器最大的问题。我们将在 8.4 节详细讨论指定大小的高速缓存。
slab 分配器的第 2 个任务是缓存经常使用的对象。初始化内核中许多数据结构所需要的时间与分配空间所花的时间相当,甚至超过了分配空间所花时间。在创建一个新的 slab 时,一些对象被存放在里面,并且由可用的构造器初始化它们。而在对象释放后,系统将保持它们为初始化时的状态,所以再次分配对象的速度很快。
slab 分配器的第 3 个任务是充分利用硬件高速缓存。若对象放入 slab 还有剩余的空间,它们就用于为 slab 着色。slab 着色方案试图让不同 slab 中的对象使用不同的硬件高速缓存行。通过将对象放置在 slab 中不同的位移起始处,对象将很可能利用 CPU 中不同的硬件高速缓存行,因此来自同一个 slab 中的对象不会彼此刷新高速缓存。这样,空间可能会因为着色而浪费掉。如图 8.2 所示,从伙伴分配器分配的页面如何存储因对齐 CPU L1 硬件高速缓存而着色的对象。
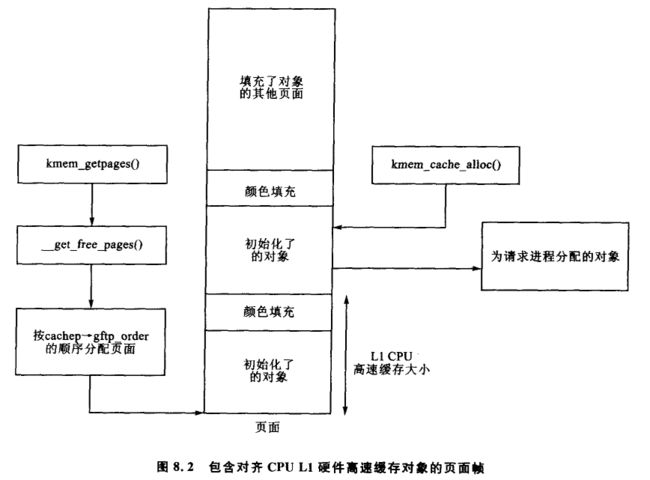
Linux 显然不会试图去给基于物理地址分配的页面帧着色 [Kes91],也不会将对象放在某一特定位置,如数据段 [GAV95]、代码段 [HK97]中,但是 slab 着色方案都可以提高硬件高速缓存行的利用率。在 8.1.5 小节中将深入讨论高速缓存着色。在 SMP 系统中,有另外的方案来利用高速缓存,即每一个高速缓存都有一个小的对象数组,而这些对象就是为每一个 CPU 所保留的。这些内容将会在 8.5 节中进一步讨论。
在编译的时候,如果设置了选项 CONFIG_SLAB_DEBUG,slab 分配器会提供额外的 slab 调试选项。其中提供的两个调试特征称为红色区域和对象感染。在红色区域中,每一个对象的末尾有一个标志位。如果这个标志位被打乱,分配器就会知道发生缓冲区溢出的对象的位置并且向系统报告。创建和释放 slab 时,感染一个对象会将预先定义好的位模(在 mm/slab.c 中定义为 0x5A)填入其中。分配时会检查这个位模,如果被改变,分配器就知道这个对象在之前已经使用过,并把它标记出来。
分配器中小而强大的 API 如表 8.1 所列。

8.1 高速缓存
8.1.1 高速缓存描述符
所有描述高速缓存的信息都存储在 mm/slab.c 中声明的 struct kmem_cache_s 中。它是一个非常大的结构,这里仅描述其中一部分。
struct kmem_cache_s {
/* 1) each alloc & free */
// 下面这些字段在分配和释放对象时很重要。
/* full, partial first, then free */
// slabs_ * :在前一节中介绍的三个 slab 链表。
struct list_head slabs_full;
struct list_head slabs_partial;
struct list_head slabs_free;
// slab 中每一个对象的大小。
unsigned int objsize;
// 一组标志位,决定分配器应该如何处理高速缓存,见 8.1.2 小节。
unsigned int flags; /* constant flags */
// 每一个 slab 中包含的对象个数。
unsigned int num; /* # of objs per slab */
// 并发控制锁,避免并发访问高速缓存描述符。
spinlock_t spinlock;
#ifdef CONFIG_SMP
// 在前面的章节中描述的为 per-cpu 高速缓存批量分配的对象数目。
unsigned int batchcount;
#endif
/* 2) slab additions /removals */
// 从高速缓存中分配和释放 slab 时将用到这些字段。
/* order of pgs per slab (2^n) */
// slab 以页为单位的大小,每个 slab 占用用 2*fpoder 个连续页面帧,其中分配的大小
// 由伙伴系统提供。
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
// 调用伙伴系统分配页面帧时用到的一组 GFP 标志位,完整列表见 7.4 节。
unsigned int gfpflags;
// 尽可能将 slab 中的对象存储在不同的硬件高速缓存行中。高速缓存着色将在
// 8.1.5 小节中进一步讨论。
size_t colour; /* cache colouring range */
// 对齐 slab 中的字节。例如 ,size-X 高速缓存对齐 L1 硬件高速缓存。
unsigned int colour_off; /* colour offset */
// 这是下一个将使用的着色行,其值超过 colour 时,它重新从 0 开始。
unsigned int colour_next; /* cache colouring */
kmem_cache_t *slabp_cache;
// 这个标志位用于指示高速缓存是否增长。如果设置了该标志位,就不太可能在
// 处于内存压力的情况下选中该高速缓存以回收空闲 slab。
unsigned int growing;
// 动态标志位,在高速缓存的生命期里动态变化,见 8.1.3 小节。
unsigned int dflags; /* dynamic flags */
/* constructor func */
// 为复杂对象提供的构造函数,用以初始化每一个新的对象。这是一个函数指针,可
// 能为空(NULL)。
void (*ctor)(void *, kmem_cache_t *, unsigned long);
/* de-constructor func */
// 对象的析构函数指针,也可能为空。
void (*dtor)(void *, kmem_cache_t *, unsigned long);
// 仅仅初始化为 0,其他的地方都没有用到。
unsigned long failures;
/* 3) cache creation/removal */
// 这两个字段在创建高速缓存时设置。
// 便于识别的高速缓存名称。
char name[CACHE_NAMELEN];
// 指向高速缓存链表中的下一个高速缓存。
struct list_head next;
#ifdef CONFIG_SMP
/* 4) per-cpu data */
// per-cpu 数据,在 8.5 中进一步讨论。
cpucache_t *cpudata[NR_CPUS];
#endif
// 在编译时设置 CONFIG_SLAB_DEBUG 选项时,这些数字才有效。它们都是不重要的计
// 数器,一般不必关心。读取/proc/slabinfo 里的统计信息时,与其依赖这些字段是否有效,还不
// 如通过另一个进程检查每个高速缓存里的每个 slab 使用情况。
#if STATS
// 当前在高速缓存中活动的对象数目。
unsigned long num_active;
// 已经分配的对象数目。
unsigned long num_allocations;
// num_active 的上限。
unsigned long high_mark;
// kmem_cache_grow()的调用次数。
unsigned long grown;
// 该高速缓存被回收的次数。
unsigned long reaped;
// 这个字段从未使用过。
unsigned long errors;
#ifdef CONFIG_SMP
// 分配器使用 per-cpu 高速缓存的次数。
atomic_t allochit;
// 对 allochit 的补充,是分配器未命中 per-cpu 高速缓存的次数。
atomic_t allocmiss;
// 在 per-cpu 高速缓存中空闲的次数。
atomic_t freehit;
// 对象释放后被置于全局池中的次数。
atomic_t freemiss;
#endif
#endif
};
8.1.2 高速缓存静态标志位
一些标志位在高速缓存初始化时就被设置了,并且在生命周期内一直不变。这些标志位影响到 slab 的结构如何组织以及对象如何存储在 slab 中。这些标志位组成一个位掩码,存储在高速缓存描述符的字段 flag 中。所有的标志位都在 linux/slab.h 中声明。
有 3 组标志位,第 1 组是内部标志位,仅由 slab 分配器使用,如表 8.2 所列。CFGS_OFF_SLAB 标志位决定 slab 描述符存储的位置。

第 2 组在创建高速缓存时设置,这些标志位决定分配器如何处理 slab,如何存储对象。列表如 8.3 所列。

第 3 组在编译选项 CONFIG_SLAB_DEBUG 设置后才有效,列表如 8.4 所列。它们决定了对 slab 和对象做哪些附加的检查,主要与新建的高速缓存相关。

为了防止调用错误的标志位,mm/slab.c 中定义了 CREATE_MASK,它由所有允许的标志位所组成。在创建一个高速缓存时,请求的标志位会和 CREATE_MASK 作比较,如果使用了无效的标志位,系统将会报告一个错误。
8.1.3 高速缓存动态标志位
虽然字段 dflag 中只有一个标志位 DFLGS_GROWN,但它却非常重要。该标志位在 kmem_cache_grow() 中设置,这样 kmem_cache_reap() 就就不会选择该高速缓存进行回收。kmem_cache_reap() 将跳过设置了该标志位的高速缓存,并清除该标志位。
8.1.4 高速缓存分配标志位
这些标志位,与为 slab 分配页面帧的 GFP 页面标志位选项相对应,列表如 8.5 所列。调用者既可以使用 SLAB_* 标志位,也可以使用 GFP * 标志位,但实际上应该仅仅使用 SLAB_* 标志位。它们和 6.4 节中所述的标志位直接对应,所以在这里不再详细讨论。假设存在这些标志位是为了明确不同的作用,在这种情况下 slab 分配器对不同的标志位就要作出不同的响应。而事实上它们没有任何区别。
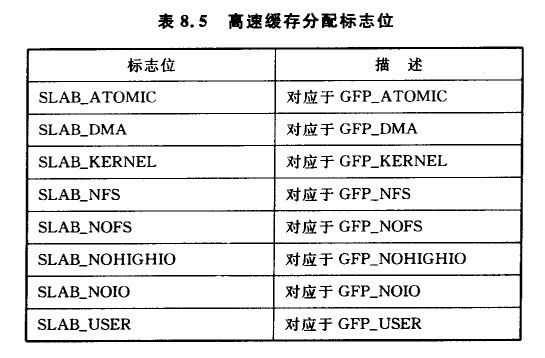
极少部分的标志位可能会传递给构造函数和析构函数,列表如 8.6 所列。

8.1.5 高速缓存着色
为了更好地利用硬件高速缓存,在不同的 slab 中,slab 分配器将对象放置在不同的偏移处,这取决于 slab 中剩余多少空间。偏移量都以 BYTES_PER_WORD 为单位,除非设置了标志位 SLAB_HWCACHE_ALIGN,在后者的情况下,将按照 L1_CACHE_BYTES 的块大小与 L1 硬件高速缓存对齐。
在创建一个高速缓存时,需要要计算一个 slab 适合多少个对象(见 8.2.7 小节),以及将浪费掉多少字节。正是由于这种字节的损失,Linux 将为高速缓存描述符计算如下两个数字。
- colour:能够使用的不同的偏移量数目。
- colour_off:每一个对象在 slab 中的整数倍偏移量。
通过对象偏移,它们将利用关联硬件高速缓存上不同的行。因此,从内存中调入 slab 中的对象就不会彼此覆盖。
最好是通过一个例子来解释。为方便起见,在 slab 中设置 s_mem(第 1 个对象的地址)为 0,且 slab 中共有 100 B 被浪费掉,另外奔腾 II 的硬件高速缓存 L1 是 32 B。
在这个例子中,第 1 个创建的 slab 使得它的对象从 0 开始。第 2 个从 32 开始,第 3 个从 64 开始,第 4 个从 96 开始,第 5 个又从 0 开始。这样,从不同 slab 中来的对象就不会命中同一硬件高速缓存行了。colour 和 colour_off 的值分别是 3 和 32。
8.1.6 创建高速缓存
函数 kmem_cache_create() 用于创建高速缓存并把他们添加到高速缓存链表中去。创建高速缓存有以下几步:
- 为了防止错误的调用,执行基本的检查。
- 如果设置了 CONFIG_SLAB_DEBUG,则执行调试检查。
- 从 cache_cache slab 高速缓存中分配一个 kmem_cache_t 结构。
- 将对象的大小调整为字对齐。
- 计算有多少对象可以放入一个 slab 中。
- 调整对象大小以适应硬件高速缓存。
- 计算着色偏移量。
- 初始化高速缓存描述符中其他字段。
- 将这个新的高速缓存添加到高速缓存链表中。
图 8.3 是创建高速缓存相关的函数调用图,每一个函数在代码注释部分都有完整描述。

8.1.7 回收高速缓存
在一个 slab 空闲时,系统将其放到 slab_free 链表中,以备将来使用。高速缓存不会自动收缩它们自己,因此当 kswapd 发现内存紧张时,就调用 kmem_cache_reap() 释放放一些内存。这个函数负责选择一个需要收缩它自己内存使用的高速缓存。值得注意的是,回收高速缓存不会考虑哪些内存节点或者哪些管理区处于压力下。这意味着,在 NUMA 或者有高端内存的机器上,内核可能会在没有内存压力的区域花大量的时间释放内存资源,但是在诸如 x86 体系结构的机器上不会出现这样的问题,因为它只有一个内存区。
图 8.4 中调用图虽然简单但其实是个假象,因为选择一个适当的高速缓存进行回收其实是一个非常漫长的过程。在有大量高速缓存的系统中,每次调用却只检查 REAP_SCANLEN(目前定义为 10)个高速缓存。最后一个被检查的高速缓存保存在变量 clock_searchp 中,以防止重复检查同一个高速缓存。对于每个已经检查过的高速缓存,回收器做如下事情:
- 检查 SLAB_NO_REAP 标志位,如果设置了就跳过。
- 如果高速缓存正在增长,也跳过。
- 如果高速缓存最近已经增长了,或正在增长,就设置标志位 DFLGS_GROW。如果该标志位已经被设置了,则跳过 slab,但同时要清除这个标志位,以便作为下一次回收的候选对象。
- 统计 slabs_free 链表中空闲 slab 的数量,并且计算在变量 pages 这么多个页面中将释放多少页面。
- 如果高速缓存有构造器,或者有大型的 slab,则调整 pages 以减少该高速缓存被选中的机会
- 如果待释放的页面数量超过 REAP_PERFECT,则释放 slabs_free 中一半的 slab。
- 否则,扫描剩下的高速缓存,并选择可释放最多页数的高速缓存,以释放 slabs_free 中它一半的 slab。

8.1.8 收缩高速缓存

在选中一个高速缓存以收缩它自己时,步骤既简单又直接:
- 删除 per-CPU 高速缓存中所有的对象。
- 删除 slabs_free 中所有的 slab,除非设置了增长标志位。
如果不是如此的微妙,Linux 其实什么也不是。
这里提供了两个易混淆的有相似名称却互不相同的收缩函数。如图 8.5 所示,kmem_cache_shrink() 删除 slabs_free 链表中所有的 slab 并返回已释放页面的数量。它是提供给 slab 分配器用户所使用的主要函数。
第 2 个函数 __kmem_cache_shrink() 如图 8.6 所示,它释放 slabs_free 链表中所有的 slab,并且核实 slab_partial 链表和 slab_full 链表是否为空。该函数仅用于内部,在销毁高速缓存的过程中显得非常重要,它不管要释放多少页面,只需高速缓存为空。
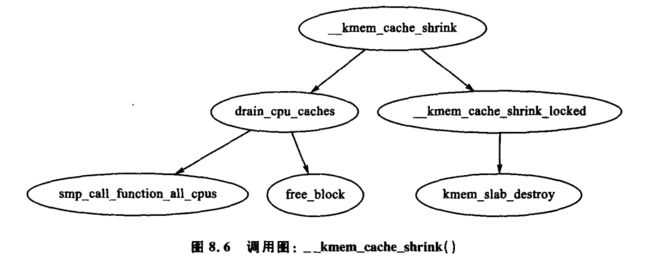
8.1.9 销毁高速缓存
在卸载一个模块时,Linux 需要由函数 kmem_cache_destroy() 销毁所有与之相关的高速缓存,如图 8.7 所示。是否适当地销毁高速缓存显得很重要,因为不允许有两个相同名称的高速缓存同时存在。核心内核代码一般不用关心去销毁它自己的高速缓存,因为这些高速缓存在整个系统生存期中一直存在。销毁一个高速缓存的步骤如下:
- 从高速缓存链表中删除该高速缓存。
- 收缩高速缓存,删除其中所有的 slab。
- 释放任意的 per-CPU 高速缓存( kfree() )。
- 从 cache_cache 结构中删除高速缓存描述符。

8.2 slabs
// mm/slab.c
/*
* slab_t
*
* Manages the objs in a slab. Placed either at the beginning of mem allocated
* for a slab, or allocated from an general cache.
* Slabs are chained into three list: fully used, partial, fully free slabs.
*/
typedef struct slab_s {
// 该 slab 所属的链接列表,可能是高速缓存管理器中 slab_full,slab_partial
// 或者slab_free 其中的一个。
struct list_head list;
// slab 中的相对于第一个对象基地止的着色偏移。第一个对象的地址是:s_mem + colouroff。
unsigned long colouroff;
// slab 中第一个对象的起始地址。
void *s_mem; /* including colour offset */
// slab 中活动的对象数目。
unsigned int inuse; /* num of objs active in slab */
// 这是一个 bufctls 数组,用于存储空闲对象的位置。更多的细节见 8.2.3 小节。
kmem_bufctl_t free;
} slab_t;
读者应该注意到,对于 slab 中给定的 slab 管理器或者对象,没有明显的方法判断它应属于哪一个 slab 或者高速缓存。这里通过 struct page 里的 list 字段来整合高速缓存。SET_PAGE_CACHE() 和 SET_PAGE_SLAB() 函数使用 page→list 中的 next 和 prev 字段来跟踪对象属于哪一个高速缓存或 slab。也可以通过宏 GET_PAGE_CACHE() 和 GET_PAGE_SLAB() 从页面中得到高速缓存描述符和 slab 描述符。这些关系如图 8.8 所示。
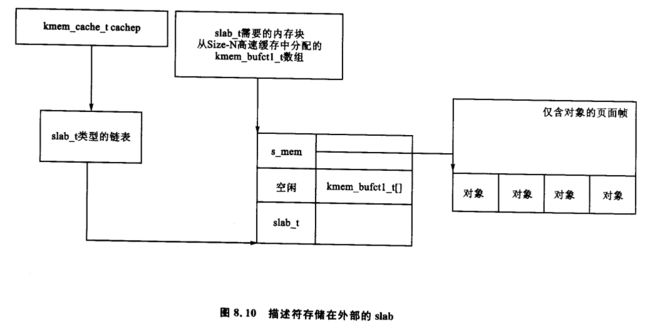
最后讨论保存 slab 描述符的位置。slab 描述符既可保存在 slab 中(CFLGS_OFF_SLAB 在静态标志位中设置)也可保存在 slab 外。具体保存的位置由创建高速缓存时对象的大小决定。但是 struct slab_t 可以存储在页面帧的首部,尽管图 8.8 中显示的 struct slab_t 和页面帧是分开的。

8.2.1 存储 slab 描述符
如果对象大于阈值(在 x86 架构中是 512 B),就需要设置高速缓存中的标志位 CFGS_OFF_SLAB,slab 描述符保存在 slab 之外的某个指定大小的高速缓存中(见 8.4 节)。所选择的指定大小的高速缓存要足够大,能够容纳 struct slab_t,在需要的时候,函数 kmem_cache_slabmgmt() 从中进行分配。这将限制存储在 slab 中的对象数目,因为只有有限的空间分配给 bufctls 数组 。然而当对象很大时,这就不重要了,因此没有必要将很多对象存储在单个 slab 中。
或者说,可以将 slab 管理器保存在 slab 的起始处。当保存在 slab 中时,在起始处要留有足够的空间以存储 slab_t 和无符号整形数组 kmem_bufctl_t。这个数组用于跟踪下一个可用空闲对象的索引,这将在 8.2.3 小节作进一步讨论。而实际的对象保存在 kmem_bufctl_t 数组之后。
图 8.9 可以帮助我们清楚地理解描述符在 slab 内部时的 slab 结构。图 8.10 描述了 slab 描述符保存在外部时,高速缓存如何用指定大小的高速缓存来存储 slab 描述符。

8.2.2 创建 slab
在这里,我们已经看到怎样创建一个高速缓存,但在创建时,它是一个空的高速缓存,而且链表 slab_full,slab_partial 和 slabs_free 也都是空的。通过调用函数 kmem_cache_grow() 给高速缓存分配新的 slab,其调用图如图 8.11 所示 。通常称之为 “高速缓存增长” ,当 slab_partial 链表中没有对象或者 slabs_free 链表中没有 slab 时调用该函数。所有的任务如下:
- 为了防止错误的调用,执行基本的全面检查。
- 计算 slab 中对象的着色偏移量。
- 为 slab 分配内存,并获取 slab 描述符。
- 把用于 slab 的页面链接起来放置到 slab 和高速缓存描述符中,见 8.2 节。
- 初始化 slab 中的对象。
- 将这个 slab 添加到高速缓存中。

8.2.3 跟踪空闲对象
slab 分配器有一个快速简单的方法来跟踪在部分填充的 slab 中的空闲对象。通过使用与每个 slab 管理器相关联的称为 kmem_bufctl_t 的无符号整形数组来达到这个目的。很明显,slab 管理器需要知道它的空闲对象在哪。
参照以往描述 slab 分配器的文章 [Bon94],kmem_bufctl_t 是一个对象链表。在 Linux2.2. x 内核中,这个结构是个具有 3 项的联合体:一个指向下个空闲对象的指针,一个指向 slab 管理器的指针,以及一个指向对象本身的指针。在联合中具体是哪一个字段取决于对象的状态。
现在,对象属于哪一个 slab 和高速缓存是由 struct page 决定的,而 kmem_bufctl_t 是一个简单的对象索引整型数组。数组中元素的个数与 slab 中对象的个数相同。
typedef unsigned int kmem_bufctl_t;
因为数组保存在 slab 描述符之后,并且没有指针直接指向第一个元素,所以需要提供辅助宏 slab_bufctl()。
#define slab_bufctl(slabp) \
((kmem_bufctl_t *)(((slab_t*)slabp)+1))
这个看起来很神秘的宏展开后却相当简单。参数 slabp 是一个指向 slab 管理器的指针。表达式 ((slab_t *)slabp)+1 将结构 slabp 转换成 slab_t 结构,然后加 1。这个操作实际上返回了指向数组 kmem_bufctl_t 起始地址的指针。(kmem_bufctl_t *) 又将这个指针转换为所需的类型。这个代码块的返回值是 slab_bufctl(slabp)[i]。或者说是,“通过指向 slab 描述符的指针,由宏 slab_bufctl() 进行偏移得到数组 kmem_bufctl_t 的起始地址,然后返回该数组中第 i 个元素”。
在 slab 里下一个空闲对象的索引存储在 slab_t→free 中,删除了为跟踪空闲对象而需要的链表。分配或者释放对象时,这个指针基于数组 kmem_bufctl_t 中的信息更新。
8.2.4 初始化 kmem_bufctl_t 数组
当高速缓存增长时,slab 中的对象和数组 kmem_bufctl_t 将被初始化。数组被填充每一个对象的索引,从 1 开始,并以标记 BUFCTL_END 结束。例如具有 5 个对象的 slab,数组中的元素如图 8.12 所示。
数值 0 存储在 slab_t→free 中,是因为第 0 个对象 BUFCTL_END 表示第一个被使用的空闲对象。对于给定的第 n 个对象,其下一个空闲对象索引将被存储在 kmem_bufctl_t[n] 中。 看着上面的数组,0 之后的下一个空闲对象图 8.12 初始化数组 kmem_bufctl_t 是 1。而 1 之后是 2,依此类推。正如数组所使用的,这样的排列使数组看起来更像一个空闲对象的后进先出队列(LIFO)。

8.2.5 查找下一个空闲对象
当分配一个对象时,kmem_cache_alloc() 调用 kmem_cache_alloc_one_tail() 执行更新数组 kmem_bufctl_t() 的实际动作。字段 slab_t→free 具有第一个空闲对象的索引。而下一个空闲对象的索引在 kmem_bufctl_t[slab_t→free] 中。它在代码中如下:
objp = slabp->s_mem + slabp->free * cachep->objsize;
slabp->free = slab_bufctl(slabp)[slabp->free];
字段 slabp→s_mem 是指向 slab 中第一个对象的指针。slabp→free 是将被分配的对象的索引,而且必须和一个对象的大小相乘。
下一个空闲对象的索引存储在 kmem_bufctl_t[slabp→free] 中。由于没有指针直接指向数组,因此使用宏 slab_bufctl() 作为辅助手段。请注意数组 kmem_bufctl_t 在分配过程中并没有改变,但是没有被分配的元素不能被访问。例如,分配 2 个元素后,数组 kmem_bufctl_t 中的索引 0 和 1 并没有被任何其他的元素所指向。
8.2.6 更新 kmem_bufctl_t
只有在函数 kmem_cache_free_one() 中释放一个对象时才需要更新数组 kmem_bufctl_t。数组更新的代码如下:
unsigned int objnr = (objp-slabp->s_mem)/cachep->objsize;
slab_bufctl(slabp)[objnr] = slabp->free;
slabp->free = objnr;
指针 objp 指向将要被释放的对象,而 objnr 是其索引。kmem_bufctl_t[objnr] 被更新为指向 slabp→free 的当前值,通过字段 free,有效地替换了虚拟链表上的对象。slabp→free 被更新为即将被释放的对象,因此它也会是下一个被分配的对象。
8.2.7 计算 slab 中对象的数量
创建高速缓存时,系统通过调用 kmem_cache_estimate() 函数计算在单个的 slab 上可以存放多少个对象。这要考虑 slab 描述符是存储在 slab 之内还是之外,并且跟踪每一个 kmem_bufctl_t 的大小,无论对象是否空闲。该函数返回可能存储的对象个数以及浪费的字节数。若使用高速缓存着色,则浪费的字节数就非常可观。
基本的计算步骤如下:
- 初始化 wastage 为整个 slab 的大小,例如 PAGE_SIZEgfp_order。
- 减去 slab 描述符所占用的空间。
- 计算可能存储的对象个数。如果 slab 描述符存储在 slab 之内,还要考虑 kmem_bufctl_t 的大小。持续增加 i 的大小直至 slab 被填充。
- 返回对象的个数和浪费的字节数。
8.2.8 销毁 slab
在收缩、销毁高速缓存时,系统将删除其中的 slab。由于对象可能有析构函数,如果这样它们就必须被调用,因此该功能的任务如下:
- 如果析构函数可用的话,调用 slab 中所有对象的析构函数。
- 如果允许调试,检查红色标志位和感染模式。
- 释放 slab 使用的页面。
函数调用图如图 8.13 所示,非常简单。

8.3 对 象
这一节主要内容是如何管理对象。大多数真正需要做的工作已经被高速缓存或 slab 管理器完成。
8.3.1 初始化 slab 中的对象
当创建一个 slab 时,所有的对象都处于初始化状态。如果构造函数可用,它将为每一个对象所调用,而一旦对象被释放,就认为它处于初始化状态。从概念上讲,这个初始化过程很简单。遍历所有的对象,调用构造函数,并为它初始化 kmem_bufctl。函数 kmem_cache_init_objs() 负责初始化对象。
8.3.2 分配对象
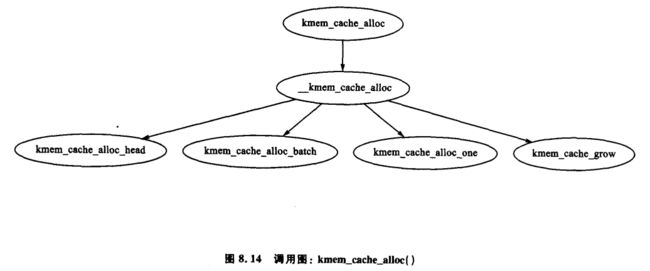
函数 kmem_cache_alloc() 负责分配一个对象给调用者,这在 UP 和 SMP 系统中稍微有所不同。在 SMP 系统中分配对象时的基本函数调用图如图 8.14 所示。
有 4 个基本步骤:第 1 步(kmem_cache_alloc_head() 进行基本的检查,确保允许分配。第 2 步选择从哪一个 slab 链表中分配对象。slabs_partial 或者 slabs_free 中的任一个都有可能。如果在 slabs_free 中没有,就增大高速缓存空间(见 8.2.2 小节)并在 slabs_free 中创建一个新的 slab。最后一步从选中的 slab 中分配对象。
在 SMP 系统中,还有一步,在分配对象前,系统会检查 per-CPU 高速缓存并查找一个可用的高速缓存,如果有的话,则使用它。如果没有,系统在会成批地分配对象的 batchcount 数量并置于它们自己的 per-CPU 高速缓存中。关于 per-CPU 高速缓存更多的信息见 8.5 节。
8.3.3 释放对象
函数 kmem_cache_free() 的调用图如图 8.15 所示,它用于释放对象,这是一个相对简单的任务。跟 kmem_cache_alloc() 函数一样,它在 UP 以及 SMP 中表现不一样。在这两个系统中主要的区别是,在 UP 中,对象直接返回给 slab;而在 SMP 中,对象却返回给 per-CPU 高速缓存。但在这两种情况下,如果对象有可用的析构函数的话,则函数都会被调用。析构函数负责把对象状态返回到初始化状态。

8.4 指定大小的高速缓存
对于小块内存分配,由于物理页面分配器不再适用,所以 Linux 保留有两套高速缓存系统。一套高速缓存由 DMA 使用,而另一套在通常情况下使用。人们称呼它们为 size-N 高速缓存和 size-N(DMA) 高速缓存,可以通过 /proc/slabinfo 看到。每种指定大小的高速缓存的信息都存放在一个 struct cache_sizes 中,它们也具有 cache_sizes_t 的类型,在 mm/slab.c 中定义如下:
// mm/slab.c
/* Size description struct for general caches. */
typedef struct cache_sizes {
// 内存块的大小。
size_t cs_size;
// 常规内存使用的高速缓存块。
kmem_cache_t *cs_cachep;
// DMA 使用的高速缓存块。
kmem_cache_t *cs_dmacachep;
} cache_sizes_t;
由于这些高速缓存的数量是有限的,所以在编译时期系统会初始化一个静态数组 cache_sizes。它的值在 4 KB 机器上以 32 B 作为起始,如果页面更大,它将会从 64 开始。
// mm/slab.c
static cache_sizes_t cache_sizes[] = {
#if PAGE_SIZE == 4096
{ 32, NULL, NULL},
#endif
{ 64, NULL, NULL},
{ 128, NULL, NULL},
{ 256, NULL, NULL},
{ 512, NULL, NULL},
{ 1024, NULL, NULL},
{ 2048, NULL, NULL},
{ 4096, NULL, NULL},
{ 8192, NULL, NULL},
{ 16384, NULL, NULL},
{ 32768, NULL, NULL},
{ 65536, NULL, NULL},
{131072, NULL, NULL},
{ 0, NULL, NULL}
};
很显然,这是一个以 0 结尾的数组,它从 25 到 217 由 2 的指数个缓冲区组成。当系统启动时,这个数组就必须被初始化,然后用于描述每一种指定大小的高速缓存。
8.4.1 kmalloc()
由于存在指定大小的高速缓存,slab 分配器可以提供一个新的分配函数 kmalloc(),每当需要较少内存缓冲区时就调用该函数。当系统接收到一个这样的请求时,系统会选择适当的指定大小的缓冲区,并且从它当中分配一个对象。因为大部分困难的工作在分配高速缓存时已经完成,所以如图 8.16 所示的调用过程非常简单。

8.4.2 kfree()
既然有一个 kmalloc() 函数用来分配小块内存对象,那么就有一个 kfree() 用来释放小块内存对象。和 kmalloc() 函数一样,实际的工作在对象释放的时候完成 (见 8.3.3 小节),所以如图 8.17 所示的函数调用图也很简单。

8.5 per-CPU 对象高速缓存
slab 分配器致力于的一个任务就是提升硬件和高速缓存的使用效率。一般来讲,高性能计算 [CS98] 的一个目标就是尽可能长时间地使用同一个 CPU 上的数据。Linux 通过 per-CPU 尝试将对象保留在同一个 CPU 高速缓存中来实现这个任务,per-CPU 高速缓存在系统中可以简单地称为每个 CPU 的 cpucache。
当对象被分配或者被释放时,它们都被放置在 cpucache 中。在没有空闲对象时,系统就将一批对象放置到这个池中。在池变得过于庞大时,系统就移除其中一半的对象,放到全局高
速缓存中。这样,就可以尽可能长时间地使用同一个 CPU 上的硬件高速缓存。
这种方法的第二个好处是在访问 CPU 池时不需要获得自旋锁,这是因为我们已经保证不会有另外的 CPU 访问这些局部数据。这点很重要,如果没有高速缓存,那么就必须在每次分配和释放时都要获得自旋锁,这是不必要的开销。
8.5.1 描述 per-CPU 对象高速缓存
每一个高速缓存描述符都有一个指针指向一个 CPU 高速缓存数组,它在高速缓存中描述如下:
// mm/slab.c
/*
* cpucache_t
*
* Per cpu structures
* The limit is stored in the per-cpu structure to reduce the data cache
* footprint.
*/
typedef struct cpucache_s {
// 在 cpucache 中可用的空闲对象的数量。
unsigned int avail;
// 能够存在的空闲对象的总数量。
unsigned int limit;
} cpucache_t;
对于一个给定的高速缓存和处理器,系统为 cpucache 提供了一个 cc_data() 宏作为辅助,它的定义如下:
// mm/slab.c
#define cc_data(cachep) \
((cachep)->cpudata[smp_processor_id()])
该宏需要一个给定的高速缓存描述符(cachep)作为输入参数,然后从 cpucache 数组(cpudata)中返回一个指针。所需的索引是当前处理器的 ID,即 smp_processor_id() 。
很快系统就会在 cpucache_t 结构后面存储 cpucache 中的对象。这与在 slab 描述符后面存储对象类似。
8.5.2 在 per~CPU 高速缓存中添加/移除对象
为防止碎片的产生,通常是在数组的末尾进行添加和删除对象的操作。以下代码块用于添加对象(obj)到 CPU 高速缓存(cc)中:
cc_entry(cc)[cc->avail++] = obj;
以下代码块用于移除对象:
obj = cc_entry(cc)[--cc->avail];
辅助宏 cc_entry()给出了 CPU 高速缓存中指向第一个对象的指针,它的定义如下:
#define cc_entry(cpucache) \
((void **)(((cpucache_t*)(cpucache))+1))
它用一个指针指向 cpucache,并根据 cpucache_t 描述符的大小增加其值,从而得到高速缓存中第一个对象。
8.5.3 启用 per-CPU 高速缓存
在创建一个高速缓存时,就必须启动 CPU 高速缓存,并调用 kmalloc() 函数为之分配内存函数 enable_cpucache() 负责决定 per-CPU 高速缓存的大小,并调用 kmem_tune_cpucache() 函数为该高速缓存分配空间。
显然,各种指定大小的高速缓存被启动后,CPU 高速缓存就不能再存在了,因此,系统使用全局变量 g_cpucache_up 来防止 CPU 高速缓存被过早地启用。函数 enable_all_cpucaches() 遍历高速缓存链表中所有的高速缓存,并逐个启动各自的 cpucache。
一旦启用了 CPU 高速缓存,不需要加锁就可以直接访问了,因为 CPU 决不会访问到错误的 cpucache,所以可以保证访问的安全性。
8.5.4 更新 per-CPU 高速缓存的信息
per-CPU 高速缓存被创建或被修改后,每一个 CPU 通过 IPI 得知该情况。这时若没有改变高速缓存描述符中所有的值,就可能导致高速缓存的信息不一致,因此就必须用加锁的方式来保护 CPU 高速缓存中的信息。所以,Linux 中提供了一个 ccupdate_t 结构,它里面包含了每一个 CPU 所需要的信息,并且每一个 CPU 在这个高速缓存描述符中通过旧信息交换新数据。用于存储新 cpucache 信息的结构定义如下:
// mm/slab.c
typedef struct ccupdate_struct_s
{
kmem_cache_t *cachep;
cpucache_t *new[NR_CPUS];
} ccupdate_struct_t;
其中的 cachep 是已经更新过的高速缓存,new 是系统中每个 CPU 的 cpucache 描述符的数组。 函数 smp_function_all_cpus() 取得每个 CPU,然后调用 do_ccupdate_local() 函数将 ccupdate_struct_t 中的信息与高速缓存描述符中的信息进行交换。
一旦这些信息被交换后,旧的数据就可以删除了。
8.5.5 清理 per~CPU 高速缓存
收缩一个高速缓存时,第一步就是调用 drain_cpu_caches() 来清理对象可能具有的 cpucache。在这里 ,slab 分配器必须清楚地知道可以释放哪些 slab,这一点很重要,因为即便在 per-CPU 高速缓存的 slab 中只有一个对象,这整个 slab 也不能被释放。在系统内存紧张时,没有必要在分配操作上节约几毫秒的时间。
8.6 初始化 slab 分配器
这一节描述 slab 分配器如何初始化它自己。在 slab 分配器创建一个新的高速缓存时,它就从 cache_cache 或者 kmem_cache 高速缓存中分配 kmem_cache_t 结构。这显然是一个是先有鸡还是先有蛋的问题,所以必须静态地初始化 cache_cache,如下:
/* internal cache of cache description objs */
static kmem_cache_t cache_cache = {
// 初始化这 3 个链表成空链表。
slabs_full: LIST_HEAD_INIT(cache_cache.slabs_full),
slabs_partial: LIST_HEAD_INIT(cache_cache.slabs_partial),
slabs_free: LIST_HEAD_INIT(cache_cache.slabs_free),
// 每个对象的大小是一个高速缓存描述器的大小。
objsize: sizeof(kmem_cache_t),
// 高速缓存的创建和删除是非常少见的,因此并不用考虑它的回收。
flags: SLAB_NO_REAP,
// 初始化自旋锁为开锁状态。
spinlock: SPIN_LOCK_UNLOCKED,
// 对象和 L1 高速缓存对齐。
colour_off: L1_CACHE_BYTES,
// 记录可读性好的命名。
name: "kmem_cache",
};
编译时,系统会计算所有这些静态定义字段的代码。为了初始化结构的其余部分,函数start_kernel() 会调用 kmem_cache_init() 。
8.7 伙伴分配器接口
slab 分配器并不拥有页面,它必须通过物理页面分配器为其分配页面。为此,系统提供了两个 API 函数 kmem_getpages() 和 kmem_freepages() 。这两个函数基本上都是对伙伴分配器的 API 封装,因此在分配时要考虑 slab 标志位。分配时,缺省页面从 cachep→gfpflags 得到,而其顺序从 cachep->gfporder 得到,其中 cachep 是请求页面的高速缓存。在释放页面时,PageClearSlab() 会在调用 free_pages() 之前由于每个即将释放的页面而被调用。
8.8 2.6 中有哪些新特性
最明显的改变是 /proc/slabinfo 格式的版本由 1.1 升级到 2.0,这样更具可读性。最有帮助的改变是现在字段都有了一个首部,省去了记忆每栏意思的必要。
主要的算法思想以及概念与原来一样。虽然主要的算法没有变,但是算法的实现却很不同。尤其是,2.6 中特别强调使用 per-CPU 对象以避免上锁操操作。其二,2.6 中包含了大量的调试代码,所以在阅读代码时就需要略过那些 #ifdef DEBUG 的部分。最后,对一些函数名做了字面意义上的修改,其实它们的行为依旧没变。例如,kmem_cache_estimate() 现在称为
cache_estimate() ,其实它们除了名字什么都是一样的。
高速缓存描述符
对 kmem_cache_s 的改变很少。首先,在这个结构的起始位置记录常用的元素,如 per-CPU 相关的数据(原因见 3.9 节)。其次 ,slab 链表(如 slabs_full)以及与其相关的统计数据都被转移到了另一个单独的 struct kmem_list3 中。注释以及不常用的宏表明将有计划使该结构对应于单个的节点。
高速缓存静态标志位
在 2.4 中的这些标志位仍然存在,他们的使用方法也是相同的。CFLAGS_OPTIMIZE 不再存在了,它在 2.4 中就没有使用过。2.6 中还引入了两个新标志位。
SLAB_STORE_USER:这是只用于调试的标志位,它记录释放对象的函数。如果对象在释放后被使用,那么感染标志位的字节就不会匹配,系统将显示一个内核错误消息。由于知道最后一个使用对象的函数,所以调试更轻松。
SLAB_RECLAIM_ACCOUNT:这个标志位由具有易回收对象的高速缓存所使用,如索引节点高速缓存。系统在一个称为 slab_reclaim_pages 的变量中设置了一个计数器,用于记录 slab 在这些高速缓存中分配了多少页面。这个计数器在后面用于 vm_enough_memory() ,来帮助决定系统是否真的内存溢出。
回收高速缓存
这是对 slab 分配器最有意思的改变。不再存在 kmem_cache_reap() 是因为在用户面对更为长远的选择时,该函数不加选择地决定如何缩小高速缓存。高速缓存的用户现在可以使用 set_shrinker() 注册一个收缩高速缓存的回调函数来实现智能计数和收缩 slab。这个简单的函数生成一个 struct shrinker,在这个结构中有一个指向回调函数的指针和一个搜寻权重,这个权重表明了在把对象放入称为 shrinker_list 的链表之前重建对象的困难程度。
在页面回收时,系统调用函数 shrink_slab() ,它遍历整个 shrinker_ist,并调用每个收缩回调函数两次。第 1 次调用传一个 0 作为参数,它表明如果函数被适当调用了,回调函数应该返回它希望自己能够释放的页面数量。系统对各回调函数的代价作了基本的试探以决定是否值得使用该回调函数。如果值得,它将第 2 次作为参数被调用,以表明有多少对象被释放。
计算释放页面数量的机制是有技巧的。 每个任务结构中有个称为 reclaim_state 的字段。在 slab 分配器释放页面时,就用被释放的页面数量更新该字段。在调用 shrink_slab() 之前,该字段设置为 0,在 shrink_cache 返回以决定释放多少页面之后,系统将再次读取该字段。
其他的改变
其他的改变实际上都是表面上的。例如,slab 描述器现在称为 struct slab 而不是 slab_t,这和目前逐步不使用 typedefs 的趋势相一致。per-CPU 高速缓存除了结构以及 API 有新的命名以外基本保持不变。相同类型的变化在大多数 2.6 内核的 slab 分配器中都实现了。
第9章 高端内存管理
内核只有在设置了页表项后才能直接定址内存。在大多数情况下,用户/内核地址空间分别分成 3 GB/1 GB。这就意味着,正如在 4.1 节中解释的那样,在一台 32 位的机器上至多只有 896 MB 的内存可以直接被访问。在一台 64 位的机器上,因为有足够多的虚拟地址空间,所以这实际上不是个问题。现在还不可能有运行 2.4 内核的机器具有 TB 级的 RAM。
现在已经有很多高端的 32 位机器拥有 1 GB 的内存,因此,就不能简单地忽略不方便定址的那部分内存。Linux 使用的方法是暂时把高端内存映射为较低的页表。9.2 节中将会讨论。
高端内存与 I/O 相关的一个问题必须提到,即并不是所有的设备都可以访问高端内存或者对 CPU 可用的所有内存。这可能是这样一种情况,如果 CPU 开启了 PAE 拓展,那么设备就被限制在只能访问有符号 32 位整数的空间(2 GB)或者是 64 位架构中所使用的 32 位设备。控制设备写内存,最好的情形是内存失效,而最坏的情形可能使内核崩责。解决这个问题的方法是使用弹性缓冲区,这个将在 9.5 节中讨论。
这一章首先简要地描述如何管理持久内核映射(PKMap)地址空间间,然然后讨论页面如何映射到高端内存以及如何解除映射。接下来的小节将先讨论哪个地方的映射必须是原子性的,然后深入讨论弹性缓冲区。最后我们将谈到在内存非常紧张时,如何使用紧急池。
9.1 管理 PKMap 地址空间
在内核页表顶部,从 PKMAP_BASE 到 FIXADDR_START 的空间保留给 PKMap 。这部分保留的空间大小变化很细微。在 x86 上,PKMAP_BASE 位于 0xFE000000,而 FIXADDR_START 的地址是一个编译时常量,它只随着配置选项而变化,但一般是只有一少部分页面被分配在线性地址空间的尾部附近。这就意味着把页面从高端内存映射到可用空间的页表空间略小于 32 MB 。
为了映射页面,单个页面集的 PTE 被存放在 PKMap 区域的起始部分,从而允许 1024 个页面在短期内通过函数 kmap() 映射到低端内存,接着由 kunmap() 解除映射。这个池看起来虽然很小,但同时 kmap() 映射页面的时间却也非常短。代码的注解表明了有计划进行分配连续的页表项以扩充这部分区域,但现在保留的仍只是代码注释,所以大部分 PKMap 的部分没有被用到。
kmap() 调用中用到的页表项称为 pkmap_page_table,它位于 PKMAP_BASE,并且在系统初始化时就建立 。在 x86 上,它是在 pagetable_init() 函数结束部分进行的 。 含有 PGD 和 PMD 项的页面由引导内存分配器分配,以保证它们的存在性。
当前页表项的状态由一个称为 pkmap_count 的简单数组管理,它具有 LAST_PKMAP 项。在没有 PAE 的 x86 系统统中,它的值是 1024,而在具有 PAE 的系统中,它的值是 512。更准确地说,虽然在代码中没有体现出来,LAST_PKMAP 变量的值等于 PTRS_PER_PTE。
虽然每个元素不是准确的引用计数,但是那也很接近引用计数。如果该项是 0,则该页空闲,而且自上次 TLB 刷新后就没被使用过。如果是 1,则该槽没有被使用,但是仍有页面映射该槽,等待一次 TLB 刷新。因为当全局的页表修改时需要对所有的 CPU 进行刷新,而这个操作的开销是相当大的,所以每个槽都被使用至少一次以后才会进行刷新。任意更高的数值都是对该页面 n-1 个用户的引用计数。
9.2 映射高端内存页面

表 9.1 中描述了从高端内存映射页面的 API。主要用于映射页面的函数是 kmap() ,其调用图见图 9.1。如果用户不想阻塞,那么可以使用 kmap_nonblock() ,而中断用户可以使用 kmap_atomic() 。kmap 池相当小,所以 kmap() 调用者尽可能快地调用 kunmap() 就显得很重要,因为与低端内存相比,这个小窗口的压力随着高端内存的增大而变得更为严重。
kmap() 函数本身非常简单。它首先检查一下以保证中断没有调用这个函数(因为它可能睡眠),然后在确认的情况下调用 out_of_line_bug() 。由于调用 BUG() 中断处理程序有可能使系统瘫痪,所以 out_of_line_bug() 输出 bug 信息并干净地退出。接着要检查的是页面是不是在 highmem_start_page 以下,因为低于该标记位的页面已经是可见的了,而且不需要映射。
接着要检查的是该页面是否已经在低端内存,如果是就只返回该页面的地址。这样,如果该页面正处于低端内存,kmap() 的调用者将会无条件地知道这一情况,所以这个函数总是安全的。如果要映射的页面是高端内存页面,那就调用 kmap_high() 来完成实际的工作。
kmap_high() 函数一开始就检查 page→ virtual 字段,该字段在页面已经被映射时设置。如果该字段为 NULL,那么由 map_new_virtual() 提供页面的一个映射。
map_new_virtual() 通过简单的线性扫描 pkmap_count 来创建新的虚拟映射。为了避免在几次 kmap() 调用间隔之间重复搜索同一个区域,因此扫描不是在 0 处开始的,而是开始于 last_pkmap_nr 处。当 last_pkmap_nr 折返到 0,系统就会调用 flush_all_zero_pkmaps() 将所有项从 1 设为 0,然后刷新 TLB。
如果在某次扫描完成后,依旧找不到某项,则该进程就会在 pkmap_map_wait 队列上睡眠,直至它被下一次 kunmap() 唤醒。
映射创建之后,pkmap_count 数组中的相应项就会增 1,然后返回低端内存的虚拟地址。

9.3 解除页面映射
解除高端内存页面映射的 API 如表 9.2 所列。kunmap() 函数就像它的辅助物一样,执行两次检查。第 1 次做与 kmap() 相似的检查,用于检查中断上下文。第 2 次检查页面是否处于 highmem_start_page 以下。如果是,则该页面已经在低端内存中,不需要做进一步的处理。如果确定该页面要被解除映射,就调用 kunmap_high() 进行解除映射的操作。
kunmap_high() 的原理很简单。它把 pkmap_count 中该页面的相应元素减 1。如果减到了 1(记住这意味着没有更多的用户了,需要一次 TLB 刷新),所有在 pkmap_map_wait 队列上等待的进程都会被唤醒,因为现在有一个槽可用。但这时并不把该页面从页表上解除映射,因为解除映射需要一次 TLB 刷新。它会一直延迟到 flush_all_zero_pkmaps() 被调用。

9.4 原子性的映射高端内存页面
虽然并不推荐使用 kmap_atomic(),但是页面槽都会留给每个 CPU 以备需要,比如弹性缓冲区,在中断时供设备使用。一种结构是需要很多不同数量的原子性映射页面操作的,这种数量由 km_type 枚举。可用的总数是 KM_TYPR_NR 标志位。在 x86 上,共有 6 种不同的原子 kmap 使用方法。
在引导时,在地址 FIX_KMAP_BEGIN 和 FIX_KMAP_END 之间,系统会为每个处理器保留 KM_TYPE_NR 个项。显然在调用 kunmap_atomic() 之前,一个 kamp 原子操作的调用者可能不会睡眠或退出,这是因为同一处理器上的下一个进程可能尝试使用同一个项,但却会失败。
在所请求类型的操作和处理机的页表中,把请求页面映射到槽时,函数 kmap_atomic() 的任务很简单。函数 kunmap_atomic() 的调用图如图 9.2 所示,该函数很有意思,因为它仅仅是在启用调试项时调用 ptr_clear() 清理 PTE。 一般认为不需要解除原子页面映射,也不需要作 TLB 刷新操作,因为下一次 kmap_atomic() 调用会替换掉这些原子页面。

9.5 弹性缓冲区
对那些不能访问所有 CPU 可见的所有内存的设备而言,弹性缓冲区是必需的。一个很明显的例子是不能寻址和 CPU 一样多的位数的设备,如在 64 位结构上的 32 位设备,或最近的允许 PAE 的 Intel 处理器。
它的基本的思想很简单。弹性缓冲区驻留在足够低端的内存中,从而使设备从里面复制数据以及向里面写数据。然后它会把相应的用户页面复制到高端内存。这种附加的复制虽然是不合理的,但它又是不可或缺的。系统首先在低端内存中分配页面供 DMA 和设备的缓冲区页面。然后在 I/O 完成时由内核把它们复制到高端内存的缓冲区中,所以弹性缓冲区扮演着一个中介的角色。这种复制操作有一些负担,因为它至少涉及复制整个页面,但是与换出低端内存中的页面操作比较起来,这些负担又是无关紧要的。
9.5.1 磁盘缓冲
磁盘块,一般为 1 KB 的大小,并且都装配成页面由 slab 分配器分配的 struct buffer_head 管理。缓冲区首部的用户具有一个回调函数选项。该回调函数在 buffer_head 中注册为 buffer_head->b_end_io(),它在 I/O 完成时调用。这就是弹性缓冲区用于完成把数据复制出弹性缓冲区的机制。注册的回调函数叫 bounce_end_io_write() 。
缓冲区首部的其他特征以及磁盘块层如何使用它们已经超出了本书的范围,它们更多的是 I/O 层所关心的。
9.5.2 创建弹性缓冲区
如图 9.3 所示,创建弹性缓冲区是一件简单的事,它从函数 create_bunce() 开始。它的原理很简单,使用一个所提供的缓冲区首部作为模板来创建一块新的缓冲区。该函数有两个参数,它们是 read/write 参数(rw)和所使用的缓冲区首部的模板(bh_orig)。

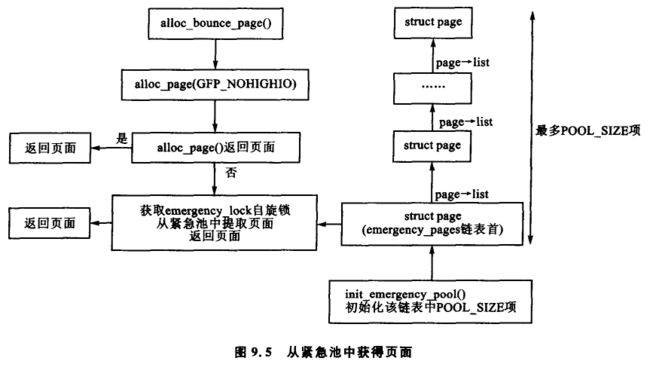
函数 alloc_bounce_page() 为缓冲区本身分配页面,它是一个 alloc_page() 的包装器,但是有一个重要的例外情形。如果该分配操作没有成功,就会有一个页面的紧急池以及缓冲区首部返回给弹性缓冲区。这将在 9.6 讨论。
可以肯定,该缓冲区的首部将由 alloc_bounce_bh() 分配,该函数原理上与 alloc_bounce_page() 类似,它调用 slab 分配器得到一个 buffer_head,如果无法分配时将使用缓冲池。另外,唤醒 bdflush 以开始将脏缓冲区刷出到磁盘,这样就可以立即释放缓冲区。
一旦分配了页面和 buffer_head,信息就会从模板 buffer_head 被复制到新的 buffer_head 中。 由于这部分操作可能用到 kmap_atomic() ,弹性缓冲区的创建仅在设置了 IRQ 安全锁 io_request_lock 后才开始。I/O 完成的回调过程或者改变为 bounce_end_io_write() 或者改变为 bounce_end_io_read() ,这取决于这是一个读或写缓冲区,因此数据将会在高端内存来回复制。
在分配方面要注意的最重要的方面是 GFP 标志位并没有涉及高端内存的 I/O 操作。这一点很重要,因为弹性缓冲区是用于高端内存的 I/O 操作的。如果分配器试图进行高端内存 I/O,它将被递归调用并最终失败。
9.5.3 通过弹性缓冲区复制数据
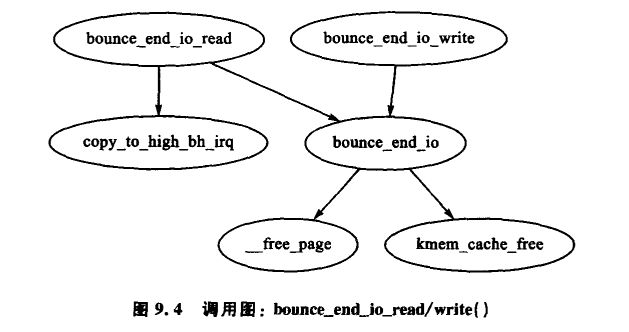
通过弹性缓冲区复制的数据随着它是读还是写缓冲区而不同。如果该缓冲区用于写数据到设备,那么该缓冲区存储的是在 copy_from_high_bh() 创建弹性缓冲区时从高端内存读出的数据,回调函数 bunce_end_io_write() 将在设备准备好接收数据时完成 I/O 操作。
如果该缓冲区用于从设备读数据,则在设备准备好前是没有数据转移的。当设备准备好后,设备的中断处理程序将调用回调函数 bounce_end_io_read() ,由它调用 copy_to_high_bh_irq() 把数据复制到高端内存。
在这两种情形下一旦 I/O 完成,模板的回调函数 buffer_head() 调用后,缓冲区首部和页面都有可能被 bounce_end_io() 回收。如果紧急池没有满,则资源会被加入到池中,否则它们就会被释并放回各自的分配器。
9.6 紧急池
为了快速使用弹性缓冲区,系统提供了 buffer_head 的两个紧急池以及相应的页面。由于高端内存的缓冲区不能等到低端内存可用时才释放,如果对分配器而言内存过于紧张,这时分配器无法完成请求的 I/O 操作,就会出现这种情况。这会导致操作失败,也可能会阻止这些操作释放它们的内存。
紧急池由 init_emergency_pool() 初始化,每个池包含 POOL_SISE 项。页面通过一个 pagelist 字段相互链接在一个以 emergency_pages 为首部的链表上。图 9.5 说明了在紧急池中如何存储页面和如何在需要时获得页面。
buffer_head 与之非常相似,因为它们也通过 buffer_head→inode_buffers 链接到一个以 emergency_bhs 为首部的链表上。页面和缓冲区链表中剩余的项数分别由两个计数器 nr_emergency_pages 和 nr_emergency_bhs 记录,而且这两个列表由一个叫 emergency_lock 的自旋锁保护。
9.7 2.6 中有哪些新特性
内存池
在 2.4 中,高端内存管理器是惟一维护紧急池中页面的子系统。2.6 中实现了内存池,它是当内存紧张时需要保留的对象的一般概念。这里的对象可以是任何对象,如除高端内存管理器中的页面外,更多的是由 slab 分配器管理的一些对象。系统使用 memppool_create() 来初始化内存池,它需要有如下参数:需要保留对象的最小值(min_nr),一个对象类型的分配函数(alloc_fn() ),一个对象类型的释放函数(free_fn() ),以及一些用于分配和释放函数的可选的私有数据。
内存池 API 提供两类分配和释放函数,分别叫做 mempool_alloc_slab() 和 mempool_free_slab() 。在使用这两类函数时,私有数据就是待分配和释放对象的 slab 高速缓存。
在高端内存管理器中,创建有两个页面池,其中一个页面池用于普通的页面池,另外一个用于 ISA 设备 。ISA 设备必须从 ZONE_DMA 中分配,其分配函数是 page_pool_alloc() ,所传递的私有数据参数表明 GFP 标志位是否使用,而释放函数是 page_pool_free() 。这样内存池就代替了 2.4 中紧急急池的那部分分代码。
在从紧急池中分配或释放对象时,系统提供了内存池 API 函数 mempool_alloc() 和 mempool_free() 函数。另外系统调用 mempool_destroy() 释放内存池。
映射高端内存页面
在 2.4 中,字段 page→virtual 用于存储 pkmap_count 数组中的页面地址。由于在高端内存系统中结构体 pages 的数量很多,所以相对而言就有很多较小的页面需要映射到 ZONE_NORMAL 中,2.6 中也有这样一个 pkmap_count 数组,但是如何管理它就与 2.4 有很大不同。
在 2.6 中创建了一个 page_address_htable 的哈希表,这个表基于结构体 page 的地址做哈希操作,另外使用了一个列表来定址结构体 page_address_slot。我们感兴趣的是 struct page 中的两个字段,一个是 struct page,另一个是虚拟地址。当内核需要一个映射页面的虚拟地址时,系统就遍历这个哈希桶。至于页面如何映射到低端内存,这实际上与 2.4 中相似,但 2.6 中不再需要 page->virtual。
进行 I/O
最后一个改变是在进行 I/O 时,最主要的是使用了 struct bio 来代替结构体 buffer_head。bio 结构的工作原理已经超出了本书的范围。需要说明的是,这里引入 bio 结构的主要原因是无论底层的设备是否支持,都可以进行以块为单位的 I/O 操作。在 2.4 中,无论底层设备的传输速率如何,所有的 I/O 操作都被分解为页面大小。
第10章 页面帧回收
由于磁盘缓冲区、目录表项、索引节点项、进程页面以及其他的原因,运行中的系统最终会使用完所有可用的页面帧。因此,Linux 需要在物理内存耗尽前选择旧的页面进行释放,以使这些页面失效而待重新使用。这一章主要集中讨论 Linux 如何实现页面替换策略以及如何让不同类型的页面失效。
本质上,Linux 选择页面的方法在一定程度上是凭经验的,而其背后的理论基础基于多种不同的策略。在实际过程中这些方法运行良好,并且它们根据用户的反馈和基准测试在不断地进行调整。在这一章中,首先要讨论的话题是页面替换策略的基础。
第 2 个要讨论的话题是页面高速缓存。所有从磁盘读出来的数据都存储在页面高速缓存中,以此来减少磁盘 I/O 的次数。严格意义上,这和页面帧回收并没有什么直接的联系,但是 LRU 链表和页面高速缓存却是密不可分的。相关的章节会集中讨论页面如何添加到页面高速缓存中以及如何被快速定位。
接下来是第 3 个话题,LRU 链表。除了 slab 分配器,系统中所有正在使用的页面都存放在页面高速缓存中,并由 page→Iru 链接在一起,所以很容易就可以扫描并替换它们。slab 页面并没有存放在页面高速缓存当中,因为人们认为基于被 slab 所使用的对象来对页面计数是很困难的。
在这个部分,会谈及页面如何依附于其他高速缓存。在谈到进程映射如何被移除之前,诸如 dcache 和 slab 分配器这样的高速缓存应当被回收。进程映射页面并不容易进行交换,这是因为除了采用查找每个页表这种手段以外没有其他的方法能把结构页面映射为 PTE,而且查找每个页表的代价也是非常大的。如果页面高速缓存中存在大量的进程映射页面,系统将会遍历进程页表,然后通过 swap_out() 函数交换出页面直至有足够的页面空闲,然而 swap_out() 函数依旧会因为共享页的缘故而带来问题。如果一个页面是共享的,同时一个交换项已经被分配,PTE 就会填写所需的信息以便在交换分区里重新找到该页并将其引用计数减 1。只有当引用计数减到零时,这个页面才被替换出去。诸如此类的共享页面都会在交换高速缓存部分涉及到。
最后,这个章节同样会涉及页面替换守护程序 kswapd,并讨论它的实现和职责所在。
10.1 页面替换策略
在讨论页面替换策略时讲的最多的便是基于最近很少使用的算法(LRU),但严格意义上,这并不是正确的,因为这里的链表并不是严格地按照 LRU 顺序来保持的。Linux 中的 LRU 链包含两个链,分别是 active_list 和 inactive_list。active_list 上的对象包含所有进程的工作集 [Den70],而 inactive_list 则包含需要回收的候选对象。由于所有可回收的页面都仅存在于这两个链表中,并且任何进程的页面都可被回收,而不仅仅局限于那些出错的进程,因此替换策略的概念是全局的。
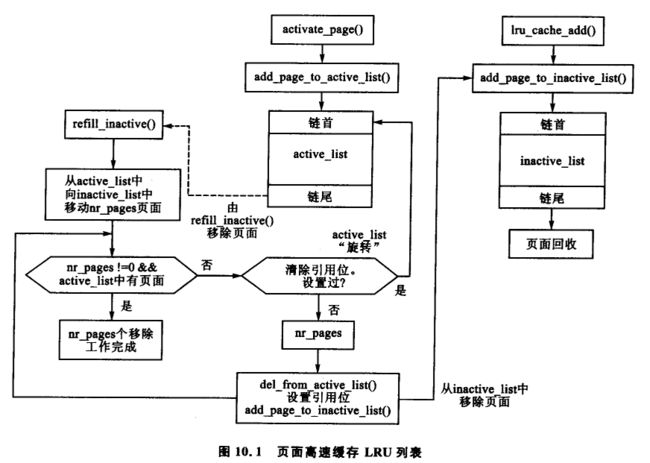
这两个列表很像一个简化了的 LRU 2Q[JS94],其中分别维护着两个叫做 Am 和 A1 的链表。在 LRU 2Q 中,第一次分配的页面被放置在一个叫做 A1 的先进先出(FIFO)队列中。如果被引用的页面同时也在那个队列中,它们就会被放置到一个叫做 Am 的普通 LRU 链表中。 这与使用 lru_cache_add() 函数把页面放到一个叫 inactive_list(AD) 的队列中及使用 mark_page_accessed() 函数把页面移到 active_list 中(Am)的方式有点相似。这个算法描述了两个链表的大小是如何相互变化的,但是 Linux 采用了一种更加简单的方法:使用 refill_inactive() 函数把页面从 active_list 尾部移到 inactive_list,以确保 active_list 约占总页面高速缓存大小的 2/3。图 10.1 图解了如何构造这两个列表表,并阐明了如何添加页面以及如何通过 refill_inactive() 函数在两个链表之间移动。
2Q 所描述的链表假定 Am 是一个 LRU 链表,而 Linux 中的链表更像是一个时钟算法 [Car84],其中时针是 active_list 的大小。当页面到达链表的底部时,就会检查引用的标志位。如果设置了引用的标志位,则该页面会被移回到链表的顶部,然后检查下一个页面。如果没有设置,则该页面会被移到 inactive_list。
这种前向试探的方法意味这些链表的行为像 LRU 一样,但是 Linux 替换策略和 LRU 还是有很多不同之处的,一般认为后者是栈式算法 [MM87]。即使我们忽略掉这是在分析多道程序系统的问题,同时也不考虑每个进程所占内存大小不固定的情况 [CD80],这种策略也不满足内含特性,因为链表中页面的位置主要取决于链表的大小,这和最后一次被引用时是相反的。因为需要链表按每次的引用来进行更新,所以链表的优先级也没有排序。在整个找算法框架中,当从进程中换出页面时,链表的关键地位几乎被忽略掉了,它的换出取决于进程在虚拟地址空间的位置,而不是页面在链表中的位置。
总而言之,这种算法的确表现得像 LRU 一样,而且基准测试中已经表明它在实际使用过程中运行良好。只有 2 种情况下这种算法才可能表现得很差。第 1 情况是如果待回收的页面主要是匿名页面,在这种情况下,Linux 会连续检查大量的页面,而这将在线性扫描进程页表以搜索待回收的页面之前完成。幸运的是,这种情况极为少见。
第 2 种情况是在某个单进程中,系统频繁地写在 inactive_list 上的许多对应于文件的常驻页面中。进程和 kswapd 可能会进入一个循环过程,持续地调换这些页面并把它们放到 inactive_list 的首部,却没有释放任何东西。在这种情况下,由于这两个链表的大小没有明显的改变,几乎没有页面会从 active_list 移到 inactive_list 中。
10.2 页面高速缓存
页面高速缓存是一个包含页面的数据结构集,这些页面对应于普通文件、块设备或交换分区。在高速缓存中,基本上存在四种类型的页面:
- 读内存映象文件时所产生的页面碎片。
- 从块设备上读出的块,或从文件系统中读出的块,它们都被封装到一个成为缓冲区页面的特殊页面中。块的数量随块大小和系统中页面大小而变化。
- 在第 11 章中将讨论匿名页面,这些页面存放于一种称为交换高速缓存的特殊页面高速缓存中,交换高速缓存在后援存储器中分配槽的时候用于换出页面。
- 属于共享内存区的页面在处理方式上和匿名页面类似。它们之间惟一的区别是在第一次写到页面后,共享页面才被添加到交换高速缓存中,并马上在后援存储设备中保留一份空间。
高速缓存存在的主要原因是为了减少不必要的读磁盘操作。从磁盘读出的页面被存储在一个基于 address_space 结构和偏移地址的页面哈希表里,在磁盘访问前都要先查找这个表。把页面放入这个高速缓存有两个原因:第一个原因是为了减少不必要的读磁盘操作。从磁盘读出的页面是存放在一个基于 address_space 结构和偏移地址的页面哈希表中的,第二个原因是由于页面高速缓存中具有队列,这就为磁盘替换算法选择丢弃或换出页面打下了基础。这里提供了一个负责操作页面高速缓存的 API 函数,如表 10.1 所列。

10.2.1 页面高速缓存哈希表
系统要求被快速地定位在高速缓存中的页面。为了简化这一点,页面都被插入了一个叫 page_hash_table 的表中,而 page->next_hash 和 page→pprev_hash 则用于处理冲突。
该表在 mm/filemap.c 中声明如下:
atomic_t page_cache_size = ATOMIC_INIT(0);
unsigned int page_hash_bits;
struct page **page_hash_table;
在系统初始化时,函数 page_cache_init() 将系统中物理页面的数量作为一个参数,并分配该表。该表所申请的大小(htable_size)足够保存系统中每个结构页面的指针,它的计算公式如下:
htable_size=num_physpages * sizeof(struct page * )
为了分配这样一个表,系统首先分配一块足够大的顺序空间来存放整个表。它从 0 开始计算并逐步增大该值,直到 2order > htable_size。这大致可以用下列简单方程的整数部分来粗略地表示:
o r d e r = l o g 2 ( ( h t a b l e _ s i z e ∗ 2 ) − 1 ) order = log_2((htable\_size * 2)-1) order=log2((htable_size∗2)−1)
系统尝试使用 __get_free_pages() 来分配这些顺序页面。如果分配失败,则尝试分配序号较小的页面,如果同样没有可以分配的页面,则系统瘫痪。
page_hash_bits 的值是基于表的大小的,并被哈希函数 _page_hashfn() 所使用。 这个值通过连续除以 2 得到,如果是在实数域,它等于
p a g e _ h a s h _ b i t s = l o g 2 ∣ P A G E _ S I Z E ∗ 2 o d e r s i z e o f ( s t r u c t p a g e ∗ ) ∣ page\_hash\_bits = log_2 \mid \frac{PAGE\_SIZE * 2^{oder} } {sizeof(struct\ page\ * )} \mid page_hash_bits=log2∣sizeof(struct page ∗)PAGE_SIZE∗2oder∣
这样就使得该表是一个 2 的幂次哈希表,从而避免了在哈希函数中经常使用的取模运算。
10.2.2 索引节点队列
// include/linux/fs.h
struct address_space {
struct list_head clean_pages; /* list of clean pages */
struct list_head dirty_pages; /* list of dirty pages */
struct list_head locked_pages; /* list of locked pages */
unsigned long nrpages; /* number of total pages */
struct address_space_operations *a_ops; /* methods */
struct inode *host; /* owner: inode, block_device */
struct vm_area_struct *i_mmap; /* list of private mappings */
struct vm_area_struct *i_mmap_shared; /* list of shared mappings */
spinlock_t i_shared_lock; /* and spinlock protecting it */
int gfp_mask; /* how to allocate the pages */
};
索引节点队列是 address_space 结构中的一部分,这在 4.4.2 小节中已有介绍。该结构包含三个链表:clean_pages 是一个由干净页面组成的链表,这些页面均与索引节点相关;dirty_pages 是一个由自从链表与磁盘同步以来已经被写过的页面所组成的链表;locked_pages 则是由那些正处于锁定状态的页面所组成的。这三种链表合起来被认为就是给定的某种映射的索引节点队列,并且 page→list 字段用来链接队列上的页面。页面通过 add_page_to_inode_queue() 函数添加到索引节点队列中的 clean_pages 链表上,并通过 remove_page_from_inode_queue() 函数完成移出操作。
10.2.3 向页面高速缓存添加页面
从文件或块设备读取页面时,通常将页面添加到页面高速缓存中以避免更多的磁盘 I/O。大多数的文件系统都使用较高层次的函数 generic_file_read() 来完成它们的 file_operations→read() 操作,如图 10.2 所示。在第 12 章中涉及的共享内存文件系统,是一个值得关注的例外。 一般情况下,文件系统都是通过页面高速缓存来进行它们的操作的。在这一节中,我们介绍 generic_file_read() 如何完成操作,以及如何把页面添加到页面高速缓存中的。

对于普通 I/O,generic_file_read() 函数在调用 do_generic_file_read() 函数之前会进行少量的基本检查工作。通过调用 __find_page_nolock() 函数并上锁 pagecache_lock 来搜索页面高速缓存,以查看该页面是否已经存在于高速缓存中。如果不在,一个新的页面将通过 page_cache_alloc() 函数分配,其过程一般通过 alloc_pages() 函数封装后再通过 __add_to_page_cache() 函数添加到页面高速缓存中。在页面高速缓存中形成页面帧后,再通过调用 generic_file_readahead() 函数(实质上是调用 page_cache_read() 函数)从磁盘读取页面。 它使用 mapping→a_ops→readpage() 这样的方法来读取页面,其中 mapping 指的是管理文件的 address_space。readpage() 函数是用来从磁盘读取页面的文件系统专有函数。
若没有进程与匿名页映射,系统会将匿名页添加到交换高速缓存中,这将在 11.4 节有更进一步的讨论。持续地尝试将它们换出时,由于它们没有可用来映射的 address_space 或者文件中的任何偏移量,这样将无法把它们添加到页面高速缓存的哈希表中。即便如此,也要注意到这些页面依旧存在于 LRU 链表中。一旦进入交换高速缓存中,匿名页面和有文件后援的页面之间的惟一实际差异便是匿名页面采用 swapper_space 作为其 struct address_space。
共享内存页面在下面两种情况下会被添加到页面高速缓存中。第 1 种情况是在调用
shmem_getpage_locked() 函数时,不论它是从交换分区中取出或者是在其中分配页面,其原因就是该页面是第 1 次被引用。第 2 种情况是当换出代码调用 shmem_unuse() 函数时。当一个交换分区被禁止时以及一个有后援交换区的页面被发现不属于任何进程时就会出现第 2 种情况。与共享内存相关的索引节点都会被穷尽搜索,直至找到正确的页面。在这两种情况下,add_to_page_cache() 函数将会把该页面添加到页面高速缓存中,如图 10.3 所示。

10.3 LRU 链表
正如 10.1 节中所谈到的,LRU 链表包含两个链表,一个称为 active_list,而另一个称为 inactive_list。它们在 mm/page_alloc.c 中声明,并由 pagemap_lru_lock 自旋锁保护。一般地,它们分别存储着经常使用和不经常使用的页面,或者说,active_list 包含系统中所有的工作集,而 inactive_list 则包含回收候选集。在表 10.2 中列出了操作 LRU 链表的 API 函数。

10.3.1 重新填充 inactive_list
在高速缓存收缩时,refill_inactive() 函数会把页面从 active_list 移到 inactive_list 中 。 它有一个参数表示移动页面的数量,该参数通过在 shrink_caches() 函数中求比率得到,而这个比率依赖于 nr_pages,即 active_list 中的页面数量,还有 inactive_list 中的页面数量。需要移动的页面数量计算公式为:
p a g e s = n r _ p a g e s ∗ n r _ a c t i v e _ p a g e s 2 ∗ ( n r _ i n a c t i v e _ p a g e s + 1 ) pages = nr\_pages * \frac{nr\_active\_pages } {2 *(nr\_inactive\_pages +1)} pages=nr_pages∗2∗(nr_inactive_pages+1)nr_active_pages
这样可以保证 active_list 大约是 inactive_list 大小的 2/3,要移动的页面数量是由一个基于我们需要换出的页面数量(nr_pages)的比率决定的。
页面从 active_list 的尾部取出。如果设置了 PG_referenced 标志位,则该标志位要被清除,然后将页面放置到 active_list 的首部,因为它最近被使用过且依旧活跃。这种情况有时被称为链表旋转。如果没有设置该标志位,则该页面被移到 inactive_list,PG_referenced 标志位会被设置,这样使得该页面在需要时能很快地添加到 active_list 中。
10.3.2 从 LRU 链表回收页面
shrink_cache() 函数是替换算法的一部分,它把页面从 inactive_list 中取出,并决定它们应该如何被换出。nr_pages 和 priority 用于决定多少工作需要做的初始参数。nr_pages 初始值为 SWAP_CLUSTER_MAX,目前在 mm/vmscan.c 中定义为 32。而 priority 的初始值为 DEF_PRIORITY,目前在 mm/vmscan. c 中定义为 6。
max_scan 和 max_mapped 这两个参数决定了该函数要做多少工作,并根据 priority 调整。每当没有足够的空闲页面却又调用了 shrink_caches() 函数时,priority 会逐渐减小直至达到最高优先级 1。
变量 max_scan 表示该函数扫描的最大页面数,它可简单计算如下
m a x _ s c a n = n r _ i n a c t i v e _ p a g e s p r i o r i t y max\_scan = \frac{nr\_inactive\_pages} {priority} max_scan=prioritynr_inactive_pages
其中 nr_inactive_pages 表示 inactive_list 中的页面数量。 这就意味着在最小优先级 6 时,inactive_list 的页面中最多只有 1/6 会被扫描到,而在最大优先级时,inactive_list 中所有页面都会被扫描到。
第二个参数是 max_mapped,它决定了在所有进程换出前,允许多少进程页面存在于页面高速缓存中。它可以在 max_scan 的 1/10 或者以下计算公式
m a x _ m a p p e d = n r _ p a g e s ∗ 2 ( 10 − p r i o r i t y ) max\_mapped = nr\_pages * 2^{(10 - priority)} max_mapped=nr_pages∗2(10−priority)
中取较小的那个值来计算。
或者说,在最低优先级时,映射页面被允许使用的最大数量是 max_scan 的 1/10 或者是待替换页面数(nr_pages)的 16 倍中那个较小的数值。 而在高优先级时,它是 max_scan 的 1/10 或是待换出页面的 512 倍。
从上面可以看出,该函数基本上是一个很庞大的 for 循环,它会从 inactive_list 的尾部开始扫描至多 max_scan 个页面,来释放掉 nr_pages 个页面,或直至 inactive_list 为空。在扫描每个页面时,它会检查是否需要重新调度它自己,以保证换出页面不会一直独占 CPU。
对于链表中每一种类型的页面,函数会作出不同的处理决定。这些不同的页面类型以及对应的处理方式如下:
-
由进程映射的页面
这会跳转到 page_mapped 标志位,稍后还会再谈到。max_mapped 计数减 1。如果 max_mapped 减到 0,进程的页表会被线性搜索并且使用 swap_out() 函数完成换出。 -
被锁定,并且 PG_launder 位也被设置了的页面
这样的页面由于在进行 I/O 而被锁定,因此应当可以直接跳过。然而,如果 PG_launder 位同时被设置了,则意味着这是第二次发现该页面被锁定,因此等 I/O 完成后再去除该页面会更好一些。该页面的引用可以通过 page_cache_get() 函数得到,以保证该页面不会被过早地释放,然后调用 wait_on_page() 函数进行睡眠,直至 I/O 完成。在 I/O 完成后,通过 page_cache_release() 函数将引用计数减 1。当引用计数减到 0 时,页面将会被回收。 -
脏页面
脏页面没有被任何进程映射,没有缓冲区,属于某个设备或文件映射。由于该页面属于某个文件或设备映射,它就有一个可用的有效函数 writepage() ,通过 page→mapping→a_ops→writepage 得到 。在开始 I/O 的时候,清除 PG_dirty 位,并设置 PG_launder 位。调用 writepage() 函数同步页面及其后援文件前,系统要调用 page_cache_get() 函数得到该页面的引用计数,而后调用 page_cache_release() 函数清除该引用。请注意,这种情况也会引起交换高速缓存中有后援存储的异步页面的同步操作,因为交换高速缓存页面使用 swapper_space 作为 page->mapping。该页面依旧在 LRU 链上。当其再度被发现时,如果 I/O 已经完成了,很容易就可以释放掉它,然后页面将被回收。如果 I/O 还没有完成,正如前面所述,内核会等待 I/O 完成。 -
具有缓冲区与磁盘数据相关联的页面
用一个引用指针指向该页面,并使用 try_to_release_page() 函数来尝试释放该页面。如果成功并且它是一个匿名页(无 page→ maping),则该页面从 LRU 链上移除,并调用 page_cache_released() 函数来减少引用计数。只有一种情况匿名页面会和高速缓存区相关联,那就是当其有后援的交换文件时,因为页面必须以块对齐的方式写出。在另一方面,如果它有后援的文件或设备,系统就可以在其计数达到 0 时,只需要简单地释放掉其引用指针,便释放掉了该页面。 -
被多个进程映射的匿名页
第一种情况里被计数的同一个 page_mapped 标志位,在被释放掉以前,解锁 LRU 链,同时解锁该页面。或者说,max_mapped 计数将减少,在其达到 0 时,调用 swap_out 函数。 -
没有被任何进程引用的页面
这是最后一种情况,但不是非得明确提出的。如果该页在交换高速缓存中,它将从交换高速缓存中移除,因为它现在正在和其后援存储器进行同步,而且没有任何的进程引用它。如果它是一个文件中的某部分,则它会从索引节点队列中移除,然后会从页面高速缓存中删除,并被释放掉。
10.4 收缩所有的高速缓存
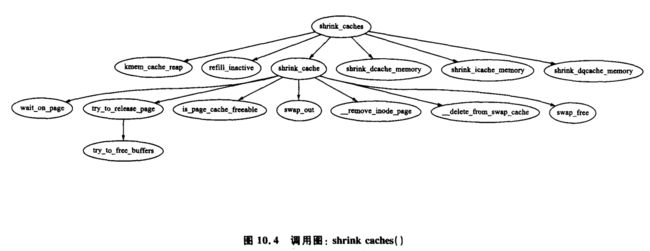
负责收缩各种高速缓存的函数是 shrink_caches(),它使用很简单的步骤释放一些内存(参考图 10.4)。任意一次允许写回磁盘的页面数量最大值是 nr_pages,它由 try_to_free_pages_zone() 函数初始化为 SWAP_CLUSTER_MAX。有了这样的限制后,如果 kswapd 调度大量的页面写回到磁盘 ,它会偶尔睡眠一下以允许 I/O 开始。随着页面的释放,nr_pages 会相应地减小。
待做的工作量也取决于 priority,它由 try_to_free_pages_zone() 函数初始化为 DEF_PRIORIRY。如果每次释放的页面不够数量,priority 会减小到最高优先级 1。
该函数会首先调用 kmem_cache_reap() 函数(见 8.1.7 小节)来选择一个待减小的 slab 高速缓存。如果释放的页面的数量达到 nr_pages,就表示工作完成了,然后函数返回。否则它会试着从其他高速缓存中释放页面以达到 nr_pages 个。
如果没有涉及到其他的高速缓存,在调用 shrink_cache() 函数来从 incative_list 尾部回收页面以减小页面高速缓存以前,refill_inactive() 函数会将页面从 active_list 移到 inactive_list。
最后, 它会减小三种特殊的高速缓存:dcache(shrink_dcache_memory() ) 高速缓存,icache(shrink_icache_memory() ) 高速缓存以及 dqcache(shrink_dqcache_memory() ) 高速缓存。这些对象本身都很小,但是级联效应会使大量的页面以缓冲区和磁盘高速缓存的形式释放。
10.5 换出进程页面
如图 10.5 所示,当在页面高速缓存中找到了 max_mapped 个页面时,swap_out() 就会被调用以启动换出进程页面的操作。系统从 swap_mm 指向的 mm_struct 和 mm->swap_address 地址开始向前搜索页表,直到释放 nr_pages 个页面。
除了 active_list 部分的页面和最近被引用的页面会被跳过外,进程映射的页面不管处于链表中的哪个位置,也不管什么时候被最后引用过,都会被检查。检查激活状态页面的开销是不小的,但是与为了获得引用某一结构页面的 PTE 而线性查找所有进程的开销比起来,这种开销又是微不足道的。
一旦决定了要换出某个进程的页面,就会试图换出至少 SWAP_CLUSTER 个页面,并且 mm_struct 的整个链表仅会被检查一遍,这样避免了在没有页面时无休止地循环。大块写出页面增加了在进程地址空间近邻的页面写到相邻磁盘槽的几率。
标志位 swap_mm 被初始化以指向 init_mm,而 swap_adress 在首次使用时被初始化为 0。 当 swap_address 等于 TASK_SIZE 时,说明某个进程已经被完全地搜索了一遍。一旦选择从某个进程换出页面,它的 mm_struct 的引用指针增加 1,使得它不会过早地被释放。然后系统会以选定的 mm_struct 作为参数来调用 swap_out_mm() 。这个函数遍历该进程持有的每个 VMA,并且在其上调用 swap_out_vma()。这样就避免了必须遍历整个很稀疏的页表的情形。swap_out_pgd() 和 swap_out_pmd() 遍历给定 VMA 的页表直到最后在实际页面以及 PTE 上调用 try_to_swap_out() 。
函数 try_to_swap_out() 首先检查以确保该页面或者不是 active_list 的一部分,或者该页面最近被引用过了,或者是我们并不关心的某个管理区的一部分。一旦确定了这是一个待换出的页面,该页面便会从该进程的页表中移出。接着检查刚移除的 PTE 以确定它是否是脏页面。如果它是脏页面,则会更新 struct page 标志位来反映这一点,以使它与后援存储设备同步。如果该页面已经在交换高速缓存中,就更新它的 RSS 位,并去掉对它的引用。否则,就把该页面加入到换出高速缓存中。在后援存储设备上分配空间和换出页面的过程将在第 11 章进一步讨论。
10.6 页面换出守护程序(kswapd)
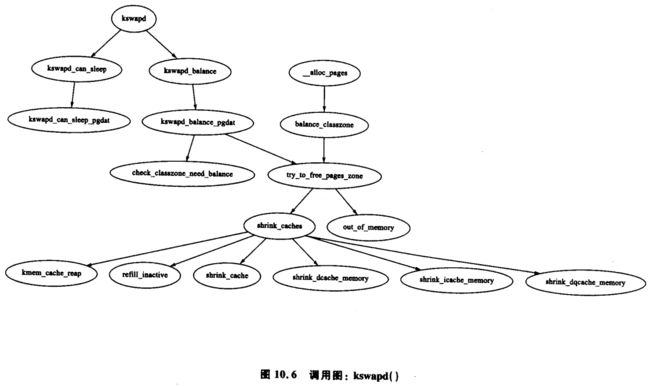
在系统启动时,一个 kswapd 的内核线程从 kswapd_init() 中启动。大多数情形下它都处于睡眠状态,一旦运行,它就不断地执行在 mm/vmscan.c 中的 kswapd() 函数。这个守护程序负责在内存大小剩下很少时回收页面。从历史经验上来看,kswapd 经常是每 10 s 被唤醒一次。现在它由物理页面分配器在管理区中空闲页的 pages_low 大小达到了某个值时唤醒(见 2.2.1 小节)。
正是这个守护程序完成了大多数诸如保持页面高速缓存正确,收缩 slab 高速缓存并在需要的时候替换出进程的任务。与 Solaris[MM01] 中的替换守护程序不同,kswpad 不是随着内存压力的增大而增加被唤醒的频率,而是不断地在释放页面直到空闲页的 pages_high 大小达到阀值。在极端的内存压力下,所有的进程会通过调用 balance_classzone(),然后 balance_classzone() 调用 try_to_free_pages_zone(),来同步地完成 kswapd 的工作。在图 10.6 中,当物理页面分配器在和 kswapd 同步相同的任务量,分配处于重负的管理区时也会调用 try_to_free_pages_zone()。
当 kswapd 被唤醒时,它执行下列步骤:
- 调用 kswapd_can_sleep(),它遍历所有的管理区,检查在结构 zone_t 中的 need_balance 字段。如果有 need_balance 被设置,则它不能睡眠。
- 如果不能睡眠,则会被移出 kswapd_wait 等待队列。
- 调用 kswapd_balance(),它遍历所有的管理区。如果 need_balance 字段被设置,它将使用 try_to_free_pages_zone() 来释放管理区内的页面,直到达到 pages_high 阀值。
- 由于 tq_disk 的任务队列的运行,所以页面队列都将清除。
- 将 kswapd 重新加入 kswapd_wait 队列并且返回第一步。
10.7 2.6 中有哪些新特性
守护进程 kswapd
如同已经在 2.8 节中说过的一样,现在系统中每一个内存节点都拥有一个 kswapd。这些守护进程现在仍然由 kswapd() 启动,它们执行一样的代码,但是现在它们都只限于在局部的节点上执行。2.6 中 kswapd 的改变主要与 kswapd-per-node 的改变有关。
kswapd 的基本操作没有变。一且该守护进程被唤醒,它就会在其监管的 pgdat 上调用 balance_pgdat() 。balance_pgdat() 有两中操作模式。如果以 nr_pages == 0 的条件调用,则它就会不断地试着释放局部 pgdat 中各个管理区的页面,直到达到了 pages_high 的值。如果以某个 nr_pages 的条件调用,则它就会不断地试着释放 nr_pages 和 MAX_CLUSTER_MAX * 8 中那个较小值的页面。
平衡管理区
balance_pgdat() 释放页面时调用的两个主要函数是 shrink_slab() 和 shrink_zone() 。shrink_slab() 在 8.8 节中已经讨论过了,不再重复。balance_pgdat() 调用函数 shrink_zone() 来释放一定数量的页面,所要释放页面的确切数量取决于释放页面的紧急程度。该函数与 2.4 中的几乎一样。refill_inactive_zone() 用于把一定数量的页面从 zone→active_list 移到 zone→inactive_list 中。注意在 2.8 节中说过,2.6 中的 LRU 链表是每个区域都有的,与 2.4 中 LRU 链表是全局的情况不同。系统调用 shrink_cache() 移出 LRU 中的页面并且回收。
页面换出压力
2.4 中页面换出操作的优先级由扫描的页面数量决定。2.6 中由 zone_adj_pressure() 调整 zone→pressure 字段指示为替换而需要扫描的页面数量,而这个调整通常是逐渐减弱的。当需要更多的页面时,zone→pressure 的值就会达到最高值 DEF_PRIORITY << 10,然后随着时间慢慢降低。通常这个值影响着为替换而需要在管理区中扫描的页面数量。这样做的目的是启动页面替换然后逐渐降低压力,而不是短时间突然进行大量替换。
控制 LRU 链表
2.4 中当需要从 LRU 链表中移出页面的时候就需要获得一个自旋锁,这样就会引起很激烈的加锁竞争。所以,为了缓解这种竞争程度,2.6 中使用了 struct pagevec 结构来处理涉及到 LRU 链表的操作,允许在 LRU 链表中批量加入或移出多达 PAGEVEC_SIZE 个页面。
具体情形是这样的,当 refill_inactive_zone() 或 shrink_cache() 要移出页面 时,它们先获得 zone→lru_lock 锁,然后移出一部分页面,并把它们存储在一个临时链表中。系统只在要移出的页面链表组织好以后,才会调用 shrink_list() 进行实际的页面释放工作,这个过程中大部分工作不需要获得 zone→lru_lock 锁就可以完成。
当要加入页面时,系统就会调用 pagevec_init() 来初始化一个新的页面向量结构体,然后调用 pagevec_add() 将所有要加入的页面加入到这个向量中,接着调用 pagevec_release() 成批地加入到 LRU 链表中。
相当一部分与 pagevec 结构体有关的 API 声明可以在
第11章 交换管理
由于 Linux 使用空闲内存作硬盘数据的缓冲,所以就有必要释放进程所占用的私有页面或匿名页面。这些页面与普通磁盘文件中的页面不同,不能简单地将它们先丢弃,将来再读取。取而代之的是 Linux 把这些页面复制到后援存储器,有时也称为交换区。本章详细介绍 Linux 如何使用和管理后援存储器。
严格意义上,Linux 并不进行交换操作,字面意义上的 “交换” 通常是指复制整个进程地址空间到磁盘,而 “换页” 指的是复制出单独的页面。实际上在当前硬件的支持下,Linux 实现的是换页,也就是传统意义上讨论的文档中所谓的交换。为了与 Linux 中对这个词的使用惯例一致,这里也称之交换。
存在交换区有两个主要原因。首先,交换区扩充了内存以供进程使用。虚拟内存和交换区的存在使得一个大型的进程即使部分常驻内存也可以运行。由于可能换出旧的页面,以及请求换页要确保页面在必要时能重新载入,所以被访问的内存可能很名易就超过 RAM 的大小。
某些读者可能会认为只要内存容量足够大,就不需要交换区。这就引出了我们需要交换区的第二个原因。一个进程在开始运行时所引用的大量页可能只是为了初始化,在后来的运行期间这些页面将不再使用。把这些页面交换出去可以空闲出更多的磁盘缓冲区,这样做比把它们常驻内存却不使用更能提高系统效率。
这并不是指交换区没有缺点。最重要也是最明显的缺点是访问磁盘的操作非常耗时。若没有交换区和高性能磁盘,那些频繁访问大量内存的进程就只可能在较大内存的支持下才能在合理的时间内完成。所以,正如我们在第 10 章所讨论的一样,如何选择正确的页面交换出去是非常重要的。同样,这也是为什么相关的页面应该存放在交换区毗邻位置的原因,因为这样进程在预读的时候能同时把相关页面换入内存。下面我们从 Linux 如何描述一个交换区开始。
本章首先讲述 Linux 所维护的每个活动交换区的结构以及如何在磁盘上组织交换区信息。然后是 Linux 如何在页面换出后的交换区定位该页,以及如何分配交换槽。接下来讨论交换高速缓存,它对共享页面非常重要。最后本章可以让你了解到如何激活和禁止交换区,内存的页面如何换出到交换区又如何换入到内存,以及如何读写交换区。
11.1 描述交换区
每个活动的交换区,无论是一个文件或分区,都由一个 swap_info_struct 结构描述。系统中该结构都存储在一个静态声明的 swap_info 数组中,它有 MAX_SWAPFILES(一般被定义为 32)个元素项。这意味着运行系统中最多存在 32 个交换区。swap_info_struct 结构在
/*
* The in-memory structure used to track swap areas.
*/
struct swap_info_struct {
unsigned int flags;
kdev_t swap_device;
spinlock_t sdev_lock;
struct dentry * swap_file;
struct vfsmount *swap_vfsmnt;
unsigned short * swap_map;
unsigned int lowest_bit;
unsigned int highest_bit;
unsigned int cluster_next;
unsigned int cluster_nr;
int prio; /* swap priority */
int pages;
unsigned long max;
int next; /* next entry on swap list */
};
下面我们简要解释这个比较大的结构的每个字段。
-
flags:有两个可取的值。SWP_USED 表示此 swap 区域处于激活状态。SWP_WRITEOK 被定义为 3,最低两位包含了 SWP_USED。标志位为 SWP_WRITEOK 时,表示 Linux 准备对此交换区进行写操作,因为写之前必须先激活交换区。
-
swap_device:该交换区所占用的磁盘设备信息,在交换区为普通文件时,其值为 NULL。
-
sdev_lock:和 Linux 中其他结构一样,swap_info_struct 也需要保护。sdev_lock 就是一个用来保护此结构的自旋锁,它主要是保护 swap_map。它通过 swap_device_lock() 和 swap_device_unlock() 进行上锁和解锁。
-
swap_file:实际的特殊文件作为交换区被挂载到系统的 dentry。如果交换区是一个分区的话,则 swap_file 是 /dev 目录下一个 dentry。在禁止一个交换区时,此字段用于确认正确的 swap_info_struct 。
-
vfs_mount:这是设备或文件作为交换区存储位置相对应的 vfs_mode 对象。
-
swap_map:这是一个非常大的数组,其中一个项对应每个交换项,或者对应每个交换区中页面大小的槽。一个项作为页槽用户数量的引用计数。交换缓存以单个用户进行计数,这里一个 PTE 被换出到槽中时算一个用户。如果计数为 SWAP_MAP_MAX,将永久地分配该槽而如果其值为 SWAP_MAP_BAD,将不再使用该槽。
-
lowest_bit:交换区中最低的可用空闲槽,它一般在线性扫描减少搜索空间时开始。由此可知不可能有空闲槽低于该标记值。
-
highest_bit:交换区中最高的可用空闲槽。如同 lowest_bit,高于该标记值不可能有空闲槽。
-
cluster_next:下一个被使用的簇块偏移量。交换区通过在簇块中分配页面,使得相关页能有机会存储在一起。
-
cluster_nr:簇内剩余的供分配的页面数量。
-
prio:每个交换区都有一个优先级,就存储在该字段里面。交换区按照优先级顺序进行组织,并决定如何使用它们。缺省状态下,系统按照活跃程度的顺序来分配优先级,当然系统管理员也可以使用 swapon-f 来指定优先级。
-
pages:由于可能不能使用交换文件中某些页面,此字段用于记录交换区中可用的页面数量。该值不同于 max,因为标记为 SWAP_MAP_BAD 的槽并没有计数。
-
max:交换区中槽的总数。
-
next:swap_info 数组中用于指向系统中下一个交换区的下标。
虽然这个交换区存放在一个数组中,但它同时也存放在一个称为 swap_list 的伪链表中,它是一个很简单的类型,在
struct swap_list_t {
int head; /* head of priority-ordered swapfile list */
int next; /* swapfile to be used next */
};
swap_list_t→head 字段使用具有最高优先级的交换区。swap_list_t→next 是下一个将被使用的交换区。尽管搜索一个合适的交换区要按照优先级顺序,但在必要的情况下,在数组中查询速度还是很快。
每个交换区在磁盘上都划分出大量页面大小的槽。例如在 X86 机上,每个页面大小为 4096 个字节。第一个槽由于存放有交换区的基本信息,故被保留且不可写。该交换区的第一个 1 KB 用于存放分区的磁盘标签,为用户空间的工具提供信息。剩下的空间用于存放交换区的其他信息,在系统程序 mkswap 创建交换区时,这些剩余的交换区将被填充。交换区的信息由一个 union swap_header 表示,在
/*
* Magic header for a swap area. The first part of the union is
* what the swap magic looks like for the old (limited to 128MB)
* swap area format, the second part of the union adds - in the
* old reserved area - some extra information. Note that the first
* kilobyte is reserved for boot loader or disk label stuff...
*
* Having the magic at the end of the PAGE_SIZE makes detecting swap
* areas somewhat tricky on machines that support multiple page sizes.
* For 2.5 we'll probably want to move the magic to just beyond the
* bootbits...
*/
union swap_header {
struct
{
char reserved[PAGE_SIZE - 10];
char magic[10]; /* SWAP-SPACE or SWAPSPACE2 */
} magic;
struct
{
char bootbits[1024]; /* Space for disklabel etc. */
unsigned int version;
unsigned int last_page;
unsigned int nr_badpages;
unsigned int padding[125];
unsigned int badpages[1];
} info;
};
各字段描述如下。
- magic:联合结构的 magic 字段,仅用于鉴别 magic 字符申。这个字符串的存在使得分区必定有一个可使用的交换区,并用于决定交换区的版本。如果字符串为 SWAP-SPACE,则交换文件格式版本为 1,如果为 SWAPSPACE2,则版本为 2。由于数组保留得很大,所以一般从页的末端开始读取该 magic 字符串。
- bootbits:保留区,用于存放分区信息,如磁盘标签。
- version:交换区的版本号。
- last_page:交换区中最后一个可用页面。
- nr_badpages:交换区中已知的坏页面数都存储在这个字段中。
- padding:通常一个磁盘扇区为 512 B。 version,last_page 和 nr_badpages 这 3 个字段占用了 12 B,padding 字段用于填充扇区剩下的 500 B。
- badpages:页面的剩下部分用于存放至多 MAX_SWAP_BADPAGES 个坏页槽。在系统程序 mkswap 打开 -c 开关检查交换区时,填充这些槽。
MAX_SWAP_BADPAGES 是一个编译时常数,它随着结构的改变而变化,但是根据当前的结构,由下面这个简单的公式可以知道它为 637。
M A X _ S W A P _ B A D P A G E S = P A G E _ S I Z E − 1024 − 512 − 10 s i z e o f ( l o n g ) MAX\_SWAP\_BADPAGES = \frac{PAGE\_SIZE - 1024-512 -10} {sizeof(long)} MAX_SWAP_BADPAGES=sizeof(long)PAGE_SIZE−1024−512−10
其中,1 024 是 bootlock 的大小,512 是 padding 的大小,10 是 magic 字符串的大小,其中 magic 字符串用于鉴别交换文件的格式。
11.2 映射页表项到交换项
在一个页面换出时,Linux 使用相应的页表项 PTE(page table entry)来存放足够用于再次在磁盘上定位该页的信息。很显然,PTE 本身并不能够大到精确保存交换页面位置的信息,但它只要存放交换槽在 swap_info 数组的下标以及在 swap_map 中的偏移量就够了。这正是 Linux 的处理方式。
每个 PTE,无论其结构如何,都必须大到能够存放一个 swap_entry_t 变量。swap_entry_t 在
/*
* A swap entry has to fit into a "unsigned long", as
* the entry is hidden in the "index" field of the
* swapper address space.
*
* We have to move it here, since not every user of fs.h is including
* mm.h, but mm.h is including fs.h via sched .h :-/
*/
typedef struct {
unsigned long val;
} swp_entry_t;
linux 分别提供了宏 pte_to_swp_entry() 和 swp_entry_to_pte() 来分别转换 PTE 到 swap_info 数组元素的映射和 swap_info 数组元素到 PTE 的映射。
// include/asm-i386/pgtable.h
#define pte_to_swp_entry(pte) ((swp_entry_t) { (pte).pte_low })
#define swp_entry_to_pte(x) ((pte_t) { (x).val })
在不同体系结构下 Linux 都必须可以确定 PTE 在内存还是已经换出。为了说明,我以 x86 为例。在 x86 中,swp_entry_t 中的第 0 位预留给 _PAGE_PRESENT 标志位,第 7 位预留给 _PAGE_PROTNONE 标志位,需要这两位的原因已在 3.2 节解释过。1~6 位标识 swap_info 数组中下标的类型,它由宏 SWP_TYPE() 返回。
8~31 位则代表交换文件内的页号,也就是在 swap_map 中的偏移量。在 x86 中,这意味着交换文件的页号占用 24 位,它限制了交换区大小为 64 GB。宏 SWP_OFFSET() 用于分离偏移。
为了将类型和其相应的偏移编号存放到 swp_entry_t 中,Linux 使用了宏 SWP_ENTRY() 。这些宏之间的关系如图 11.1 所示。

标识类型的那 6 位必须允许 32 位系统中存在 64 个交换区,而不是 MAX_SWAPFILES 的中限制的 32 个交换区。MAX_SWAPFILES 的限制是由于 vmalloc 地址空间有消耗。如果交换区具有可能的最大尺寸,则 swap_map 需要 32 MB(224 * sizeof(short) )空间,不要忘记每个页面都有一个短整型的引用数。在 MAX_SWAPFILES 个最大尺寸的交换文件存在时,就要 1 GB 虚拟 malloc 空间,而这样分割用户内核线性地址空间几乎是不可能的。
这意味着不值得这样为支持 64 个交换区而增加系统处理复杂度,但是在某些情况下,即使没有增加整个有效交换区,存在大量的小交换区也可以提高系统执行效率。一些现代化的机器已经拥有许多独立的磁盘,可以在这些磁盘间创建大量的独立块设备。在这种情况下,创建大量分布在磁盘间的小交换区,可以大大加强页调度过程的并行度,这对那些交换密集的应用很重要。
11.3 分配一个交换槽
所有指定大小的槽都由数组 swap_info_struct→swap_map 跟踪 ,它的元素类型为 unsigned short。在共享页且 0 页空闲的情形下,数组中每项都是一个槽使用者的引用计数。如果项值为 SWAP_MAP_MAX,则对应的页将永久保留给这个槽。尽管元素值不可能为 SWAP_MAP_MAX,但还是这样做,主要是为防止引用数溢出。如果项值为 SWAP_MAP_BAD,则对应的页将不能再使用。
寻找和分配一个交换项的任务分为两个步骤。如图 11.2 所示,首先调用高层函数 get_swap_page() 。从当前交换文件索引 swap_list_next 处开始在分配区域中寻找可分配的交换槽。找到后,记录下一个待用的交换区,并返回分配的表项。
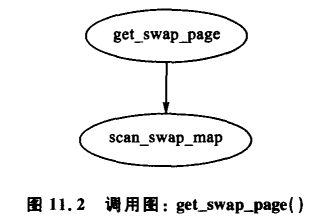
scan_swap_map() 函数负责查找交换图。原理上,这是很简单的一步,因为它线性查找空闲槽并返回,可以肯定的是,它的实现还要彻底一点。
Linux 将磁盘中的 SWAPFILE_CLUSTER 个页分配到一个簇中。它在交换区中顺序分配 SWAPFILE_CLUSTER 个页面,然后在 swap_info_struct cluster_nr 记录簇中已分配的页面数,在 swap_info_struct cluster_next 中记录交换文件当前偏移量。在分配好一个连续的块后,系统寻找一个空闲的尺寸为 SWAPFILE_CLUSTER 的表项,供下一个簇使用。如果找到了一足够大的块,系统将会把它作为另一个簇大小的序列。
如果交换区中找不到足够大的空闲族,系统将从 swap_info_struct lowest_bit 位置进行首次空闲搜索。这样做的目的是使得在同一时间交换出去的页位置靠近,当然前提是同一时间
交换出去的页是相关的。这个前提初看上去很奇怪,但若考虑到页替换算法在线性扫描交换出去页的地址空间要使用很大的交换区,就很合理了。如果不需要扫描大量的空闲块并使用它们,则扫描就会退化成首次空闲搜索,速度也不需提高。但是若需要,退出中的进程可能释放很大的块的槽。
11.4 交换区高速缓存
前面讲过,Linux 无法快速完成页面结构到每个引用它的 PTE 的映射,所以,由多个进程共享的页面不能简单地换出。这就导致如果不同步磁盘数据,就没有条件判断某个 PTE 引用的页面是否因为其他进程的换出而得到了更新,因此会丢失更新。
为了解决这个问题,共享页在后援存储器中保留一个槽作为交换高速缓存的一部分。交换高速缓存有一些与其有关的 API,如表 11.1 所列。交换高速缓存是一个纯概念性的东西,因为它只是页面高速缓存的特殊形式。页面高速缓存页面与交换高速缓存页面的一个区别是交换高速缓存总是使用 swapper_space 作为 page->mapping 的地址空间。另外一个区别如图 11.3 所示,交换高速缓存中的页面通过 add_to_swap_cache() 加到交换高速缓存中,而不是使用 add_to_page_cache()。

匿名页只有在交换出去时才是交换高速缓存的一部分。同时这意味着,系统在首次写属于共享内存区的页时才把它们加入到交换高速缓存中。变量 swapper_space 在 swap_state.c 中如下声明:
static struct address_space_operations swap_aops = {
writepage: swap_writepage,
sync_page: block_sync_page,
};
struct address_space swapper_space = {
LIST_HEAD_INIT(swapper_space.clean_pages),
LIST_HEAD_INIT(swapper_space.dirty_pages),
LIST_HEAD_INIT(swapper_space.locked_pages),
0, /* nrpages */
&swap_aops,
};


一个页面在 page mapping 设置为 swapper_space 时才成为交换高速缓存的一部分。swapper_space 是 address_space 类型,管理交换文件。宏 PageSwapCache() 测试 page mapping 是否为 swapper_space。Linux 中同步交换区和内存间页面的代码相同,因为它们都使用后援文件来实现同步。它们共享页面高速缓存代码,之间的区别仅是使用到的函数不同。
作为后援存储地址空间的 swapper_space 使用 swap_ops 作为它的 address_space->a_ops。在一般意义下,系统使用 page->index 字段而不是文件偏移来存储 swp_entry_t 结构。类型为 address_space_operations 的结构体 swap_aops 在 swap_state.c 中如下声明:
static struct address_space_operations swap_aops = {
writepage: swap_writepage,
sync_page: block_sync_page,
};
当一个页面加到交换高速缓存中后,系统调用 get_swap_page() 来分配一个可用的交换页目录项,然后使用 add_to_swap_cache() 将它加入到页高速缓存中,接着把它标志为脏数据。脏页清洗程序处理该页时,就把它写入到磁盘中。这个过程如图 11.4 所示。

接下来共享 PTE 的页交换将调用 swap_duplicate(),它仅将 swap_map 相应页的引用计数加 1。如果 PTE 由于被写过而被硬件标志为 “脏数据” ,则其对应的交换页目录项位将被清除,且页结构由 set_page_dirty 标志为 “脏页” ,这时系统在页被删除之前将进行磁盘复制同步在删除对页的所有引用之前,系统会检查磁盘数据是否和页数据一致。
在页面的引用计数最后到 0 时,该页面就可以从页面高速缓存中删除,但交换映射计数将等于磁盘槽所属的 PTE 的计数,所以该槽将不会过早地被释放掉。而是由同一个 LRU 清除并在最后销毁,这种逻辑已在第 10 章中有描述。
另一方面,如果系统在已交换到交换区的页上产生页中断,则 do_swap_page() 函数将调用 lookup_swap_cache() 检查页是否在交换高速缓存中。如果在,则更新 PTE 指向该页,将页引用计数加 1,然后调用 swap_free() 释放交换槽。
11.5 从后援存储器读取页面
读页面时的主要函数是 read_swap_cache_async(),它主要在发生缺页中断时调用,如图 11.5 所示。此函数首先调用 find_get_page() 寻找交换高速缓存。通常情况下,交换高速缓存通过 lookup_swap_cache() 函数完成查找,但该函数在更新执行的查询时也会更新统计的数量。由于需要多次查询高速缓存,所以 Linux 使用了 find_get_page() 。
如果其他进程有页面的映射,则该页面已经在交换区中或者多个进程同时都在同一页上发生缺页中断。如果交换高速缓存中不存在页面,系统就会从后援存储器中分配一页并填入数据。由于在交换高速缓存中的操作都是对页面的操作,在 alloc_page() 分配页面后,就由 add_to_swap_cache() 将其加入到交换高速缓存中。如果不能把页面加入到交换高速缓存中,系统就会再次查找一遍交换高速缓存,保证其他进程不会向交换高速缓存中加入数据。
为了从后援存储器中读入信息,它会调用 rw_swap_page(),这将在 11. 7 节讨论。在这个函数调用结束后,系统调用 page_cache_release() 释放 find_get_page() 找到的页面。

11.6 向后援存储器写页面
在向磁盘写页面时,系统就使用 address_space→a_ops 找到相应的写出函数。在使用后援存储时,address_space 即为 swapper_space,swap_aops 中就包含有交换操作 。由于 swap_aops 的写出函数的缘故,所以由 swap_aops 注册 swap_writepage() 函数,如图 11.6 所示。

函数 swap_writepage() 因为写进程是否是交换高速缓存页面的最后使用者的不同而表现为不同的操作,它通过调用 remove_exclusive_swap_page() 确定这一点。 函数 remove_exclusive_swap_page() 通过检查被操作页获取的 pagecache_lock 的数量知道页面的引用计数,从而得知是否存在其他进程也在使用被操作页。如果没有,该页将从交换高速缓存中移走并释放。
在 remove_exclusive_swap_page() 将页面从交换高速缓存中移走并释放后,因为已经不再使用该页 ,所以 swap_writepage() 将释放页锁,唤醒所有等待该锁的进程。如果页面还在交换高速缓存中,则调用 rw_swap_page() 将页的内容写到备份空间中。
11.7 读/写交换区域的块
读写交换区的高层函数是 rw_swap_page()。此函数确保所有操作在交换高速缓存中完成以避免丢失更新。rw_swap_page_base() 是完成实际工作的核心函数。
它首先检查操作是否为读。如果是,则调用 ClearPageUptodate() 清除 uptodate 标志位,因为 I/O 请求写入数据的页面显然不是过时的页面。此标志位会在页成功后从磁盘读入时再次置位。然后调用 get_swaphandle_info() 获得文件索引节点的交换分区的设备。这些是在块一级所需要的,而在这一级上有实际 I/O 操作。
核心函数既可以在交换分区运行,也可以在文件一级运行。因为它使用了块一级的函数 brw_page() 完成实际的磁盘 I/O。如果交换区是一个文件,就调用 bmap() 把操作页所在的文件系统所有块组成的列表填充为一个本地数组。请注意文件系统可能有自己存储文件和磁盘的方法,可能和磁盘分区的直接将信息写入到磁盘的方法不一致。如果后援存取区是一个分区,由于没有涉及到文件,就不需要 bmap(),这时只需要一次页面大小块的 I/O 操作。
在确定需要读入或写入一块时,系统使用 brw_page() 执行平常的块 I/O 操作。由于所有的 I/O 都是异步进行的,所以所有函数很快就可以返回。I/O 操作完成后,在块一层就会解锁页面,系统将唤醒所有处于等待状态的进程。
11.8 激活一个交换区
现在你已经知道什么是交换区,它是怎样组织以及页是怎样记录的,现在我们来看看它们是如何链接在一起以激活一个区域的。激活一个交换区的操作从概念上说很简单:打开一个文件,从磁盘获得交换首部的信息,填写 swap_info,将它加入到交换列表中。
函数 sys_swapon() 负责激活交换区。它有两个参数,交换区对应文件的路径和一组标志位。当系统激活交换区时,大内核锁(BKL,Big Kernel Lock)启动,阻止任何程序在该函数执行时进入到核心空间。该函数比较大,但可以分成下面几个简单的步骤:
-
在 swap_info 数组中找到一个空闲项,对其进行缺省初始化。
-
调用 user_path_walk(),该函数遍历提供的文件路径目录树,用文件的有效数据填充 namidata 结构,例如存放在 vfsmount 中的目录项和文件系统的信息。
-
填充涉及到交换区的大小和如何找到交换区的 swap_info 结构。如果交换区是一个分区,则块大小在计算大小之前为 PAGE_SIZE。如果是一个文件,信息直接从索引节点处获得。
-
确定空间是否未被激活。如果未激活,则从内存中分配一页并读取交换区第一页信息。这页包含很多信息,如可用槽,怎样用坏项填充 swap_info 中的 swap_map。
-
系统调用 vmalloc() 为 swap_info_struct->swap_map 分配内存,并将每个可用槽的项初始化为 0,不可用槽对应的项初始化为 SWAP_MAP_BAD。理想情况下,首部信息的文件格式为版本 2,因为版本 1 限制交换区在页大小为 4 KB 的系统结构下,小于 128 MB。如 x86 。
-
验证头节点信息与实际的交换区匹配,在这之后,在 swap_info_struct 中填充类似页面最大数量和可用页面数等其余的信息,修改全局统计参数 nr_swap_pages 和 total_swap_pages。
-
至此,交换区已激活并初始化,在交换区的逻辑列表中插入代表此交换区的新元素,仍遵循优先级排序的顺序。
在函数结束时,释放 BKL,此时系统拥有一个新的用于换页的交换区。
11.9 禁止一个交换区
与激活一个交换区比,禁止交换区的代价非常高。这主要是因为交换区不能被随便地移去,每个交换出去的页必须再次交换回来。正是由于没有快速的方法把 struct page 映射到每个引用它的 PTE 上,所以也没有快速的方法映射交换项到 PTE。这要求遍历所有的进程页表以找到需要禁止的交换区的相关 PTE,然后将其交换回去。当然,这意味着如果物理内存被禁止,此操作将失败。
可以肯定,函数 sys_swapoff() 负责禁止交换区。该函数主要是更新 swap_info_struct。try_to_unuse() 负责将每个交换出去的页交换回来,但它执行的代价非常高。在 swap_map 中所使用的每一个槽,都必须遍历进程的页表来搜索它。在极端情况下,所有属于 mm_structs 的页表都需要被遍历。因此,一般地,禁止一个交换区的任务如下:
-
调用 user_path_walk() 获得需禁止的交换文件信息,并启动 BKL 将相应的 swapinfo_struct 从交换列表中移走。并更新全局变量 nr_swap_pages(有效交换页)和 total_swap_pages(交换项总数)。完成后,释放 BKL。
-
从交换列表中释放 swap_info_struct,修改全局统计参数 nr_swap_pages(可用交换页
面数)和 total_swap_pages(交换项总数),成功后,可以以再次释放 BKL。 -
调用 try_to_unuse(),将需要禁止的交换区域中所有页交换回去。该函数遍历交换映射表并调用 find_next_to_unuse() 定位下个已用的交换页。对于找到的每个已用的页,执行下面的步骤:
-
调用 read_swap_cache_async() 为磁盘上分配保存该页的空间。理想情况下,空间应该已在交换高速缓存里分配好,若没有,将调用页分配器进行分配。
-
等待所有的页被交换回去,并对其加锁。加锁后,为每一个有引用该页的 PTE 的进程调用 unuse_process() 。该函数遍历页表查找相关的 PTE,然后更新它指向 page。如果页面是一个共享内存页,且没有其他的引用,则调用 shmem_unuse() 释放所有被永久映射的页。
-
释放那些永久性映射的存储槽,有人认为存储槽不会被永久保留,但是这种风险仍然存在。
-
如果在意外情况下交换映射表仍存在页的引用,则从交换高速缓存中删除此页以防止 try_to_swap_out() 引用该页。
-
-
如果没有足够的内存将所有的项交换回去,则不能简单地删除交换区,而是将其重新插入到系统中。如果成功地将所有项交换回去,则 swap_info_struct 处于未定义状态,swap_map 的空间将由 vfree() 释放。
11.10 2.6 中有哪些新特性
为实现扩展区,在 struct swap_info_struct 中改变的最重要的部分是增加了一个名为 extent_list 的链表,以及一个叫做 curr_swap_extent 高速缓存字段。
扩展区由 struct swap_extent 表示,它把交换区的一串连续的页面映射为磁盘上的一片磁盘块。这些扩展区由函数 setup_swap_extents() 在交换时启用。对一个块设备只启用一个扩展区,这不是为了提高性能,而是为了使系统一致对待块设备或普通文件所使用的交换区。
它们与交换文件有很大的不同,交换文件会启用多个扩展区,表示在块中连续的多个页面。当查找处于某个偏移值的文件时,系统会遍历一遍扩展区列表。为减少搜索时间,最后一次搜索的扩展区将会缓存在 swap_extent->curr_swap_extent 。