Prometheus常见问题集锦
Prometheus常见问题集锦
- 问题1:prometheus日志报错Error on ingesting out-of-order samples或者prometheus就没有报错日志,对应的采集的metrics接口都是通的,但是prometheus查询不到指标数据
- 问题2:自定义的元指标查询出来的数据和元指标内容查询出来的数据不一样
问题1:prometheus日志报错Error on ingesting out-of-order samples或者prometheus就没有报错日志,对应的采集的metrics接口都是通的,但是prometheus查询不到指标数据
#问题现象
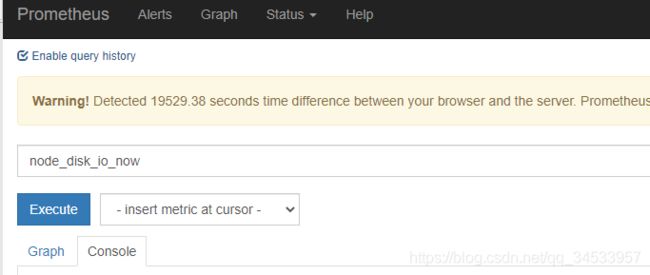
1、prometheus前端页面查询不到指标数据。
2、后台prometheus日志报错如下,
level=warn ts=2020-12-21T20:03:07.341377415Z caller=scrape.go:1053 component="scrape manager" scrape_pool=federate target="http://192.168.227.129:31090/federate?match%5B%5D=%7Bjob%3D%22prometheus%22%7D&match%5B%5D=%7Bjob%3D%22kubernetes-nodes%22%7D&match%5B%5D=%7Bjob%3D%22kubernetes-kubelet%22%7D&match%5B%5D=%7B__name__%3D~%22job%3A.%2A%22%7D&match%5B%5D=%7B__name__%3D%22up%22%7D" msg="Error on ingesting out-of-order samples" num_dropped=420
3、或者prometheus就没有报错日志,对应的采集的metrics接口都是通的,但是prometheus查询不到指标数据
#问题原因:
prometheus是安装在个人笔记本电脑的vmware虚拟机上的,有时候经常不关机,直接合上屏幕待机,这样应该造成虚拟机中断,导致数据错乱。网上百度发现此问题和时间同步有关系(https://stackoverflow.com/questions/57331750/prometheus-error-error-on-ingesting-samples)
于是乎想到我的三台虚拟机的时候未做同步,也未设置与网络同步,接下来设置下虚拟机与网络时间同步,
[root@centos-wt02 ~]# ntpdate ntp4.aliyun.com
22 Dec 09:35:01 ntpdate[86624]: step time server 203.107.6.88 offset 19529.242911 sec
[root@centos-wt02 ~]#
三台虚拟机均执行上面的命令后,再次到prometheus前端页面查询数据,发现可以查询出来数据了,问题解决。
故,在prometheus查询不到数据的时候,检查下系统时间是否一样,或者直接执行上面命令ntpdate ntp4.aliyun.com做下时间同步。
问题2:自定义的元指标查询出来的数据和元指标内容查询出来的数据不一样
#问题现象:我定义了一个元指标:app_pod_available_list,内容为:
labels_append(labels_append(label_replace(sum by(tenantId, clusterId, namespace, pod, tenant, clusterName) (kube_pod_status_ready{condition=“true”} != 0), “pod_name”, “$1”, “pod”, “(.)"), kube_pod_info, “pod”, “node”, “node”), kube_namespace_labels, “namespace”, “label_nsTenantId”, “nsTenantId”)
在prometheus中查询app_pod_available_list可以查询出来两条数据,但是使用其内容(labels_append(labels_append(label_replace(sum by(tenantId, clusterId, namespace, pod, tenant, clusterName) (kube_pod_status_ready{condition=“true”} != 0), “pod_name”, “$1”, “pod”, "(.)”), kube_pod_info, “pod”, “node”, “node”), kube_namespace_labels, “namespace”, “label_nsTenantId”, “nsTenantId”))查询出来一条数据
定位了半天还以为是prometheus那里异常了导致,数据不一致,同时,还怀疑是不是k8s etcd里面多了一条数据,
后经过定位发现是因为,前面在使用promethues的页面UI的时候提示,时间不一致,我再后台修复了时间,保持浏览器和后台服务器时间一致,但是没有重启promethues,所以,导致自定义的元指标app_pod_available_list报错“out of order sample”,从而导致数据不正确,
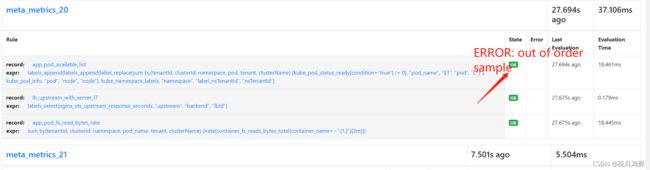
重启prometheus,问题解决了。
结论:prometheus提示IE的时间和prometheus服务器的不一致的,修复后,如果有定义的自定义规则,需要重启prometheus