Requests 基本使用看过来
Python 内置了 requests 模块,该模块主要用来发 送 HTTP 请求
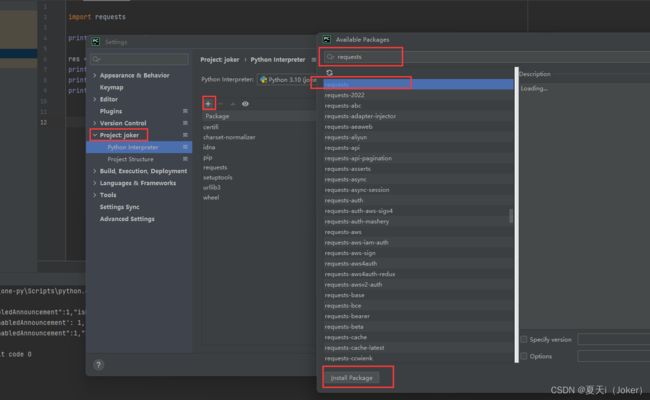
一、命令安装 requests 库
pip install requests或者Pycahrm内安装
二、基本使用
| 方法 |
说明 |
| requsts.requst() |
构造一个请求,最基本的方法,是下面方法的支撑 |
| requsts.get() |
获取网页,对应HTTP中的GET方法 |
| requsts.post() |
向网页提交信息,对应HTTP中的POST方法 |
| requsts.head() |
获取html网页的头信息,对应HTTP中的HEAD方法 |
| requsts.put() |
向html提交put方法,对应HTTP中的PUT方法 |
| requsts.patch() |
向html网页提交局部请求修改的的请求,对应HTTP中的PATCH方法 |
| requsts.delete() |
向html提交删除请求,对应HTTP中的DELETE方法 |
三、GET请求

使用get请求百度地址
# 引入 requests
import requests
# 打印 Hello Python
print("Hello Python")
# get请求 http://www.baidu.com/
res = requests.get("http://www.baidu.com/")
#打印请求响应 res.text
print(res.text)控制台内容如下,输出了百度网页信息

四、POST请求
r = requests.post('http://httpbin.org/post')
print(r.text)含参数的post请求
data = {
"name":"germey",
"age":"22"
}
r = requests.post('http://httpbin.org/post',data=data)
print(r.text)响应结果如下

五、设置请求头
url = 'http://httpbin.org/get'
data = {
"name":"germey",
"age":"22"
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0',
'my-test':'Hello'
}
r = requests.get(url, data=data, headers=headers)
print(r.text)响应结果
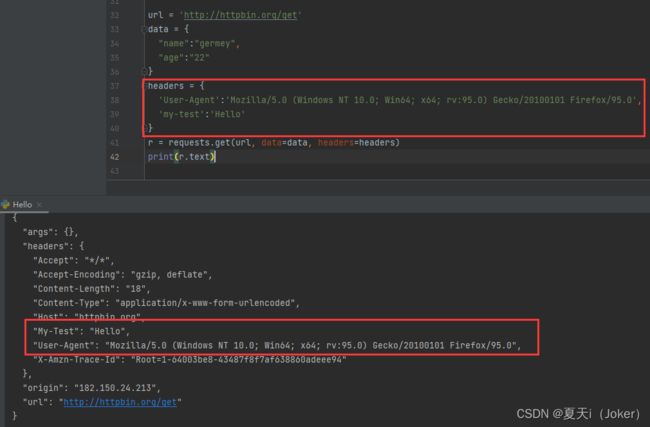
res 是一个response 对象,一个包含服务资源的对象
https://www.runoob.com/python3/python-requests.htm
六、响应属性:
import requests
r = requests.get('https://www.baidu.com/')
#响应内容(str类型)
print(type(r.text),r.text)
#响应内容(bytes类型)
print(type(r.content),r.content)
#状态码
print(type(r.status_code),r.status_code)
#响应头
print(type(r.headers),r.headers)
#Cookies
print(type(r.cookies),r.cookies)
#URL
print(type(r.url),r.url)
#请求历史
print(type(r.history),r.history) requests.codes对象拥有的状态码如下:
#信息性状态码
100:('continue',),
101:('switching_protocols',),
102:('processing',),
103:('checkpoint',),
122:('uri_too_long','request_uri_too_long'),
#成功状态码
200:('ok','okay','all_ok','all_okay','all_good','\\o/','√'),
201:('created',),
202:('accepted',),
203:('non_authoritative_info','non_authoritative_information'),
204:('no_content',),
205:('reset_content','reset'),
206:('partial_content','partial'),
207:('multi_status','multiple_status','multi_stati','multiple_stati'),
208:('already_reported',),
226:('im_used',),
#重定向状态码
300:('multiple_choices',),
301:('moved_permanently','moved','\\o-'),
302:('found',),
303:('see_other','other'),
304:('not_modified',),
305:('user_proxy',),
306:('switch_proxy',),
307:('temporary_redirect','temporary_moved','temporary'),
308:('permanent_redirect',),
#客户端请求错误
400:('bad_request','bad'),
401:('unauthorized',),
402:('payment_required','payment'),
403:('forbiddent',),
404:('not_found','-o-'),
405:('method_not_allowed','not_allowed'),
406:('not_acceptable',),
407:('proxy_authentication_required','proxy_auth','proxy_authentication'),
408:('request_timeout','timeout'),
409:('conflict',),
410:('gone',),
411:('length_required',),
412:('precondition_failed','precondition'),
413:('request_entity_too_large',),
414:('request_uri_too_large',),
415:('unsupported_media_type','unsupported_media','media_type'),
416:('request_range_not_satisfiable','requested_range','range_not_satisfiable'),
417:('expectation_failed',),
418:('im_a_teapot','teapot','i_am_a_teapot'),
421:('misdirected_request',),
422:('unprocessable_entity','unprocessable'),
423:('locked'),
424:('failed_dependency','dependency'),
425:('unordered_collection','unordered'),
426:('upgrade_required','upgrade'),
428:('precondition_required','precondition'),
429:('too_many_requests','too_many'),
431:('header_fields_too_large','fields_too_large'),
444:('no_response','none'),
449:('retry_with','retry'),
450:('blocked_by_windows_parental_controls','parental_controls'),
451:('unavailable_for_legal_reasons','legal_reasons'),
499:('client_closed_request',),
#服务端错误状态码
500:('internal_server_error','server_error','/o\\','×')
501:('not_implemented',),
502:('bad_gateway',),
503:('service_unavailable','unavailable'),
504:('gateway_timeout',),
505:('http_version_not_supported','http_version'),
506:('variant_also_negotiates',),
507:('insufficient_storage',),
509:('bandwidth_limit_exceeded','bandwith'),
510:('not_extended',),
511:('network_authentication_required','network_auth','network_authentication')七、爬取二进制数据
图片、音频、视频这些文件本质上都是由二进制码组成的,所以想要爬取它们,就要拿到它们的二进制码。以爬取百度的站点图标(选项卡上的小图标)为例
#向资源URL发送一个GET请求
r = requests.get('https://www.baidu.com/favicon.ico')
with open('F:\\JOKER\\favicon.ico','wb') as f:
f.write(r.content)使用open( )方法,它的第一个参数是要保存文件名(可带路径),第二个参数表示以二进制的形式写入数据。运行结束之后,可以在当前目录下发现保存的名为favicon.ico的图标。同样的,音频和视频也可以用这种方法获取。
查看文件夹中已下载成功
![]()
八、文件上传
requests可以模拟提交一些数据。假如某网站需要上传文件,我们也可以实现。
import requests
#以二进制方式读取当前目录下的favicon.ico文件,并将其赋给file
files = {'file':open('favicon.ico','rb')}
#进行上传
r = requests.post('http://httpbin.org/post',files=files)
print(r.text)九、会话维持:
通过调用get( )或post( )等方法可以做到模拟网页的请求,但是这实际上是相当于不同的会话,也就是说相当于你用了两个浏览器打开不同的页面。
如果第一个请求利用post( )方法登录了网站,第二次想获取登录成功后的自己的个人信息,又使用了一次get( )方法取请求个人信息,实际上,这相当于打开了两个浏览器,所以是不能成功的获取到个人信息的。
为此,需要会话维持,你可以在两次请求时设置一样的Cookies,但这样很繁琐,而通过Session类可以很轻松地维持一个会话。
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)首先通过requests打开一个会话,然后通过该会话发送了一个get请求,该请求用于向cookies中设置参数number,参数值为123456789;接着又使用该发起了一个get请求,用于获取Cookies,然后打印获取的内容。

十、超时设置
1.指定请求总的超时时间
#向淘宝发出请求,如果1秒内没有得到响应,则抛出错误
r = requests.get('https://www.taobao.com',timeout=1)
print(r.status_code)2.分别指定超时时间。实际上,请求分为两个阶段:连接(connect)和读取(read)。如果给timeout参数指定一个整数值,则超时时 间是这两个阶段的总和;如果要分别指定,就可以传入一个元组,连接超时时间和读取超时时间
#向淘宝发出请求,如果连接阶段5秒内没有得到响应或读取阶段30秒内没有得到响应,则抛出错误
r = requests.get('https://www.taobao.com',timeout=(5,30))
print(r.status_code)3.如果想永久等待,可以直接timeout设置为None,或者不设置timeout参数,因为它的默认值就是None。
#向淘宝发出请求,如果想永久等待,可以直接timeout设置为None,或者不设置timeout参数,因为它的默认值就是None
r = requests.get('https://www.taobao.com',timeout=None)
print(r.status_code)十一、其他:
处理Cookies / SSL证书验证 / 代理设置 / 身份验证 / Prepared Request
借鉴自文章:
requests库的使用(一篇就够了)_上善若水。。的博客-CSDN博客