本指南的学习目标(Learning Goals of this guide)
Brief introduction to containers, Kubernetes, Streamlit, and Polyaxon.
容器, Kubernetes , Streamlit和Polyaxon的简要介绍。
Create a Kubernetes cluster and deploy Polyaxon with Helm.
创建一个Kubernetes集群并使用Helm部署Polyaxon 。
How to explore datasets on a Jupyter Notebook running on a Kubernetes cluster.
如何在Kubernetes集群上运行的Jupyter Notebook上浏览数据集。
How to train multiple versions of a machine learning model using Polyaxon on Kubernetes.
如何使用Kubernetes上的Polyaxon训练机器学习模型的多个版本。
- How to save a machine learning model. 如何保存机器学习模型。
How to analyze the models using Polyaxon UI.
如何使用Polyaxon UI分析模型。
How to expose the model with a user interface using Streamlit and make new predictions.
如何使用Streamlit通过用户界面公开模型并做出新的预测。
本指南所需的工具 (Tools Required for this guide)
什么是容器?(What is a container?)
A container is a standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another. Docker is a tool designed to make it easier to create, deploy, and run applications by using containers.
容器是打包代码及其所有依赖项的软件的标准单元,因此该应用程序可以从一个计算环境快速可靠地运行到另一个计算环境。 码头工人 是一种工具,旨在使使用容器更容易创建,部署和运行应用程序。
In our guide we will use containers to package our code and dependencies and easily deploy them on Kubernetes.
在我们的指南中,我们将使用容器打包我们的代码和依赖项,并轻松地将它们部署在Kubernetes上。
什么是Kubernetes? (What is Kubernetes?)
Kubernetes is a powerful open-source distributed system for managing containerized applications. In simple words, Kubernetes is a system for running and orchestrating containerized applications across a cluster of machines. It is a platform designed to completely manage the life cycle of containerized applications.
Kubernetes是用于管理容器化应用程序的功能强大的开源分布式系统。 简单来说就是Kubernetes 是一个用于跨机器集群运行和协调容器化应用程序的系统。 它是一个旨在完全管理容器化应用程序生命周期的平台。
Why should I use Kubernetes.
我为什么要使用Kubernetes。
Load Balancing: Automatically distributes the load between containers.
负载平衡:自动在容器之间分配负载。
Scaling: Automatically scale up or down by adding or removing containers when demand changes such as peak hours, weekends and holidays.
缩放:在需求变化(例如高峰时间,周末和节假日)时,通过添加或删除容器来自动缩放。
Storage: Keeps storage consistent with multiple instances of an application.
存储:使存储与应用程序的多个实例保持一致。
Self-healing Automatically restarts containers that fail and kills containers that don’t respond to your user-defined health check.
自我修复功能自动重新启动失败的容器并杀死不响应用户定义的运行状况检查的容器。
Automated Rollouts you can automate Kubernetes to create new containers for your deployment, remove existing containers and adopt all of their resources to the new container.
自动化推出,您可以自动化Kubernetes来为您的部署创建新容器,删除现有容器并将其所有资源用于新容器。
什么是Streamlit? (What is Streamlit?)
Streamlit is an open-source framework to create an interactive, beautiful visualization app. All in python!
Streamlit是一个开放源代码框架,用于创建交互式,美观的可视化应用程序。 全部在python中!
Streamlit provides many useful features that can be very helpful in making visualizations for data-driven projects.
Streamlit提供了许多有用的功能,这些功能对于使数据驱动的项目可视化非常有用。
Example of Face-GAN explorer using Streamlit
使用Streamlit的Face-GAN资源管理器示例

Why should I use Streamlit?
为什么要使用Streamlit?
- Simple and easy way to create an interactive user interface 创建交互式用户界面的简便方法
- Requires zero development experience需要零开发经验
- It’s fun making use of different function in your data-driven projects :)在数据驱动的项目中使用不同的功能很有趣:)
- Comprehensive documentation 综合文件
什么是Polyaxon?(What is Polyaxon?)
Polyaxon is an open-source cloud native machine learning platform, that provides simple interfaces to train, monitor, and manage models.
Polyaxon是一个开源的云原生机器学习平台,它提供了简单的界面来训练,监视和管理模型。
Polyaxon runs on top of Kubernetes to allow scaling up and down of your cluster’s resources, and provides tools to automate the process of experimentation, while tracking information about models, configurations, parameters, and code.
Polyaxon在Kubernetes之上运行,以允许扩展和缩减集群的资源,并提供工具来自动执行实验过程,同时跟踪有关模型,配置,参数和代码的信息。
Why should I use Polyaxon?
为什么要使用Polyaxon?
- Automatically track key model metrics, hyperparameters, visualizations, artifacts and resources, and version control code and data. 自动跟踪关键模型指标,超参数,可视化,工件和资源以及版本控制代码和数据。
- Maximize the usage of your cluster by scheduling jobs and experiments via the CLI, dashboard, SDKs, or REST API. 通过CLI,仪表板,SDK或REST API安排作业和实验,从而最大程度地利用群集。
- Use optimization algorithms to effectively run parallel experiments and find the best model. 使用优化算法有效地运行并行实验并找到最佳模型。
- Visualize, search, and compare experiment results, hyperparams, training data and source code versions, so you can quickly analyze what worked and what didn’t. 可视化,搜索和比较实验结果,超参数,训练数据和源代码版本,因此您可以快速分析哪些有效,哪些无效。
- Consistently develop, validate, deliver, and monitor models to create a competitive advantage. 一致地开发,验证,交付和监视模型以创建竞争优势。
- Scale your resources as needed, and run jobs and experiments on any platform (AWS, Microsoft Azure, Google Cloud Platform, and on-premises hardware). 根据需要扩展资源,并在任何平台(AWS,Microsoft Azure,Google Cloud Platform和本地硬件)上运行作业和实验。
什么是头盔? (What is Helm?)
Helm is the package manager for Kubernetes, it allows us to deploy and manage the life cycle of cloud native projects like Polyaxon.
Helm是Kubernetes的软件包经理,它使我们能够部署和管理Polyaxon等云原生项目的生命周期。
Azure Kubernetes服务 (Azure Kubernetes Service)
In this tutorial we will be using Azure Kubernetes Service (AKS), a fully managed Kubernetes service on Azure. If you do not have an account with Azure, you can sign-up here for a free account.
在本教程中,我们将使用Azure Kubernetes服务(AKS) ,这是Azure上完全托管的Kubernetes服务。 如果您没有使用Azure的帐户,则可以在此处注册一个免费帐户。
In future posts, we will provide similar instructions of running this guide on Google Cloud Platform (GKE), AWS (EKS), and a local cluster with Minikube.
在以后的文章中,我们将提供在Google Cloud Platform (GKE) , AWS (EKS)和Minikube本地集群上运行此指南的类似说明。
设置工作区 (Setting the workspace)
The purpose of this tutorial is to get hands-on experience of running machine learning experimentation and deployment on Kubernetes. Let’s get started by creating our workspace.
本教程的目的是获得在Kubernetes上运行机器学习实验和部署的实践经验。 让我们开始创建工作区。
第1步—使用AKS部署Kubernetes集群 (Step 1 — Deploy a Kubernetes cluster with AKS)
Let’s create a simple Kubernetes cluster on AKS with a single node:
让我们在具有单个节点的AKS上创建一个简单的Kubernetes集群:
az aks create --resource-group myResourceGroup --name streamlit-polyaxon --node-count 1 --enable-addons monitoring --generate-ssh-keysTo make sure you are on the right cluster you can execute the command
为了确保您在正确的集群上,可以执行以下命令
az aks get-credentials --resource-group 第2步-安装头盔(Step 2 — Install Helm)
Install Helm on your local machine to be able to manage Polyaxon as well as other cloud native projects that you might want to run on Kubernetes.
在本地计算机上安装Helm ,以便能够管理Polyaxon以及您可能希望在Kubernetes上运行的其他云本机项目。
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3chmod 700 get_helm.sh./get_helm.sh第3步-将Polyaxon图表添加到Helm (Step 3— Add Polyaxon Charts to Helm)
helm repo add polyaxon https://charts.polyaxon.com第4步-安装Polyaxon CLI (Step 4— Install Polyaxon CLI)
pip install -U polyaxon第5步—将Polyaxon部署到Kubernetes (Step 5—Deploy Polyaxon to Kubernetes)
polyaxon admin deploy第6步-等待部署达到就绪状态 (Step 6—Wait for the deployments to reach the ready state)
kubectl get deployment -n polyaxon -wThis should take about 3 min:
这大约需要3分钟:
NAME READY UP-TO-DATE AVAILABLE AGE
polyaxon-polyaxon-api 1/1 1 1 3m17s
polyaxon-polyaxon-gateway 1/1 1 1 3m17s
polyaxon-polyaxon-operator 1/1 1 1 3m17s
polyaxon-polyaxon-streams 1/1 1 1 3m17s第7步-公开Polyaxon API和UI (Step 7— Expose Polyaxon API and UI)
Polyaxon provides a simple command to expose the dashboard and the API in a secure way on your localhost:
Polyaxon提供了一个简单的命令,可以在您的本地主机上以安全的方式公开仪表板和API:
polyaxon port-forward第8步-在Polyaxon上创建一个项目 (Step 8— Create a project on Polyaxon)
In a different terminal session than the one used for exposing the dashboard, run:
在不同于用于显示仪表板的终端会话中,运行:
polyaxon project create --name=streamlit-appYou should see:
您应该看到:
Project `streamlit-app` was created successfully.
You can view this project on Polyaxon UI: http://localhost:8000/ui/root/streamlit-app/
Now we can move to the next section: training and analyzing a model.
现在,我们可以进入下一部分:训练和分析模型。
训练机器学习模型 (Training a machine learning model)
In this tutorial we will train a model to classify Iris flower species from its features.
在本教程中,我们将训练一个模型,根据其特征对鸢尾花种类进行分类。
Iris features: Sepal, Petal, lengths, and widths
虹膜特征:萼片,花瓣,长度和宽度
探索数据集(Exploring the datasets)
We will start first by exploring the iris dataset in a notebook session running on our Kubernetes cluster.
我们将首先在Kubernetes集群上运行的笔记本会话中探索虹膜数据集。
Let’s start a new notebook session and wait until it reaches the running state:
让我们开始一个新的笔记本会话,然后等待它进入运行状态:
polyaxon run --hub jupyter-lab -wPolyaxon provides a list of highly productive components, called hub, and allows to start a notebook session using a single command. behind the scene Polyaxon will create a Kubernetes deployment and a headless service, and will expose the service using Polyaxon’s API. For more details please check Polyaxon’s open-source hub.
Polyaxon提供了称为hub的高效率组件列表,并允许使用单个命令启动笔记本会话。 Polyaxon将在后台创建Kubernetes部署和无头服务,并将使用Polyaxon的API公开该服务。 有关更多详细信息,请检查Polyaxon的开源中心。
After a couple of seconds the notebook will be running.
几秒钟后,笔记本计算机将开始运行。
Note: if you stopped the previous command, you can always get the last (cached) running operation by executing the command:
注意:如果停止了上一条命令,则始终可以通过执行以下命令来获取最后一个(缓存的)运行操作:
polyaxon ops service
Polyaxon Ops服务
Let’s create a new notebook and start by examining the dataset’s features:
让我们创建一个新的笔记本并开始检查数据集的功能:

Commands executed:
执行的命令:
from sklearn.datasets import load_irisiris= load_iris()print(iris.feature_names)
print(iris.target_names)
print(iris.data.shape)
print(iris.target.shape)
print(iris.target)The dataset is about the Iris flower species:
数据集是关于鸢尾花的种类:


探索模型(Exploring the model)
There are different classes of algorithms that scikit-learn offers, in the scope of this tutorial, we will use Nearest Neighbors algorithm.
scikit-learn提供了不同种类的算法,在本教程的范围内,我们将使用Nearest Neighbor s算法。
Before we create a robust script, we will play around with a simple model in our notebook session:
在创建健壮的脚本之前,我们将在笔记本会话中尝试一个简单的模型:
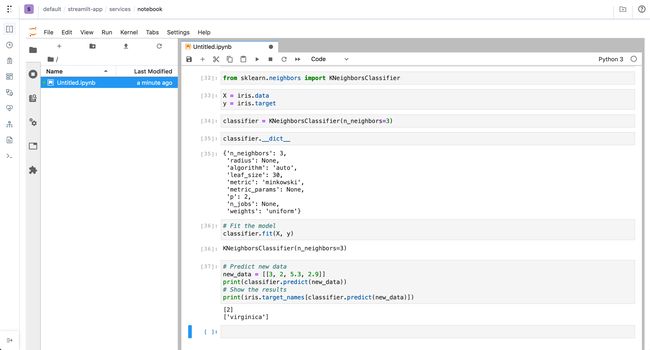
Commands executed:
执行的命令:
from sklearn.neighbors import KNeighborsClassifierX = iris.data
y = iris.targetclassifier = KNeighborsClassifier(n_neighbors=3)# Fit the model
classifier.fit(X, y)# Predict new data
new_data = [[3, 2, 5.3, 2.9]]
print(classifier.predict(new_data))
# Show the results
print(iris.target_names[classifier.predict(new_data)])In this case we used n_neighbors=3 and the complete dataset for training the model.
在这种情况下,我们使用n_neighbors=3和完整的数据集来训练模型。
In order to explore different variants of our model, we need to make a script for our model, and parametrize the inputs and outputs, to easily change the parameters such as n_neighbors we also need to establish some rigorous way of estimating the performance of the model.
为了探索模型的不同变体,我们需要为模型创建脚本,并对输入和输出进行参数化,以轻松更改参数(例如n_neighbors我们还需要建立一些严格的方法来评估模型的性能。
A practical way of doing that, is by creating an evaluation procedure where we would split the dataset to training and testing. We train the model on the training set and evaluate it on the testing set.
一种实用的方法是创建评估程序,将数据集拆分为训练和测试。 我们在训练集上训练模型,并在测试集上对其进行评估。
scikit-learn provides methods to split a dataset:
scikit-learn提供了分割数据集的方法:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1012)生产模型训练 (Productionizing the model training)
Now that we established some practices let’s create a function that accepts parameters, trains the model, and saves the resulting score:
现在,我们已经建立了一些实践,让我们创建一个接受参数,训练模型并保存结果得分的函数:
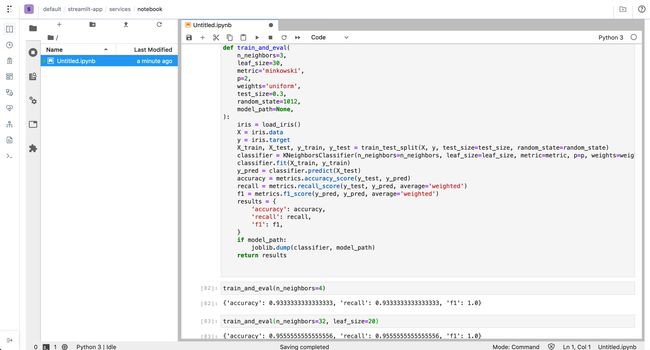
Commands executed:
执行的命令:
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
from sklearn.datasets import load_iristry:
from sklearn.externals import joblib
except:
passdef train_and_eval(
n_neighbors=3,
leaf_size=30,
metric='minkowski',
p=2,
weights='uniform',
test_size=0.3,
random_state=1012,
model_path=None,
):
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)
classifier = KNeighborsClassifier(n_neighbors=n_neighbors, leaf_size=leaf_size, metric=metric, p=p, weights=weights)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracy = metrics.accuracy_score(y_test, y_pred)
recall = metrics.recall_score(y_test, y_pred, average='weighted')
f1 = metrics.f1_score(y_pred, y_pred, average='weighted')
results = {
'accuracy': accuracy,
'recall': recall,
'f1': f1,
}
if model_path:
joblib.dump(classifier, model_path)
return resultsNow we have a script that accepts parameters to evaluate the model based on different inputs, saves the model and returns the results, but this is still very manual, and for larger and more complex models this is very impractical.
现在,我们有了一个脚本,该脚本接受参数以根据不同的输入评估模型,保存模型并返回结果,但这仍然是非常手动的,对于更大,更复杂的模型,这是非常不切实际的。
使用Polyaxon进行实验 (Running experiments with Polyaxon)
Instead of running the model by manually changing the values in the notebook, we will create a script and run the model using Polyaxon. We will also log the resulting metrics and model using Polyaxon’s tracking module.
我们将创建脚本并使用Polyaxon运行模型,而不是通过手动更改笔记本中的值来运行模型。 我们还将使用Polyaxon的跟踪模块记录生成的度量和模型。
The code for the model that we will train can be found in this github repo.
我们将训练的模型的代码可以在这个github repo中找到。
Running the example with the default parameters:
使用默认参数运行示例:
polyaxon run --url=https://raw.githubusercontent.com/polyaxon/polyaxon-examples/master/in_cluster/sklearn/iris/polyaxonfile.yml -lRunning with a different parameters:
使用不同的参数运行:
polyaxon run --url=https://raw.githubusercontent.com/polyaxon/polyaxon-examples/master/in_cluster/sklearn/iris/polyaxonfile.yml -l -P n_neighbors=50安排多个并行实验 (Scheduling multiple parallel experiments)
Instead of manually changing the parameters, we will automate this process by exploring a space of configurations:
代替手动更改参数,我们将通过探索配置空间来自动执行此过程:
polyaxon run --url=https://raw.githubusercontent.com/polyaxon/polyaxon-examples/master/in_cluster/sklearn/iris/hyper-polyaxonfile.yml --eagerYou will see the CLI creating several experiments that will run in parallel:
您将看到CLI创建了几个可以并行运行的实验:
Starting eager mode...
Creating 15 operations
A new run `b6cdaaee8ce74e25bc057e23196b24e6` was created
...分析实验 (Analyzing the experiments)
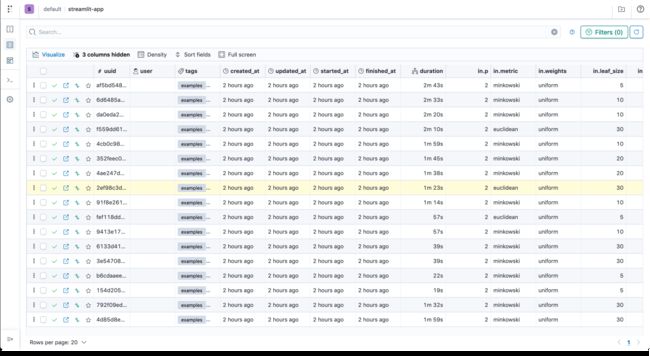
Sorting the experiments based on their accuracy metric
根据实验的准确性指标对实验进行排序

Comparing accuracy against n_neighbors
将accuracy与n_neighbors进行比较
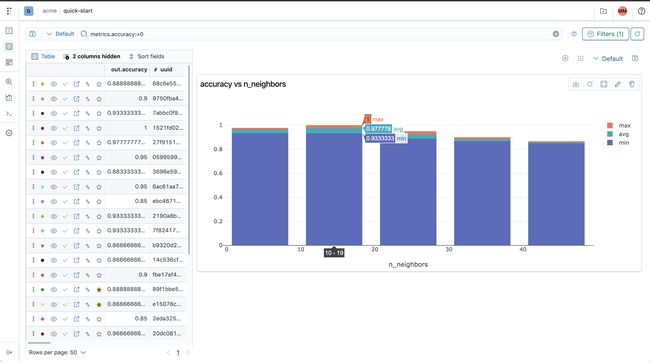
通过准确性选择最佳模型 (Selecting the best model by accuracy)
In our script we used Polyaxon to log a model every time we run an experiment:
在我们的脚本中,每次运行实验时,我们都使用Polyaxon记录模型:
# Logging the model
tracking.log_model(model_path, name="iris-model", framework="scikit-learn")
将模型部署为虹膜分类应用(Deploying the model as an Iris Classification App)
We will deploy a simple streamlit app that will load our model and display an app that makes a prediction based on the features and displays an image corresponding to the flower class.
我们将部署一个简单的streamlit应用程序,该应用程序将加载我们的模型并显示一个基于功能进行预测并显示与花类相对应的图像的应用程序。
import streamlit as st
import pandas as pd
import joblib
import argparse
from PIL import Image
def load_model(model_path: str):
model = open(model_path, "rb")
return joblib.load(model)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--model-path',
type=str,
)
args = parser.parse_args()
setosa = Image.open("images/iris-setosa.png")
versicolor = Image.open("images/iris-versicolor.png")
virginica = Image.open("images/iris-virginica.png")
classifier = load_model(args.model_path)
print(classifier)
st.title("Iris flower species Classification")
st.sidebar.title("Features")
parameter_list = [
"Sepal length (cm)",
"Sepal Width (cm)",
"Petal length (cm)",
"Petal Width (cm)"
]
sliders = []
for parameter, parameter_df in zip(parameter_list, ['5.2', '3.2', '4.2', '1.2']):
values = st.sidebar.slider(
label=parameter,
key=parameter,
value=float(parameter_df),
min_value=0.0,
max_value=8.0,
step=0.1
)
sliders.append(values)
input_variables = pd.DataFrame([sliders], columns=parameter_list)
prediction = classifier.predict(input_variables)
if prediction == 0:
elif prediction == 1:
st.image(versicolor)
else:
st.image(virginica)Let’s schedule the app with Polyaxon
让我们用Polyaxon安排应用程序
polyaxon run --url=https://raw.githubusercontent.com/polyaxon/polyaxon-examples/master/in_cluster/sklearn/iris/streamlit-polyaxonfile.yml -P uuid=86ffaea976c647fba813fca9153781ffNote that the uuid 86ffaea976c647fba813fca9153781ff will be different in your use case.
请注意,您的用例中的uuid 86ffaea976c647fba813fca9153781ff将有所不同。

结论(Conclusion)
In this tutorial, we went through an end-to-end process of training and deploying a simple classification app using Kubernetes, Streamlit, and Polyaxon.
在本教程中,我们使用了Kubernetes,Streamlit和Polyaxon进行了端到端的培训和部署简单分类应用程序的过程。
You can find the source code for this tutorial in this repo.
您可以在此仓库中找到本教程的源代码。
翻译自: https://towardsdatascience.com/deploy-machine-learning-applications-to-kubernetes-using-streamlit-and-polyaxon-49bf4b963515