从期望最大化(EM)到变分自编码器(VAE)
本文主要记录了自己对变分自编码器论文的理解。
Kingma D P, Welling M. Auto-encoding variational bayes[J]. arXiv preprint arXiv:1312.6114, 2013.
https://arxiv.org/abs/1312.6114
1 带有潜在变量的极大似然估计
假设我们有一个有限整数随机数发生器 z ∼ p θ ( z ) z \sim {p_\theta }\left( z \right) z∼pθ(z), z = 1 , 2 , . . . , K z = 1,2,...,K z=1,2,...,K,且每一个整数 z z z 都对应着一个随机分布 p θ ( x ∣ z ) {p_\theta }\left( {x|z} \right) pθ(x∣z),其中 θ \theta θ 代表这个随机系统所涉及所有参数的集合。根据全概率公式,可知
p θ ( x ) = ∑ z = 1 K p θ ( x , z ) = ∑ z = 1 K p θ ( x ∣ z ) p θ ( z ) . (1.1) {p_\theta }\left( x \right) = \sum\limits_{z = 1}^K {{p_\theta }\left( {x,z} \right)} = \sum\limits_{z = 1}^K {{p_\theta }\left( {x|z} \right){p_\theta }\left( z \right)} .\tag{1.1} pθ(x)=z=1∑Kpθ(x,z)=z=1∑Kpθ(x∣z)pθ(z).(1.1)
在实际应用中,我们往往只能获取到 x x x,而无法直接得知 x x x 采样自哪个条件分布 p θ ( x ∣ z ) {p_\theta }\left( {x|z} \right) pθ(x∣z)。这时 z z z 称为潜在变量。如果我们要通过独立同分布数据集 X = { x ( i ) } i = 1 N X = \left\{ {{x^{\left( i \right)}}} \right\}_{i = 1}^N X={x(i)}i=1N 来估计未知的分布参数 θ \theta θ,根据极大似然估计,相当于最大化以下函数
L ( θ ; X ) = log ∏ i = 1 N p θ ( x ( i ) ) = ∑ i = 1 N log ∑ z = 1 K p θ ( x ( i ) ∣ z ) p θ ( z ) . (1.2) {\cal L}\left( {\theta ;X} \right) = \log \prod\limits_{i = 1}^N {{p_\theta }\left( {{x^{\left( i \right)}}} \right)} = \sum\limits_{i = 1}^N {\log \sum\limits_{z = 1}^K {{p_\theta }\left( {{x^{\left( i \right)}}|z} \right){p_\theta }\left( z \right)} } .\tag{1.2} L(θ;X)=logi=1∏Npθ(x(i))=i=1∑Nlogz=1∑Kpθ(x(i)∣z)pθ(z).(1.2)
这时可以发现,log 函数内部包含了求和部分,这对于梯度计算非常麻烦。
为了解决以上问题,我们需要引入变分的思想。引入一个关于潜在变量 z z z 的未知条件分布 q ϕ ( z ∣ x ) {q_\phi }\left( {z|x} \right) qϕ(z∣x),注意此分布无需与 θ \theta θ 相关,结合 Jensen 不等式可得
log p θ ( x ) = log ∑ z = 1 K p θ ( x , z ) = log ∑ z = 1 K q ϕ ( z ∣ x ) p θ ( x , z ) q ϕ ( z ∣ x ) ≥ ∑ z = 1 K q ϕ ( z ∣ x ) log p θ ( x , z ) q ϕ ( z ∣ x ) . (1.3) \begin{array}{c} \log {p_\theta }\left( x \right) = \log \sum\limits_{z = 1}^K {{p_\theta }\left( {x,z} \right)} = \log \sum\limits_{z = 1}^K {{q_\phi }\left( {z|x} \right)\frac{{{p_\theta }\left( {x,z} \right)}}{{{q_\phi }\left( {z|x} \right)}}} \\ \ge \sum\limits_{z = 1}^K {{q_\phi }\left( {z|x} \right)\log \frac{{{p_\theta }\left( {x,z} \right)}}{{{q_\phi }\left( {z|x} \right)}}} . \end{array}\tag{1.3} logpθ(x)=logz=1∑Kpθ(x,z)=logz=1∑Kqϕ(z∣x)qϕ(z∣x)pθ(x,z)≥z=1∑Kqϕ(z∣x)logqϕ(z∣x)pθ(x,z).(1.3)
且可计算得不等式两侧差距为
log p θ ( x ) − ∑ z = 1 K q ϕ ( z ∣ x ) log p θ ( x , z ) q ϕ ( z ∣ x ) = ∑ z = 1 K q ϕ ( z ∣ x ) ( log p θ ( x ) − log p θ ( x , z ) q ϕ ( z ∣ x ) ) = ∑ z = 1 K q ϕ ( z ∣ x ) log q ϕ ( z ∣ x ) p θ ( x ) p θ ( x , z ) = ∑ z = 1 K q ϕ ( z ∣ x ) log q ϕ ( z ∣ x ) p θ ( z ∣ x ) = D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) . (1.4) \begin{array}{l} \log {p_\theta }\left( x \right) - \sum\limits_{z = 1}^K {{q_\phi }\left( {z|x} \right)\log \frac{{{p_\theta }\left( {x,z} \right)}}{{{q_\phi }\left( {z|x} \right)}}} \\ = \sum\limits_{z = 1}^K {{q_\phi }\left( {z|x} \right)\left( {\log {p_\theta }\left( x \right) - \log \frac{{{p_\theta }\left( {x,z} \right)}}{{{q_\phi }\left( {z|x} \right)}}} \right)} \\ = \sum\limits_{z = 1}^K {{q_\phi }\left( {z|x} \right)\log \frac{{{q_\phi }\left( {z|x} \right){p_\theta }\left( x \right)}}{{{p_\theta }\left( {x,z} \right)}}} \\ = \sum\limits_{z = 1}^K {{q_\phi }\left( {z|x} \right)\log \frac{{{q_\phi }\left( {z|x} \right)}}{{{p_\theta }\left( {z|x} \right)}}} \\ = {D_{KL}}\left( {{q_\phi }\left( {z|x} \right)\parallel {p_\theta }\left( {z|x} \right)} \right). \end{array}\tag{1.4} logpθ(x)−z=1∑Kqϕ(z∣x)logqϕ(z∣x)pθ(x,z)=z=1∑Kqϕ(z∣x)(logpθ(x)−logqϕ(z∣x)pθ(x,z))=z=1∑Kqϕ(z∣x)logpθ(x,z)qϕ(z∣x)pθ(x)=z=1∑Kqϕ(z∣x)logpθ(z∣x)qϕ(z∣x)=DKL(qϕ(z∣x)∥pθ(z∣x)).(1.4)
即不等式两侧差距刚好为未知分布 q ϕ ( z ∣ x ) {q_\phi }\left( {z|x} \right) qϕ(z∣x) 与后验分布 p θ ( z ∣ x ) {p_\theta }\left( {z|x} \right) pθ(z∣x) 的 KL 散度,其具有非负性,当且仅当两分布相同时 KL 散度为 0。于是,我们可以将式 (1.2) 拆分为以下两部分,
L ( θ ; X ) = ∑ i = 1 N L ( θ ; x ( i ) ) = ∑ i = 1 N log p θ ( x ( i ) ) = ∑ i = 1 N [ D K L ( q ϕ ( z ∣ x ( i ) ) ∥ p θ ( z ∣ x ( i ) ) ) + L ( θ , ϕ ; x ( i ) ) ] , (1.5) \begin{array}{l} {\cal L}\left( {\theta ;X} \right) = \sum\limits_{i = 1}^N {{\cal L}\left( {\theta ;{x^{\left( i \right)}}} \right)} = \sum\limits_{i = 1}^N {\log {p_\theta }\left( {{x^{\left( i \right)}}} \right)} \\ = \sum\limits_{i = 1}^N {\left[ {{D_{KL}}\left( {{q_\phi }\left( {z|{x^{\left( i \right)}}} \right)\parallel {p_\theta }\left( {z|{x^{\left( i \right)}}} \right)} \right) + {\cal L}\left( {\theta ,\phi ;{x^{\left( i \right)}}} \right)} \right]} , \end{array}\tag{1.5} L(θ;X)=i=1∑NL(θ;x(i))=i=1∑Nlogpθ(x(i))=i=1∑N[DKL(qϕ(z∣x(i))∥pθ(z∣x(i)))+L(θ,ϕ;x(i))],(1.5)
其中
L ( θ , ϕ ; x ( i ) ) = ∑ z = 1 K q ϕ ( z ∣ x ( i ) ) log p θ ( x ( i ) , z ) q ϕ ( z ∣ x ( i ) ) . (1.6) {\cal L}\left( {\theta ,\phi ;{x^{\left( i \right)}}} \right) = \sum\limits_{z = 1}^K {{q_\phi }\left( {z|{x^{\left( i \right)}}} \right)\log \frac{{{p_\theta }\left( {{x^{\left( i \right)}},z} \right)}}{{{q_\phi }\left( {z|{x^{\left( i \right)}}} \right)}}} .\tag{1.6} L(θ,ϕ;x(i))=z=1∑Kqϕ(z∣x(i))logqϕ(z∣x(i))pθ(x(i),z).(1.6)
当然目前我们还不知道式 (1.5) 所表示的极大似然估计对于估计分布参数的作用,更不清楚新引入的未知分布 q ϕ ( z ∣ x ) {q_\phi }\left( {z|x} \right) qϕ(z∣x) 的意义。但实际上,由于 q ϕ ( z ∣ x ) {q_\phi }\left( {z|x} \right) qϕ(z∣x) 是任意选取的,结合 KL 散度的性质,我们将能推导出一种十分巧妙而有效的优化方法,也就是期望最大化(EM)算法。这种通过改变概率分布来达到代价函数最大化的模式,也正是变分法的特征所在。由于篇幅的限制,本文只是大概地讲述了 EM 算法的原理,更多内容以及利用 EM 算法求解高斯混合模型(GMM)可查看我以前的博客:
高斯混合模型(GMM)与期望最大化算法(EM) https://blog.csdn.net/qq_33552519/article/details/106963417
2 期望最大化算法
首先考虑一种参数优化模式。对于需要寻找极大值点的函数 f ( x ) f\left( x \right) f(x),假设存在一辅助函数 A ( x , x o l d ) A\left( {x,{x^{old}}} \right) A(x,xold),其中 x o l d {x^{old}} xold 为上一次迭代所找到的最优解,即辅助函数的定义与上一次的最优解相关。注意,这里的 x o l d {x^{old}} xold 为已知常数。如果辅助函数满足以下条件:
∀ x → f ( x ) ≥ A ( x , x o l d ) , f ( x o l d ) = A ( x o l d , x o l d ) . (2.1) \begin{array}{l} \forall x \to f\left( x \right) \ge A\left( {x,{x^{old}}} \right),\\ f\left( {{x^{old}}} \right) = A\left( {{x^{old}},{x^{old}}} \right). \end{array}\tag{2.1} ∀x→f(x)≥A(x,xold),f(xold)=A(xold,xold).(2.1)
那么找到 A ( x , x o l d ) A\left( {x,{x^{old}}} \right) A(x,xold) 的极大值点,即有
x n e w = arg max x A ( x , x o l d ) ⇒ f ( x n e w ) ≥ A ( x n e w , x o l d ) ≥ A ( x o l d , x o l d ) = f ( x o l d ) . (2.2) \begin{array}{l} {x^{new}} = \arg {\max _x}A\left( {x,{x^{old}}} \right)\\ \Rightarrow f\left( {{x^{new}}} \right) \ge A\left( {{x^{new}},{x^{old}}} \right) \ge A\left( {{x^{old}},{x^{old}}} \right) = f\left( {{x^{old}}} \right). \end{array}\tag{2.2} xnew=argmaxxA(x,xold)⇒f(xnew)≥A(xnew,xold)≥A(xold,xold)=f(xold).(2.2)
因此,我们可以保证整个迭代过程不会出现恶化的情况。当迭代停滞时,即意味着 f ( x ) f\left( x \right) f(x) 也到达了一个极大值点。要证明这一点,令
h ( x ) = f ( x ) − A ( x , x o l d ) ≥ 0. (2.3) h\left( x \right) = f\left( x \right) - A\left( {x,{x^{old}}} \right) \ge 0.\tag{2.3} h(x)=f(x)−A(x,xold)≥0.(2.3)
那么 x o l d {x^{old}} xold 一定是 h ( x ) h\left( x \right) h(x) 的一个极小值点,所以有
f ′ ( x o l d ) = A ′ ( x o l d , x o l d ) . (2.4) f'\left( {{x^{old}}} \right) = A'\left( {{x^{old}},{x^{old}}} \right). \tag{2.4} f′(xold)=A′(xold,xold).(2.4)
当迭代停滞时,有
x n e w = x o l d ⇒ A ′ ( x n e w , x o l d ) = A ′ ( x o l d , x o l d ) = 0 ⇒ f ′ ( x n e w ) = f ′ ( x o l d ) = 0. (2.5) \begin{array}{l} {x^{new}} = {x^{old}}\\ \Rightarrow A'\left( {{x^{new}},{x^{old}}} \right) = A'\left( {{x^{old}},{x^{old}}} \right) = 0\\ \Rightarrow f'\left( {{x^{new}}} \right) = f'\left( {{x^{old}}} \right) = 0. \end{array}\tag{2.5} xnew=xold⇒A′(xnew,xold)=A′(xold,xold)=0⇒f′(xnew)=f′(xold)=0.(2.5)
因此,这种迭代策略是十分有效的,只是寻找合适的辅助函数成了我们现在所要面临的问题。
回到第一节所讨论的极大似然估计问题上,对于任意一个待考察的参数 θ o l d {\theta ^{old}} θold,根据贝叶斯定理,我们可以求得 x x x 来自某一个 z z z 对应分布的后验概率为
p θ o l d ( z ∣ x ) = p θ o l d ( x ∣ z ) p θ o l d ( z ) p θ o l d ( x ) = p θ o l d ( x ∣ z ) p θ o l d ( z ) ∑ k = 1 K p θ o l d ( x ∣ z = k ) p θ o l d ( z = k ) . (2.6) {p_{{\theta ^{old}}}}\left( {z|x} \right) = \frac{{{p_{{\theta ^{old}}}}\left( {x|z} \right){p_{{\theta ^{old}}}}\left( z \right)}}{{{p_{{\theta ^{old}}}}\left( x \right)}} = \frac{{{p_{{\theta ^{old}}}}\left( {x|z} \right){p_{{\theta ^{old}}}}\left( z \right)}}{{\sum\limits_{k = 1}^K {{p_{{\theta ^{old}}}}\left( {x|z = k} \right){p_{{\theta ^{old}}}}\left( {z = k} \right)} }}.\tag{2.6} pθold(z∣x)=pθold(x)pθold(x∣z)pθold(z)=k=1∑Kpθold(x∣z=k)pθold(z=k)pθold(x∣z)pθold(z).(2.6)
因为 KL 散度当且仅当两分布相同时为 0,因此不妨令
q ϕ o l d ( z ∣ x ) = p θ o l d ( z ∣ x ) . (2.7) {q_{{\phi ^{old}}}}\left( {z|x} \right) = {p_{{\theta ^{old}}}}\left( {z|x} \right).\tag{2.7} qϕold(z∣x)=pθold(z∣x).(2.7)
因为 KL 散度具有非负性,于是有
D K L ( q ϕ o l d ( z ∣ x ) ∥ p θ ( z ∣ x ) ) ≥ 0. (2.8) {D_{KL}}\left( {{q_{{\phi ^{old}}}}\left( {z|x} \right)\parallel {p_\theta }\left( {z|x} \right)} \right) \ge 0.\tag{2.8} DKL(qϕold(z∣x)∥pθ(z∣x))≥0.(2.8)
注意这里 q ϕ o l d ( z ∣ x ) {q_{{\phi ^{old}}}}\left( {z|x} \right) qϕold(z∣x) 是一个固定的分布,而 p θ ( z ∣ x ) {p_\theta }\left( {z|x} \right) pθ(z∣x) 则是由变量 θ \theta θ 决定的不断变化的分布。于是我们获得了式 (2.1) 所需的两个条件:
∀ θ → L ( θ ; x ( i ) ) ≥ L ( θ , ϕ o l d ; x ( i ) ) . L ( θ o l d ; x ( i ) ) = L ( θ o l d , ϕ o l d ; x ( i ) ) . (2.9) \begin{array}{l} \forall \theta \to {\cal L}\left( {\theta ;{x^{\left( i \right)}}} \right) \ge {\cal L}\left( {\theta ,{\phi ^{old}};{x^{\left( i \right)}}} \right).\\ {\cal L}\left( {{\theta ^{old}};{x^{\left( i \right)}}} \right) = {\cal L}\left( {{\theta ^{old}},{\phi ^{old}};{x^{\left( i \right)}}} \right). \end{array}\tag{2.9} ∀θ→L(θ;x(i))≥L(θ,ϕold;x(i)).L(θold;x(i))=L(θold,ϕold;x(i)).(2.9)
因此,为了极大化似然 L ( θ ; X ) {\cal L}\left( {\theta ;X} \right) L(θ;X),我们可以定义以下辅助函数:
A ( θ , θ o l d ) = ∑ i = 1 N L ( θ , ϕ o l d ; x ( i ) ) = ∑ i = 1 N ∑ z = 1 K q ϕ o l d ( z ∣ x ( i ) ) log p θ ( x ( i ) , z ) q ϕ o l d ( z ∣ x ( i ) ) = ∑ i = 1 N ∑ z = 1 K p θ o l d ( z ∣ x ( i ) ) ( log p θ ( x ( i ) , z ) − log p θ o l d ( z ∣ x ( i ) ) ) = ∑ i = 1 N ∑ z = 1 K p θ o l d ( z ∣ x ( i ) ) log p θ ( x ( i ) , z ) − C o n s t . (2.10) \begin{array}{l} A\left( {\theta ,{\theta ^{old}}} \right) = \sum\limits_{i = 1}^N {{\cal L}\left( {\theta ,{\phi ^{old}};{x^{\left( i \right)}}} \right)} \\ = \sum\limits_{i = 1}^N {\sum\limits_{z = 1}^K {{q_{{\phi ^{old}}}}\left( {z|{x^{\left( i \right)}}} \right)\log \frac{{{p_\theta }\left( {{x^{\left( i \right)}},z} \right)}}{{{q_{{\phi ^{old}}}}\left( {z|{x^{\left( i \right)}}} \right)}}} } \\ = \sum\limits_{i = 1}^N {\sum\limits_{z = 1}^K {{p_{{\theta ^{old}}}}\left( {z|{x^{\left( i \right)}}} \right)\left( {\log {p_\theta }\left( {{x^{\left( i \right)}},z} \right) - \log {p_{{\theta ^{old}}}}\left( {z|{x^{\left( i \right)}}} \right)} \right)} } \\ = \sum\limits_{i = 1}^N {\sum\limits_{z = 1}^K {{p_{{\theta ^{old}}}}\left( {z|{x^{\left( i \right)}}} \right)\log {p_\theta }\left( {{x^{\left( i \right)}},z} \right)} } - Const. \end{array}\tag{2.10} A(θ,θold)=i=1∑NL(θ,ϕold;x(i))=i=1∑Nz=1∑Kqϕold(z∣x(i))logqϕold(z∣x(i))pθ(x(i),z)=i=1∑Nz=1∑Kpθold(z∣x(i))(logpθ(x(i),z)−logpθold(z∣x(i)))=i=1∑Nz=1∑Kpθold(z∣x(i))logpθ(x(i),z)−Const.(2.10)
或者等价地使用以下辅助函数:
Q ( θ , θ o l d ) = ∑ i = 1 N ∑ z = 1 K p θ o l d ( z ∣ x ( i ) ) log p θ ( x ( i ) , z ) . (2.11) Q\left( {\theta ,{\theta ^{old}}} \right) = \sum\limits_{i = 1}^N {\sum\limits_{z = 1}^K {{p_{{\theta ^{old}}}}\left( {z|{x^{\left( i \right)}}} \right)\log {p_\theta }\left( {{x^{\left( i \right)}},z} \right)} } .\tag{2.11} Q(θ,θold)=i=1∑Nz=1∑Kpθold(z∣x(i))logpθ(x(i),z).(2.11)
注意,尽管式 (2.9) 对于单个样本 x ( i ) ∈ X {x^{\left( i \right)}} \in X x(i)∈X 都成立,但因为分布参数 θ \theta θ 是由所有样本共用的,所以在优化参数时需要把所有样本都考虑进来,否则可能会有较大的偏差。因为 p θ ( x , z ) = p θ ( x ∣ z ) p θ ( z ) {p_\theta }\left( {x,z} \right) = {p_\theta }\left( {x|z} \right){p_\theta }\left( z \right) pθ(x,z)=pθ(x∣z)pθ(z) 是连乘的形式,所以 A ( θ , θ o l d ) A\left( {\theta ,{\theta ^{old}}} \right) A(θ,θold) 的导数往往会具有更加简洁的形式,使得对 L ( θ ; X ) {\cal L}\left( {\theta ;X} \right) L(θ;X) 的参数估计具有更高的可行性。
我们把以上的参数优化过程称为期望最大化(Expectation Maximum, EM)算法,其可表示为以下步骤:
- 随机选取一组初始参数 θ o l d {\theta ^{old}} θold,但为了避免遇到较差的局部极值点,一般会选择多组初始参数独立优化。
- E step:根据式 (2.6) 计算后验概率 p θ o l d ( z ∣ x ( i ) ) {p_{{\theta ^{old}}}}\left( {z|{x^{\left( i \right)}}} \right) pθold(z∣x(i)),构造辅助函数 A ( θ , θ o l d ) A\left( {\theta ,{\theta ^{old}}} \right) A(θ,θold)。
- M step:求解辅助函数极大值点 θ n e w = arg max θ A ( θ , θ o l d ) {\theta ^{new}} = \arg {\max _\theta }A\left( {\theta ,{\theta ^{old}}} \right) θnew=argmaxθA(θ,θold)。
- 如参数收敛,算法结束;否则更新 θ o l d ← θ n e w {\theta ^{old}} \leftarrow {\theta ^{new}} θold←θnew,返回第 2 步。
3 带有潜在变量的随机系统
我们应该意识到,在第一节开头所描述的采样过程中,潜在变量 z z z 来自于有限个随机整数的假设并不是必须的。尽管这种假设对于随机样本的模糊分类问题十分合适,但也严重限制了 EM 算法的应用范围。实际上,我们可以用一种更加具有普适性的架构来描述带有潜在变量的随机系统,如图 1 所示。
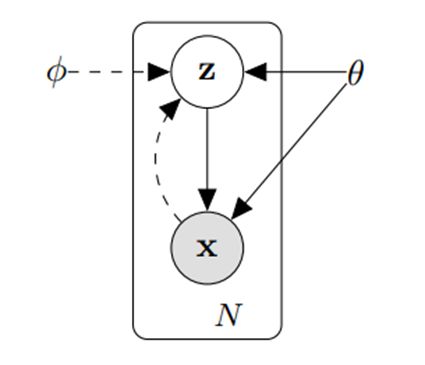
举个例子,当遇到一个陌生人时,我们可以直接从其身上获取到一些直观的信息,包括性别、身高、样貌、衣着、举止等等,将这些直观信息排列起来,即为我们所能直接观察到的特征向量,常用 x {\bf{x}} x 来表示。然而,影响一个人外在表现的内在因素有很多,包括受教育程度,家庭条件,乃至遗传基因等等,这些因素是我们对于陌生人无法直接得知的。我们同样可以把这些未知因素排列起来,即为我们无法直接观察到的特征向量,或者称为潜在特征向量,常用 z {\bf{z}} z 来表示。如果我们认同 x {\bf{x}} x 与 z {\bf{z}} z 都符合具有某些未知参数的随机分布,这些参数的集合用 θ \theta θ 来表示,那么对于随机遇到的一个人,其外在表现为 x {\bf{x}} x 而内在具有潜在特征 z {\bf{z}} z 的概率可表示为
p θ ( x , z ) = p θ ( x ∣ z ) p θ ( z ) . (3.1) {p_\theta }\left( {{\bf{x}},{\bf{z}}} \right) = {p_\theta }\left( {{\bf{x}}|{\bf{z}}} \right){p_\theta }\left( {\bf{z}} \right).\tag{3.1} pθ(x,z)=pθ(x∣z)pθ(z).(3.1)
以信息编码理论的视角来看,我们还可以将潜在特征 z {\bf{z}} z 表述为直接特征 x {\bf{x}} x 经过压缩所获得的编码(code)。因为 x {\bf{x}} x 的维度通常要远远大于 z {\bf{z}} z,例如我们可以在 x {\bf{x}} x 中加入一张照片,如果能用少量的编码 z {\bf{z}} z 来比较准确地还原 x {\bf{x}} x,无疑会减轻很大的存储压力,以 z {\bf{z}} z 代替 x {\bf{x}} x 进行一些如身份识别等任务也可以极大降低模型的复杂度。这种信息压缩的特性与主成分分析(PCA)等不谋而合,只是在这里我们增加了随机性,使其对于数据集中未曾出现过的编码 z {\bf{z}} z,只要我们知道相关的概率分布,就可以通过采样与解码生成很多具有现实意义的 x {\bf{x}} x,这是 PCA 等确定性算法所不能做到的。
相比于第一节中的描述,此时潜在特征不再为单一标量,而是由多个相关或者独立随机变量组成的随机向量,当然为了简化一般都会考虑潜在特征向量的各个分量是相互独立的,但它们既可能是离散的,也有可能是连续的。回顾第二节的 EM 算法,关键的一步是求得在现有参数下的后验分布 p θ ( z ∣ x ) {p_\theta }\left( {{\bf{z}}|{\bf{x}}} \right) pθ(z∣x),而这需要用到 p θ ( x ) {p_\theta }\left( {\bf{x}} \right) pθ(x) 的全概率公式。对于 z {\bf{z}} z 为连续向量的情况,可得
p θ ( x ) = ∫ p θ ( x ∣ z ) p θ ( z ) d z . (3.2) {p_\theta }\left( {\bf{x}} \right) = \int {{p_\theta }\left( {{\bf{x}}|{\bf{z}}} \right){p_\theta }\left( {\bf{z}} \right)d{\bf{z}}} .\tag{3.2} pθ(x)=∫pθ(x∣z)pθ(z)dz.(3.2)
而积分运算是计算机几乎不能完成的事情,所以此时 EM 算法的迭代流程就很难展开。除此以外,随着 z {\bf{z}} z 维度的增加, p θ ( x ∣ z ) {p_\theta }\left( {{\bf{x}}|{\bf{z}}} \right) pθ(x∣z) 的分布类型也通常会变得更加复杂,对其过于简单的分布假设无疑会对 p θ ( x ) {p_\theta }\left( {\bf{x}} \right) pθ(x) 的估计产生较大的偏差,对于参数估计也是十分不利的。
除此以外,当 z {\bf{z}} z 为连续向量时,对于辅助函数的构造也同样涉及到积分运算。以单个样本 x ( i ) {{\bf{x}}^{\left( i \right)}} x(i) 为例,根据式 (2.11),有
Q ( θ , θ o l d ; x ( i ) ) = ∫ p θ o l d ( z ∣ x ( i ) ) log p θ ( x ( i ) , z ) d z . (3.3) Q\left( {\theta ,{\theta ^{old}};{{\bf{x}}^{\left( i \right)}}} \right) = \int {{p_{{\theta ^{old}}}}\left( {{\bf{z}}|{{\bf{x}}^{\left( i \right)}}} \right)\log {p_\theta }\left( {{{\bf{x}}^{\left( i \right)}},{\bf{z}}} \right)d{\bf{z}}} .\tag{3.3} Q(θ,θold;x(i))=∫pθold(z∣x(i))logpθ(x(i),z)dz.(3.3)
这里假设 p θ o l d ( z ∣ x ( i ) ) {p_{{\theta ^{old}}}}\left( {{\bf{z}}|{{\bf{x}}^{\left( i \right)}}} \right) pθold(z∣x(i)) 和 p θ ( x ( i ) , z ) {p_\theta }\left( {{{\bf{x}}^{\left( i \right)}},{\bf{z}}} \right) pθ(x(i),z) 已知。以上积分运算对于计算机来说也非常难以计算,更不要说求解极值点。然而,这个问题是有较好的解决办法的,那就是蒙特卡洛 EM 算法(MCEM)。蒙特卡洛是一个著名的赌城,赌徒不懂得各种游戏中复杂的概率分析,但他知道,如果每次游戏结果都是以某种分布独立随机产生的,只要把多次游戏的结果进行统计,就能对其概率分布做出比较准确的估计。我们把这种基于某种分布采样并统计的估计方法称为蒙特卡洛方法。对于式 (3.3) 而言,其可表示为 p θ ( x ( i ) , z ) {p_\theta }\left( {{{\bf{x}}^{\left( i \right)}},{\bf{z}}} \right) pθ(x(i),z) 在 p θ o l d ( z ∣ x ( i ) ) {p_{{\theta ^{old}}}}\left( {{\bf{z}}|{{\bf{x}}^{\left( i \right)}}} \right) pθold(z∣x(i)) 分布下的期望值,即
Q ( θ , θ o l d ; x ( i ) ) = E p θ o l d ( z ∣ x ( i ) ) [ log p θ ( x ( i ) , z ) ] . (3.4) Q\left( {\theta ,{\theta ^{old}};{{\mathbf{x}}^{\left( i \right)}}} \right) = {\mathbb{E}_{{p_{{\theta ^{old}}}}\left( {{\mathbf{z}}|{{\mathbf{x}}^{\left( i \right)}}} \right)}}\left[ {\log {p_\theta }\left( {{{\mathbf{x}}^{\left( i \right)}},{\mathbf{z}}} \right)} \right].\tag{3.4} Q(θ,θold;x(i))=Epθold(z∣x(i))[logpθ(x(i),z)].(3.4)
根据蒙特卡洛方法,以 p θ o l d ( z ∣ x ( i ) ) {p_{{\theta ^{old}}}}\left( {{\bf{z}}|{{\bf{x}}^{\left( i \right)}}} \right) pθold(z∣x(i)) 分布进行 L L L 次独立采样得到 Z = { z ( l ) } l = 1 L {\bf{Z}} = \left\{ {{{\bf{z}}^{\left( l \right)}}} \right\}_{l = 1}^L Z={z(l)}l=1L,注意这里的 x ( i ) {{\bf{x}}^{\left( i \right)}} x(i) 样本是固定的,那么对式 (3.4) 的估计可表示为
Q ( θ , θ o l d ; x ( i ) ) ≃ 1 L ∑ l = 1 L log p θ ( x ( i ) , z ( l ) ) . (3.5) Q\left( {\theta ,{\theta ^{old}};{{\bf{x}}^{\left( i \right)}}} \right) \simeq \frac{1}{L}\sum\limits_{l = 1}^L {\log {p_\theta }\left( {{{\bf{x}}^{\left( i \right)}},{\bf{z}}^{\left( l \right)}} \right)} .\tag{3.5} Q(θ,θold;x(i))≃L1l=1∑Llogpθ(x(i),z(l)).(3.5)
我们强调 p θ o l d ( z ∣ x ( i ) ) {p_{{\theta ^{old}}}}\left( {{\bf{z}}|{{\bf{x}}^{\left( i \right)}}} \right) pθold(z∣x(i)) 和 p θ ( x ( i ) , z ) {p_\theta }\left( {{{\bf{x}}^{\left( i \right)}},{\bf{z}}} \right) pθ(x(i),z) 是已知的,至于如何获取则需要考虑更多的问题。一种可以规避显式后验概率 p θ ( z ∣ x ) {p_\theta }\left( {{\bf{z}}|{\bf{x}}} \right) pθ(z∣x) 的采样方法是哈密顿蒙特卡洛(HMC)方法,其只需要用到后验概率的梯度,而
log p θ ( z ∣ x ) = log p θ ( x ∣ z ) + log p θ ( z ) − log p θ ( x ) , ⇒ ∇ z log p θ ( z ∣ x ) = ∇ z log p θ ( x ∣ z ) + ∇ z log p θ ( z ) . (3.6) \begin{array}{l} \log {p_\theta }\left( {{\bf{z}}|{\bf{x}}} \right) = \log {p_\theta }\left( {{\bf{x}}|{\bf{z}}} \right) + \log {p_\theta }\left( {\bf{z}} \right) - \log {p_\theta }\left( {\bf{x}} \right),\\ \Rightarrow {\nabla _{\bf{z}}}\log {p_\theta }\left( {{\bf{z}}|{\bf{x}}} \right) = {\nabla _{\bf{z}}}\log {p_\theta }\left( {{\bf{x}}|{\bf{z}}} \right) + {\nabla _{\bf{z}}}\log {p_\theta }\left( {\bf{z}} \right). \end{array} \tag{3.6} logpθ(z∣x)=logpθ(x∣z)+logpθ(z)−logpθ(x),⇒∇zlogpθ(z∣x)=∇zlogpθ(x∣z)+∇zlogpθ(z).(3.6)
因为 p θ ( x ∣ z ) {p_\theta }\left( {{\bf{x}}|{\bf{z}}} \right) pθ(x∣z) 和 p θ ( z ) {p_\theta }\left( {\bf{z}} \right) pθ(z) 往往作为一种先验假设容易求得,所以 HMC 采样方法基本是可行的,其具体原理在此略去。注意,当我们使用 HMC 采样方法对辅助函数 Q ( θ , θ o l d ; x ( i ) ) Q\left( {\theta ,{\theta ^{old}};{{\bf{x}}^{\left( i \right)}}} \right) Q(θ,θold;x(i)) 进行蒙特卡洛估计时,后验概率 p θ ( z ∣ x ) {p_\theta }\left( {{\bf{z}}|{\bf{x}}} \right) pθ(z∣x) 就没必要求解了,式 (3.2) 所述求解边缘分布 p θ ( x ) {p_\theta }\left( {\bf{x}} \right) pθ(x) 的问题自然也就可以忽略。
综上所述,基于蒙特卡洛方法,我们巧妙避开了后验概率的计算,使得 EM 算法的迭代过程能够持续下去,从而能够处理具有更加复杂的潜在变量的随机系统的极大似然估计问题。然而我们也应该看到,随着潜在变量 z {\bf{z}} z 维度的增大,我们必然需要更多次的采样来保证蒙特卡洛方法的准确性,而我们需要对数据集 X {\bf{X}} X 中每一个样本进行蒙特卡洛估计,这无疑需要非常大的计算量,对于大数据集来说是比较低效的。而且 EM 算法的每一次迭代通常需要把整个数据集的样本纳入计算,我们当然更加希望能像神经网络那样使用类似于随机梯度下降的优化方法,每次迭代只需要考虑少量的样本,且尽可能保证参数的收敛。除此以外,EM 算法迭代的收敛性是建立在式 (2.9) 所示限制上的,当我们通过蒙特卡洛方法近似时,并不清楚会出现什么问题。因此,不同于 EM 算法,我们需要考虑不同的 q ϕ ( z ∣ x ) {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) qϕ(z∣x) 对于似然估计的影响,而不是仅限制于其等于 p θ ( z ∣ x ) {p_\theta }\left( {{\bf{z}}|{\bf{x}}} \right) pθ(z∣x) 的假设。以上的问题,引出了我们下面所要讨论的变分贝叶斯方法。
4 变分贝叶斯算法
基于第一节的内容,我们知道对于一可观测数据集 X = { x ( i ) } i = 1 N {\bf{X}} = \left\{ {{{\bf{x}}^{\left( i \right)}}} \right\}_{i = 1}^N X={x(i)}i=1N 中每一个样本 x ( i ) {{\bf{x}}^{\left( i \right)}} x(i) 出现的边缘概率为 p θ ( x ( i ) ) {p_\theta }\left( {{{\bf{x}}^{\left( i \right)}}} \right) pθ(x(i)) 可表示为以下两部分:
log p θ ( x ( i ) ) = D K L ( q ϕ ( z ∣ x ( i ) ) ∥ p θ ( z ∣ x ( i ) ) ) + L ( θ , ϕ ; x ( i ) ) . (4.1) \log {p_\theta }\left( {{{\bf{x}}^{\left( i \right)}}} \right) = {D_{KL}}\left( {{q_\phi }\left( {{\bf{z}}|{{\bf{x}}^{\left( i \right)}}} \right)\parallel {p_\theta }\left( {{\bf{z}}|{{\bf{x}}^{\left( i \right)}}} \right)} \right) + {\cal L}\left( {\theta ,\phi ;{{\bf{x}}^{\left( i \right)}}} \right).\tag{4.1} logpθ(x(i))=DKL(qϕ(z∣x(i))∥pθ(z∣x(i)))+L(θ,ϕ;x(i)).(4.1)
通过第三节的分析可知,后验概率 p θ ( z ∣ x ) {p_\theta }\left( {{\bf{z}}|{\bf{x}}} \right) pθ(z∣x) 的求解非常困难,因此想要令上式中 KL 散度为 0 几乎是不可能的。然而,因为 KL 散度具有非负性,无论未知分布 q ϕ ( z ∣ x ) {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) qϕ(z∣x) 如何变化,总有
log p θ ( x ( i ) ) ⩾ L ( θ , ϕ ; x ( i ) ) = ∫ q ϕ ( z ∣ x ( i ) ) log p θ ( x ( i ) , z ) q ϕ ( z ∣ x ( i ) ) d z = ∫ q ϕ ( z ∣ x ( i ) ) [ − log q ϕ ( z ∣ x ( i ) ) + log p θ ( x ( i ) , z ) ] d z = E q ϕ ( z ∣ x ( i ) ) [ − log q ϕ ( z ∣ x ( i ) ) + log p θ ( x ( i ) , z ) ] . (4.2) \begin{aligned} \log {p_\theta }\left( {{{\mathbf{x}}^{\left( i \right)}}} \right) &\geqslant \mathcal{L}\left( {\theta ,\phi ;{{\mathbf{x}}^{\left( i \right)}}} \right) \\ &= \int {{q_\phi }\left( {{\mathbf{z}}|{{\mathbf{x}}^{\left( i \right)}}} \right)\log \frac{{{p_\theta }\left( {{{\mathbf{x}}^{\left( i \right)}},{\mathbf{z}}} \right)}}{{{q_\phi }\left( {{\mathbf{z}}|{{\mathbf{x}}^{\left( i \right)}}} \right)}}d{\mathbf{z}}} \\ &= \int {{q_\phi }\left( {{\mathbf{z}}|{{\mathbf{x}}^{\left( i \right)}}} \right)\left[ { - \log {q_\phi }\left( {{\mathbf{z}}|{{\mathbf{x}}^{\left( i \right)}}} \right) + \log {p_\theta }\left( {{{\mathbf{x}}^{\left( i \right)}},{\mathbf{z}}} \right)} \right]d{\mathbf{z}}} \\ &= {\mathbb{E}_{{q_\phi }\left( {{\mathbf{z}}|{{\mathbf{x}}^{\left( i \right)}}} \right)}}\left[ { - \log {q_\phi }\left( {{\mathbf{z}}|{{\mathbf{x}}^{\left( i \right)}}} \right) + \log {p_\theta }\left( {{{\mathbf{x}}^{\left( i \right)}},{\mathbf{z}}} \right)} \right]. \\ \end{aligned} \tag{4.2} logpθ(x(i))⩾L(θ,ϕ;x(i))=∫qϕ(z∣x(i))logqϕ(z∣x(i))pθ(x(i),z)dz=∫qϕ(z∣x(i))[−logqϕ(z∣x(i))+logpθ(x(i),z)]dz=Eqϕ(z∣x(i))[−logqϕ(z∣x(i))+logpθ(x(i),z)].(4.2)
所以我们也将 L ( θ , ϕ ; x ) {\cal L}\left( {\theta ,\phi ;{\bf{x}}} \right) L(θ,ϕ;x) 称为变分下界。注意,因为
− log q ϕ ( z ∣ x ) + log p θ ( x , z ) = − log q ϕ ( z ∣ x ) + log p θ ( x ∣ z ) + log p θ ( z ) = − log q ϕ ( z ∣ x ) p θ ( z ) + log p θ ( x ∣ z ) , (4.3) \begin{aligned} &- \log {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) + \log {p_\theta }\left( {{\bf{x}},{\bf{z}}} \right)\\ = &- \log {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) + \log {p_\theta }\left( {{\bf{x}}|{\bf{z}}} \right) + \log {p_\theta }\left( {\bf{z}} \right)\\ = &- \log \frac{{{q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right)}}{{{p_\theta }\left( {\bf{z}} \right)}} + \log {p_\theta }\left( {{\bf{x}}|{\bf{z}}} \right), \end{aligned} \tag{4.3} ==−logqϕ(z∣x)+logpθ(x,z)−logqϕ(z∣x)+logpθ(x∣z)+logpθ(z)−logpθ(z)qϕ(z∣x)+logpθ(x∣z),(4.3)
所以变分下界还可表示为
L ( θ , ϕ ; x ( i ) ) = E q ϕ ( z ∣ x ( i ) ) [ − log q ϕ ( z ∣ x ( i ) ) + log p θ ( x ( i ) , z ) ] = E q ϕ ( z ∣ x ( i ) ) [ − log q ϕ ( z ∣ x ( i ) ) p θ ( z ) + log p θ ( x ( i ) ∣ z ) ] = − D K L ( q ϕ ( z ∣ x ( i ) ) ∥ p θ ( z ) ) + E q ϕ ( z ∣ x ( i ) ) [ log p θ ( x ( i ) ∣ z ) ] . (4.4) \begin{aligned} \mathcal{L}\left( {\theta ,\phi ;{{\mathbf{x}}^{\left( i \right)}}} \right) &= {\mathbb{E}_{{q_\phi }\left( {{\mathbf{z}}|{{\mathbf{x}}^{\left( i \right)}}} \right)}}\left[ { - \log {q_\phi }\left( {{\mathbf{z}}|{{\mathbf{x}}^{\left( i \right)}}} \right) + \log {p_\theta }\left( {{{\mathbf{x}}^{\left( i \right)}},{\mathbf{z}}} \right)} \right] \\ &= {\mathbb{E}_{{q_\phi }\left( {{\mathbf{z}}|{{\mathbf{x}}^{\left( i \right)}}} \right)}}\left[ { - \log \frac{{{q_\phi }\left( {{\mathbf{z}}|{{\mathbf{x}}^{\left( i \right)}}} \right)}}{{{p_\theta }\left( {\mathbf{z}} \right)}} + \log {p_\theta }\left( {{{\mathbf{x}}^{\left( i \right)}}|{\mathbf{z}}} \right)} \right] \\ &= - {D_{KL}}\left( {{q_\phi }\left( {{\mathbf{z}}|{{\mathbf{x}}^{\left( i \right)}}} \right)\parallel {p_\theta }\left( {\mathbf{z}} \right)} \right) + {\mathbb{E}_{{q_\phi }\left( {{\mathbf{z}}|{{\mathbf{x}}^{\left( i \right)}}} \right)}}\left[ {\log {p_\theta }\left( {{{\mathbf{x}}^{\left( i \right)}}|{\mathbf{z}}} \right)} \right]. \\ \end{aligned} \tag{4.4} L(θ,ϕ;x(i))=Eqϕ(z∣x(i))[−logqϕ(z∣x(i))+logpθ(x(i),z)]=Eqϕ(z∣x(i))[−logpθ(z)qϕ(z∣x(i))+logpθ(x(i)∣z)]=−DKL(qϕ(z∣x(i))∥pθ(z))+Eqϕ(z∣x(i))[logpθ(x(i)∣z)].(4.4)
如果能够最大化变分下界,则边缘概率 p θ ( x ) {p_\theta }\left( {\bf{x}} \right) pθ(x) 也更有可能取更大的值。我们把这种最大化变分下界的方法称为变分贝叶斯(Variational Bayesian, VB)算法。
和 EM 算法一样,我们的目的也是要最大化变分下界 L ( θ , ϕ ; x ) {\cal L}\left( {\theta ,\phi ;{\bf{x}}} \right) L(θ,ϕ;x),因此 EM 算法可认为是一种特殊的 VB 算法。但不同的地方在于,EM 算法的变分下界中未知分布 q ϕ ( z ∣ x ) {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) qϕ(z∣x) 是由后验概率 p θ ( z ∣ x ) {p_\theta }\left( {{\bf{z}}|{\bf{x}}} \right) pθ(z∣x) 唯一决定的,因此参数 ϕ \phi ϕ 并不是真正需要优化的对象,然而问题在于后验概率在实际中几乎无法计算。对于 VB 算法,因为对于固定的参数 θ \theta θ 边缘概率 p θ ( x ) {p_\theta }\left( {\bf{x}} \right) pθ(x) 是固定的,当我们在最大化变分下界的时候,等价于在最小化式 (4.1) 中的 KL 散度,也就是使得 KL 散度不断往 0 逼近。这时我们就能明白引入 q ϕ ( z ∣ x ) {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) qϕ(z∣x) 的意义,我们希望在优化随机系统参数 θ \theta θ 的同时,联合地优化参数 ϕ \phi ϕ 使得 q ϕ ( z ∣ x ) {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) qϕ(z∣x) 能够不断地逼近真正的后验概率 p θ ( z ∣ x ) {p_\theta }\left( {{\bf{z}}|{\bf{x}}} \right) pθ(z∣x),从而令 VB 算法能够不断地向 EM 算法靠拢。对于 EM 算法而言,通过最大化变分下界,可以保证参数 θ \theta θ 能够收敛到边缘概率 p θ ( X ) {p_\theta }\left( {\bf{X}} \right) pθ(X) 一个极大值点,这也保证了 VB 算法的收敛性。由于 θ \theta θ 与 ϕ \phi ϕ 是联合优化的,所以 VB 算法能有更大的灵活性,对 q ϕ ( z ∣ x ) {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) qϕ(z∣x) 分布类型的限制也相当宽松,迭代时也无需将整个数据集的样本纳入计算,而可以基于随机梯度下降法每次只使用少量几个样本,这使其能够在线地对不断增加的新样本进行优化,同时也可以避免过早地陷入一个局部最优解中。因此,现在的问题转化为如何联合地优化参数 θ \theta θ 与 ϕ \phi ϕ 使变分下界最大化。
为了最大化变分下界,我们可以采用梯度下降的方法,因此首先要计算其梯度。为了公式的简洁,我们将变分下界中需要计算数学期望的部分用函数 f ( z ) f\left( {\bf{z}} \right) f(z) 来表示,可得关于 ϕ \phi ϕ 的梯度为
∇ ϕ E q ϕ ( z ∣ x ) [ f ( z ) ] = ∇ ϕ ∫ f ( z ) q ϕ ( z ∣ x ) d z = ∫ f ( z ) ∇ ϕ q ϕ ( z ∣ x ) d z = ∫ f ( z ) q ϕ ( z ∣ x ) ∇ ϕ log q ϕ ( z ∣ x ) d z = E q ϕ ( z ∣ x ) [ f ( z ) ∇ ϕ log q ϕ ( z ∣ x ) ] . (4.5) \begin{aligned} &{\nabla _\phi }{\mathbb{E}_{{q_\phi }\left( {{\mathbf{z}}|{\mathbf{x}}} \right)}}\left[ {f\left( {\mathbf{z}} \right)} \right] \\ = &{\nabla _\phi }\int {f\left( {\mathbf{z}} \right){q_\phi }\left( {{\mathbf{z}}|{\mathbf{x}}} \right)d{\mathbf{z}}} \\ = &\int {f\left( {\mathbf{z}} \right){\nabla _\phi }{q_\phi }\left( {{\mathbf{z}}|{\mathbf{x}}} \right)d{\mathbf{z}}} \\ = &\int {f\left( {\mathbf{z}} \right){q_\phi }\left( {{\mathbf{z}}|{\mathbf{x}}} \right){\nabla _\phi }\log {q_\phi }\left( {{\mathbf{z}}|{\mathbf{x}}} \right)d{\mathbf{z}}} \\ = &{\mathbb{E}_{{q_\phi }\left( {{\mathbf{z}}|{\mathbf{x}}} \right)}}\left[ {f\left( {\mathbf{z}} \right){\nabla _\phi }\log {q_\phi }\left( {{\mathbf{z}}|{\mathbf{x}}} \right)} \right]. \\ \end{aligned} \tag{4.5} ====∇ϕEqϕ(z∣x)[f(z)]∇ϕ∫f(z)qϕ(z∣x)dz∫f(z)∇ϕqϕ(z∣x)dz∫f(z)qϕ(z∣x)∇ϕlogqϕ(z∣x)dzEqϕ(z∣x)[f(z)∇ϕlogqϕ(z∣x)].(4.5)
因为式 (4.5) 属于随机变量的数学期望,一种自然而然的想法是使用蒙特卡洛方法进行估计。即对于函数 f ( z ) f\left( {\bf{z}} \right) f(z) 在 q ϕ ( z ∣ x ) {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) qϕ(z∣x) 分布下的数学期望,可对随机变量 z ∼ q ϕ ( z ∣ x ) {\bf{z}} \sim {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) z∼qϕ(z∣x) 进行 L L L 次独立同分布的采样,于是有
E q ϕ ( z ∣ x ) [ f ( z ) ] = ∫ q ϕ ( z ∣ x ) f ( z ) d z ≃ 1 L ∑ l = 1 L f ( z ( l ) ) . (4.6) {\mathbb{E}_{{q_\phi }\left( {{\mathbf{z}}|{\mathbf{x}}} \right)}}\left[ {f\left( {\mathbf{z}} \right)} \right] = \int {{q_\phi }\left( {{\mathbf{z}}|{\mathbf{x}}} \right)f\left( {\mathbf{z}} \right)d{\mathbf{z}}} \simeq \frac{1}{L}\sum\limits_{l = 1}^L {f\left( {{{\mathbf{z}}^{\left( l \right)}}} \right)} .\tag{4.6} Eqϕ(z∣x)[f(z)]=∫qϕ(z∣x)f(z)dz≃L1l=1∑Lf(z(l)).(4.6)
然而问题在于,当完成采样与估计后,代价函数就不再与参数 ϕ \phi ϕ 相关了(这里先不考虑 f ( z ) f\left( {\bf{z}} \right) f(z) 与 ϕ \phi ϕ 相关)。也就是说,采样操作关于 ϕ \phi ϕ 是不可导的。从这也能看出 EM 算法与 VB 算法的区别,因为 EM 算法中 ϕ \phi ϕ 并不作为可优化的参数,所以对 EM 算法使用蒙特卡洛估计不需要考虑不可导问题。不过庆幸的是,我们通过式 (4.5) 中的导数变换将参数 ϕ \phi ϕ 保留在了需要求数学期望的函数中,避免梯度消失的问题。但式 (4.5) 主要的问题在于,由于 VB 算法每次迭代通常只使用少数几个样本, q ϕ ( z ∣ x ) {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) qϕ(z∣x) 的方差在实际中会比较大,由式 (4.6) 所定义蒙特卡洛估计的结果也往往具有较大的误差,这对于参数 ϕ \phi ϕ 的收敛有非常大的影响。为了解决以上问题,论文提出了重参数化(Reparameterization)的方法。
以高斯分布为例,对于随机变量 z ∼ p ( z ) = N ( μ , σ 2 ) z \sim p\left( z \right) = {\cal N}\left( {\mu ,{\sigma ^2}} \right) z∼p(z)=N(μ,σ2),其实际可由标准高斯分布 ε ∼ p ( ε ) = N ( 0 , 1 ) \varepsilon \sim p\left( \varepsilon \right) = {\cal N}\left( {0,1} \right) ε∼p(ε)=N(0,1) 通过函数 z = f ( ε ) = μ + σ ε z = f\left( \varepsilon \right) = \mu + \sigma \varepsilon z=f(ε)=μ+σε 变换而来。因此,当分布属于某些特定类型时,如高斯分布、指数分布、拉普拉斯分布等等,对于 z ∼ q ϕ ( z ∣ x ) {\bf{z}} \sim {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) z∼qϕ(z∣x),通常可由某个独立的边缘分布 ε ∼ p ( ε ) \varepsilon \sim p\left( \varepsilon \right) ε∼p(ε),如标准正态分布,通过确定性函数 z = g ϕ ( ε , x ) {\bf{z}} = {g_\phi }\left( {\varepsilon ,{\bf{x}}} \right) z=gϕ(ε,x) 变换而来。因此对于式 (4.6) 中的蒙特卡洛估计,我们可以将其转换为
E q ϕ ( z ∣ x ) [ f ( z ) ] = E p ( ε ) [ f ( g ϕ ( ε , x ) ) ] ≃ 1 L ∑ l = 1 L f ( g ϕ ( ε ( l ) , x ) ) . (4.7) {\mathbb{E}_{{q_\phi }\left( {{\mathbf{z}}|{\mathbf{x}}} \right)}}\left[ {f\left( {\mathbf{z}} \right)} \right] = {\mathbb{E}_{p\left( \varepsilon \right)}}\left[ {f\left( {{g_\phi }\left( {\varepsilon ,{\mathbf{x}}} \right)} \right)} \right] \simeq \frac{1}{L}\sum\limits_{l = 1}^L {f\left( {{g_\phi }\left( {{\varepsilon ^{\left( l \right)}},{\mathbf{x}}} \right)} \right)} .\tag{4.7} Eqϕ(z∣x)[f(z)]=Ep(ε)[f(gϕ(ε,x))]≃L1l=1∑Lf(gϕ(ε(l),x)).(4.7)
此时采样所依据的分布不再与参数 ϕ \phi ϕ 相关,但是我们通过确定性函数 z = g ϕ ( ε , x ) {\bf{z}} = {g_\phi }\left( {\varepsilon ,{\bf{x}}} \right) z=gϕ(ε,x) 保留了 ϕ \phi ϕ 对于 f ( z ) f\left( {\bf{z}} \right) f(z) 数学期望的影响,这样我们就实现了采样操作从不可导到可导的转变。同时,由于每次采样所依据的分布是固定的,这也可以在一定程度上减小蒙特卡洛估计的误差,对于参数的收敛也是十分有利的。注意,因为变分下界本身也是关于 q ϕ ( z ∣ x ) {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) qϕ(z∣x) 分布的数学期望形式,所以我们没必要直接对式 (4.5) 中的梯度进行重参数化的蒙特卡洛估计,而只需对变分下界本身进行估计即可,这样我们可以把相关的梯度计算交给自动微分等技术来实现。
回顾本节开头,我们提到了两种形式的变分下界。对于式 (4.2) 定义的第一种形式,根据以上的重参数方法与蒙特卡洛估计,可得以下近似
L ~ A ( θ , ϕ ; x ( i ) ) = 1 L ∑ l = 1 L log p θ ( x ( i ) , z ( i , l ) ) − log q ϕ ( z ( i , l ) ∣ x ( i ) ) , w h e r e z ( i , l ) = g ϕ ( ε ( i , l ) , x ( i ) ) , ε ( i , l ) ∼ p ( ε ) . (4.8) \begin{array}{l} {{\tilde {\cal L}}^A}\left( {\theta ,\phi ;{{\bf{x}}^{\left( i \right)}}} \right) = \frac{1}{L}\sum\limits_{l = 1}^L {\log {p_\theta }\left( {{{\bf{x}}^{\left( i \right)}},{{\bf{z}}^{\left( {i,l} \right)}}} \right) - \log {q_\phi }\left( {{{\bf{z}}^{\left( {i,l} \right)}}|{{\bf{x}}^{\left( i \right)}}} \right)} ,\\ {\rm{where }} {\text{ }} {{\bf{z}}^{\left( {i,l} \right)}} = {g_\phi }\left( {{\varepsilon ^{\left( {i,l} \right)}},{{\bf{x}}^{\left( i \right)}}} \right),\;{\varepsilon ^{\left( {i,l} \right)}} \sim p\left( \varepsilon \right). \end{array}\tag{4.8} L~A(θ,ϕ;x(i))=L1l=1∑Llogpθ(x(i),z(i,l))−logqϕ(z(i,l)∣x(i)),where z(i,l)=gϕ(ε(i,l),x(i)),ε(i,l)∼p(ε).(4.8)
对于式 (4.4) 定义的第二种形式,由于其第一部分为 KL 散度,而 KL 散度对于某些分布类型具有解析的表达式,例如高斯分布等,所以实际中并不需要对其进行蒙特卡洛估计。因此,当 KL 散度具有解析表达式时,我们更倾向于使用第二种变分下界形式,并有以下近似
L ~ B ( θ , ϕ ; x ( i ) ) = − D K L ( q ϕ ( z ∣ x ( i ) ) ∥ p θ ( z ) ) + 1 L ∑ l = 1 L log p θ ( x ( i ) ∣ z ( i , l ) ) , w h e r e z ( i , l ) = g ϕ ( ε ( i , l ) , x ( i ) ) , ε ( i , l ) ∼ p ( ε ) . (4.9) \begin{array}{l} {{\tilde {\cal L}}^B}\left( {\theta ,\phi ;{{\bf{x}}^{\left( i \right)}}} \right) = - {D_{KL}}\left( {{q_\phi }\left( {{\bf{z}}|{{\bf{x}}^{\left( i \right)}}} \right)\parallel {p_\theta }\left( {\bf{z}} \right)} \right) + \frac{1}{L}\sum\limits_{l = 1}^L {\log {p_\theta }\left( {{{\bf{x}}^{\left( i \right)}}|{{\bf{z}}^{\left( {i,l} \right)}}} \right)} ,\\ {\rm{where }} {\text{ }} {{\bf{z}}^{\left( {i,l} \right)}} = {g_\phi }\left( {{\varepsilon ^{\left( {i,l} \right)}},{{\bf{x}}^{\left( i \right)}}} \right),\;{\varepsilon ^{\left( {i,l} \right)}} \sim p\left( \varepsilon \right). \end{array}\tag{4.9} L~B(θ,ϕ;x(i))=−DKL(qϕ(z∣x(i))∥pθ(z))+L1l=1∑Llogpθ(x(i)∣z(i,l)),where z(i,l)=gϕ(ε(i,l),x(i)),ε(i,l)∼p(ε).(4.9)
这时 KL 散度就相当于对 ϕ \phi ϕ 的规整化,使得所估计的后验概率 q ϕ ( z ∣ x ) {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) qϕ(z∣x) 尽量与先验 p θ ( z ) {p_\theta }\left( {\bf{z}} \right) pθ(z) 相近。当给定数据集 X = { x i } i = 1 N {\bf{X}} = \left\{ {{{\bf{x}}^i}} \right\}_{i = 1}^N X={xi}i=1N 时,在一次迭代中使用所有样本往往是比较低效的。类似于神经网络的训练方法,每次我们可随机抽取 M M M 个样本,组成一个 minibatch,即为 X M = { x i } i = 1 M {{\bf{X}}^M} = \left\{ {{{\bf{x}}^i}} \right\}_{i = 1}^M XM={xi}i=1M,那么对完整数据集 X {\bf{X}} X 变分下界的估计可表示为
L ( θ , ϕ ; X ) ≃ N M L ~ ( θ , ϕ ; X M ) = N M ∑ i = 1 M L ~ ( θ , ϕ ; x ( i ) ) . (4.10) {\cal L}\left( {\theta ,\phi ;{\bf{X}}} \right) \simeq \frac{N}{M}\tilde {\cal L}\left( {\theta ,\phi ;{{\bf{X}}^M}} \right) = \frac{N}{M}\sum\limits_{i = 1}^M {\tilde {\cal L}\left( {\theta ,\phi ;{{\bf{x}}^{\left( i \right)}}} \right)} .\tag{4.10} L(θ,ϕ;X)≃MNL~(θ,ϕ;XM)=MNi=1∑ML~(θ,ϕ;x(i)).(4.10)
论文表示,当 M M M 足够大如 M = 100 M = 100 M=100 时,关于变分下界的蒙特卡洛估计所需采样次数 L L L 可以低至 1 而保证参数的收敛速度与准确性。对于 L ~ ( θ , ϕ ; X M ) \tilde {\cal L}\left( {\theta ,\phi ;{{\bf{X}}^M}} \right) L~(θ,ϕ;XM) 我们不要求直接求得其极值点,只需要求得其梯度 ∇ θ , ϕ L ~ ( θ , ϕ ; X M ) {\nabla _{\theta ,\phi }}\tilde {\cal L}\left( {\theta ,\phi ;{{\bf{X}}^M}} \right) ∇θ,ϕL~(θ,ϕ;XM),然后根据如随机梯度下降等方法对当前最优解进行调整即可,这与神经网络的训练方法是一样的。根据式 (4.9) 所定义的代价函数,我们也能很容易地将变分贝叶斯与自编码神经网络联系起来,从而获得了我们下面所要介绍的变分自编码器。
5 变分自编码器
通过前面的内容,我们介绍了带有潜在变量的随机系统,并且知道一个可能具有较高维度的可观测数据 x {\bf{x}} x,能够通过具有较低维度的不可观测的潜在随机向量 z {\bf{z}} z 采样并估计而来,这个过程可以称为对 z {\bf{z}} z 的解码。同样地,我们也可以基于可观测数据 x {\bf{x}} x 估计潜在向量 z {\bf{z}} z 的具体分布参数,这个过程也可以称为对 x {\bf{x}} x 的编码。这种“编码-解码”的模式也正是自编码神经网络的核心。本节内容将介绍如何将自编码器与变分贝叶斯结合,从而赋予自编码器以随机性以及对于任意潜在向量的生成能力。

自编码器是一种确定性模型,其架构如图 2 所示。自编码器分为编码与解码两部分,它们通常可以通过包括多层感知机(MLP)以及卷积神经网络(CNN),或者其他能够对信息进行压缩与解压缩的架构来实现。对于编码和解码,我们可以分别使用某种具有复杂形式的函数来表示,如
z = f e n c ( x ) , x ′ = g d e c ( z ) . (5.1) {\bf{z}} = {f_{enc}}\left( {\bf{x}} \right),\quad {\bf{x}}' = {g_{dec}}\left( {\bf{z}} \right).\tag{5.1} z=fenc(x),x′=gdec(z).(5.1)
这个过程中,我们要最小化解码重构误差,即有代价函数
L = 1 2 ∑ x ∥ x − x ′ ∥ 2 2 = 1 2 ∑ x ∥ x − g d e c ( f e n c ( x ) ) ∥ 2 2 . (5.2) {\cal L} = \frac{1}{2}\sum\limits_{\bf{x}} {\left\| {{\bf{x}} - {\bf{x}}'} \right\|_2^2} = \frac{1}{2}\sum\limits_{\bf{x}} {\left\| {{\bf{x}} - {g_{dec}}\left( {{f_{enc}}\left( {\bf{x}} \right)} \right)} \right\|_2^2} .\tag{5.2} L=21x∑∥x−x′∥22=21x∑∥x−gdec(fenc(x))∥22.(5.2)
由于 z {\bf{z}} z 的维度通常远远小于 x {\bf{x}} x 的维度,所以自编码器并不是简单地把输入复制到输出,而是需要具备信息压缩的能力,并且能够通过更少的维度准确地还原更高维的内容。
回顾变分贝叶斯的内容,对于变分下界第二种形式,我们可得变分贝叶斯算法的代价函数
L ( θ , ϕ ; x ( i ) ) ≃ − D K L ( q ϕ ( z ∣ x ( i ) ) ∥ p θ ( z ) ) + 1 L ∑ l = 1 L log p θ ( x ( i ) ∣ z ( i , l ) ) , w h e r e z ( i , l ) = g ϕ ( ε ( i , l ) , x ( i ) ) , ε ( i , l ) ∼ p ( ε ) . (5.3) \begin{array}{l} {\cal L}\left( {\theta ,\phi ;{{\bf{x}}^{\left( i \right)}}} \right) \simeq - {D_{KL}}\left( {{q_\phi }\left( {{\bf{z}}|{{\bf{x}}^{\left( i \right)}}} \right)\parallel {p_\theta }\left( {\bf{z}} \right)} \right) + \frac{1}{L}\sum\limits_{l = 1}^L {\log {p_\theta }\left( {{{\bf{x}}^{\left( i \right)}}|{{\bf{z}}^{\left( {i,l} \right)}}} \right)} ,\\ {\rm{where }} {\text{ }} {{\bf{z}}^{\left( {i,l} \right)}} = {g_\phi }\left( {{\varepsilon ^{\left( {i,l} \right)}},{{\bf{x}}^{\left( i \right)}}} \right),\;{\varepsilon ^{\left( {i,l} \right)}} \sim p\left( \varepsilon \right). \end{array}\tag{5.3} L(θ,ϕ;x(i))≃−DKL(qϕ(z∣x(i))∥pθ(z))+L1l=1∑Llogpθ(x(i)∣z(i,l)),where z(i,l)=gϕ(ε(i,l),x(i)),ε(i,l)∼p(ε).(5.3)
出于可实现性的考量,我们这时需要对上式中各种分布分别做出合理的假设。由于 KL 散度对于如高斯分布具有简单的解析形式,即有(具体推导见链接 https://blog.csdn.net/qq_33552519/article/details/130561606 )
D K L ( N ( μ 1 , σ 1 2 ) ∥ N ( μ 2 , σ 2 2 ) ) = ( μ 1 − μ 2 ) 2 + ( σ 1 2 − σ 2 2 ) 2 σ 2 2 + log σ 2 σ 1 . (5.4) {D_{KL}}\left( {{\cal N}\left( {{\mu _1},\sigma _1^2} \right)\parallel {\cal N}\left( {{\mu _2},\sigma _2^2} \right)} \right) = \frac{{{{\left( {{\mu _1} - {\mu _2}} \right)}^2} + \left( {\sigma _1^2 - \sigma _2^2} \right)}}{{2\sigma _2^2}} + \log \frac{{{\sigma _2}}}{{{\sigma _1}}}.\tag{5.4} DKL(N(μ1,σ12)∥N(μ2,σ22))=2σ22(μ1−μ2)2+(σ12−σ22)+logσ1σ2.(5.4)
同时考虑到中心极限定理中高斯分布的普适性,我们不妨假设 q ϕ ( z ∣ x ) {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) qϕ(z∣x), p θ ( z ) {p_\theta }\left( {\bf{z}} \right) pθ(z) 都为高斯分布(一般考虑连续的随机变量 z {\bf{z}} z),并且为了简化代价函数的计算假设它们具有对角阵形式的协方差矩阵,即各个分量都是独立的。一般来说,我们会假设先验 p θ ( z ) {p_\theta }\left( {\bf{z}} \right) pθ(z) 服从标准正态分布即 p θ ( z ) = N ( 0 , I ) {p_\theta }\left( {\bf{z}} \right) = {\cal N}\left( {{\bf{0}},{\bf{I}}} \right) pθ(z)=N(0,I),这是因为该先验理论上不与任何可观测数据 x {\bf{x}} x 相关。对于 q ϕ ( z ∣ x ) {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) qϕ(z∣x),这是一个由观测数据 x {\bf{x}} x 决定的分布,并且有
log q ϕ ( z ∣ x ( i ) ) = log N ( z ; μ ( i ) , σ 2 ( i ) I ) . (5.5) \log {q_\phi }\left( {{\bf{z}}|{{\bf{x}}^{\left( i \right)}}} \right) = \log {\cal N}\left( {{\bf{z}};{\mu ^{\left( i \right)}},{\sigma ^{2\left( i \right)}}{\bf{I}}} \right).\tag{5.5} logqϕ(z∣x(i))=logN(z;μ(i),σ2(i)I).(5.5)
注意在这里, q ϕ ( z ∣ x ( i ) ) {q_\phi }\left( {{\bf{z}}|{{\bf{x}}^{\left( i \right)}}} \right) qϕ(z∣x(i)) 的参数 ϕ \phi ϕ 并不直接等同于高斯分布的两个参数 μ ( i ) {\mu ^{\left( i \right)}} μ(i) 和 σ ( i ) {\sigma ^{\left( i \right)}} σ(i),它们是由关于参数 ϕ \phi ϕ 的复杂函数如神经网络,对于输入的 x ( i ) {{\bf{x}}^{\left( i \right)}} x(i) 映射而得到的。所有的样本 x ( i ) {{\bf{x}}^{\left( i \right)}} x(i) 共享神经网络的权重与偏置 ϕ \phi ϕ,但不同的样本 x ( i ) {{\bf{x}}^{\left( i \right)}} x(i) 通过神经网络映射可得不同的高斯分布参数 μ ( i ) {\mu ^{\left( i \right)}} μ(i) 和 σ ( i ) {\sigma ^{\left( i \right)}} σ(i)。这实际对应了自编码器中的编码部分。尽管变分贝叶斯没有直接从 x ( i ) {{\bf{x}}^{\left( i \right)}} x(i) 编码出 z ( i ) {{\bf{z}}^{\left( i \right)}} z(i),但我们得到了高斯分布的参数,这也可以看作另一种形式的编码。以分布 q ϕ ( z ∣ x ( i ) ) {q_\phi }\left( {{\bf{z}}|{{\bf{x}}^{\left( i \right)}}} \right) qϕ(z∣x(i)) 进行采样,我们就获得了 z ( i ) {{\bf{z}}^{\left( i \right)}} z(i)。而这个过程是随机的,这是确定性自编码器所不具备的特点。基于式 (5.4),容易可得变分下界中的 KL 散度为
− D K L ( q ϕ ( z ∣ x ( i ) ) ∥ p θ ( z ) ) = 1 2 ∑ j = 1 J ( 1 + log ( ( σ j ( i ) ) 2 ) − ( μ j ( i ) ) 2 − ( σ j ( i ) ) 2 ) . (5.6) \begin{array}{l} {-} {D_{KL}}\left( {{q_\phi }\left( {{\bf{z}}|{{\bf{x}}^{\left( i \right)}}} \right)\parallel {p_\theta }\left( {\bf{z}} \right)} \right)\\ = \frac{1}{2}\sum\limits_{j = 1}^J {\left( {1 + \log \left( {{{\left( {\sigma _j^{\left( i \right)}} \right)}^2}} \right) - {{\left( {\mu _j^{\left( i \right)}} \right)}^2} - {{\left( {\sigma _j^{\left( i \right)}} \right)}^2}} \right)} . \end{array}\tag{5.6} −DKL(qϕ(z∣x(i))∥pθ(z))=21j=1∑J(1+log((σj(i))2)−(μj(i))2−(σj(i))2).(5.6)
其中 J J J 为 z {\bf{z}} z 的维度。实际上, q ϕ ( z ∣ x ) {q_\phi }\left( {{\bf{z}}|{\bf{x}}} \right) qϕ(z∣x) 为高斯分布对于蒙特卡洛估计中的重参数方法也是有利的,这时可令采样分布服从标准正态分布 ε ∼ p ( ε ) = N ( 0 , I ) \varepsilon \sim p\left( \varepsilon \right) = {\cal N}\left( {{\bf{0}},{\bf{I}}} \right) ε∼p(ε)=N(0,I),且有变换函数
z ( i , j ) = g ϕ ( ε ( i , l ) , x ( i ) ) = μ ( i ) + σ ( i ) ⊙ ε ( i , l ) . (5.7) {{\mathbf{z}}^{\left( {i,j} \right)}} = {g_\phi }\left( {{\varepsilon ^{\left( {i,l} \right)}},{{\mathbf{x}}^{\left( i \right)}}} \right) = {\mu ^{\left( i \right)}} + {\sigma ^{\left( i \right)}} \odot {\varepsilon ^{\left( {i,l} \right)}}.\tag{5.7} z(i,j)=gϕ(ε(i,l),x(i))=μ(i)+σ(i)⊙ε(i,l).(5.7)
其中 ⊙ \odot ⊙ 代表 element-wise 的相乘。
对于代价函数的第二部分 log p θ ( x ( i ) ∣ z ( i , l ) ) \log {p_\theta }\left( {{{\bf{x}}^{\left( i \right)}}|{{\bf{z}}^{\left( {i,l} \right)}}} \right) logpθ(x(i)∣z(i,l)),由于 x {\bf{x}} x 既可能是离散的(例如二元),也可能是连续的,所以我们可以根据数据的类型选择合适的分布类型假设。例如对于二元数据,我们可以选择伯努利分布;而对于连续数据,一般选择高斯分布会比较合适。这里我们以连续类型数据为例,类似于编码部分,我们并不要求解码部分可以直接输出重构的数据来逼近 x ( i ) {{\bf{x}}^{\left( i \right)}} x(i),解码器只需要估计 p θ ( x ( i ) ∣ z ( i , l ) ) {p_\theta }\left( {{{\bf{x}}^{\left( i \right)}}|{{\bf{z}}^{\left( {i,l} \right)}}} \right) pθ(x(i)∣z(i,l)) 的参数,例如对于高斯分布的均值和方差。因为高斯分布在均值处具有最大的概率密度,所以如果解码器输出的均值与输入的 x ( i ) {{\bf{x}}^{\left( i \right)}} x(i) 越接近,我们就能获得更大的代价函数值。因此让解码器直接输出重构结果来逼近输入 x ( i ) {{\bf{x}}^{\left( i \right)}} x(i),与让解码器输出 p θ ( x ( i ) ∣ z ( i , l ) ) {p_\theta }\left( {{{\bf{x}}^{\left( i \right)}}|{{\bf{z}}^{\left( {i,l} \right)}}} \right) pθ(x(i)∣z(i,l)) 的分布参数是等价的。而后者还赋予了我们生成更多具有现实意义的 x {\bf{x}} x 的能力,而不是仅仅把已知的两个数据 x ( i ) {{\bf{x}}^{\left( i \right)}} x(i)和 x ( j ) {{\bf{x}}^{\left( j \right)}} x(j) 加权叠加的结果。这也是确定性自编码器所不能做到的。
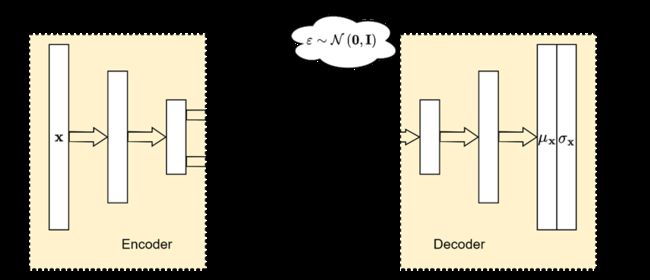
综上所述,我们可以搭建一个变分自编码器如图 3 所示。相比于普通自编码器,变分自编码器的主要特征是包含了一个随机采样操作,且编码器与解码器的输出并不是确定性的潜在特征与重构数据,而是两者的分布参数。根据前面的内容,可得变分自编码器的代价函数为
L ( θ , ϕ ; x ( i ) ) ≃ 1 2 ∑ j = 1 J ( 1 + log ( ( σ j ( i ) ) 2 ) − ( μ j ( i ) ) 2 − ( σ j ( i ) ) 2 ) + 1 L ∑ l = 1 L log p θ ( x ( i ) ∣