史上最强数据结构----单链表的C模拟实现(图示+代码)
单链表的模拟实现
-
- 3.1 链表的概念及结构
- 3.2 链表的分类
- 3.3 链表的实现无头+单向+非循环链表增删查改实现
-
- 3.3.1 链表的定义
- 3.3.2 链表数据的打印
- 3.3.3 链表的尾插
- 3.3.4 链表空间的动态申请
- 3.3.5 链表的头插
- 3.3.6 链表的尾删
- 3.3.7 链表的头删
- 3.3.7 链表任意位置的前插入
- 3.3.8 链表的任意位置的后插入
- 3.3.8 链表的任意位置的删除
- 3.3.9 链表的任意位置的前删除
- 3.3.10 链表的任意位置的后删除
- 3.3.11 链表的销毁
- 3.3.12 链表的总结
3.1 链表的概念及结构
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链 接次序实现的 。

注意:
1. 从上图可以看出,链式结构在逻辑上是连续的,但是在物理上不一定是连续
2. 现实中的节点一般是从堆上申请出来的
3. 从对上申请的空间,是按照一定的策略来分配的,两次申请的空间可能连续,也可能不连续
3.2 链表的分类
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
1、单向或者双向链表
2、带头或者不带头链表
3、循环或非循环链表
最常用的有两种:无头单向非循环链表、带头双向循环链表
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结 构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向 循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
3.3 链表的实现无头+单向+非循环链表增删查改实现
3.3.1 链表的定义
typedef int SLTDataType;//
typedef struct SListNode
{
int data;//val,存储的数据,此处假设存储的数据为int型
struct SListNode* next;//存储下一个节点的位置
}SListNode,SLN;
3.3.2 链表数据的打印
void SListPrint(SListNode* phead)
{
SListNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
3.3.3 链表的尾插
void SListPushBack(SListNode** pphead, SLTDataType x)
{
SListNode* newnode = BuySListNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
//找尾
SListNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
在找尾的过程中,务必不能写成下面的代码:
while(tail!=NULL)
{
tail = tail->next;
}
tail->next = newnode;

当然,上面的介绍的是尾删的情况。
尾插其实也是类似的,尾插的话像上面的代码中,当tail!=NULL不成立之后,tail等于空,然后执行赋值操作,tail->next = newnode这行代码相当于下面的代码:
(*tail).next,此处相当于是对空指针进行解引用,其实就是非法访问了,并还试图非法修改未授权内存中的数据,这将必然会引发程序的崩溃。而且也并没有将新节点的地址存储到之前为节点的next中。
这个地方需要弄明白链表进行遍历的根本原理:

链表是一个相对静态的存储在堆区中的数据空间,我们通过改变栈区中的局部变量tail中的数据(即每一个链表节点的地址)来进行遍历,之所以能够通过tail变量能够进行访问并且修改节点数据的原因就是因为tail的数据类型是SListNode*,即指向节点的指针,指针的类型决定了对指针解引用能够访问的数据类型,所以*tail能够访问堆区中的节点的数据并且能够进行修改。
3.3.4 链表空间的动态申请
SListNode* BuySListNode(SLTDataType x)
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
if (newnode == NULL)
{
printf("malloc fail\n");
exit(-1);
}
else
{
newnode->data = x;
newnode->next = NULL;
}
return newnode;
}
3.3.5 链表的头插
void SListPushFront(SListNode** pphead, SLTDataType x)
{
SListNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
3.3.6 链表的尾删
需要考虑三种情况:
- 空
- 一个节点
- 多个节点
两种写法:
第一种:
void SListPopBack(SListNode** pphead)
{
assert(pphead);
if (*pphead == NULL)//空链表
{
return;
}
else if ((*pphead)->next == NULL)//一个节点
{
free(*pphead);//*pphead就是plist的值
*pphead = NULL;
}
else//多个节点
{
SListNode* tail = *pphead;
SListNode* prev = NULL;//为什么要置为空呢?因为这个地方相当于是指向第一个节点之前的节点,这个节点并不存在,设为空
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;
}
}

这种方式在面对只有一个节点时也不会出现问题。
第二种:
void SListPopBack(SListNode** pphead)
{
assert(pphead);
if (*pphead == NULL)//空链表
{
return;
}
else if ((*pphead)->next == NULL)//一个节点
{
free(*pphead);//*pphead就是plist的值
*pphead = NULL;
}
else//多个节点
{
SListNode* tail = *pphead;
while (tail->next->next != NULL)
{
tail = tail->next;
}
free(tail->next);//释放尾节点
tail->next = NULL;//将新尾节点的next置为NULL
}
}
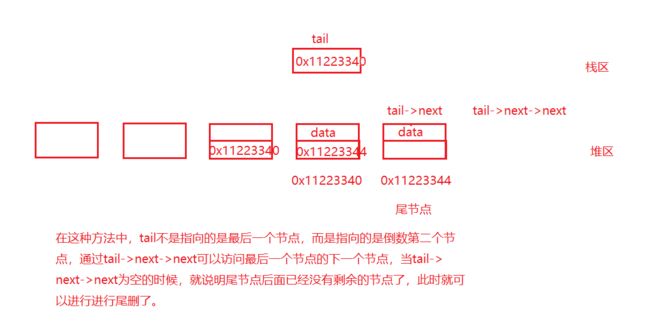
3.3.7 链表的头删
void SListPopFront(SListNode** pphead)
{
assert(pphead);
if (*pphead == NULL)//空链表
{
return;
}
else//非空链表
{
SListNode* next = (*pphead)->next;//next作为临时变量存放的是被删除的节点中next存储的第二个节点的地址
free(*pphead);
*pphead = next;
}
}
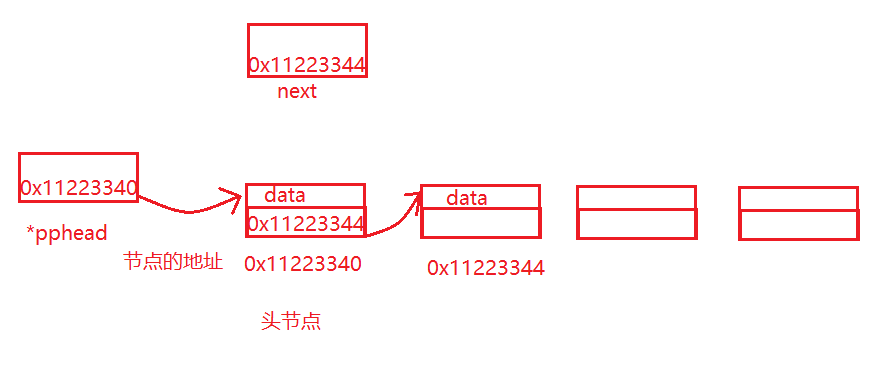
3.3.7 链表任意位置的前插入
void SListInsertBefore(SListNode** pphead, SListNode* pos,SLTDataType x)
{
assert(pphead);
if (*pphead == pos)//pos是第一个节点,相当于头插
{
SListPushFront(pphead, x);
}
else
{
SListNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SListNode* newnode = BuySListNode(x);
prev->next = newnode;
newnode->next = pos;
}
}

3.3.8 链表的任意位置的后插入
两种实现方式:
方式一:
void SListInsertAfter(SListNode* pos, SLTDataType x)
{
assert(pos);
SListNode* newnode = BuySListNode(x);
newnode->next = pos->next;
pos->next = newnode;
//这两行代码顺序是固定的,只能这个顺序,无法进行改变
}
图示:

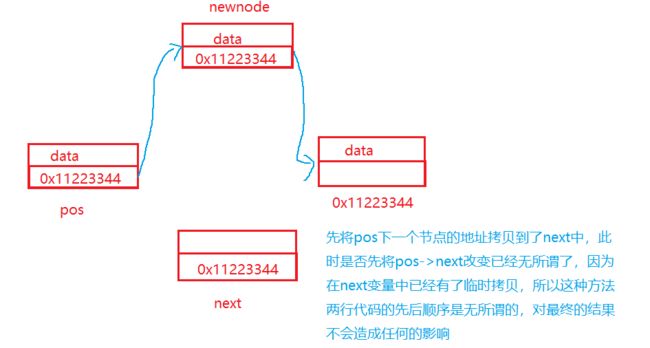
方式二:
void SListInsertAfter(SListNode* pos, SLTDataType x)
{
assert(pos);
SListNode* next = pos->next;
SListNode* newnode = BuySListNode(x);
newnode->next = next;
pos->next = newnode;
//这两行代码可以任意改变顺序,谁先谁后都不影响最后的结果
}
图示:
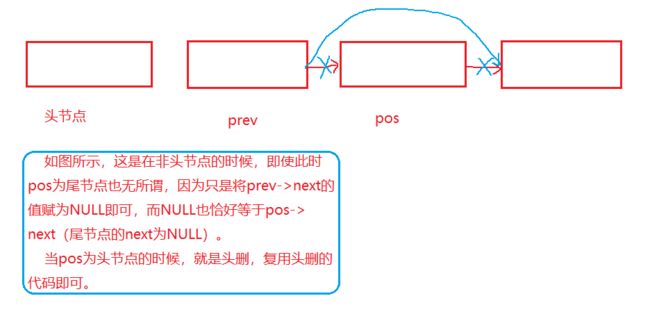
3.3.8 链表的任意位置的删除
void SListErase(SListNode** pphead, SListNode* pos)
{
assert(pphead);
assert(pos);
if (pos == *pphead)//当pos为头节点的时候
{
SListPopFront(pphead);
}
else//当pos为非头节点的时候
{
SListNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;
}
}
图示:
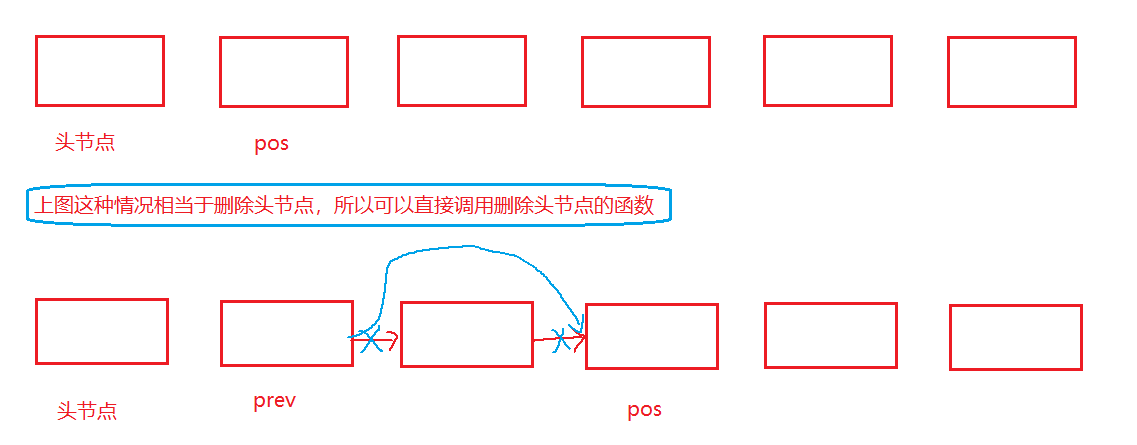
3.3.9 链表的任意位置的前删除
void SListEraseBefore(SListNode** pphead, SListNode* pos)//pos即为任意位置
{
assert(pphead);
assert(pos);
if (pos == *pphead)
{
return;
}
else if(pos==(*pphead)->next)
{
SListPopFront(pphead);
}
else
{
SListNode* prev = *pphead;//prev用来存储pos的前一个位置的前一个位置
while (prev->next->next != pos)
{
prev = prev->next;
}
SListNode* next = prev->next;//保存pos前一个节点的地址
prev->next = prev->next->next;//将prev和pos的两个节点进行连接
free(next);//删除pos的前一个节点
}
}
3.3.10 链表的任意位置的后删除
void SListEraseAfter(SListNode* pos)
{
assert(pos);
SListNode* next = pos->next;
if (next == NULL)//当pos是最后一个节点的时候
{
return;
}
else
{
pos->next = next->next;
free(next);
next = NULL;
}
}
图示:

3.3.11 链表的销毁
void SListDestory(SListNode** pphead)
{
assert(pphead);
SListNode* cur = *pphead;
SListNode* next = *pphead;//是为了存储cur下一个节点的地址,因为free(cur)之后,cur指针指向的内存中的数据可能已经称为乱码了,即不能再正常的使用
while (cur)
{
next = cur->next;
free(cur);
cur = next;
}
*pphead = NULL;
}
3.3.12 链表的总结
总结:单链表结构,适合头插头删。尾部或者中间某个位置插入删除都不适合。如果要使用链表结构单独存储数据,更适合用双向链表。
单链表学习的意义:
- 单链表会作为我们以后学习复杂数据结构的子结构(图的邻接表、哈希桶)
- 单链表会有很多经典的练习题,在笔试面试中会有很多相关的题目。