深度学习-第T10周——数据增强
深度学习-第T10周——数据增强
- 深度学习-第T10周——数据增强
-
- 一、前言
- 二、我的环境
- 三、前期工作
-
- 1、导入数据集
- 2、查看图片数目
- 四、数据预处理
-
- 1、 加载数据
-
- 1.1、设置图片格式
- 1.2、划分训练集
- 1.3、划分验证集
- 1.4、查看标签
- 1.5、再次检查数据
- 1.6、配置数据集
- 2、数据可视化
- 五、数据增强
-
- 1.数据增强
- 2.增强方式
-
- 法一:将其嵌入model中
- 法二:在Dataset数据集中进行数据增强
- 六、模型训练
- 七、自定义增强函数
- 八、总结
深度学习-第T10周——数据增强
一、前言
- 本文为365天深度学习训练营 中的学习记录博客
- 原作者:K同学啊
二、我的环境
- 电脑系统:Windows 10
- 语言环境:Python 3.8.5
- 编译器:colab在线编译
- 深度学习环境:Tensorflow
三、前期工作
数据增强:数据增强可以用少量数据达到非常棒的识别准确率
数据增强的两种方式:
1、将数据增强模块嵌入model中
2、在Dataset数据集中进行数据增强
1、导入数据集
导入数据集,这里使用k同学的数据集,共2个分类。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, models
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os, PIL, pathlib
#1、载入数据
data_dir = ("D:/DL_Camp/CNN/T8/365-7-data")
data_dir = pathlib.Path(data_dir)
这段代码将字符串类型的 data_dir 转换为了 pathlib.Path 类型的对象。pathlib 是 Python3.4 中新增的模块,用于处理文件路径。
通过 Path 对象,可以方便地操作文件和目录,如创建、删除、移动、复制等。
在这里,我们使用 pathlib.Path() 函数将 data_dir 转换为路径对象,这样可以更加方便地进行文件路径的操作和读写等操作。
2、查看图片数目
image_mount = len(list(data_dir.glob("*/*.jpg")))
print(image_mount)
获取指定目录下所有子文件夹中 jpg 格式的文件数量,并将其存储在变量 image_count 中。
data_dir 是一个路径变量,表示需要计算的目标文件夹的路径。
glob() 方法可以返回匹配指定模式(通配符)的文件列表,该方法的参数 “/.jpg” 表示匹配所有子文件夹下以 .jpg 结尾的文件。
list() 方法将 glob() 方法返回的生成器转换为列表,方便进行数量统计。最后,len() 方法计算列表中元素的数量,就得到了指定目录下 jpg 格式文件的总数。
所以,这行代码的作用就是计算指定目录下 jpg 格式文件的数量。
![]()
四、数据预处理
1、 加载数据
1.1、设置图片格式
batch_size = 32
img_height = 224
img_width = 224
1.2、划分训练集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split = 0.3,
subset = 'training',
seed = 12,
image_size = (img_height, img_width),
batch_size = batch_size
)
这行代码使用 TensorFlow 读取指定路径下的图片文件,并生成一个 tf.data.Dataset 对象,用于模型的训练和评估。
具体来说,tf.keras.preprocessing.image_dataset_from_directory() 函数从指定目录中读取图像数据,并自动对其进行标准化和预处理。该函数有以下参数:
data_dir: 字符串,指定要读取的图片文件夹路径。
validation_split: 浮点数,指定验证集所占的比例。默认值为 0.2。
subset: 字符串,表示要读取哪个子集的数据。默认为 “training”,即读取训练集数据。
seed: 整型,用于设置随机种子以生成可重复的随机数,默认为 None。
image_size: 元组,表示所有图像的期望尺寸。例如 (150, 150) 表示将所有图像调整为 150x150 大小。
batch_size: 整型,表示每个批次的样本数。
通过这些参数,函数将指定目录中的图像按照指定大小预处理后,随机划分为训练集和验证集。最终,生成的 tf.data.Dataset 对象包含了划分好的数据集,可以用于后续的模型训练和验证。
需要注意的是,这里的 img_height 和 img_width 变量应该提前定义,并且应该与实际图像的尺寸相对应。同时,batch_size 也应该根据硬件设备的性能合理调整,以充分利用 GPU/CPU 的计算资源。
![]()
1.3、划分验证集
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split = 0.3,
subset = "validation",
seed = 12,
image_size = (img_height, img_width),
batch_size = batch_size
)
这段代码和上一段代码类似,使用 TensorFlow 的 keras.preprocessing.image_dataset_from_directory() 函数从指定的目录中读取图像数据集,并将其划分为训练集和验证集。
其中,data_dir 指定数据集目录的路径,validation_split 表示从数据集中划分出多少比例的数据作为验证集,subset 参数指定为 “validation” 则表示从数据集的 20% 中选择作为验证集,其余 80% 作为训练集。seed 是一个随机种子,用于生成可重复的随机数。image_size 参数指定输出图像的大小,batch_size 表示每批次加载的图像数量。
该函数返回一个 tf.data.Dataset 对象,代表了整个数据集(包含训练集和验证集)。可以使用 train_ds 和 val_ds 两个对象分别表示训练集和验证集。
不过两段代码的 subset 参数值不同,一个是 “training”,一个是 “validation”。
因此,在含有交叉验证或者验证集的深度学习训练过程中,需要定义两个数据集对象 train_ds 和 val_ds。我们已经定义了包含训练集和验证集的数据集对象 train_ds,可以省略这段代码,无需重复定义 val_ds 对象。只要确保最终的训练过程中,两个数据集对象都能够被正确地使用即可。
如果你没有定义 val_ds 对象,可以使用这段代码来创建一个验证数据集对象,用于模型训练和评估,从而提高模型性能。
![]()
1.4、查看标签
由于原始数据集不包含测试集,因此需要创建一个
#由于原始数据集不包含测试集,因此需要创建一个
val_batches = tf.data.experimental.cardinality(val_ds)
test_ds = val_ds.take(val_batches // 5)
val_ds = val_ds.skip(val_batches // 5)
print('Number Of Val Batches: %d' % val_batches)
print('Number Of Validation Batches: %d' % tf.data.experimental.cardinality(val_ds))
print('Number Of test Batches: %d' % tf.data.experimental.cardinality(test_ds))
class_names = train_ds.class_names
class_names
![]()
1.5、再次检查数据
for images_batch, labels_batch in train_ds.take(1):
print(images_batch.shape)
print(labels_batch.shape)
break
![]()
image_batch 是张量的形状(64, 224, 224,3)。这是一批形状2242243的8张图片,最后一维指的是彩色通道RGB
label_batch是形状为(64,)的张量,这些标签对应64张图片
1.6、配置数据集
AUTOTUNE = tf.data.AUTOTUNE
"""
定义 AUTOTUNE 常量
这个常量的作用是指定 TensorFlow 数据管道读取数据时使用的线程个数,使得数据读取可以尽可能地并行化,提升数据读取效率。
具体来说,AUTOTUNE 的取值会根据系统资源和硬件配置等因素自动调节。"""
def preprocess_image(image, label):
return (image / 255.0, label)
"""这个函数的作用是对输入的图像数据进行预处理操作,其中 image 表示输入的原始图像数据,label 表示对应的标签信息。
函数体内的操作是把原始图像数据除以 255,使其数值归一化到 0 和 1 之间。
函数返回一个元组 (image / 255.0, label),其中第一个元素是经过处理后的图像数据,第二个元素是对应的标签信息。
"""
#归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls = AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls = AUTOTUNE)
test_ds = test_ds.map(preprocess_image, num_parallel_calls = AUTOTUNE)
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size = AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size = AUTOTUNE)
"""
通过 map 方法对数据集中的每个元素应用 preprocess_image 函数进行预处理。
num_parallel_calls 参数指定了并行处理的个数,这里设为 AUTOTUNE,表示自动选择最优的并行个数。
接着,对经过预处理后的数据集,通过 cache 方法将其缓存到内存中,以提高读取效率。
然后,再利用 shuffle 方法和 prefetch 方法对训练数据集进行混洗和数据预取,增强训练稳定性和效率。
而验证数据集只需要进行缓存和数据预取操作即可。
"""
在 TensorFlow 中,map 是一种对数据集中的每个元素应用一个函数的方法,常用于数据预处理和数据增强等任务。其使用方式为:
dataset = dataset.map(map_func, num_parallel_calls=None)
其中,dataset 表示待处理的数据集对象,map_func 表示要应用的函数,num_parallel_calls 表示并行执行 map_func 的线程数。
具体来说,map_func 函数会被应用到数据集中的每个元素上,函数接受一个或多个张量作为输入,输出也可以是一个或多个张量。map_func 的定义方式应当符合 TensorFlow 的计算图模型,即是一组 TensorFlow 的计算操作(ops)。
使用 map 方法可以方便地对数据集进行预处理,例如图像数据的归一化、尺寸调整、数据增强等。同时,由于 map 方法本身支持并行处理,因此可以大大加速数据处理的速度。
在使用 map 方法时,应尽可能指定 num_parallel_calls 参数以充分利用计算资源,提高处理效率。
2、数据可视化
plt.figure(figsize = (15, 13))
for images, labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(5, 8, i + 1)
plt.imshow(images[i])
plt.title(class_names[labels[i]])
plt.axis("off")
train_ds.take(1) 是一个方法调用,它返回一个数据集对象 train_ds 中的子集,其中包含了 take() 方法参数指定的数量的样本。
在这个例子中,take(1) 意味着我们从 train_ds 数据集中获取一批包含一个样本的数据块。
因此,for images, labels in train_ds.take(1): 的作用是遍历这个包含一个样本的数据块,并将其中的图像张量和标签张量依次赋值给变量 images 和 labels。具体来说,
它的执行过程如下:
从 train_ds 数据集中获取一批大小为 1 的数据块。
遍历这个数据块,每次获取一个图像张量和一个标签张量。
将当前图像张量赋值给变量 images,将当前标签张量赋值给变量 labels。
执行 for 循环中的代码块,即对当前图像张量和标签张量进行处理。
plt.imshow() 函数是 Matplotlib 库中用于显示图像的函数,它接受一个数组或张量作为输入,并在窗口中显示对应的图像。
在这个代码中,images[i] 表示从训练集中获取的第 i 个图像张量。由于 images 是一个包含多个图像的张量列表,因此使用 images[i] 可以获取其中的一个图像。
plt.axis(“off”) 是 Matplotlib 库中的一个函数调用,它用于控制图像显示时的坐标轴是否可见。
具体来说,当参数为 “off” 时,图像的坐标轴会被关闭,不会显示在图像周围。这个函数通常在 plt.imshow() 函数之后调用,以便在显示图像时去掉多余的细节信息,仅仅显示图像本身。

五、数据增强
1.数据增强
data_augmentation = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.RandomFlip("horizontal_and_vertical"),
tf.keras.layers.experimental.preprocessing.RandomRotation(0.2)
])
image = tf.expand_dims(images[i], 0)
plt.figure(figsize = (8,8))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i+1)
plt.imshow(augmented_image[0])
plt.axis('off')
上述代码定义了一个数据增强模型data_augmentation,用于对图像数据进行随机翻转和旋转操作。具体来说,该模型使用tf.keras.Sequential容器将两个图像处理层拼接在一起:
tf.keras.layers.experimental.preprocessing.RandomFlip(“horizontal_and_vertical”):该层用于对图像进行随机水平和垂直翻转的操作。其中,"horizontal_and_vertical"参数表示对图像进行同时水平和垂直方向上的翻转。如果不需要进行某个方向上的翻转可以分别使用"horizontal"和"vertical"参数。
tf.keras.layers.experimental.preprocessing.RandomRotation(0.2):该层用于对图像进行随机旋转操作。其中,0.2参数表示旋转角度的幅度范围,即在[-20%, 20%]的范围内随机旋转图像。

2.增强方式
法一:将其嵌入model中
model = tf.keras.Sequential([
data_augmentation,
layers.Conv2D(16, 3, padding = "same", activation = 'relu'),
layers.MaxPooling2D()
])
法二:在Dataset数据集中进行数据增强
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE()
def prepare(ds):
ds = ds.map(lambda x, y : (data_augmentation(x, training = True), y), num_parallel_calls = AUTOTUNE)
return ds
train_ds = prepare(train_ds)
六、模型训练
#四、训练模型
model = tf.keras.Sequential([
data_augmentation,
layers.Conv2D(16, 3, padding = 'same', activation = 'relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding = 'same', activation = 'relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding = 'same', activation = 'relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation = 'relu'),
layers.Dense(len(class_names))
])
model.compile(
optimizer = 'adam',
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=( True )),
metrics = ['accuracy']
)
epochs = 20
history = model.fit(
train_ds,
validation_data = val_ds,
epochs = epochs
)
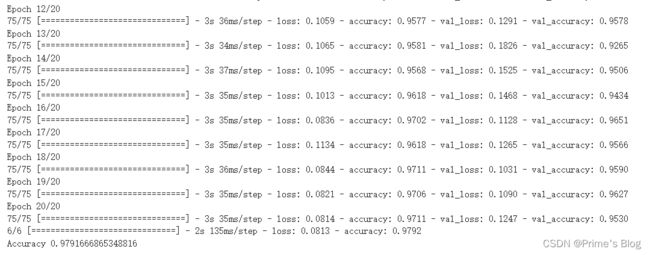
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
七、自定义增强函数
import random
def aug_img(image):
seed = (random.randint(0, 9), 0)
#随机改变图像对比度
stateless_random_brightness = tf.image.stateless_random_contrast(image, lower = 0.1, upper = 1.0, seed = seed)
return stateless_random_brightness
image = tf.expand_dims(images[3] * 255, 0)
print("Min And Max Pixel Values:", image.numpy().min(), image.numpy().max())
plt.figure(figsize = (8, 8))
for i in range(9):
augmented_image = aug_img(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")

八、总结
数据增强可以有效地提高模型的识别精度和泛化能力。在训练过程中对输入数据进行随机变换,可以使得模型更加鲁棒,避免过度拟合。对输入图像进行随机翻转和旋转,可以增加训练数据的多样性,从而提高模型对不同角度和方向的图像进行分类的能力。