【Python】基于机器学习的财务数据分析——识别财务造假
【Python】基于机器学习的财务数据分析——识别财务造假
前言:
本文数据使用了2021泰迪杯官方给出的数据。
其中第一章的代码给出了如何由比赛数据生成案例分析所使用的数据
而第二章则重点介绍了 如何通过上一章的数据进行财务数据分析
文章目录
- 【Python】基于机器学习的财务数据分析——识别财务造假
-
- 第一章 生成财务分析数据
-
- 1.1 Load 比赛的官方数据
- 1.2 数据处理
- 第二章 基于机器学习的财务数据分析——识别财务造假
第一章 生成财务分析数据
1.1 Load 比赛的官方数据
# load lab
import pandas as pd
import numpy as np
# load data
df = pd.read_csv('附件2(样例数据).csv')
df.info()
df
| TICKER_SYMBOL | ACT_PUBTIME | PUBLISH_DATE | END_DATE_REP | END_DATE | REPORT_TYPE | FISCAL_PERIOD | MERGED_FLAG | ACCOUTING_STANDARDS | CURRENCY_CD | ... | CA_TURNOVER | OPER_CYCLE | INVEN_TURNOVER | FA_TURNOVER | TFA_TURNOVER | DAYS_AP | DAYS_INVEN | TA_TURNOVER | AR_TURNOVER | FLAG | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4019 | 5 | 5 | 4 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0 |
| 1 | 4213 | 5 | 5 | 5 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0 |
| 2 | 8166 | 5 | 5 | 3 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0 |
| 3 | 9063 | 5 | 5 | 4 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | 5.3401 | 3.2947 | NaN | 4009.2584 | 4402.6179 | 1.2731 | NaN | 4.6236 | 109.2667 | 0 |
| 4 | 10083 | 5 | 5 | 4 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3558 | 4992858 | 5 | 5 | 4 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | 0.0601 | 6785.7245 | 0.0535 | 32.8540 | 94.7623 | 76.3016 | 6732.3615 | 0.0563 | 6.7463 | 0 |
| 3559 | 4993201 | 4 | 4 | 3 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0 |
| 3560 | 4993297 | 6 | 6 | 5 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0 |
| 3561 | 4998808 | 5 | 5 | 4 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0 |
| 3562 | 4999709 | 5 | 5 | 4 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | 1.2648 | 96.8794 | 4.7511 | 0.2166 | 0.2019 | 169.4288 | 75.7725 | 0.1492 | 17.0560 | 0 |
3563 rows × 363 columns
1.2 数据处理
df1 = df.copy()
df2 = df1.dropna(axis=1)
df2.dropna(axis=0)
| TICKER_SYMBOL | ACT_PUBTIME | PUBLISH_DATE | END_DATE_REP | END_DATE | REPORT_TYPE | FISCAL_PERIOD | MERGED_FLAG | ACCOUTING_STANDARDS | CURRENCY_CD | ... | REVENUE | T_REVENUE | T_PROFIT | OPERATE_PROFIT | COMPR_INC_ATTR_P | T_COMPR_INCOME | N_INCOME_ATTR_P | N_INCOME | T_COGS | FLAG | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4019 | 5 | 5 | 4 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | 6.144704e+08 | 6.144704e+08 | -1.081696e+08 | -1.229547e+08 | -9.021130e+07 | -9.021130e+07 | -9.021130e+07 | -9.021130e+07 | 7.362240e+08 | 0 |
| 1 | 4213 | 5 | 5 | 5 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | 1.103340e+09 | 1.103340e+09 | 1.440264e+08 | 1.417321e+08 | 1.173408e+08 | 1.173408e+08 | 1.173408e+08 | 1.173408e+08 | 9.609019e+08 | 0 |
| 2 | 8166 | 5 | 5 | 3 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | 6.768557e+09 | 6.768557e+09 | 5.501612e+08 | 4.160823e+08 | 4.427106e+08 | 4.427106e+08 | 4.406464e+08 | 4.406464e+08 | 6.374538e+09 | 0 |
| 3 | 9063 | 5 | 5 | 4 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | 3.649249e+10 | 3.649249e+10 | 4.442545e+08 | 4.178863e+08 | 3.603373e+08 | 3.590776e+08 | 3.582523e+08 | 3.569925e+08 | 3.610338e+10 | 0 |
| 4 | 10083 | 5 | 5 | 4 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | 4.090022e+08 | 4.090022e+08 | 5.522668e+07 | 5.422161e+07 | 4.059508e+07 | 4.059508e+07 | 4.059508e+07 | 4.059508e+07 | 3.547806e+08 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3558 | 4992858 | 5 | 5 | 4 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | 1.916369e+08 | 1.916369e+08 | -5.854943e+07 | -6.549837e+07 | -5.698415e+07 | -5.888314e+07 | -5.698415e+07 | -5.888314e+07 | 2.563552e+08 | 0 |
| 3559 | 4993201 | 4 | 4 | 3 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | 7.584324e+08 | 7.584324e+08 | 4.562972e+07 | 4.016267e+07 | 3.719758e+07 | 3.704166e+07 | 3.719758e+07 | 3.704166e+07 | 7.174872e+08 | 0 |
| 3560 | 4993297 | 6 | 6 | 5 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | 8.707040e+08 | 8.707040e+08 | 1.657144e+08 | 1.204156e+08 | 1.428394e+08 | 1.623189e+08 | 1.422310e+08 | 1.615584e+08 | 7.586088e+08 | 0 |
| 3561 | 4998808 | 5 | 5 | 4 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | 1.345086e+09 | 1.345086e+09 | 8.585497e+07 | 7.220415e+07 | 7.851344e+07 | 7.895948e+07 | 7.500529e+07 | 7.545319e+07 | 1.275262e+09 | 0 |
| 3562 | 4999709 | 5 | 5 | 4 | 3 | A | 12 | 1 | CHAS_2007 | CNY | ... | 1.260865e+10 | 1.260865e+10 | 3.371832e+09 | 3.297172e+09 | 2.258473e+09 | 2.677414e+09 | 2.460094e+09 | 2.870661e+09 | 1.165588e+10 | 0 |
3563 rows × 34 columns
df2.to_excel('winner.xlsx',index = False)
df3 = df2.iloc[:,11:]
df3
| FIXED_ASSETS | T_ASSETS | T_LIAB | T_EQUITY_ATTR_P | T_SH_EQUITY | T_LIAB_EQUITY | N_CF_OPERATE_A | C_PAID_FOR_OTH_OP_A | C_INF_FR_OPERATE_A | N_CHANGE_IN_CASH | ... | REVENUE | T_REVENUE | T_PROFIT | OPERATE_PROFIT | COMPR_INC_ATTR_P | T_COMPR_INCOME | N_INCOME_ATTR_P | N_INCOME | T_COGS | FLAG | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.384757e+09 | 3.360603e+09 | 9.086384e+08 | 2.451965e+09 | 2.451965e+09 | 3.360603e+09 | -1.531725e+08 | 8.092480e+07 | 5.484389e+08 | -5.863646e+07 | ... | 6.144704e+08 | 6.144704e+08 | -1.081696e+08 | -1.229547e+08 | -9.021130e+07 | -9.021130e+07 | -9.021130e+07 | -9.021130e+07 | 7.362240e+08 | 0 |
| 1 | 3.550098e+08 | 1.801029e+09 | 4.622409e+08 | 1.338788e+09 | 1.338788e+09 | 1.801029e+09 | 1.530939e+08 | 3.725100e+07 | 1.059183e+09 | -2.576530e+07 | ... | 1.103340e+09 | 1.103340e+09 | 1.440264e+08 | 1.417321e+08 | 1.173408e+08 | 1.173408e+08 | 1.173408e+08 | 1.173408e+08 | 9.609019e+08 | 0 |
| 2 | 1.014511e+09 | 9.033789e+09 | 4.241620e+09 | 4.792168e+09 | 4.792168e+09 | 9.033789e+09 | 8.985383e+08 | 1.011182e+09 | 7.778336e+09 | -7.102159e+08 | ... | 6.768557e+09 | 6.768557e+09 | 5.501612e+08 | 4.160823e+08 | 4.427106e+08 | 4.427106e+08 | 4.406464e+08 | 4.406464e+08 | 6.374538e+09 | 0 |
| 3 | 2.592562e+09 | 1.445027e+10 | 9.246911e+09 | 5.049558e+09 | 5.203356e+09 | 1.445027e+10 | 4.287553e+08 | 3.640225e+09 | 4.261880e+10 | 2.915535e+08 | ... | 3.649249e+10 | 3.649249e+10 | 4.442545e+08 | 4.178863e+08 | 3.603373e+08 | 3.590776e+08 | 3.582523e+08 | 3.569925e+08 | 3.610338e+10 | 0 |
| 4 | 4.234430e+07 | 5.389908e+08 | 2.419290e+08 | 2.970618e+08 | 2.970618e+08 | 5.389908e+08 | 3.351069e+07 | 2.934517e+07 | 4.872505e+08 | 1.073503e+07 | ... | 4.090022e+08 | 4.090022e+08 | 5.522668e+07 | 5.422161e+07 | 4.059508e+07 | 4.059508e+07 | 4.059508e+07 | 4.059508e+07 | 3.547806e+08 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3558 | 1.542683e+08 | 7.881017e+08 | 3.139182e+08 | 4.168727e+08 | 4.741834e+08 | 7.881017e+08 | -5.238869e+06 | 1.838851e+07 | 1.844894e+08 | -9.722585e+07 | ... | 1.916369e+08 | 1.916369e+08 | -5.854943e+07 | -6.549837e+07 | -5.698415e+07 | -5.888314e+07 | -5.698415e+07 | -5.888314e+07 | 2.563552e+08 | 0 |
| 3559 | 2.945962e+08 | 8.894905e+08 | 2.485487e+08 | 6.370977e+08 | 6.409417e+08 | 8.894905e+08 | 8.333100e+07 | 7.960547e+07 | 8.047397e+08 | -8.111294e+07 | ... | 7.584324e+08 | 7.584324e+08 | 4.562972e+07 | 4.016267e+07 | 3.719758e+07 | 3.704166e+07 | 3.719758e+07 | 3.704166e+07 | 7.174872e+08 | 0 |
| 3560 | 3.435635e+09 | 5.628529e+09 | 2.599046e+09 | 2.774693e+09 | 3.029483e+09 | 5.628529e+09 | 4.344513e+08 | 2.430308e+07 | 1.084828e+09 | 8.119653e+07 | ... | 8.707040e+08 | 8.707040e+08 | 1.657144e+08 | 1.204156e+08 | 1.428394e+08 | 1.623189e+08 | 1.422310e+08 | 1.615584e+08 | 7.586088e+08 | 0 |
| 3561 | 1.963836e+09 | 4.936854e+09 | 3.018880e+09 | 1.878145e+09 | 1.917974e+09 | 4.936854e+09 | 7.512584e+07 | 2.379392e+08 | 1.873552e+09 | 1.619822e+08 | ... | 1.345086e+09 | 1.345086e+09 | 8.585497e+07 | 7.220415e+07 | 7.851344e+07 | 7.895948e+07 | 7.500529e+07 | 7.545319e+07 | 1.275262e+09 | 0 |
| 3562 | 4.760795e+09 | 3.820173e+10 | 1.753208e+10 | 1.818157e+10 | 2.066965e+10 | 3.820173e+10 | 1.621028e+09 | 3.193049e+09 | 1.472222e+10 | 3.384381e+08 | ... | 1.260865e+10 | 1.260865e+10 | 3.371832e+09 | 3.297172e+09 | 2.258473e+09 | 2.677414e+09 | 2.460094e+09 | 2.870661e+09 | 1.165588e+10 | 0 |
3563 rows × 23 columns
df3.to_excel('raw_data.xlsx',index = False)
第二章 基于机器学习的财务数据分析——识别财务造假
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_excel('raw_data.xlsx')
df
| FIXED_ASSETS | T_ASSETS | T_LIAB | T_EQUITY_ATTR_P | T_SH_EQUITY | T_LIAB_EQUITY | N_CF_OPERATE_A | C_PAID_FOR_OTH_OP_A | C_INF_FR_OPERATE_A | N_CHANGE_IN_CASH | ... | REVENUE | T_REVENUE | T_PROFIT | OPERATE_PROFIT | COMPR_INC_ATTR_P | T_COMPR_INCOME | N_INCOME_ATTR_P | N_INCOME | T_COGS | FLAG | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.384757e+09 | 3.360603e+09 | 9.086384e+08 | 2.451965e+09 | 2.451965e+09 | 3.360603e+09 | -1.531725e+08 | 8.092480e+07 | 5.484389e+08 | -5.863646e+07 | ... | 6.144704e+08 | 6.144704e+08 | -1.081696e+08 | -1.229547e+08 | -9.021130e+07 | -9.021130e+07 | -9.021130e+07 | -9.021130e+07 | 7.362240e+08 | 0 |
| 1 | 3.550098e+08 | 1.801029e+09 | 4.622409e+08 | 1.338788e+09 | 1.338788e+09 | 1.801029e+09 | 1.530939e+08 | 3.725100e+07 | 1.059183e+09 | -2.576530e+07 | ... | 1.103340e+09 | 1.103340e+09 | 1.440264e+08 | 1.417321e+08 | 1.173408e+08 | 1.173408e+08 | 1.173408e+08 | 1.173408e+08 | 9.609019e+08 | 0 |
| 2 | 1.014511e+09 | 9.033789e+09 | 4.241620e+09 | 4.792168e+09 | 4.792168e+09 | 9.033789e+09 | 8.985383e+08 | 1.011182e+09 | 7.778336e+09 | -7.102159e+08 | ... | 6.768557e+09 | 6.768557e+09 | 5.501612e+08 | 4.160823e+08 | 4.427106e+08 | 4.427106e+08 | 4.406464e+08 | 4.406464e+08 | 6.374538e+09 | 0 |
| 3 | 2.592562e+09 | 1.445027e+10 | 9.246911e+09 | 5.049558e+09 | 5.203356e+09 | 1.445027e+10 | 4.287553e+08 | 3.640225e+09 | 4.261880e+10 | 2.915535e+08 | ... | 3.649249e+10 | 3.649249e+10 | 4.442545e+08 | 4.178863e+08 | 3.603373e+08 | 3.590776e+08 | 3.582523e+08 | 3.569925e+08 | 3.610338e+10 | 0 |
| 4 | 4.234430e+07 | 5.389908e+08 | 2.419290e+08 | 2.970618e+08 | 2.970618e+08 | 5.389908e+08 | 3.351069e+07 | 2.934517e+07 | 4.872505e+08 | 1.073503e+07 | ... | 4.090022e+08 | 4.090022e+08 | 5.522668e+07 | 5.422161e+07 | 4.059508e+07 | 4.059508e+07 | 4.059508e+07 | 4.059508e+07 | 3.547806e+08 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3558 | 1.542683e+08 | 7.881017e+08 | 3.139182e+08 | 4.168727e+08 | 4.741834e+08 | 7.881017e+08 | -5.238869e+06 | 1.838851e+07 | 1.844894e+08 | -9.722585e+07 | ... | 1.916369e+08 | 1.916369e+08 | -5.854943e+07 | -6.549837e+07 | -5.698415e+07 | -5.888314e+07 | -5.698415e+07 | -5.888314e+07 | 2.563552e+08 | 0 |
| 3559 | 2.945962e+08 | 8.894905e+08 | 2.485487e+08 | 6.370977e+08 | 6.409417e+08 | 8.894905e+08 | 8.333100e+07 | 7.960547e+07 | 8.047397e+08 | -8.111294e+07 | ... | 7.584324e+08 | 7.584324e+08 | 4.562972e+07 | 4.016267e+07 | 3.719758e+07 | 3.704166e+07 | 3.719758e+07 | 3.704166e+07 | 7.174872e+08 | 0 |
| 3560 | 3.435635e+09 | 5.628529e+09 | 2.599046e+09 | 2.774693e+09 | 3.029483e+09 | 5.628529e+09 | 4.344513e+08 | 2.430308e+07 | 1.084828e+09 | 8.119653e+07 | ... | 8.707040e+08 | 8.707040e+08 | 1.657144e+08 | 1.204156e+08 | 1.428394e+08 | 1.623189e+08 | 1.422310e+08 | 1.615584e+08 | 7.586088e+08 | 0 |
| 3561 | 1.963836e+09 | 4.936854e+09 | 3.018880e+09 | 1.878145e+09 | 1.917974e+09 | 4.936854e+09 | 7.512584e+07 | 2.379392e+08 | 1.873552e+09 | 1.619822e+08 | ... | 1.345086e+09 | 1.345086e+09 | 8.585497e+07 | 7.220415e+07 | 7.851344e+07 | 7.895948e+07 | 7.500529e+07 | 7.545319e+07 | 1.275262e+09 | 0 |
| 3562 | 4.760795e+09 | 3.820173e+10 | 1.753208e+10 | 1.818157e+10 | 2.066965e+10 | 3.820173e+10 | 1.621028e+09 | 3.193049e+09 | 1.472222e+10 | 3.384381e+08 | ... | 1.260865e+10 | 1.260865e+10 | 3.371832e+09 | 3.297172e+09 | 2.258473e+09 | 2.677414e+09 | 2.460094e+09 | 2.870661e+09 | 1.165588e+10 | 0 |
3563 rows × 23 columns
X, y = df.iloc[:,:-1],df.iloc[:,-1]
y
0 0
1 0
2 0
3 0
4 0
..
3558 0
3559 0
3560 0
3561 0
3562 0
Name: FLAG, Length: 3563, dtype: int64
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 对数据进行标准化处理, 主要是X_train
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss = ss.fit(X_train)
X_train_std = ss.fit_transform(X_train)
X_test_std = ss.fit_transform(X_test)
#--------------- Modllong
#--------------- Modllong
# SVM Classifier
def svm_classifier(train_x, train_y):
from sklearn.svm import SVC
model = SVC(kernel='rbf', probability=True)
model.fit(train_x, train_y)
return model
# KNN Classifier
def knn_classifier(train_x, train_y):
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit(train_x, train_y)
return model
# Logistic Regression Classifier
def logistic_regression_classifier(train_x, train_y):
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(penalty='l2')
model.fit(train_x, train_y)
return model
# DT
def dt(train_x, train_y):
from sklearn import tree
model = tree.DecisionTreeClassifier()
model.fit(train_x, train_y)
return model
# nn
def nn(train_x, train_y):
from sklearn.neural_network import MLPClassifier
model = MLPClassifier(solver='lbfgs', alpha=1e-5,hidden_layer_sizes=(5, 2), random_state=1)
model.fit(train_x, train_y)
return model
train_x = X_train_std
train_y = y_train
model_svc = svm_classifier(train_x, train_y)
model_knn = knn_classifier(train_x, train_y)
model_logistic = logistic_regression_classifier(train_x, train_y)
model_dt = dt(train_x, train_y)
model_nn = nn(train_x, train_y)
# ----------
y_svc = model_svc.predict(X_test_std)
y_knn = model_knn.predict(X_test_std)
y_logistic = model_logistic.predict(X_test_std)
y_dt = model_dt.predict(X_test_std)
y_nn = model_nn.predict(X_test_std)
# 结果分析
from sklearn.metrics import f1_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
# print('分类准确率为:',accuracy_score(y_test,y_svc),accuracy_score(y_test,y_knn),accuracy_score(y_test,y_logistic),accuracy_score(y_test,y_rf))
# print('宏平均准确率:',precision_score(y_test,y_svc,average='macro'),precision_score(y_test,y_knn,average='macro'),precision_score(y_test,y_logistic,average='macro'),precision_score(y_test,y_rf,average='macro'))
# print('微平均准确率:',precision_score(y_test,y_svc,average='micro'),precision_score(y_test,y_knn,average='micro'),precision_score(y_test,y_logistic,average='micro'),precision_score(y_test,y_rf,average='micro'))
# print('宏平均召回率为:',recall_score(y_test,y_svc,average='macro'),recall_score(y_test,y_knn,average='macro'),recall_score(y_test,y_logistic,average='macro'),recall_score(y_test,y_rf,average='macro'))
# print('微平均召回率为:',recall_score(y_test,y_svc,average='micro'),recall_score(y_test,y_knn,average='micro'),recall_score(y_test,y_logistic,average='micro'),recall_score(y_test,y_rf,average='micro'))
# print('宏平均f1值为:',f1_score(y_test,y_svc,average='macro'),f1_score(y_test,y_knn,average='macro'),f1_score(y_test,y_logistic,average='macro'),f1_score(y_test,y_rf,average='macro'))
# print('微平均f1值为:',f1_score(y_test,y_svc,average='micro'),f1_score(y_test,y_knn,average='micro'),f1_score(y_test,y_logistic,average='micro'),f1_score(y_test,y_rf,average='micro'))
# 误差评估
from sklearn.metrics import confusion_matrix
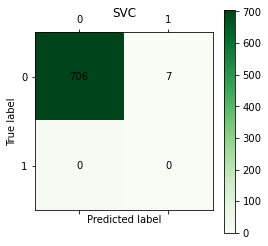
# svc
C=confusion_matrix(y_test, y_svc)
# df=pd.DataFrame(C,index=["财务造假", "财务不造假"],columns=["财务造假", "财务不造假"])
# sns.heatmap(df,annot=True)
plt.matshow(C, cmap=plt.cm.Greens)
plt.colorbar()
for i in range(len(C)):
for j in range(len(C)):
plt.annotate(C[i,j], xy=(i, j), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.title('SVC')
plt.show()
# knn
C=confusion_matrix(y_test, y_knn)
# df=pd.DataFrame(C,index=["财务造假", "财务不造假"],columns=["财务造假", "财务不造假"])
# sns.heatmap(df,annot=True)
plt.matshow(C, cmap=plt.cm.Greens)
plt.colorbar()
for i in range(len(C)):
for j in range(len(C)):
plt.annotate(C[i,j], xy=(i, j), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.title('KNN')
plt.show()
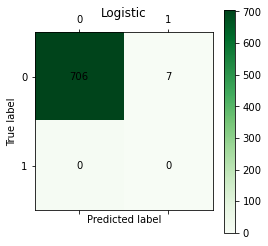
# log
C=confusion_matrix(y_test, y_logistic)
# df=pd.DataFrame(C,index=["财务造假", "财务不造假"],columns=["财务造假", "财务不造假"])
# sns.heatmap(df,annot=True)
plt.matshow(C, cmap=plt.cm.Greens)
plt.colorbar()
for i in range(len(C)):
for j in range(len(C)):
plt.annotate(C[i,j], xy=(i, j), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.title('Logistic')
plt.show()
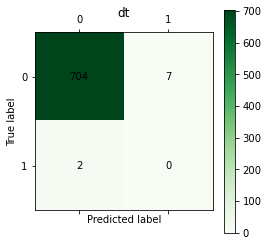
# dt
C=confusion_matrix(y_test, y_dt)
# df=pd.DataFrame(C,index=["财务造假", "财务不造假"],columns=["财务造假", "财务不造假"])
# sns.heatmap(df,annot=True)
plt.matshow(C, cmap=plt.cm.Greens)
plt.colorbar()
for i in range(len(C)):
for j in range(len(C)):
plt.annotate(C[i,j], xy=(i, j), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.title('dt')
plt.show()
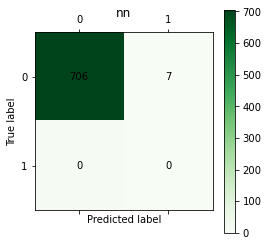
# nn
C=confusion_matrix(y_test, y_nn)
# df=pd.DataFrame(C,index=["财务造假", "财务不造假"],columns=["财务造假", "财务不造假"])
# sns.heatmap(df,annot=True)
plt.matshow(C, cmap=plt.cm.Greens)
plt.colorbar()
for i in range(len(C)):
for j in range(len(C)):
plt.annotate(C[i,j], xy=(i, j), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.title('nn')
plt.show()