JVM(Java Virtual Machine)
JVM
- 内存区域划分
-
- Program Counter Register(程序计数器)
- Native Method Stacks(本地方法栈)
- JVM Stacks(虚拟机栈)
-
- 区分虚拟机栈与本地方法栈
- 栈是线程私有的
- Heap(堆区)
- Metaspace(元数据区)
- 总结
- 类加载
-
- 类加载的流程
-
- 加载
- 验证
- 准备
- 解析
-
- 符号引用转为直接引用
- 初始化
- 类加载的时机
- 双亲委派模型
-
- 上述类加载器如何配合工作
- 破坏双亲委派模型
- GC(垃圾回收机制)
-
- STW(Stop The World)
- GC的回收单位
- GC的实际工作过程
- 如何清理垃圾
-
- 标记清除
- 复制算法
- 标记整理
- 分代回收
- 结尾
内存区域划分
JVM 是一个应用程序
在启动时, 会向操作系统申请内存空间
根据不同的需求, 将空间分割成不同的部分, 每个部分的功能各不相同
(类似于我们的房子, 根据不同的需求, 将房子的空间进行分割, 一部分成为了卧室, 一部分成为了厨房…)
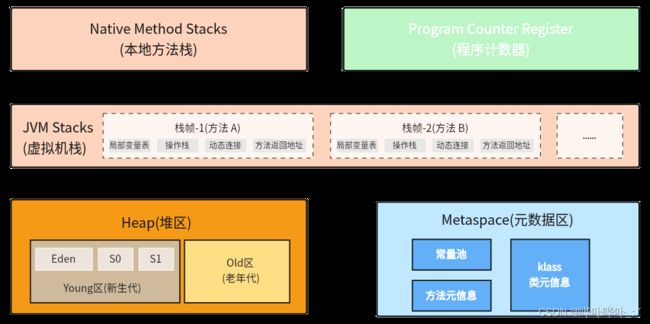
- JVM 将内存区域划分为5个部分
- Native Method Stacks(本地方法栈)
- Program Counter Register(程序计数器)
- JVM Stacks(虚拟机栈)
- Heap(堆区)
- Metaspace(元数据区, 也称为方法区)
注意
此处所指的栈,堆指代的是JVM中的内存空间
并非数据结构中的栈,堆
Program Counter Register(程序计数器)
程序计数器
记录当前线程执行到哪个指令
(程序计数器是很小的一块内存区域)
Native Method Stacks(本地方法栈)
Native 表示 JVM 内部的 C++ 代码
本地方法栈
调用 Native 方法(JVM 内部的方法)时准备的栈空间
JVM Stacks(虚拟机栈)
虚拟机栈
调用 Java 代码时准备的栈空间
栈空间内部包含很多的元素(每个元素表示一个方法)
每一个元素又称为是一个栈帧
- 栈帧包含
- 方法的入口
- 方法的参数
- 返回地址
- 局部变量
- …
区分虚拟机栈与本地方法栈
- 对于
本地方法栈, 存储的是Native方法(C++代码)之间的调用关系 - 对于
虚拟机栈, 存储的是方法(Java代码)之间的调用关系 - 方法的调用, 具有
后进先出的特点, 此处的栈也是后进先出
方法的调用, 后进先出
⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇
public static void main(String[] args) {
System.out.println(testAndVerify());
}
private static String testAndVerify() {
return "welcome to bibubibu's blog!";
}
栈是线程私有的
对于栈是线程私有的这句话, 并不是足够的准确(个人理解)
私有表示的意思是我的东西, 你不能碰
类似于这台笔记本是我私有的, 你不能碰我的笔记本
但对于一个线程的内容来说, 另一个线程可以通过变量捕获的方式获取
t1 线程通过变量捕获方式访问 main 线程的局部变量 locker
⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇
public class ThreadDemo {
public static void main(String[] args) throws InterruptedException {
Object locker = new Object();
Thread t1 = new Thread(() -> {
try {
System.out.println("wait开始");
synchronized(locker) {
locker.wait();
}
System.out.println("wait结束");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t1.start();
}
}
Heap(堆区)
堆区是 JVM 内存空间的最大区域
通常 new 出来的对象都是存储在堆
Metaspace(元数据区)
元数据区, 也称为方法区
元
即 Meta, 表示属性
元数据区
主要存储类对象, 常量池, 静态成员
这里所说的类对象不是 A a = new A();
而是类似于对象的图纸, 描述了该对象的属性
类对象
⬇⬇⬇⬇⬇

总结
| 名称 | 描述 |
|---|---|
| JVM(Java 虚拟机) | 每个进程有一份 |
| Program Counter Register(程序计数器) | 每个线程有一份 |
| Native Method Stacks(本地方法栈) | 每个线程有一份 |
| JVM Stacks(虚拟机栈) | 每个线程有一份 |
| Heap(堆区) | 每个进程有一份 |
| Metaspace(元数据区) | 每个进程有一份 |
- 局部变量默认存储在栈
- 普通成员变量默认存储在堆
- 静态成员变量默认存储在元数据区(方法区)
类加载
类加载
将 .class 文件, 从文件(硬盘)加载到内存(元数据区)
.java 通过 javac 编译生成 .class

- 类加载的步骤
- 加载(Loading)
- 连接(Linking)
- 验证(Verfication)
- 准备(Preparation)
- 解析(Resolution)
- 初始化(Initialization)
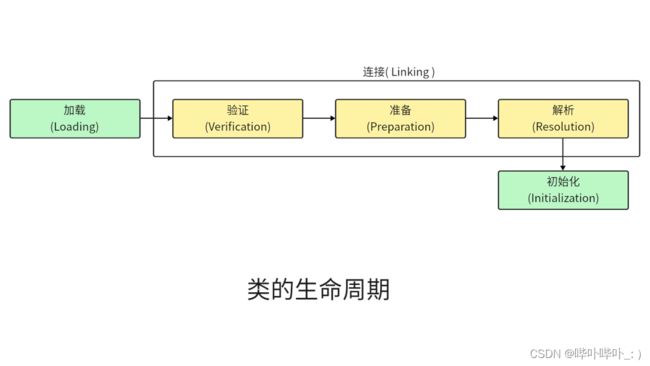
类加载的流程
加载
找到 .class 文件, 打开文件, 读取文件(将文件内容读取至内存中)
验证
检查 .class 文件的格式是否正确
- .class 是一个二进制文件, 其格式有着严格的说明
- 官方提供的 JVM 规范文档详细描述了 .class 的格式
准备
为类对象分配内存空间(此时内存初始化为全0)
静态成员变量的值也就被设为0
解析
初始化字符串常量, 将符号引用转为直接引用
符号引用转为直接引用
- 字符串常量包括
- 内存空间, 存储该字符串的实际内容
- 引用, 存储内存空间的起始地址
类加载之前
字符串常量位于 .class 文件中
此时的引用记录的并非是字符串常量的真正地址, 而是字符串常量在文件中的"偏移量"(符号引用)
类加载之后
字符串常量位于内存中(即字符串常量拥有了内存地址)
此时的引用记录的才是真正的内存地址(直接引用)
初始化
针对类对象的内容进行初始化
执行代码块, 静态代码块, 加载父类…
类加载的时机
并非 Java 程序运行, 所有的类就会被加载
而是真正用到该类, 才会被加载
(懒汉模式)
- 常见的类加载时机
- 构造类的实例
- 调用这个类的静态方法 / 静态成员变量
- 加载子类之前, 需先加载其父类
(加载过一次之后, 后续使用就不必重复加载)
双亲委派模型
加载
找到 .class 文件, 打开文件, 读取文件(将文件内容读取至内存中)
双亲委派模型
描述的是找到 .class 文件的基本过程
- JVM 默认提供了三个
类加载器- BootstrapClassLoader(负责加载标准库中的类)
- ExtensionClassLoader(负责加载 JVM 扩展库中的类)
- ApplicationClassLoader(负责加载用户提供的第三方库 / 用户项目代码中的类)
上述三个类加载器, 存在"父子关系"
此处所说的父子关系并不是父类子类
(可以简单理解为 Parent 属性)
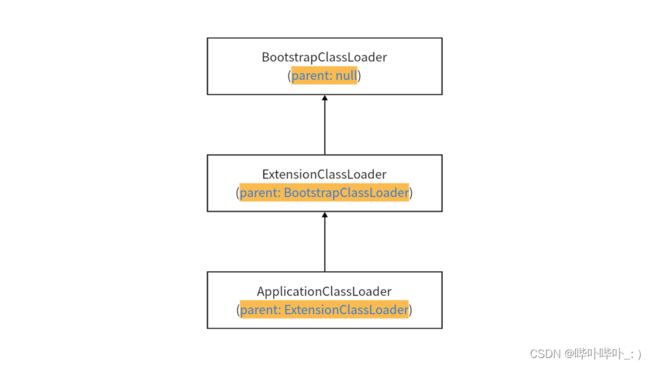
上述类加载器如何配合工作
- 从 ApplicationClassLoader 开始加载一个类
- ApplicationClassLoader 会将加载任务, 交给其父(ExtensionClassLoader), 让其父去执行
- ExtensionClassLoader 会将加载任务, 交给其父(BootstrapClassLoader), 让其父去执行
- BootstrapClassLoader 会将加载任务, 交给其父(null), 让其父去执行
但 BootstrapClassLoader 的父亲是 null, 于是自行加载(自己动手丰衣足食)
此时 BootstrapClassLoader 就会搜索标准库目录相关的类
如果找到需要加载的类, 就会去进行加载
如果未找到需要加载的类, 就由其子类加载器进行加载 - ExtensionClassLoader 加载 BootstrapClassLoader 未能加载的 JVM 扩展库中的类
此时 ExtensionClassLoader 就会搜索 JVM 扩展库目录相关的类
如果找到需要加载的类, 就会去进行加载
如果未找到需要加载的类, 就由其子类加载器进行加载 - ExtensionClassLoader 加载 BootstrapClassLoader 未能加载的用户提供的第三方库 / 用户项目代码中的类
此时 ExtensionClassLoader 就会搜索用户提供的第三方库 / 用户项目代码目录中相关的类
如果找到需要加载的类, 就会去进行加载
如果未找到需要加载的类, 就会抛出ClassNotFoundException(未找到指定类异常)
- 类
加载器自行加载的情况- 该
类加载器没有父 - 该
类加载器的父加载完毕后仍未找到所需加载的类
- 该
为什么双亲委派模型的执行顺序是这样的?
上述过程是一个递归的过程(保证了 BootstrapClassLoader 最先执行), 避免因用户创建一些奇怪的类从而引起的 Bug
假设用户在代码中创建了一个系统已存在的类
根据上述的加载流程, 此时 JVM 会先加载标准库中的类, 而不是用户自己代码中的类
这样避免了因为类相同从而可能引起 JVM 标准库中的类出现混乱

破坏双亲委派模型
自己写的类加载器可以遵守上述的执行过程, 也可以不遵守上述的执行过程
看实际的需求
GC(垃圾回收机制)
垃圾
不再使用的内存
垃圾回收
将不用的内存进行释放
如果内存一直占用, 不去释放, 就会导致剩余的空间越来越少, 从而导致后续申请内存失败
- 对于进程, 这种情况可能会随着进程的结束从而将内存恢复
- 对于服务器(7 * 24 运行), 这种情况就是致命的
由此, Java 中引入了 GC, 帮助我们自动进行释放"垃圾"
- GC 的优点: 省心, 能够自动将不用的内存释放
- GC 的缺点: 消耗额外的系统资源, 额外的性能开销(STW 问题)
STW(Stop The World)
假设内存中的垃圾很多, 此时触发一次 GC 操作
其开销可能非常大, 大到可能将系统资源耗光
另一方面, GC 回收垃圾时, 可能会涉及一些锁操作, 导致业务代码无法正常运行
这样的卡顿, 极端情况下可能是几十毫秒甚至上百毫秒
注意
Scanner sc = new Scanner(System.in);
sc.close();
类似于这种释放的是文件资源, 并非内存
GC的回收单位
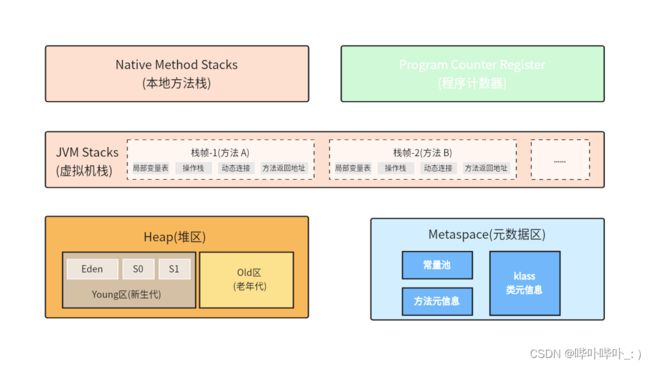
- JVM 中存在的内存区域
- 堆
- 栈
- 虚拟机栈
- 本地方法栈
- 程序计数器
- 元数据
GC 主要是针对堆进行内存释放的
这是因为堆上的对象存活时间相对较长
而栈上的对象会随着方法的结束而结束
- 将内存空间大致划分为3类
- 正在使用的内存
- 不用的内存(但未回收)
- 未分配的内存
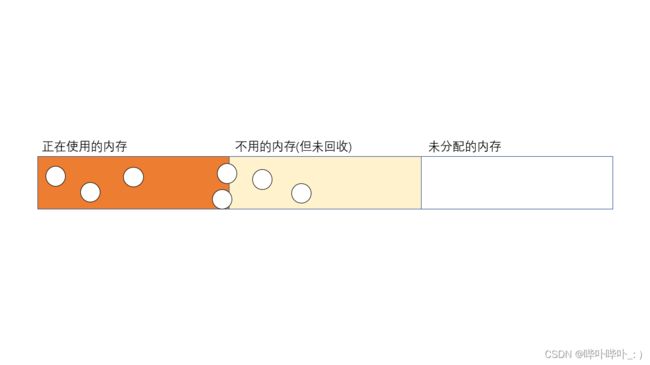
- GC 回收是以"对象"为基本单位, 并非字节
- GC 回收的是整个对象(整个对象不再使用时回收), 并非一部分使用, 一部分不使用
(一个对象可能有多个属性 ,其中一部分属性需要使用, 一部分属性用过之后不再进行使用, GC 进行回收是当整个对象不再使用时, 即该对象中所有属性不再使用)
GC的实际工作过程
- GC 的实际工作过程可以划分为2步
- 寻找垃圾(找到不再使用的内存)
- 回收垃圾(将不再使用的内存进行释放)
寻找垃圾
- 寻找垃圾有2种方法
- 引用计数(
python/php) - 可达性分析(
Java)
引用计数
为每个对象分配一个计数器
创建一个指向该对象的引用时, 该对象的计数器 + 1
销毁一个指向该对象的引用时, 该对象的计数器 - 1
举个栗子
Test t1 = new Test();// Test 对象引用计数 + 1
Test t2 = new Test();// Test 对象引用计数 + 1
Test t3 = new Test();// Test 对象引用计数 + 1
t1 = null;// Test 对象引用计数 - 1
- 引用计数的不足
- 内存空间浪费
- 循环引用
内存空间浪费
- 引用计数需要为每个对象分配一个计数器
- 当代码中的对象较少时, 空间浪费率较低
- 当代码中的对象较多时, 空间浪费率较高
- 当每个对象的体积(占用的内存空间)较小时, 此时分配的计数器所占空间会较为突出
(假设计数器所占内存空间为4字节, 当对象的体积为4字节时, 此时所消耗的额外空间相当于一个对象的体积)
- 当每个对象的体积(占用的内存空间)较小时, 此时分配的计数器所占空间会较为突出
循环引用
分析如下伪代码
public class Node {
Node next = null;
}
Node a = new Node();// 1号对象, 引用计数为1
Node b = new Node();// 2号对象, 引用计数为1
a.next = b;// 2号对象, 引用计数为2(a.next 指向 b)
b.next = a;// 1号对象, 引用计数为2(b.next 指向 a)
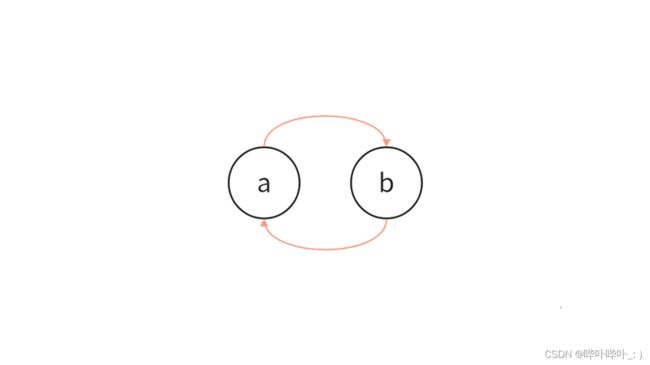
此时将 a 和 b 进行销毁
a = null;// 1号对象, 引用计数为1(2 - 1 = 1)
b = null;// 2号对象, 引用计数为1(2 - 1 = 1)
此时1号对象和2号对象的引用计数为1, 表示无法释放内存
(引用计数为0时, 释放内存)
但此刻1号对象与2号对象却无法被访问(循环引用)
可达性分析
Java 中的对象是通过引用进行指向并访问的
可达性分析, 就是将这些对象被组织的结构视为链式结构
从起始位置出发, 遍历链
能够被访问到的对象标记为"可达"
反之即为"不可达"
(将不可达的作为"垃圾"进行回收)
举个栗子
class TreeNode {
int val;
TreeNode left;
TreeNode right;
}

目前所有的节点都是可达的

此时3 → 6之间的连接断开
6不可达
8不可达
于是6, 8被当作垃圾进行回收
- 可达性分析
- 需要进行类似于遍历操作从而判断是否可达
- 相比于引用计数, 其执行效率要慢一些
- 可达性分析的遍历操作, 并不需要一直执行, 是一种周期性的策略(隔一段时间分析一遍)
- 可达性分析遍历的起点
- 栈上的局部变量
- 常量池中的对象
- 静态成员变量
如何清理垃圾
标记清除
将垃圾标记并回收

标记清除的不足
内存碎片问题
被释放的空间是零散的, 不是连续的
申请内存的空间要求是连续的空间
导致总的空闲空间可能很大(非连续), 但每个具体的空间(连续)却较小
从而申请内存失败
复制算法
将内存空间划分为两半
将不是垃圾的对象复制到另一半, 然后将整个空间删除

复制算法解决了内存碎片问题
但也有其不足
复制算法的不足
- 空间利用率较低
- 垃圾少, 有效对象多时, 复制成本较大
标记整理
将垃圾进行标记
将不是垃圾的对象覆盖垃圾的空间
删除剩余空间

解释
1为垃圾
后面的元素依次进行覆盖
由
1, 2, 3, 4, 5, 6
变为
2, 3, 4, 5, 6

解释
3为垃圾
后面的元素依次进行覆盖
由
2, 3, 4, 5, 6
变为
2, 4, 5, 6

解释
5为垃圾
后面的元素依次进行覆盖
由
2, 4, 5, 6
变为
2, 4, 6
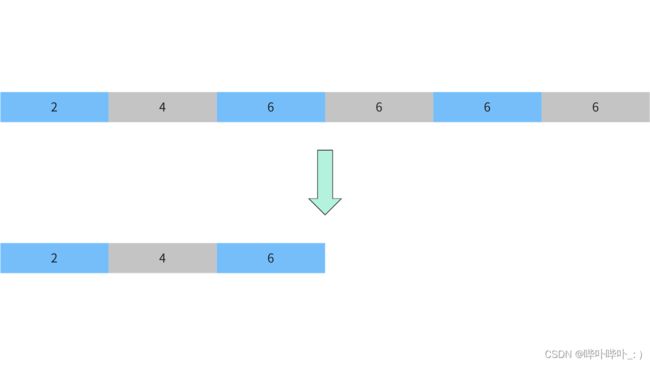
解释
删除剩余空间
标记整理解决了复制算法的空间利用率较低的问题
但也有其不足
标记整理的不足
效率问题
(需要将对象进行搬运, 如果要搬运的对象较多, 此时效率就会较低)
分代回收
可以看出, 上述对于垃圾清理的操作, 都有其相对的适用场景与不足
那么, 能不能让合适的垃圾清理方法去其适合的场景呢
于是引出了分代回收
分代回收
将垃圾回收划分成不同的场景
不同的场景应用不同的清理方法
(各展所长)
分代是如何划分的
基于经验规律
是的, 基于经验规律
这个规律是这样的
如果一个东西存在的时间比较长, 那么大概率还会继续长时间的存在下去
这个规律, 对于 Java 的对象也是有效的(由一系列的实验和论证过程得出)
- Java对象的生命周期大致可以划分为两种
- 生命周期极短
- 生命周期极长
于是, 给对象引入了一个概念—年龄
(此处的年龄指代的是熬过GC的轮次, 可以类比于人类的年龄)
于是将堆进行了区域的划分

更为具体的划分
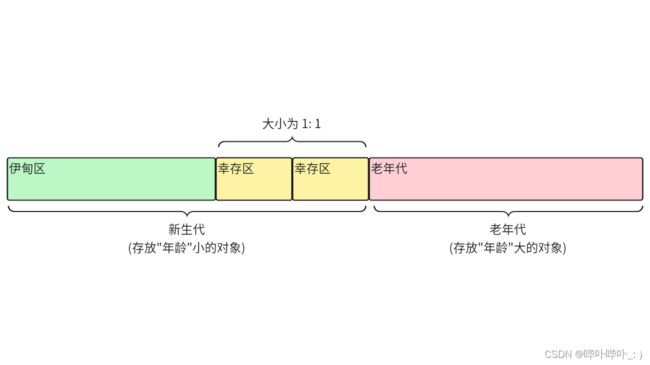
- 新 new 出来的对象, "年龄"为0, 存放在伊甸区
- 使用复制算法
- 熬过一轮 GC 的对象, 存放在幸存区(伊甸区 → 幸存区)
- 使用复制算法
- 在幸存区经过多轮拷贝的对象, 存放在老年代(幸存区 → 老年代)
- 使用标记整理
结尾
创作不易,如果对您有帮助,希望您能点个免费的赞
大家有什么不太理解的,可以私信或者评论区留言,一起加油