linux mysql安装 读写分离_Linux运维:MySQL读写分离解决方案
原标题:Linux运维:MySQL读写分离解决方案
在MMM集群架构中,通过提供虚拟的读、写IP地址,将 数据库 的读写功能分离出来,但是这仅仅设定了读、写的VIP地址,并没有真正实现业务系统中所说的读、写分离功能,因为应用程序不可能在需要读的时候就去找可读的VIP,在写的时候就去找可写的VIP,要解决这个问题,可由两种方法来实现。
第一种实现读、写分离的方式是通过修改程序,将读、写操作提取出来,并分别在程序的连接池中设定可读、可写的VIP地址,这种方法要修改业务系统的程序,实现起来相对比较困难,如果是新开发的程序,可以在开发时就预留这样的接口,而如果程序已经在运行,修改的难度是相当大的,采用这种方法基本行不通。
第二种实现读、写分离的方法是通过一个 数据库 透明代理,也就是在业务系统和 数据库 之间提供一个代理接口,由这个接口来完成业务系统读、写请求的分发,将读操作分发到后端只读的 数据库上,而将写请求分发到后端可写的 数据库服务器 上。常见的读、写分离软件有Amoeba和 MySQL -Proxy。
MySQL -Proxy是 MySQL 官方推出的一个处在业务系统和 MySQL之间的程序,这个代理可以用来分析、监控和变换通信数据,但是 MySQL 官方建议不要将 MySQL -Proxy用于生产环境。事实上, MySQL -Proxy确实很不稳定,它的读、写分离功能都是通过一个lua脚本来实现的,而这个脚本bug很多,所以不建议通过 MySQL -Proxy来实现读、写分离功能,不过可以作为线下测试使用。
Amoeba是一个开源项目,致力于的分布式前端代理层,它主要在应用层访问的时候充当SQL功能,具有、高可用性、SQL过滤、读写分离等功能,通过Amoeba可以实现数据源的高可用、、数据切片等功能。本文介绍Amoeba作为读、写分离代理接口的实现过程。
1、通过Amoeba实现MySQL读写分离
(1)MMM整合Amoeba应用架构
在实际的应用环境中,Amoeba可与简单的主从复制架构进行整合,实现读与写的分离操作。但是这样存在安全性问题,例如的Master节点出现故障或者任何一个Slave节点故障,那么Amoeba并不能自动屏蔽这些故障的节点,可能会导致前端应用程序无法读取的情况。为了解决这个问题,Amoeba经常与MMM集群架构一起使用,这样如果任意节点故障,MMM集群就能自动屏蔽故障节点,从而保证Amoeba一直能够连接到正常的节点。这里要介绍的Amoeba应用环境就是在MMM集群的基础上构建的,整个架构如图1所示。

图1 MMM整合Amoeba应用架构
此架构其实就是在MMM集群架构的基础上增加了Amoeba Server,这样前端所有应用程序的请求都将提交到Amoeba Server上,然后Amoeba Server根据自身的读、写配置参数将读请求分配到可读的每个节点,而将写请求分配到可写的节点上。这个架构由于在底层使用了MMM集群,因此,Amoeba Server不用担心会将请求分配到一个故障的节点,因为MMM集群会自动转移故障节点到健康节点上。
(2)Amoeba的安装
这里下载的是amoeba-mysql-3.0.5-RC-distribution.zip。Amoeba的安装非常简单,直接解压即可使用,这里将Amoeba解压到/usr/local/amoeba目录下,这样就完成安装了。
Amoeba框架是基于Java SE1.5开发的,因此,还需要安装环境,建议使用Java SE1.5以上的JDK版本,这里使用的JDK版本为jdk1.6.0_25。将JDK安装到/usr/local/目录下,然后设置环境变量,信息如下:
export JAVA_HOME= /usrk/local/jdk1.6.0_25
export CLASSPATH=.:$JAVA_HOME/jre/lib//rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
将这些内容添加到系统的/etc/profile文件中即可完成 Java 环境的设置。
(3)配置Amoeba
Amoeba的配置文件在本环境下位于/usr/local/amoeba/conf目录。配置文件比较多,但是仅仅使用读、写分离功能,只需配置二个文件即可,分别是dbServers.xml和amoeba.xml,如果需要配置IP 访问控制 ,还需要修改access_list.conf文件。下面首先介绍dbServers.xml文件的配置,内容如下:
${defaultManager}
64
128
3306 #设置Amoeba要连接的mysql数据库的端口,默认是3306
testzhu #缺省数据库,当连接amoeba时,操作表必须显式的指定数据库名,即采用dbname.tablename的方式,不支持 use dbname指定缺省库,因为操作会调度到各个后端dbserver
test1 #设置amoeba连接后端数据库服务器的账号和密码,因此需要在所有后端数据库上创建该用户,并授权amoeba服务器可连接
#设置一个后端可写的dbServer,这里定义为writedb,这个名字可以任意命名,后面还会用到
192.168.1.129 #设置后端可写dbserver
#设置后端可读dbserver
192.168.1.118 #后端可读dbserver的IP
……
这样Amoeba就配置完成了。
(4)设置Amoeba登录数据库权限
这里假定Amoeba 服务器 的IP地址为192.168.88.35,在MMM集群的所有 MySQL 节点上执行如下操作,为Amoeba访问MMM集群中所有 MySQL节点授权:
mysql>GRANT ALL ON repldb.* TO 'ixdba'@'192.168.88.35' IDENTIFIED BY 'xxxxxx';
mysql>flush privileges;
(5)启动Amoeba
在Amoeba 服务器 上执行如下命令,启动Amoeba:
[root@amoebaserver bin]# /usr/local/amoeba/bin/launcher
2019-10-24 18:46:37 [INFO] Project Name=Amoeba-MySQL, PID=22474, starting...
log4j:WARN log4j config load completed from file:/usr/local/amoeba/conf/log4j.xml
2019-10-24 18:50:21,668 INFO context.MysqlRuntimeContext - Amoeba for Mysq current versoin=5.1.45-mysql-amoeba-proxy-3.0.4-BETA
log4j:WARN ip access config load completed from file:/usr/local/amoeba/conf/access_list.conf
2019-10-24 18:50:22,852 INFO net.ServerableConnectionManager - Server listening on 0.0.0.0/0.0.0.0:8066.
[root@cloud0 bin]# netstat -unlpt | grep java
tcp 0 0 :::8066 :::* LISTEN 22474/java
由此可知Amoeba启动正常。
(6)测试Amoeba实现读、写分离和负载均衡
要测试Amoeba实现读、写分离和功能,需要在MMM集群的所有节点开启的查询日志。查询日志可以记录中建立的客户端连接和执行的语句。开启方法很简单,在配置文件/etc/my.cnf中添加如下内容:
log=/var/log/mysql_query_log
当然,mysql_query_log文件要事先存在,并且对 MySQL 用户可写。
为了测试方便,这里在每个 MySQL 节点的test库中创建一张表,表的名字为mmm_test,例如在Master1节点,创建表的过程如下:
mysql>use test;
mysql>create table mmm_test(id int,email varchar(60));
mysql>insert into mmm_test(id,email) values(100,'this is 192.168.88.20');
上面的操作是在mmm_test表的email字段中插入一条记录“this is 192.168.88.20”,而字符串“this is 192.168.88.20”就是个IP标识,这样做的目的是区分多个 MySQL 节点不同IP地址的情况。接着在Master2节点同样执行上面的SQL操作,所不同的是mmm_test表email字段的内容修改为“this is 192.168.88.21”。依此类推,分别在Slave1和Slave2节点执行相同的操作。
接着,在MySQL 客户端通过Amoeba配置文件中指定的用户名、密码、端口以及Amoeba服务器的IP地址连接 MySQL,操作过程如图2所示。
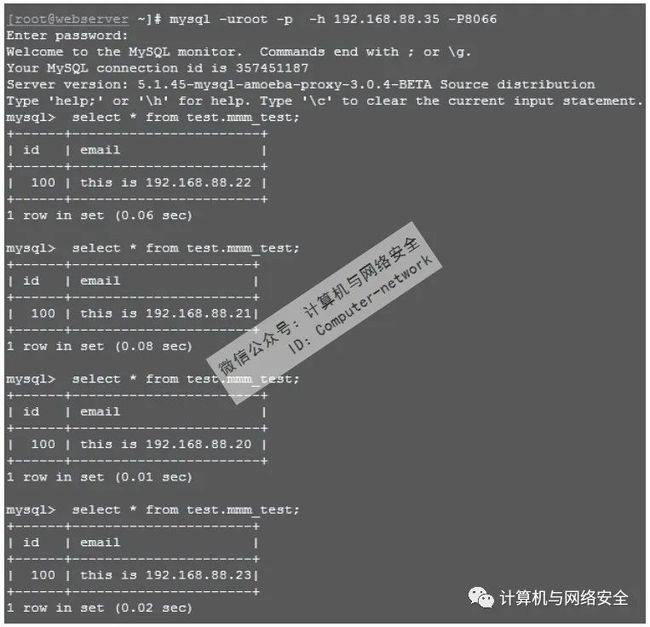
图2 测试Amoeba实现读操作的负载均衡功能
从图2可以看出,客户端连接到的Server version为5.1.45-mysql-amoeba-proxy-3.0.4-BETA,可见客户端连接的是Amoeba实例而不是实例,而从下面的查询test库中mmm_test表的内容来看,Amoeba依次将4次select请求均衡地分配到MMM集群中4个可读节点上,由此可知,Amoeba实现了读操作的。
下面继续进行SQL测试,创建两个表mmm_test1和mmm_test2,操作过程如下:
mysql>create table mmm_test1(id int,email varchar(60));
Query OK,0 rows affected(0.04 sec)
mysql>create table mmm_test2(id int,email varchar(60));
Query OK,0 rows affected(0.04 sec)
mysql>insert into mmm_test1(id,email) values(101,'mmm_test1@126.com');
Query OK,1 rows affected(0.02 sec)
mysql>drop table mmm_test2;
Query OK,0 rows affected(0.10 sec)
为了确定创建的两个表是否已经正常同步到MMM集群的其他节点,可分别登录每个节点进行查询,接着还要确定的写操作是否分配到可写的节点Master1,可通过查看每个节点的查询日志。Master1节点的查询日志信息如图3所示。

图3 Master1节点MySQL查询日志
Master2节点的 MySQL 查询日志信息如图4所示。

图4 Master2节点MySQL查询日志
其他节点的信息基本类似,这里不一一列出。从的查询日志中可以进一步验证Amoeba实现了读,而写操作在Master1节点执行了。虽然Master2节点也有相关写操作的日志,但这是的复制线程执行的写操作,因为除了Master1,其他节点都是read_only状态,是无法执行写操作的。
2、通过Keepalived构建高可用的Amoeba服务
在上面介绍的MMM整合Amoeba应用方案中,虽然通过Amoeba实现了 的读、写分离,但是这个架构并不完美,因为还存在Amoeba单点故障,也就是说当Amoeba出现故障后,业务系统将无法访问 服务。要解决这个问题其实非常简单,通过Keepalived给Amoeba做高可用即可,通过Keepalived实现Amoeba高可用并实现 集群读、写分离的架构如图5所示。
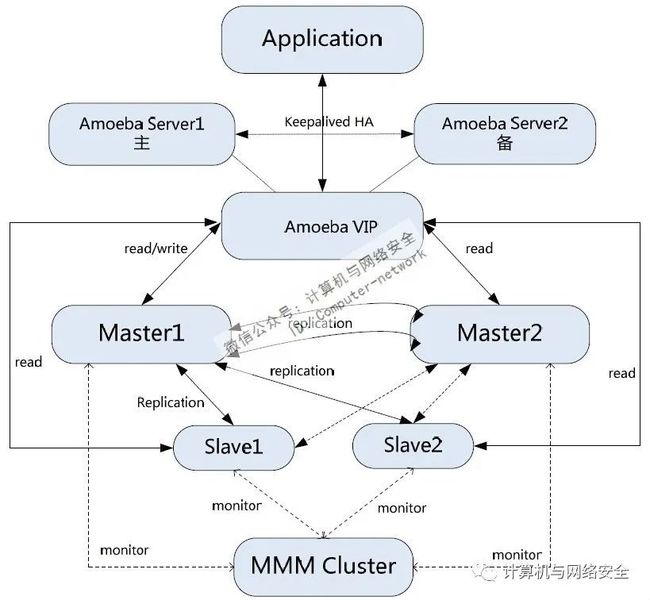
图5 通过Keepalived实现Amoeba高可用并实现MySQL集群读、写分离架构返回搜狐,查看更多
责任编辑: