【论文简介】DragGAN:Interactive Point-based Manipulation on the Generative Image Manifold (6月即将开源)
在生成图像流形上的基于交互式点控制
论文以StyleGAN2架构为基础,实现了点点鼠标、拽一拽关键点就能P图的效果(虽然效果惊人,目前只能在特定数据集进行编辑)
官方项目地址:https://vcai.mpi-inf.mpg.de/projects/DragGAN/
科研媒体报道:让GAN再次伟大!拽一拽关键点就能让狮子张嘴&大象转身,汤晓鸥弟子的DragGAN爆火,网友:R.I.P. Photoshop
DragGAN允许用户“拖动”任何gan生成的图像的内容。用户只需点击图像上的几个手柄点(红色)和目标点(蓝色),我们的方法将移动手柄点,精确地到达相应的目标点。
用户可以选择绘制一个灵活的区域(更亮的区域)的掩模,以保持图像的其余部分不变(fixed)。这种基于点的灵活操作可以控制许多空间属性,如姿态、形状、表达式和布局。

摘要
满足用户需求的视觉内容合成通常需要对生成对象的姿势(pose)、形状(shape)、表情(expression)和布局(layout)具备灵活且精确的可控性。现有方法通过手动标注的训练数据或先前的3D模型来实现对生成对抗网络(GANs)的可控性,但这往往缺乏灵活性、精确性和普适性。在本研究中,我们探索了一种强大但较少被探索的控制GANs的方式,即以用户交互的方式“拖动”图像中的任意点,精确地达到目标点,如图1所示。为了实现这一目标,我们提出了DragGAN,它包括两个主要组成部分:1)基于特征(feature)的运动监督(motion supervision),推动手柄点向目标位置移动;2)一种利用判别式(discriminative)生成器特征的新的点跟踪方法,用于定位手柄点的位置。通过DragGAN,任何人都可以通过精确控制像素的位置来改变图像,从而操纵动物、汽车、人类、风景等多种类别的姿势、形状、表情和布局。由于这些操作是在GAN学习到的生成图像流形(generative image manifold)上进行的,它们往往可以产生逼真的输出,即使在挑战性场景下,如产生遮挡内容的幻象和保持对象刚性的形状变形。定性和定量的比较结果显示DragGAN在图像操作和点跟踪任务上相比之前的方法具有优势。我们还展示了通过GAN反演对真实图像进行操作的示例。
关键词和短语:GANs、交互式图像操作(interactive image manipulation)、点跟踪(point tracking)。
3 方法
本工作旨在开发一种GANs交互式图像处理方法,用户只需要点击图像来定义一些对(手柄点,目标点),并驱动手柄点到达相应的目标点。我们的研究基于StyleGAN2体系结构。这里我们简要介绍这个体系结构的基础知识。
图像流形的建模
由于生成器学习从低维潜在空间到高维图像空间的映射,它可以被看作是对图像流形的建模[Zhu et al. 2016]。
- 1609.Generative visual manipulation on the natural image manifold
3.1 基于交互式点的操作 ( Interactive Point-based Manipulation)
图像处理管道的概述如图2所示。对于任何由具有潜在代码的GAN生成的图像I∈R 3××,我们允许用户输入一些句柄点{=(,,,)|= 1,2,…,}及其对应的目标点{=(,,,)|= 1,2,…,}(,即对应的目标点为)。目标是移动图像中的物体,使手柄点的语义位置(如图2中的鼻子和下巴)达到相应的目标点。我们还允许用户选择性地绘制一个二进制掩模M,表示图像的哪个区域是可移动的。
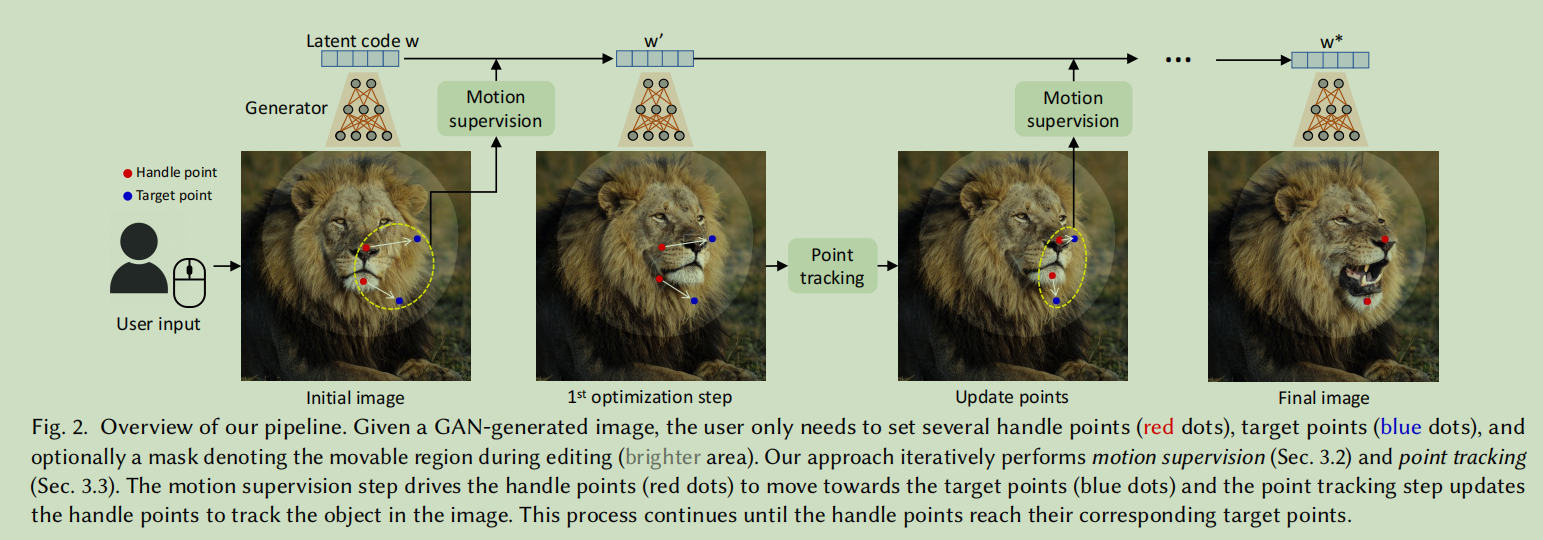
根据用户的输入,我们以优化的方式进行图像处理。如图2所示,每个优化步骤包括两个子步骤,包括1)运动监督和2)点追踪。在运动监督中( motion supervision),使用一种损失函数来迫使(enforces)控制点向目标点移动,以优化潜在代码。经过一次优化步骤,我们得到一个潜在代码新的'和一个新的图像I’。这个更新会导致图像中的物体轻微移动( a slight movement)。
请注意,每次运动监督步骤只将每个手柄点向目标移动一小段的距离,但每步的确切长度不清楚(the exact length of the step is unclear),因为它受到复杂的优化迭代动态作用(is subject to complex optimization dynamics ),不同的对象和部件而不同。因此,我们更新控制点的位置{}来跟踪物体上的相应点。
跟踪过程(This tracking process)是必要的,因为如果控制点(例如,狮子的鼻子)没有准确地被跟踪,那么在下一个运动监督步骤中,将会监督错误的点(例如,狮子的脸),从而导致不期望的结果。在跟踪之后,我们根据新的控制点和潜在代码重复上述优化步骤。这个优化过程会一直持续,直到控制点{}到达目标点{}的位置,根据我们的实验,这通常需要30-200次迭代。用户也可以在任何中间步骤停止优化。
在编辑之后,用户可以输入新的控制点和目标点,并继续编辑,直到对结果满意为止。
图2 实现流程
我们的流程概述。给定一个由GAN生成的图像,用户只需设置几个操作点(handle points)(红色点)、目标点(蓝色点)和可选的标记移动区域的蒙版(mask)(较亮的区域)。我们的方法迭代地执行运动监督(motion supervision)(第3.2节)和点跟踪(第3.3节)。运动监督步骤驱动手柄点(红色点)向目标点(蓝色点)移动,而点跟踪步骤则更新手柄点以跟踪图像中的对象。这个过程持续进行,直到手柄点达到相应的目标点位置。
3.2 运动监督(motion supervision)
如何监督(supervise)一个gan生成的图像的点运动(point motion)之前还没有太多的探索。
在这项工作中,我们提出了一个不依赖于任何附加的神经网络的运动监督损失。
关键思想是,生成器中间特征(the intermediate features of the generator)是非常有判别力的(discriminative),一个简单的损失就足以监督运动。
具体来说,我们考虑了StyleGAN2的第6个模块(6th blocsk)之后的特征图F,由于在分辨率和鉴别性之间有很好的权衡(a good trade-of)
通过双线性插值(bilinear interpolation),将F调整大小,使其与最终图像具有相同的分辨率,
图3 运动监督的方法
我们通过在生成器的特征图上使用平移的块损失(a shifted patch loss)实现运动监督。我们在同一特征空间上通过最近邻搜索(the nearest neighbor search )来执行点跟踪。
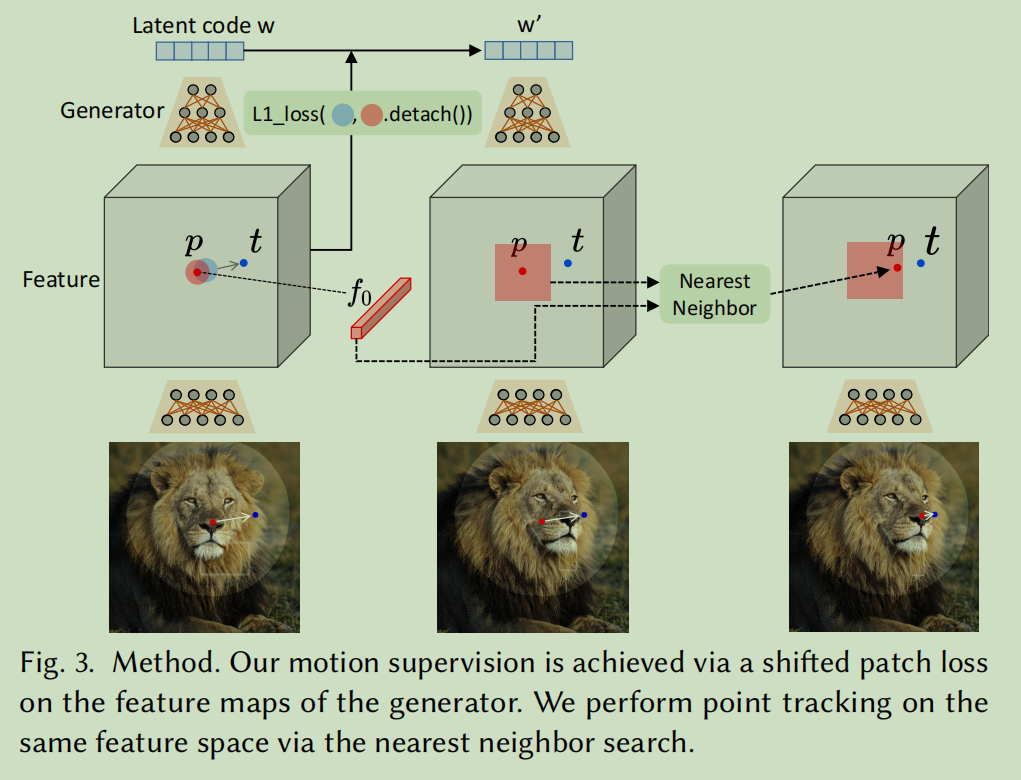
图3涉及的公式
要将一个控制点移动到目标点,我们的想法是通过监督围绕的一个小补丁(patch)(红色圆圈)向着迈出一个小步骤(蓝色圆圈)。我们使用Ω1(, 1)来表示距离小于1的像素点,然后我们的运动监督损失为:
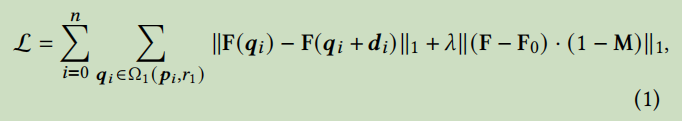
F()表示像素处的特征值,
是从指向的归一化向量(如果 = ,则 = 0):
F0是对应于初始图像的特征图。
M是二值掩码
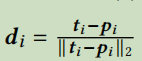
需要注意的是,第一项是对所有控制点{}求和。由于 + 的值不是整数(integers),我们通过双线性插值获得F( + )。
重要的是,在使用该损失进行反向传播时,梯度不会通过 F() 进行反向传播。这将促使移动到 + ,而不是相反。
如果给定二值掩码M,则通过重建损失保持未掩码区域固定 (keep the unmasked region fixed with a reconstruction loss) ,这公式(1)的第二项显示(shown as the second term)即
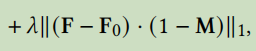
。在每个运动监督步骤中,此损失用于优化一个步骤的潜在编码。可以在W空间或W+空间中进行优化,这取决于用户是否想要一个更受约束的图像流形(image manifold)。。
由于W+空间更容易实现分布外操作( out-of distribution manipulations)(例如,图16中的cat),
我们在本工作中使用W+来获得更好的可编辑性。在实践中,我们观察到图像的空间属性主要受前6层的的影响,而其余的空间属性只影响外观。因此,受风格混合技术的启发,我们只更新的前6层,同时固定了其他层(fixing other)以保持外观。这种选择性的优化导致了所期望的图像内容的轻微移动。
图16 W+ 与 W空间优化的区别

3.3 点跟踪
在上述的运动监督步骤中,我们得到了一个新的潜在代码’,新的特征图F’(new feature maps),和一个新的图像I’。由于运动监督步骤并没有直接提供控制点的精确新位置,我们的目标是更新每个控制点,使其跟踪物体上对应的点。
通常,点跟踪是通过`光流估计模型(via optical flow estimation)或粒子视频方法来实现的[Harley et al. 2022]。然而,这些额外的模型往往会显著降低效率(harm efficiency),并且在存在GAN中的伪影等( alias artifacts)问题时可能会受到累积误差( accumulation error)的影响。因此,我们提出了一种适用于GAN的新的点跟踪方法。
我们的观点是,GAN的判别特征((discriminative features of GANs)能够很好地捕捉到密集的对应关系( dense correspondence),因此可以通过在特征图中的区域进行最近邻搜索来有效地进行跟踪(via nearest
neighbor search in a feature patch.)。具体来说,我们将初始控制点的特征表示为 = F0()。我们将周围的区域定义为Ω2(, 2) = {(, ) | | − ,| < 2, | − ,| < 2}。然后,通过在Ω2(, 2)中搜索的最近邻(nearest)来得到跟踪到的点。
3.4 实现细节
我们的方法是基于PyTorch实现的。我们使用Adam优化器 [Kingma and Ba 2014] 对潜在代码进行优化。对于FFHQ [Karras et al. 2019]、AFHQCat [Choi et al. 2020] 和 LSUN Car [Yu et al. 2015] 数据集,我们将优化步长设置为2e-3,对于其他数据集,设置为1e-3。超参数设置为 = 20,1 = 3,2 = 12。在我们的实现中,当所有控制点与其对应的目标点之间的距离不超过像素时,我们停止优化过程,其中的取值为1(最多5个控制点)或2(其他情况)。我们还开发了一个图形用户界面(GUI)来支持交互式图像操作。由于我们的方法具有高效的计算能力,用户只需等待几秒钟即可完成每次编辑,并且可以持续进行编辑直到满意为止。我们强烈建议读者参考附带的视频以获取交互式会话的实时录制。
5 结论
使用了2种新的方法(noval ingredients)
一种对隐码的(latent codes)的优化方法(optimization),可将多个操作点逐步移动到其目标位置,以及一种点跟踪过程(a point tracking procedure),以忠实地跟踪操作点的轨迹(trace the trajectory)
这两个组件都利用GAN的中间特征层(intermediate feature maps)的鉴别质量(discriminative quality)来产生像素精确的图像变形和交互性能。
我们已经证明了我们的方法在基于GAN的操作方面(GAN-based manipulation)的表现更好,并为使用生成先验进行强大的图像编辑开辟了新的方向。至于未来的工作,我们计划将基于点的编辑,未来扩展到三维生成模型。
附录
回顾stylegan的结构
多维潜在编码 ∈ N(0, ) 通过一个映射网络被映射到中间潜在编码 ∈ R⁵¹²。的空间通常被称为W。然后,被发送到生成器以生成输出图像 I = ()。在这个过程中,被多次复制并发送到生成器的不同层,以控制不同层次的属性。或者,可以为不同的层使用不同的,此时输入将为 ∈ R×512 = W+,其中 是层数。这种约束较少的 W+ 空间被证明具有更高的表现力[Abdal et al. 2019]。
stylegan1的结构:1812.A Style-Based Generator Architecture for Generative Adversarial Networks
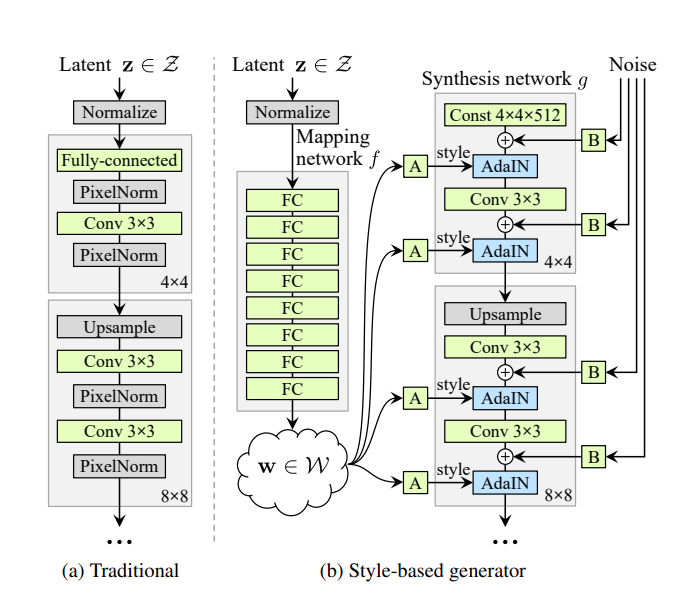
(stylegan1结构解析1:https://www.seeprettyface.com/research_notes.html#step3 )
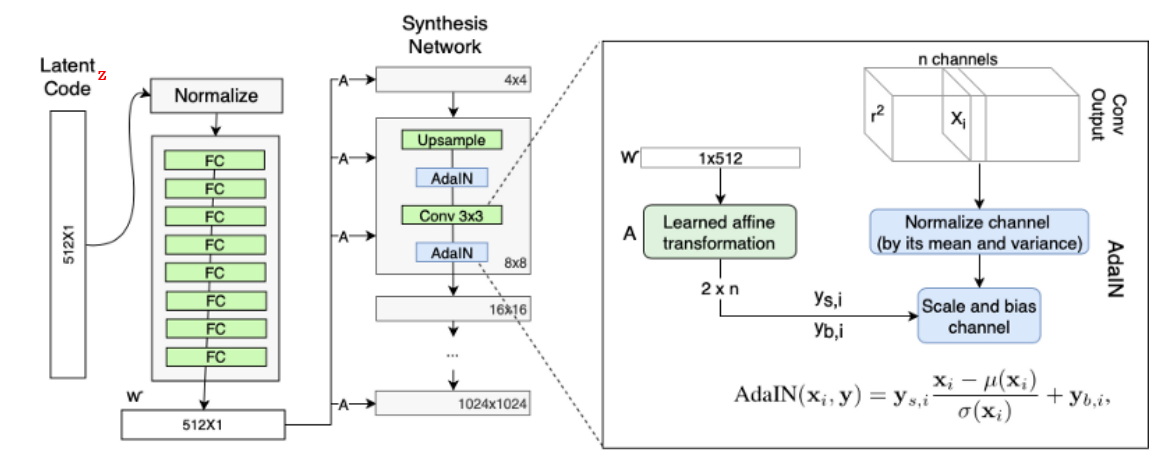
stylegan2的结构(取消AdIN模块): 1912.Analyzing and Improving the Image Quality of StyleGAN
