【ICIP2013】MULTI-SOURCE IMAGE AUTO-ANNOTATION
题目:多来源图像自动标注
文中利用了不同来源的图像组内和组间的关系来增强自动标注的效果。
一方面认为,相似的图像预测的也应该是相似的,利用kNN图的关系进行组内的正则化,以此增强底层特征的联系。
另一方面认为,不同来源的共享的标签的预测函数的参数应该是相似的,利用组间关系改善预测的参数。
最终利用多任务学习模型得到目标函数。
Problem Statement
定义 为N个不同来源的标注图像,其中x是图像的特征向量,y是图像的标注向量,i是来源的编号,j是同一组内图像的编号。
为N个不同来源的标注图像,其中x是图像的特征向量,y是图像的标注向量,i是来源的编号,j是同一组内图像的编号。
则利用最小二乘回归(least squares regression, LSR)每一个来源内的目标为

其中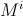 是参数矩阵,利用F范数进行结果的度量。
是参数矩阵,利用F范数进行结果的度量。
Inter-source structure regularizers
视觉相似的图像在语义上通常有联系,所以它们的标注也和它们的局部结构相关。作者在所有来源图像相似性的kNN稀疏图(kNN sparse graph)上,定义了 作为图像s和t的相似性度量,如果在稀疏图上没有边则相似度为0。
作为图像s和t的相似性度量,如果在稀疏图上没有边则相似度为0。
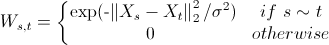
 为同一来源内的相似性,通过将中的部分值设为0获得,则正则化的公式为:
为同一来源内的相似性,通过将中的部分值设为0获得,则正则化的公式为:
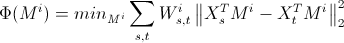
对于相似性高的图像,W的值更大,右侧两者预测的差距就应该越小。
通过引入拉普拉斯矩阵,上式可以转变为:
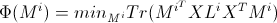
其中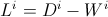 ,
,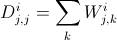
Inter-source parameter constraints
文中认为,对于不同来源的共享的标注,预测函数的模型参数应该是相似的。
定义矩阵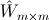 为标签在所有来源中的一致性,m是所有来源标签数量的总和。
为标签在所有来源中的一致性,m是所有来源标签数量的总和。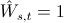 表示标签s和t来源不同但实质相同,否则等于0。
表示标签s和t来源不同但实质相同,否则等于0。
则参数约束为:
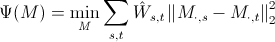
当时,约束了不同来源的参数的相似性。
同样引入拉普拉斯矩阵,

Multi-task learning model
最终:

其中C是和来源相关的用来正规化的参数,表示不同来源的信任程度,在实验中与 标签矩阵大小 和 每个来源的结构约束的数量 的反比,C的累加和为1。
对于C0来说,标签矩阵越大,分错的可能性就越大,所以应该使用反比。
对于C1来说,相似性的图像越多,对于分类包含的信息就越少,同样应该使用反比。
经证明可知上式是凸性的,所以可以通过L-BFGS的Quasi Newton方法求得全局最优解。
Experiment
与自己的不同情况和SVM相比较。
评价的标准为Mean AUC(area under ROC curve)。