数据可视化----操作CSV格式数据并进行简单的可视化
from numpy import *
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['figure.dpi'] = 150 #设置分辨率
series = pd.read_csv('train.csv', header=0, index_col=0)
# print(series.shape) # (2172, 1) 共计2172个观测
alt=array(series)
print(alt)
x0=[]
for a in alt:
x0.append(a[0])
# print(x0)
#根据数据绘制图形
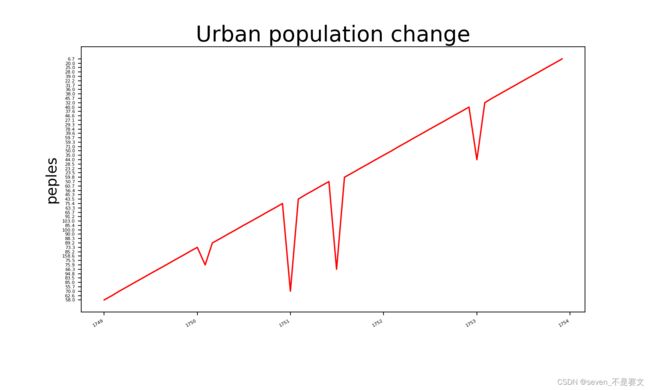
fig = plt.figure(dpi=128,figsize=(10,6)) #设置绘图窗口的尺寸
plt.plot(x0,c='red')
#设置图形的格式
plt.title("Urban population change", fontsize=24) #从1749年到18xx年的人口变化
plt.xlabel('',fontsize=16) #这里的x就是从1749年到18xx年 。太多了,所以要截取数据集
plt.ylabel("人数",fontsize=16) #人数的值
plt.tick_params(axis='both',which='major',labelsize=16)
plt.show()
参考别人:
csv数据集呈现:
AKDT,Max TemperatureF,Mean TemperatureF,Min TemperatureF,Max Dew PointF,MeanDew PointF,Min DewpointF,Max Humidity, Mean Humidity, Min Humidity, Max Sea Level PressureIn,`在这里插入代码片` Mean Sea Level PressureIn, Min Sea Level PressureIn, Max VisibilityMiles, Mean VisibilityMiles, Min VisibilityMiles, Max Wind SpeedMPH, Mean Wind SpeedMPH, Max Gust SpeedMPH,PrecipitationIn, CloudCover, Events, WindDirDegrees
2014-7-1,64,56,50,53,51,48,96,83,58,30.19,30.00,29.79,10,10,10,7,4,,0.00,7,,337
2014-7-2,71,62,55,55,52,46,96,80,51,29.81,29.75,29.66,10,9,2,13,5,,0.14,7,Rain,327
2014-7-3,64,58,53,55,53,51,97,85,72,29.88,29.86,29.81,10,10,8,15,4,,0.01,6,,258
2014-7-4,59,56,52,52,51,50,96,88,75,29.91,29.89,29.87,10,9,2,9,2,,0.07,7,Rain,255
2014-7-5,69,59,50,52,50,46,96,72,49,29.88,29.82,29.79,10,10,10,13,5,,0.00,6,,110
2014-7-6,62,58,55,51,50,46,80,71,58,30.13,30.07,29.89,10,10,10,20,10,29,0.00,6,Rain,213
2014-7-7,61,57,55,56,53,51,96,87,75,30.10,30.07,30.05,10,9,4,16,4,25,0.14,8,Rain,211
2014-7-8,55,54,53,54,53,51,100,94,86,30.10,30.06,30.04,10,6,2,12,5,23,0.84,8,Rain,159
2014-7-9,57,55,53,56,54,52,100,96,83,30.24,30.18,30.11,10,7,2,9,5,,0.13,8,Rain,201
2014-7-10,61,56,53,53,52,51,100,90,75,30.23,30.17,30.03,10,8,2,8,3,,0.03,8,Rain,215
2014-7-11,57,56,54,56,54,51,100,94,84,30.02,30.00,29.98,10,5,2,12,5,,1.28,8,Rain,250
2014-7-12,59,56,55,58,56,55,100,97,93,30.18,30.06,29.99,10,6,2,15,7,26,0.32,8,Rain,275
2014-7-13,57,56,55,58,56,55,100,98,94,30.25,30.22,30.18,10,5,1,8,4,,0.29,8,Rain,291
2014-7-14,61,58,55,58,56,51,100,94,83,30.24,30.23,30.22,10,7,0,16,4,,0.01,8,Fog,307
2014-7-15,64,58,55,53,51,48,93,78,64,30.27,30.25,30.24,10,10,10,17,12,,0.00,6,,318
2014-7-16,61,56,52,51,49,47,89,76,64,30.27,30.23,30.16,10,10,10,15,6,,0.00,6,,294
2014-7-17,59,55,51,52,50,48,93,84,75,30.16,30.04,29.82,10,10,6,9,3,,0.11,7,Rain,232
2014-7-18,63,56,51,54,52,50,100,84,67,29.79,29.69,29.65,10,10,7,10,5,,0.05,6,Rain,299
2014-7-19,60,57,54,55,53,51,97,88,75,29.91,29.82,29.68,10,9,2,9,2,,0.00,8,,292
2014-7-20,57,55,52,54,52,50,94,89,77,29.92,29.87,29.78,10,8,2,13,4,,0.31,8,Rain,155
2014-7-21,69,60,52,53,51,50,97,77,52,29.99,29.88,29.78,10,10,10,13,4,,0.00,5,,297
2014-7-22,63,59,55,56,54,52,90,84,77,30.11,30.04,29.99,10,10,10,9,3,,0.00,6,Rain,240
2014-7-23,62,58,55,54,52,50,87,80,72,30.10,30.03,29.96,10,10,10,8,3,,0.00,7,,230
2014-7-24,59,57,54,54,52,51,94,84,78,29.95,29.91,29.89,10,9,3,17,4,28,0.06,8,Rain,207
2014-7-25,57,55,53,55,53,51,100,92,81,29.91,29.87,29.83,10,8,2,13,3,,0.53,8,Rain,141
2014-7-26,57,55,53,57,55,54,100,96,93,29.96,29.91,29.87,10,8,1,15,5,24,0.57,8,Rain,216
2014-7-27,61,58,55,55,54,53,100,92,78,30.10,30.05,29.97,10,9,2,13,5,,0.30,8,Rain,213
2014-7-28,59,56,53,57,54,51,97,94,90,30.06,30.00,29.96,10,8,2,9,3,,0.61,8,Rain,261
2014-7-29,61,56,51,54,52,49,96,89,75,30.13,30.02,29.95,10,9,3,14,4,,0.25,6,Rain,153
2014-7-30,61,57,54,55,53,52,97,88,78,30.31,30.23,30.14,10,10,8,8,4,,0.08,7,Rain,160
2014-7-31,66,58,50,55,52,49,100,86,65,30.31,30.29,30.26,10,9,3,10,4,,0.00,3,,217
参考:https://blog.csdn.net/qq_44907926/article/details/108284168
import csv
from matplotlib import pyplot as plt
from datetime import datetime
'''处理少量csv数据时!'''
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f) #创建一个与该文件相关联的阅读器对象
header_row = next(reader) # 模块csv的reader类包含next()方法,表用时返回文件的下一行
#因为就调用一次next()方法,所以返回文件的第一行
# for index,column_header in enumerate(header_row): #对列表调用enumerate()方法,获取每个元素的索引及其值
# print(index,column_header)
#获取日期和最高气温
dates,highs =[],[]
for row in reader: #依此循环csv文件的每一行
current_date = datetime.strptime(row[0],"%Y-%m-%d") #取出每一行的下标为0的数据
dates.append(current_date)
high = int(row[1]) #循环的每一行数据为列表形式存在row里,取出每一行的下标为1的数据
highs.append(high)
#根据数据绘制图形
fig = plt.figure(dpi=128,figsize=(10,6)) #设置绘图窗口的尺寸
plt.plot(dates,highs,c='red')
#设置图形的格式
plt.title("Daily high temperatures, July 2014", fontsize=24)
plt.xlabel('',fontsize=16)
fig.autofmt_xdate() #使x轴标签绘制为斜的日期标签,以免它们彼此重叠
plt.ylabel("Temperature(F)",fontsize=16)
plt.tick_params(axis='both',which='major',labelsize=16)
plt.show()

如果用我的数据集,因为那个数据太密集了:

筛选一下就好啦
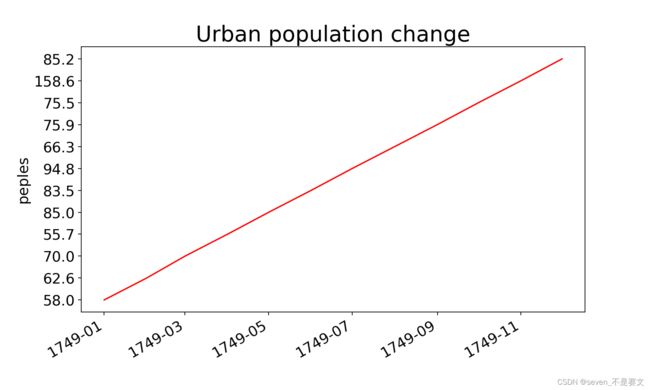
又或许改一下字体大小
plt.xlabel("销售月份",fontsize=16,color='red',fontweight='bold',loc='center',backgroundcolor='black',
labelpad=10,rotation=1,alpha=1)
'''
```handlebars
fontsize 设置字体大小 默认值为12
fontweight 设置字体粗细
color 设置字体颜色
loc 设置标题对齐方式 具体值有center left right top bottom
backgroundcolor 设置背景颜色
labelpad 设置距离轴的距离
rotation 设置倾斜角度 取值为数值
alpha 设置透明度 取值为0-1之间