走进机器学习

作者简介:本人是一名大二学生,就读于人工智能专业,学习过c,c++,java,python,Mysql等编程知识,现在致力于学习人工智能方面的知识,感谢CSDN让我们相遇,我也会致力于在这里分享自己的学习知识。
专栏简介:本专栏作为深度学习的专栏,注重于介绍神经网络,强化学习等重要框架理论知识,也会介绍一些算法,少部分代码作为示例,具体的代码学习会放在后面的神经网络学习专栏。旨在让大家认识神经网络,强化学习,深度学习,人工智能之间的关系,并利用这些知识解决生活中的一些问题。
学习目标:
(1)、掌握深度学习背后的数学理论。
(2)、使用卷积神经网络和胶囊网络研究计算机视觉。
(3)、使用循环网络和注意力模型实现NLP任务。
(4)、探索认识强化学习,深度学习。
(5)、了解探索深度学习在生活中的应用。
日常分享:每天努力一点,不为别的,只是为了日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!

目录
论述人工智能
机器学习概述
机器学习算法
监督学习
1.线性回归和逻辑回归
2.支持向量机
3.决策树
4.朴素贝叶斯
无监督学习
K-means
强化学习
Q-learning
总结
论述人工智能
人工智能的发展从二战后到今天,经历了三次变革,起起落落,前两次兴起则是在20世纪,而这第三次就是在2012年到现在,相信很多小伙伴都已经了解过Chatpt了,chatgpt的出世可以说是一次划时代,有人说这是第四次半工业革命的开始,所以人工智能的发展是非常必要的。那么什么叫作人工智能,人工智能与深度学习,机器学习,神经网络之间的关系又是什么?
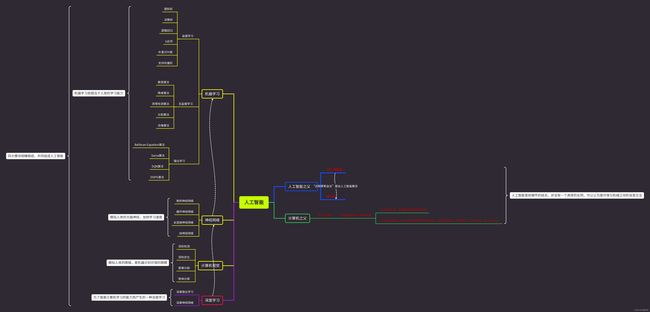
这里我给出我画得思维导图,这也是我对人工智能的理解,人工智能并不是一个确切的概念,所以可以和外界进行信息交互的都应该被称作人工智能,上到神经交互,下到语音交流等,这些其实都可以理解为人工智能。我对人工智能的理解就是一个能够与环境进行交互的系统。
机器学习概述
机器学习通常与大数据和人工智能等术语联系在一起。但是吧,这三者还是有很大的区别,大数据可以说是利用了机器学习,机器学习又需要大数据,可以说他们两个也是组成人工智能重要的框架。
据说,谷歌公司一天处理的数据就达到了20PB的容量,这个数据是非常恐怖的,并且这个数据还在不断的增加。根据IBM的估计,每天都会茶ungjai创建2.5EB的数据,而且这些数据都是两年前已经创建的。
对于这么多的数据,如果是仅仅靠人类去分辨,那可能是永远也分辨不完的,于是机器学习也因此诞生,机器学习,顾名思义,就是发现数据中存在的逻辑,模式和规律。机器学习就像人类的大脑,使机器能够通过分析传感器传回的数据,从而做出一定响应。比如说,摄像头的人物识别预警系统,摄像头采集到的人物的面目信息传回到总体的系统,然后经过特征提取,信息比对,判断是否为危险分子,并对警报系统发布指令。那么如何发布正确的指令,就需要对信息的准确的处理,生成相应的指令。
上面说了机器学习,那么深度学习又是什么?其实你可以理解为深度学习是机器学习和神经网络的子领域,但是又不完全是子领域,可以说深度学习是为了更加的辅助机器学习,而神经网络则也是如此。他们既是相辅相成的,又是可以自己独当一面的。
机器学习算法
“机器学习”这个术语只是一种通用的方式称呼,指的是用于从大型数据集合中推断模式的通用技术,可以大致理解为是一种基于现有的数据对新数据进行预测的能力。机器学习算法大致可以分为以下几类:
(1)、监督学习(Supervised Learning)。
(2)、无监督学习(Unsupervised Learning)。
(3)、强化学习(Reinforcement Learning ,RL)。
监督学习
监督学习算法是机器学习算法的一类,他使用的是先前标记的数据学习特征,,从而对相似的未标记的数据进行分类。下面我给出一个例子就很好懂了:
手机上的屏蔽大家应该都不陌生,可以屏蔽消息,视频等等,那么是怎么做到屏蔽的喃?其实就是根据一些标记进行分类。比如说,垃圾邮件我们标记为0,工作邮件标记为1,家庭邮件标记为2,亲戚邮件标记为3,到时候只需要根据标记就可以进行分类,但是这个分类是不需要我们进行分类的,是你使用的软件进行分类。当然,这也是一个非常复杂的事。也就是前面说的,需要很多的数据进行训练,生成一个准确的模型,也就是在这种情况下,神经网络,深度学习才发展起来的。
1.线性回归和逻辑回归
回归算法(Regression Algorithms)是一种监督性算法,它使用输入数据的特征来预测值,简单点来说就是找到最适合输入数据集的参数值。这样可能不太好理解,我举个例子,比如你有100元,你知道水果的价格,需要买水果,最可能的买到多的水果,我们该如何去分配?就需要根据各种水果的价格来进行计算,找到每种水果的最大购买量,这样是不是就好理解了。
在线性回归算法中,目标是通过最接近目标值的输入数据上为函数找到合适的参数以使代价函数(Cost Function)最小。代价函数是计算误差的函数,用来度量真实值与预测值的差距。代价函数通常用均方误差(MSE)表示,此处取期望值与预测结果只差的平方,
假设有一个小区,里面的房子需要卖出去,你刚好需要买,你有1000000元,需要买一套房子,不知道房子买多大,多少个卧室。厕所,厨房,在哪个街区,哪个区域,假设卧室价格2000,厕所价格1000,厨房价格1500,街区有10个,区域划分为0~5,那么它的价格为:
![]() .当然,这得出的结果可能不是特别的完美,这是需要很多的数据的,比如你利用了1000栋房子,计算出这几个参数值
.当然,这得出的结果可能不是特别的完美,这是需要很多的数据的,比如你利用了1000栋房子,计算出这几个参数值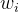 ,使其达到最优解。
,使其达到最优解。
使用一些随机值初始化向量w
循环:
E=0 #用0初始化代价函数
for 循环遍历训练集的每个个体(样本),目标对(
):
E+=(
) #
是房屋的实际价格
MSE=E/样本总数 #均方误差
基于MSE使用梯度下降法更新权重w
知道MSE低于阈值
所以我们的目标就是得出最优的w解,也就是获取最优参数,生成模型后,就可以直接使用了。后面介绍神经网络的时候会详细介绍如何进行训练。
除了线性回归,还有一个就是逻辑回归,这个和线性回归的区别就是最后的结果,线性回归的出的结果是![]() ,而逻辑回归最后得到的就是一个特殊的Logistic函数
,而逻辑回归最后得到的就是一个特殊的Logistic函数![]() ,他得出的结果可以理解为概率值,范围为【0-1】,比如说,世界杯上,我们知道了一个球员射门的位置,结合以前他射门的位置的数据,训练成一个数据集,只需要输入此次的数值,就可以得出此次射门进球的概率(不考虑其他因素影响);越接近1,则发生的可能性越大。
,他得出的结果可以理解为概率值,范围为【0-1】,比如说,世界杯上,我们知道了一个球员射门的位置,结合以前他射门的位置的数据,训练成一个数据集,只需要输入此次的数值,就可以得出此次射门进球的概率(不考虑其他因素影响);越接近1,则发生的可能性越大。
逻辑回归不是一种分类算法,但是也可以作为分类算法,比如以0.5为判断值,如果结果大于0.5,则表示能踢进,否则,不能进。
2.支持向量机
支持向量机(Support Vector Machine,SVM)是一种监督性机器学习算法,主要用于分类。前面解释过的,其实就是找到一个超平面将数据分割出来。

就像上面的图片,红色的点和蓝色的点是两种不同的类别,我们的目的就是分割出来,所以中间的平面就是分割面,也叫做超平面,超平面的概念就是高维空间中的平面,例如一维空间中超平面是一个点,二维空间中是一条线,三维空间是一个面。当然,在实际情况中,两边的数据集是会出现交错的,所以简单的平面是布恩那个做到准确的分类的,就需要用到激活函数,这个我在计算机视觉专栏中介绍过了。
除了使用激活函数,对于一些非线性分类,还可以使用其他的方法来进行实现:引入软间隔(Soft Margin)或使用核技巧(Kernel Trick)。
软间隔的工作原理就是允许犯错,也就是或它是允许一些数据分错类,只要在规定的比例之类,是可以接受的,这种最简单,但是对于一些非常精密的数据分类,会存在很大的误差,同时容易出现过拟合。
核技巧,简单的来说就是改变维度,二维空间内不能解决的,就用三维解决,这样,二维中的不可线性分类为问题,在三维中或许就可以进行分类。
3.决策树
最后再介绍一种监督性算法,决策树(Decision Tree),决策树的创建是以树的原理进行创建,由决策节点和叶节点组成,决策节点对特定属性执行测试,叶节点指示目标属性的值。
我们借用一个鸢尾花数据集来进行分析:

经过这些年的发展,决策树在两个大的方面做出了改进:第一种是随机森岭(Random Forest),它是一种继承方法,结合了多棵树的预测;第二种是梯度提升机(Gradient Boosting Machine),他创建了多个顺序决策树,每棵树都试图改善前一棵树的误差。因为这些改进,决策树算法越来越被人们接受使用。
4.朴素贝叶斯
朴素贝叶斯(Naive Bayes)不同于其他机器学习算法,大多数机器学习技术都试图评估某个事件Y在给定条件X下的概率p(Y|X)。
我们给出一个概念,假设已知事件Y及其概率,样本是X。朴素贝叶斯定理指出p(X|Y)=p(Y|X)p(X)/p(Y),其中p(X|Y)表示给定Y条件下X的概率,这也就是朴素贝叶斯被称为生成方法(Generative Approach)的原因。下面我给出一个例子:
假设有一种癌症,这种癌症只影响老年人,50岁以下的人中只有2%的人患这种癌症,对50岁以下的人进行的测试,只有3.9%的人呈阳性。问题是:如果一项检查的癌症准确率达到98%,当一个45岁的人进行检测,结果成阳性,那么此人患癌症的概率是多大。
p(癌症|检测=阳性)=0.98*0.02/0.039=0.50。
将此分类器称为朴素贝叶斯,因为它假设不同事件的独立性以计算其概率。其实这个和概率论中的计算方式很相似。只不过是用来进行的一种实际应用。
无监督学习
无监督学习是机器学习算法中的第二类。它不需要预先标记数据,而是让算法得出结论。在无监督学习中,最常见的就是聚类,是一种尝试将数据分离为子集的技术。
简单的来说,就是把具有相似特征的数据放在一个组,用一句名言“物以类聚”。

深度学习也使用的是无监督学习,尽管与聚类不同。在自然语言处理(Natural Langurage Processing,NLP)中,使用无监督(或半监督,取决于询问的对象)算法表示单词向量,最常用的方法就是word2vec。
无监督学习的另一个有趣应用是生成模型(Generative Model),与判别模式不同,它是使用一个特定领域的大量数据(如图像或文本)训练生成模型,并且该模型将尝试生成与用于训练的数据相似的新数据。
K-means
K-means是一种聚类算法,它将数据集的元素分组到k个不同的簇中(名称中k的由来)。
(1)、从特征空间中选取k个随机点,称为质心(Centroids)代表k个簇的中心。
(2)、将数据集的每个样本(即特征空间中的每个点)指定给距离质心最近的簇。
(3)、对于每个簇,通过取簇中所有点的平均值以重新计算新质心。
(4)、对于新质心,重复(2)和(3),直到满足条件停止。

强化学习
强化学习是机器学习中的第三类。强化学习的使用非常多,顾名思义,强化学习就是让机器具有学习能力。根据目标,选择每一步的行动或选择。在强化学习中,代理采取行动,从而改变环境状态。代理使用新状态和奖励确定下一步行动。例如,举个例子,几年前的“阿尔法狗”和围棋大师李世石进行比赛,这里的阿尔法狗他其实用到的就是强化学习,根据预测到的下棋位置,选择最佳的下棋方式。
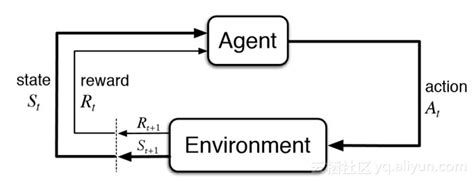
当然,强化学习的应用还不仅仅如此,比如像对抗游戏,车辆自动驾驶,股票投资等。强化学习是一个非常庞大的体系,也算是机器学习中比较重要的一个分支。
Q-learning
Q-learning(Q学习)是一种偏策略的时序差分强化学习算法。Q-learning算法之所以叫做Q学习,是因为其中用到了一个Q表,就是用来存储所有行动的组合,比如说象棋游戏,最开始Q表是空的,但是每走一步就会收录到Q表,同时根据这些组合形成Q值,Q值越大,行动越有吸引力,也就是说权值越高,越有可能成为下一个行动的目标。
使用任意值初始化的Q表
对于每个状态序列:
观察初始状态s
对于本状态序列的每一步
使用基于Q表的策略选择新行动a
观察奖励r并进入新状态s‘
使用贝尔曼方程更新Q表中的q(s,a)
直到本状态序列的终止状态
Q-learning算法会利用贝尔曼方程(Bellman Equation),在每个新行动后更新q(s,a)。这里只是简单的介绍一下,后面会详细介绍。
但是吧,你们应该能发现,Q学习中的Q表会随着行动越来越大,读取速度就会越来越慢,所以可以使用神经网络来替换Q表。比如说,在Go、Dota2和Doom等游戏上发挥了很大的作用。
总结
本节的内容就介绍到这里了,对于机器学习,很多人都是似懂非懂,这里我将机器学习中的一些基本知识进行了介绍,后面会详细介绍如何去使用。下一节就是神经网络的学习了。欢迎留赞,收藏。