全链路压测
一般区分为两种:测试环境和生产环境压测。因生产环境的压测和真实用户的使用环境完全一致,测试结果更具有参考性。
全链路的压测的实施一般需要给压测请求带一个压测标识,用于压测数据的数据落库,查询,缓存,消息中间件topic的数据隔离。通常的在处理请求头中带eg:yc标识的请求,数据库操作自动指向对应业务的影子表(根据真实业务表的表结构创建的另外一张影子表,如xxx_test)、缓存查询、消息处理也指向对应的_test组件或topic。
对于程序处理的业务逻辑压测和正式请求则使用同一套。
主要流程

在系统的性能稳定性保障的流程,大概有如下六个事情
1.系统峰值评估
toC 的业务,从登录到交易,其实系统是有物理上限的,而人民群众对于系统的热爱是不可阻挡的。所以在评估系统峰值的时候,是需要和业务部门,约定好系统到底要支撑多少峰值,以此作为容量评估的依据。
也会有一种情况,是业务部门也不知道该支撑多少,这时候,根据以往的监控数据,乘以一个倍数来让业务方选择即可。
还有一种情况,是新接口或者线上未监控的接口,不存在历史数据,且不存在类似功能接口的数据可供参数考,此时需要估算峰值,常用方法有 8/2 原则——一天内 80%的请求会在 20%的时间内到达。
top QPS = (总 PV 0.8) / (60 60 * 24 * 0.2)
RT 如无特殊要求,一般采用默认值:
单服务单表类,RT<100ms
较复杂接口,RT<300ms
大数据量或调用链较长的接口,RT<1s
电商秒杀活动,预估同时有 1000w 人参与,简单起见假设总 QPS 是 1000w。由于前端不同的秒杀倒计时形式使得请求有 2s 的打散,再加上 nginx 等 webserver 做了 20%几率拒绝请求的策略,所以下单接口总 QPS = 1000w / 2 * (1 - 0.2) = 400w/s,最终压测目标为 400w/s 的 QPS。
电商全天低价抢购活动:根据 8/2 原则,预估在午休(12-1)和晚上下班后(7-10)共 4h 是流量高峰,估算接口峰值 QPS = 活动全天接口 PV / (4*3600s)。
2.依赖梳理 &上下游流量评估
微服务架构下,服务的调用网络呈现出网状模型,如果本身有分布式链路追踪的工具,可以比较快速的进行依赖梳理。
什么是上游、下游?
下游的输入来自于上游的输出,假设有服务 A、B,A 调用了 B(或者说 A 依赖 B),那 B 就是 A 的上游,A 就是 B 的下游,因为 A 的输入来自于 B 的输出(A 调用了 B,获取 B 的输出)
上下游流量评估,主要是结合上面的系统峰值,来判断上下游的流量情况。
3.单链路压测
链路这个词,很容易产生歧义。我和不同的人交流过,对这个词语都会不同的理解。
如何避免产生歧义呢,其实很简单,按照一个 http 或者 dubbo 的入口来作为原子链路,是最不容易产生歧义的。
为什么要做单链路的压测?
在微服务架构下,整体链路的性能瓶颈,取决于短板(木桶原理)。
因此,单机单链路基准测试的目的,是在全链路压测开始前进行性能摸底,定位排查链路瓶颈。
4.系统优化、扩容
在做单链路的压测完毕后,定位瓶颈点。对瓶颈点进行优化完毕后,根据系统峰值进行扩容。
5.生产环境全链路压测
在完成了单链路的压测、优化、扩容后,就可以进入到全链路压测的阶段了。
一般来说,在开始全链路压测前,还要做一波预热,预先跑一部分流量使得该缓存的数据提前缓存起来。
正式压测时细分有几种压测策略:
峰值脉冲:流量是逐渐变大的一个小坡,还是骤升后保持高峰;
系统摸高:关闭熔断降级限流等 fallback 功能,提高压力观察系统性能转折点;
fallback 策略验证:开启熔断限流等 fallback 功能,这些功能是否生效,系统是否还能扛得住;
破坏性测试:主要为了验证预案的有效性,类似于容灾演练时的预案执行演练,验证后手抢救方案。
6.预案评审、演练 &应对手册输出
专项预案主要包括如下几项:限流、降级、熔断、脉冲、破坏性验证等五种场景。
进行预案演练的目的主要有如下几项:
1、验证预案是否生效;
2、针对预案设定阈值进行测试调优;
3、验证预案生效时服务本身的性能表现;
4、针对上述专项场景进行实战演练;
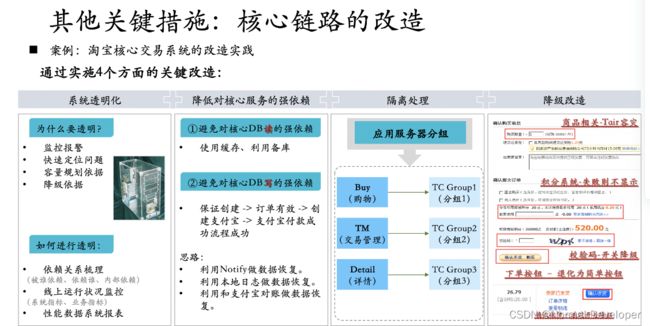
其他关键措施
为了保证核心业务的高可用,生产环境的压测是一种技术手段,同时仍要从系统透明化、降低强依赖、隔离、降级这些手段入手。