史上最全的集合(集合UML图(Collection集合和Map集合)详解,子接口(list和set)泛型)
文章目录
- 一.集合的UML图
- 二.Collection集合
-
-
- 1. 集合与数组之间的区别:
- 2.Collection集合的功能(方法)概述
- 3.Collection集合面试题分析:
-
- 三.迭代器(Iterator):用来遍历数据结构
-
-
-
-
- Iterator接口的子接口(ListIterator)
- 并发修改异常(ConcurrentModificationException)出现的原因
-
-
-
- 四 .Collection的子接口List
-
-
- 1.List集合特有的功能
- 2.List的三个子类
-
- (1)三个子类(ArrayList,Vector,LinkedList)之间的区别
- (2)ArrayList特有的方法功能
-
- 如何把ArrayList变成线程安全的?
- (3)Vector特有的方法功能
- (4)LinkedList特有的方法功能
-
- 五.Map集合
-
-
- 1.Map集合的UML图
- 2.Set接口和Map接口之间的关系
- 3.HashMap详解
-
-
- ①HashMap底层源码分析
- ②底层内存图
- ③HashMap常用方法
- ④put方法和get方法的内部实现原理
-
- 4.HashTable
-
-
- ①HashMap和HashTable的区别
- ② Properties类(HashTable的子类)
-
- 5.TreeMap
-
-
- ①对于自定义类型来说,TreeSet可以排序吗
- ②解决自定义类型无法排序的三种方式
-
- 6.Collections工具类
-
- 六.泛型
一.集合的UML图

集合有两种存储方式:
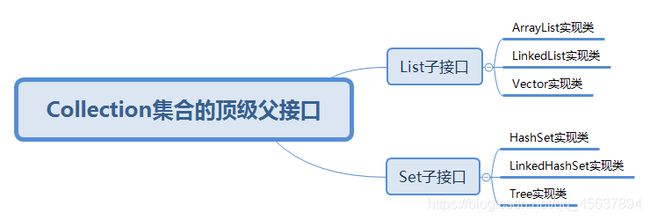
①单个方式存储元素: 顶级父接口:java.util.Collection
②以键值对的方式存储 顶级父接口:java.util.Map
二.Collection集合
集合类的作用:方便操作多个对象。
- 数组就是一个集合
- 集合也是一个对象,也有内存地址
- List集合元素的特点:有序可重复,存储有下标
- Set集合元素的特点:无序不可重复,无下标
1. 集合与数组之间的区别:
(1): 长度区别:
数组的长度是固定的而集合的长度是可变的
(2): 存储数据类型的区别:
数组可以存储基本数据类型 , 也可以存储引用数据类型; 而集合只能存储引用数据类型
(3): 内容区别:
数组只能存储同种数据类型的元素 ,集合可以存储不同类型的元素
2.Collection集合的功能(方法)概述
| Collection集合的方法 | 概述 |
|---|---|
| boolean add(Object obj) | 添加一个元素 |
| boolean addAll(Collection c) | 添加一个集合的元素 |
| void clear() | 移除所有元素 |
| boolean removeAll(Collection c) | 删除的元素是两个集合的交集元素 |
| boolean remove(Object o) | 移除一个元素 |
| boolean contains(Object o) | 判断集合中是否包含指定的元素 |
| boolean containsAll(Collection c) | 判断这个集合 是否包含 另一个集合中所有的元素 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 元素的个数 |
代码展示:
//Collection中的方法
Collection list = new ArrayList();
list.add(1);//自动装箱
list.add("111");
list.add(new Object());
list.size(); //获取集合中元素的个数
System.out.println(list);
boolean contains = list.contains("111");
System.out.println(contains);//判断集合中 是否有某个对象的地址
// list.clear(); //清除数组元素
list.remove("111");//移除数组元素
System.out.println(list);
boolean empty = list.isEmpty(); //判断集合是否为空
System.out.println(empty);
Object[] objects = list.toArray();//集合转换为数组
for (int i = 0; i < objects.length; i++) {
System.out.println(objects[i]);
}
3.Collection集合面试题分析:
public class CollectionText03 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
String abc = new String("abc");
list.add(abc);
String abc1 = new String("abc");
boolean contains = list.contains(abc1);
System.out.println(contains);
//contains底层调用了equals方法,string重写了equals,如果不重写,则为false
boolean remove = list.remove(abc1);
System.out.println(remove);
//remove同样调用了equals方法
//重写equals方法是每个程序员的素养
}
}
运行结果:
true
true
从源代码中我们可以看出contain方法和remove方法底层调用了equals方法,而String类型底层重写了equals方法,所以abc和abc1指的是同一个对象。
三.迭代器(Iterator):用来遍历数据结构
public class MyTest {
public static void main(String[] args) {
Collection collection1 = new ArrayList();
collection1.add("美国队长");
collection1.add("钢铁侠");
collection1.add("雷神");
collection1.add("黑寡妇");
Iterator iterator = collection1.iterator();
Object next = iterator.next();//手动移动
while (iterator.hasNext()){
Object obj= iterator.next();
System.out.println(obj);
}
}
}

Iterator接口的子接口(ListIterator)
| ListIterator特有的方法 | 概述 |
|---|---|
| boolean hasPrevious(): | 是否存在前一个元素 |
| E previous(): | 返回列表中的前一个元素 |
注意:以上两个方法可以实现反向遍历 但是注意 要完成反向遍历之前 要先进行正向遍历 这样指针才能移到最后,如果直接反向遍历是没有效果的 因为指针默认位置就在最前面 他前面没有元素。
并发修改异常(ConcurrentModificationException)出现的原因
原因是:我们的迭代依赖与集合 当我们往集合中添加好了元素之后 获取迭代器 , 那么迭代器已经知道了集合的元素个数;
这个时候你在遍历的时候又突然想给 集合里面加一个元素(用的是集合的add方法),就会出现并发修改异常。
如何更改:
- 采用迭代器自带的add方法添加元素(ListIterator.add());
- 使用for循环遍历元素。
四 .Collection的子接口List
1.List集合特有的功能
| 方法 | 概述 |
|---|---|
| void add(int index,E element) | 在指定索引处添加元素 |
| E remove(int index) | 移除指定索引处的元素 |
| E get(int index) | 获取指定索引处的元素 |
| E set(int index,E element) | 更改指定索引处的元素 |
2.List的三个子类
(1)三个子类(ArrayList,Vector,LinkedList)之间的区别
- ArrayList:
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高。 - Vector:
底层数据结构是数组,查询快,增删慢。
线程安全,效率低。 - LinkedList:
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高。
(2)ArrayList特有的方法功能
| void forEach(Consumer action) | 执行特定动作的每一个元素的 Iterable直到所有元素都被处理或操作抛出异常 |
- 底层先创建了一个长度为0的object[]数组,当添加第一个元素时,初始化容量为10
- Arraylist的扩容时=是原容量的1.5倍(底层调用了grow方法)
int newCapacity = oldCapacity + (oldCapacity >> 1);
代码展示:方法的使用
public class ListText01 {
public static void main(String[] args) {
//list集合有序可重复,并且有下标
//list中常用的方法
List o = new ArrayList<>();
o.add("1"); //默认向集合末尾加入元素
o.add(111);
o.add(1,22);//在列表指定位置添加元素 效率比较低,不常用
o.add(new Object());
Iterator iterator = o.iterator();
while (iterator.hasNext()){
Object next = iterator.next();
System.out.println(next);
}
Object o1 = o.get(0);//通过下标获取元素
//通过下标去获取元素
for (int i = 0; i < o.size(); i++) {
Object o2 = o.get(i);
System.out.println(o2);
}
int index = o.indexOf("1");//指定对象第一次出现的索引
int index1 = o.lastIndexOf("1");//最后一次出现的索引
Object remove = o.remove(1);//删除指定下标的元素
Object set = o.set(3, "444"); //修改指定位置的元素
}
}
如何把ArrayList变成线程安全的?
ArrayList list = new ArrayList();
//变成线程安全的
Collections.synchronizedList(list);
(3)Vector特有的方法功能
| public void addElement(E obj) | 将指定的数据类型添加到此向量的末尾,使其大小增加1. |
| public E elementAt(int index) | 在指定的索引处加入指定的数据类型 |
| public void setElementAt(E obj, int index) | 将指定索引处的组件设置为指定的对象 |
| public boolean removeElement(Object obj) | 移除索引最小的匹配项 |
- 底层同样调用了grow方法进行扩容 ,容量扩大了原来的2倍
- 线程安全,但效率低
(4)LinkedList特有的方法功能
| public void addFirst(E e) | 将指定的元素插入集合的开头 |
|---|---|
| public void addLast(E e) | 将指定的元素插入集合的末尾 |
| public E getFirst() | 返回此集合的第一个元素 |
| public E getLast() | 返回此集合的最后一个元素 |
| public E removeFirst() | 移除此集合的第一个元素 |
| public E removeLast() | 移除此元素的最后一个元素 |
五.Map集合
1.Map集合的UML图
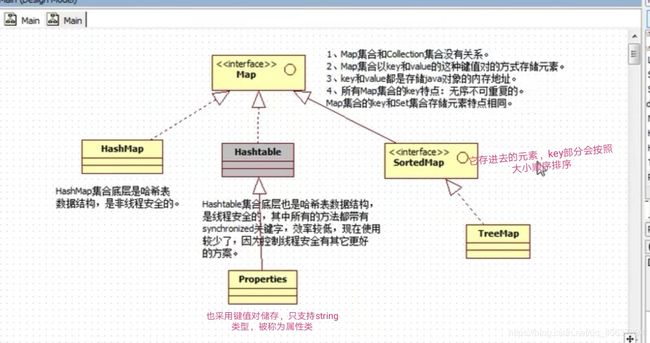
2.Set接口和Map接口之间的关系
- HashSet底层new了个hashMap,底层通过put方法将元素放到了hashMap集合的key部分
- TreeSet底层是TreeMap,传到了TreeMap的key部分
- SortedMap和SortedSet接口,会将key部分的元素按照大小顺序自动排序
3.HashMap详解
①HashMap底层源码分析
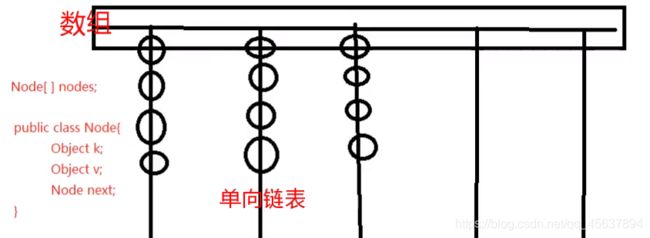
HashMap的底层是哈希表(数组和链表的结合体)Node对象
HashMap集合的默认初始化容量为16,默认加载因子为0.75(当底层的数组容量达到75%时,数组开始扩容)
底层扩容为原来的2倍
HashMap的初始化容量必须是2的倍数,以此达到散列分布均匀
如果哈希表中的元素的数量超过了8个,就会将单向链表转换成红黑树数据结构,如果小于6会自动转换成单向链表
Node对象的四个属性:
-
int hash; 哈希值(key的hashCode方法的执行结果,hash值通过哈希算法,可以转换存储成数组的下标) -
K key; map集合中的key -
V value; map集合中的value -
Node
②底层内存图
③HashMap常用方法
| HashMap的常用方法 | 概述 |
|---|---|
| put(key,value); | 往集合中添加元素 |
| get(key); | 通过key获取value |
| size(); | 获取键值对的数量 |
| remove(key); | 通过key删除键值对 |
| containsKey(key) | 判断是否包含某个key |
| containsValue(value) | 判断是否包含某个value |
| values(); | 获取所有的value |
| keySet(); | 过keyset方法获取所有的key,返回一个set数组 |
| entrySet(); | 将map集合直接转换为set集合,返回一个Node对象 |
| clear(); | 清空map集合 |
| isEmpty(); | 判断是否为空 |
代码展示:
iMap.put(1,"刘恒");
iMap.put(2,"鸣轩");
iMap.put(3,"贾刘煜");
String s = iMap.get(1); //通过key获取value
System.out.println(s);
int size = iMap.size(); //获取键值对的数量
System.out.println(size);
iMap.remove(1);//通过key删除键值对
System.out.println(iMap.size());
//判断是否包含某个key或者value
boolean b = iMap.containsKey(1);
boolean 刘恒 = iMap.containsValue("刘恒");
// iMap.clear(); //清空map集合
// iMap.isEmpty();//判断是否为空
Collection<String> values = iMap.values(); //获取所有的value
for (String value : values) {
System.out.println(value);
}
//通过keyset方法获取所有的key,通过key遍历,调用get方法获取所有的value
Set<Integer> integers = iMap.keySet();
for (Integer integer : integers) {
String s1 = iMap.get(integer);
System.out.println(integer+""+s1);
}
//class Node implements Map.Entry事实上Map.Entry中的每个元素都是Node对象
//将map集合直接转换为set集合,里面元素的类型是Map.Entry是一个静态内部类
Set<Map.Entry<Integer, String>> entries = iMap.entrySet();
for (Map.Entry<Integer, String> node : entries) {
Integer key = node.getKey();
String value = node.getValue();
//效率高
}
System.out.println(entries);
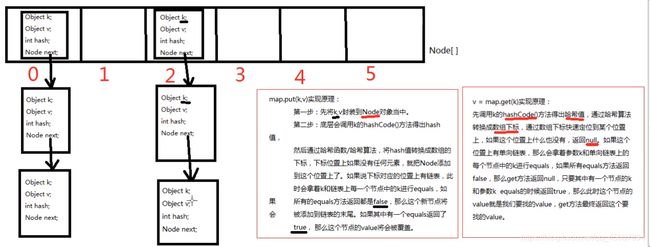
④put方法和get方法的内部实现原理
4.HashTable
①HashMap和HashTable的区别
- HashTable的key和value都不能为null,HashMap相反都可以为null
- HashTable是线程安全的,HashMap不是线程安全的
- HashTable初始化容量为11,加载因子为0.75,扩容是原容量的2倍加一
- HashMap的初始化为16,加载因子为0.75,扩容为原来的2倍
② Properties类(HashTable的子类)
- key和value都是String对象
- 是线程安全的
代码展示:常用方法
Properties properties = new Properties();
properties.setProperty("1","刘恒"); //底层调用了put方法
String property = properties.getProperty("1");
System.out.println(property);
5.TreeMap
实现了SortedMap接口,因此具有自动排序的功能
对于String和Integer等实现了Comparable接口的类才能排序
①对于自定义类型来说,TreeSet可以排序吗
无法排序,因为没有指定自定义类型对象之间的比较规则,谁大谁小并没有说明
会出现类型转换异常,通过观看源代码我们可以知道treemap的无参构造,使comparator = null,在调用put方法时
Comparable k = (Comparable) key;进行了强制类型转换,然后调用compare to方法进行比较
②解决自定义类型无法排序的三种方式
- 让自定义类实现java.lang.comparable接口,重写compare to方法
public class Student implements Comparable<Student> {
String name;
public Student(String name) {
this.name = name;
}
@Override
public int compareTo(Student o) {
//this.age-o.age
int i = this.name.compareTo(o.name);
return i;
}
- 编写一个比较器实现java.util.Comparator接口
public class TreeSetText02 {
public static void main(String[] args) {
TreeSet<Wugui> wuguis = new TreeSet<>(new WuGuiComparator());
wuguis.add(new Wugui(10000000));
wuguis.add(new Wugui(2));
wuguis.add(new Wugui(222222));
for (Wugui wugui : wuguis) {
System.out.println(wugui);
}
}
}
class Wugui{
int age;
public Wugui(int age) {
this.age = age;
}
@Override
public String toString() {
return "Wugui{" +
"age=" + age +
'}';
}
}
//单独在这里编写一个比较器实现java.util.Comparator接口
class WuGuiComparator implements Comparator<Wugui>{
@Override
public int compare(Wugui o1, Wugui o2) {
return o1.age-o2.age;
}
}
- 通过匿名内部类,同样实现Comparator接口
public class TreeSetText02 {
public static void main(String[] args) {
TreeSet<Wugui> wuguis = new TreeSet(new Comparator<Wugui>(){
@Override
public int compare(Wugui o1, Wugui o2) {
return o1.age-o2.age;
}
});
wuguis.add(new Wugui(10000000));
wuguis.add(new Wugui(2));
wuguis.add(new Wugui(222222));
for (Wugui wugui : wuguis) {
System.out.println(wugui);
}
}
}
class Wugui{
int age;
public Wugui(int age) {
this.age = age;
}
@Override
public String toString() {
return "Wugui{" +
"age=" + age +
'}';
}
}
6.Collections工具类
public class CollectionsText {
public static void main(String[] args) {
ArrayList<String> objects = new ArrayList<>();
Collections.synchronizedList(objects); //变成线程安全的
objects.add("1");
objects.add("111");
Collections.sort(objects);//排序,要求你的类必须实现Comparable接口
Collections.sort(objects, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return 0;
}
});
//sort方法的参数必须是list集合
for (String object : objects) {
System.out.println(object);
}
HashSet<String> objects1 = new HashSet<>();
ArrayList<String> objects2 = new ArrayList<>(objects1);
Collections.sort(objects2);
}
}
六.泛型
采用泛型的目的:解决需要转型的问题。
(1)泛型类
public class 类名<泛型类型1,…>
注意:泛型类型必须是引用类型
(2)泛型方法
public <泛型类型> 返回类型 方法名(泛型类型 变量名)
(3)泛型接口
public interface 接口名<泛型类型>
(4)泛型通配符
- 通配符 任意类型,如果没有明确,那么就是Object以及任意的Java类了
- ? extends E (向下限定,E及其子类)
- ? super E (向上限定,E及其父类)
public class MyTest2 {
public static void main(String[] args) {
ArrayList<Dog> objects = new ArrayList<Dog>();
//?泛型统配符
ArrayList<?> objects2 = new ArrayList<Cat>();
//向上限定
ArrayList<? super Animal> objects3 = new ArrayList<Animal>();
ArrayList<? super Animal> objects4 = new ArrayList<Object>();
//向下限定
ArrayList<? extends Animal> objects5 = new ArrayList<Dog>();
ArrayList<? extends Animal> objects6= new ArrayList<Cat>();
ArrayList<? extends Animal> objects7 = new ArrayList<Animal>();
}
}
class Animal{
}
class Dog extends Animal{
}
class Cat extends Animal{}