【回眸】Python入门(五)基础语法&&列表和词典:Python如何消灭重复性劳动
前言
本篇博客为填坑篇,这个系列的上一篇竟然是2021年的9月30更新的,离谱,差点就到断更两周年纪念日了,后续逐渐走向填坑的每一天,继续创作,希望这个系列的专栏文章能帮助到更多有需要的人。
列表
什么是列表?

随便写一个: class(列表名) = (赋值) ['高一四班','高二八班','高三六班'](外部是中括号,用逗号隔开)。
一个列表需要用中括号[ ]把里面的各种数据框起来,里面的每一个数据叫作“元素”。每个元素之间都要用英文逗号隔开。
这就是列表的标准格式,现在请创建一个列表名为list1的列表,列表里有三个元素:'啤酒鸭',18,1.75,并将其打印出来:
list1=['啤酒鸭',18,1.75]
print(list1)列表很包容,各种类型的数据(整数/浮点数/字符串)无所不能包。
取出列表里具体的某一个元素
但问题来了,如果只想取出列表里具体的某一个元素该怎么办呢?
这就涉及到一个新的知识点:偏移量。列表中的各个元素,好比教室里的某排学生那样,是有序地排列的,也就是说,每个元素都有自己的位置编号(即偏移量)。

从上图可得:1.偏移量是从0开始的,而非从1开始;2.列表名后加带偏移量的中括号,就能取到相应位置的元素。
所以,可以通过偏移量来对列表进行索引(可理解为搜索定位),读取我们所需的元素。
在【‘啤酒鸭’,'DD','回眸','咸蛋超人'】里取出啤酒鸭这个元素的代码是怎么样的呢?
students = ['咸蛋超人','啤酒鸭','DD','回眸']
print(students[1])从列表提取多个元素
list2 = [5,6,7,8,9]
print(list2[:])
print(list2[2:])
print(list2[:2])
print(list2[1:3])
print(list2[2:4])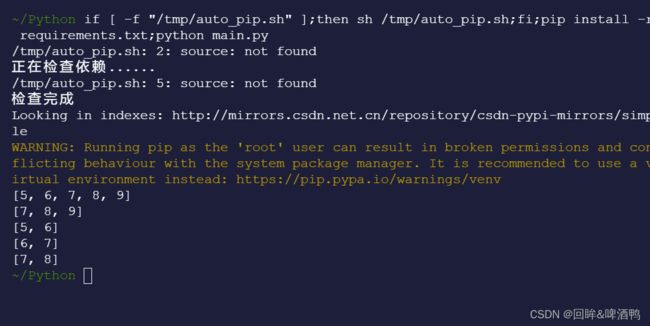
用冒号来截取列表元素的操作叫作切片,顾名思义,就是将列表的某个片段拿出来处理。这种切片的方式可以从列表中取出多个元素。
冒号左边空,就要从偏移量为0的元素开始取;右边空,就要取到列表的最后一个元素。后半句:冒号左边数字对应的元素要拿,右边的不动
速记:左右空取到头,左要取,右不取。
students = ['啤酒鸭','回眸','严啤啤','啤雅雅']
print(students[:3]) 给列表增加/删除元素
增加元素:
append函数并不生成一个新列表,而是让列表末尾新增一个元素。而且,列表长度可变,理论容量无限,所以支持任意的嵌套。
students = ['小明','小红','小刚']
students.append('小美')
print(students)使用append 添加元素可以将新元素添加到链表里。
删除元素:
del语句非常方便,可以删除一个元素,也能一次删除多个元素(原理和切片类似,左取右不取)。
语法是:del 列表名[元素的索引]
students = ['小明','小红','小刚','小美']
del students[1:2]
print(students)运行的结果是发现小红删了。
字典
这次期中考呢、,小啤、小眸、小严分别考了95、90和90分。
假如还用列表来装数据的话,需要新创建一个列表来专门放分数,而且要保证和姓名的顺序是一致的,很麻烦。所以类似这种名字和数值(如分数、身高、体重等)两种数据存在一一对应的情况,用第二种数据类型——“字典”(dictionary)来存储会更方便。
students = ['小啤','小眸','小严']
scores = {'小啤':95,'小眸':90,'小严':90}
print(len(scores))scores(字典名) = {'小啤'(键):95(值),'小眸':90,'小严':90}(大括号)
列表中的元素是自成一体的,而字典的元素是由一个个键值对构成的,用英文冒号连接。如'小啤':95,其中我们把'小啤'叫键(key),95叫值(value)。
这样唯一的键和对应的值形成的组合,我们就叫做【键值对】,上述字典就有3个【键值对】:'小啤':95、'小眸':90、'小严':90
如果不想口算,可以用len()函数来得出一个列表或者字典的长度(元素个数),括号里放列表或字典名称。
这里需要强调的是,字典中的键具备唯一性,而值可重复。
如果你不小心声明了两个以'小啤'为键的【键值对】,后出现的【键值对】会覆盖前面的【键值对】。打印出的值也会以后面一个为准。
这便是从字典中提取对应的值的用法。和列表相似的是要用[ ],不过因为字典没有偏移量,所以在中括号中应该写键的名称,即字典名[字典的键]。
如果想取出小啤的成绩的值,可以运行下面的代码
scores = {'小啤':95,'小眸':90,'小严':90}
print(scores['小啤'])字典的删改
删除字典里键值对的代码是del语句del 字典名[键],而新增键值对要用到赋值语句字典名[键] = 值。
scores = {'小啤':95,'小眸':90,'小严':90}
del scores['小严']
scores['小严']=92
scores['小菜']=85
print(scores)列表和字典的异同
差异
列表中的元素是有自己明确的“位置”的,所以即使看似相同的元素,只要在列表所处的位置不同,它们就是两个不同的元素。
而字典相比起来就显得随和很多,调动顺序也不影响。因为列表中的数据是有序排列的,而字典中的数据是随机排列的。
这也是为什么两者数据读取方法会不同的原因:列表有序,要用偏移量定位;字典无序,便通过唯一的键来取值。
共同点
在列表和字典中,如果要修改元素,都可用赋值语句来完成
第二个共同点即支持任意嵌套。除之前学过的数据类型外,列表可嵌套其他列表和字典,字典也可嵌套其他字典和列表。
练手demo
练习目标:
我们会通过今天的作业,更熟练地取出层层嵌套中的数据,并了解一种新的数据类型:元组。
练习要求:
我们知道了列表和字典的不同:列表的基本单位是元素,而字典里是键值对。所以,两者提取数据的方式也不同。
你可以通过头两个练习来验证自己已经掌握了。
而在第三道练习,你会学会提取元组里的数据。
1、请你通过所学知识,把列表list1中的'love'取出来,并打印出来。
2、请你通过所学知识,把字典dict1中的'love'取出来,并打印出来。
3、下面,介绍一种新的数据类型:元组(tuple)。 可以看到:元组和列表很相似,不过,它是用小括号来包的。
元组和列表都是序列,提取的方式也是偏移量,如 tuple1[1]、tuple1[1:]。另外,元组也支持任意的嵌套。
请你根据以上提供的信息,将tuple1中的A和list2中的D打印出来。看到了,理解了,运用了,就能够掌握了。