B站主播投稿视频数据分析与tableau可视化——视频名称、简介、弹幕数、点赞数、收藏数、转发数、投币数等分析
在短视频运营中,数据分析这一环节是非常重要的,要去观察数据背后的现象,这样有利于我们对视频内容的调整,优化有一个指导性的作用。
本文爬取b站主播OldBa1的投稿视频数据,包括视频名称、简介、弹幕数、点赞数、收藏数、转发数、投币数等,并据此计算相应比率,根据视频主题和时间进行分类可视化,分析其转型可能性及方向。
数据获取与简介
本文数据是从b站爬取,本人爬虫经验不足,爬虫的部分,参考了爬取b站视频的名称、地址、简介、观看次数、弹幕数量及发布时间并保存为csv文件的方法并稍作修改。
代码如下,具体不再介绍。
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
import time
from urllib import request
import json
import importlib,sys
importlib.reload(sys)
alphabet = 'fZodR9XQDSUm21yCkr6zBqiveYah8bt4xsWpHnJE7jL5VG3guMTKNPAwcF'
def dec(x):#BV号转换成AV号
r = 0
for i, v in enumerate([11, 10, 3, 8, 4, 6]):
r += alphabet.find(x[v]) * 58**i
return (r - 0x2_0840_07c0) ^ 0x0a93_b324
def crawl():#获取每个视频的html文本
htmls = [] # 存放每个页面的HTML
# 用for循环爬取每一个页面并获得其HTML
for i in range(50):
# 用f+字符串来表示每一个页面的网址
url = f"https://search.bilibili.com/all?keyword=oldba1&from_source=nav_search&spm_id_from=333.851.b_696e7465726e6174696f6e616c486561646572.11&page={str(int(i+1))}"
r = requests.get(url) # 返回Response对象
if r.status_code != 200: # 状态码检测
raise Exception("error")
htmls.append(r.text) # r.text是字符串类型
return htmls
def parse(htmls): #对html文本进行解析
videos = [] # 存放每个视频解析出来的HTML
print('解析页面中……')
for html in htmls:
soup = BeautifulSoup(html, 'html.parser') # 解析每个页面
# 获取每个视频的标签树
video = soup.find(class_ = "video-list clearfix").find_all(class_="video-item matrix")
videos.extend(video) # 列表存入列表,所以用extend()函数
items = [] # 存放每个视频的各个项目
print('正在爬取相关信息……')
for video in videos:
up = video.find(class_ = 'up-name').get_text().split()
item = {} # 每个字典存放每个视频的相关信息
if up[0] == 'OldBa1':
item['视频标题'] = video.find('a')['title'] # 获取标签属性
item['视频地址'] = video.find('a')['href']
item['bv'] = item['视频地址'][25:37]
item['av'] = dec(item['bv'])
item['简介'] = video.find(class_ = 'des hide').string.split() # 获取NavigableString
item['观看次数'] = float(video.find(class_ = 'so-icon watch-num').get_text().split()[0][:-1])*10000 # 获取目标路径下的子孙字符串
item['发布时间'] = video.find(class_ = 'so-icon time').get_text().split()[0]
item['弹幕数量'] = float(video.find(class_ = 'so-icon hide').get_text().split()[0][:-1])*10000
if '【' in item['视频标题'] or '】' in item['视频标题']:
item['视频主题'] = item['视频标题'].split('【')[1].split('】')[0]
else:
item['视频主题'] = '其它'
items.append(item) # 字典存入列表,所以用append()函数
return items
if __name__ == '__main__':
htmls = crawl()
items = parse(htmls)
# save_to_csv(items)
print('爬取信息成功!')
def get_info(av):
headers = {
'Host': 'api.bilibili.com',
'Referer': 'https://www.bilibili.com/video/av77413543',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
info = 'https://api.bilibili.com/x/web-interface/archive/stat?aid=' + av
info_rsp = requests.get(url=info, headers=headers)
info_json = info_rsp.json()
out = {}
if info_json['code'] == 0:
out['点赞数'] = info_json['data']['like']
out['收藏数'] = info_json['data']['favorite']
out['硬币数'] = info_json['data']['coin']
out['转发数'] = info_json['data']['share']
return out
for i in range(len(items)):
out= get_info(str(items[i]['av']))
items[i].update(out)
# 将爬取的数据写入csv文件
df = pd.DataFrame(items) # 用DataFrame构造数据框
df.to_csv("OldBa1.csv")
最终得到的数据如下:
- av:投稿视频的av号
- bv:投稿视频的bv号
- 发布时间:该视频的发布时间
- 视频地址
- 视频标题
- 视频主题:爬取的主播主营第五人格,也会玩一些其他游戏和生活视频
- 简介:为了方便分析视频的性质,简介也爬取下来
- 观看次数:播放量
- 弹幕数
- 硬币数
- 点赞数
- 收藏数
- 转发数
短视频关键指标
视频播放后,观众会观看,进一步就会和观众、粉丝产生了一些互动。这就是互动数据,有几个基础的关键数据:播放量、评论量、点赞量、转发量、收藏量。
不同的视频平台对指标的重视度不同,例如微博比较看重转发等数据,可以达到更好的宣传效果,而类似抖音、快手等平台则比较看重播放量,相对而言,b站对于视频的播放量(基础指标)、一键三连(点赞投币加收藏)、特色(弹幕)这几个指标都比较看重,本文则主要围绕这几个指标进行分析。
播放量是一个基础中的基础量了,评判一个视频好坏的重要标准之一也是播放量。这里提取播放量前十的十条视频信息(可以取更多有代表性,这里只展示10条)如下:
SELECT
发布时间,简介,视频标题,视频主题,观看次数
FROM
oldba1
ORDER BY
观看次数 DESC
LIMIT 10

从年份角度分析,其中18年的占6条,19年的占2条,而17和20各占1条。
从视频主题角度分析,第五人格占5条,其它占3条,粉丝互动视频和纸人视频占2条。
从简介角度分析(由于大多数视频我都看过),播放量前10的视频的共同特点是具有爆笑的特点。
我们还有另外四种量,分析可以类似于播放量,有兴趣的可以试一下,由于和最后的总表有些相似,这里不再细说。
短视频关联指标
另外四种数据本身具有一定的价值,可能不同程度代表了受喜爱程度、视频价值、粉丝粘性等,但由于其在不同情况下会呈现不同的状态,并不能完全代表喜爱程度,比如弹幕量往往是和播放量呈正比关系的,但如果视频属于互动类型的,弹幕量往往会比其他视频多,另外一些实用性技巧(比如英语,考证等)视频往往会有更多的收藏量,同时如果粉丝粘度够高,收藏量也会比较高。
关联指标(或互动指标)是指由两个数据相互作用的结果反馈。其中比较重要的指标有:投币率、点赞率、转发率、收藏率、人均弹幕数。就是用投币量、点赞量、转发量和收藏量,弹幕数分别除以播放量得到的比率。
-
投币率 = 硬币量/播放量*100%
在b站中,投币对于up主来说是有收益的,投币率越高的视频具有的商业价值一般会越高,投币率高的视频一般是一些教程类或主播类的视频。 -
点赞率 = 点赞量/播放量*100%
点赞往往会增加视频的被推荐程度,点赞率高或点赞率增长快的更容易出现在首页,是宣传和拉新很重要的因素,因此在运营中是需要着重关注的指标。 -
转发率 = 转发量/播放量*100%
转发率高的视频,说明观众更愿意推荐给他的朋友或者通过视频表达个人的观点或态度,有较强的传播性。 -
收藏率 = 收藏量/播放量*100%
收藏率高的视频,首先代表内容本身对于观看者有用,收藏后可能产生再次观看。如果收藏率高,但是转发率很低的视频,可能涉及用户的隐私考虑,传播性有一定的局限性。 -
人均弹幕数 = 弹幕数/播放量*100%
人均弹幕数可以表现出视频的互动性,往往互动性强的视频人均弹幕数是比较高的,这样的视频更容易增加参与性。
参考播放量总是上不去? 短视频运营需注重的5个数据指标一文中的一个例子来简单说明一下这些比率的意义
两个美食制作教程为主的IP,一个是夏厨SK,另一个是贫困生活料理。
我们来看一下他们在头条发布的十个视频的数据。
夏厨SK的视频播放量几乎稳定在3W左右,高一点的5W,低一点的1W或者几千。收藏率整体偏高。最低3%点多,高的超过10%甚至达到14%。
贫困生活料理的播放量高的可以达到19W,正常是2W左右。但是播放量最高的这个视频,在最后一列的收藏率也是6%。虽然贫困生活料理的收藏率不存在什么14%的巨高量,但是有4.6%的转发率。这里就显现出求这个比率的意义了。即使播放量相差很多,比率是有可比性的。
数据上产生的差异主要来源于以下原因。
夏厨制作过程非常清晰易懂,大家看完一遍觉得有用,就会收藏一下,所以收藏率就高。贫困生活料理的视频收藏率很低,但是播放量还可以,首先因为它是创意视频。其次,它不是一个教程视频,所以收藏率低是肯定的;但过程有趣,所以转发率挺高的。
可视化展示
大概了解其中概念后,我们使用tableau进行可视化(近来突然领悟到tableau的好用之处)。
首先是整体的情况:
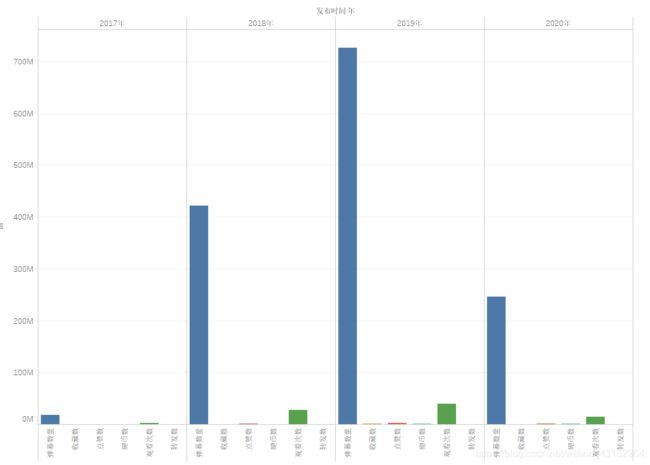
可以看到自2017年-2019年,无论是播放量还是弹幕量基本都是逐年上升的,且上升幅度较大,这也与主播人气渐高相符,但是也可以看到,虽然2020年只过去一半,但弹幕量或播放量并没有到达2019年的一半,这在粉丝量多于2019年的情况下,并不乐观。
2020年的劣势产生的原因可能有很多种,下面具体观察不同时期不同视频主题的变化情况,tableau可以很好的将几个变量指标和时间、主题融合到一起,如下:
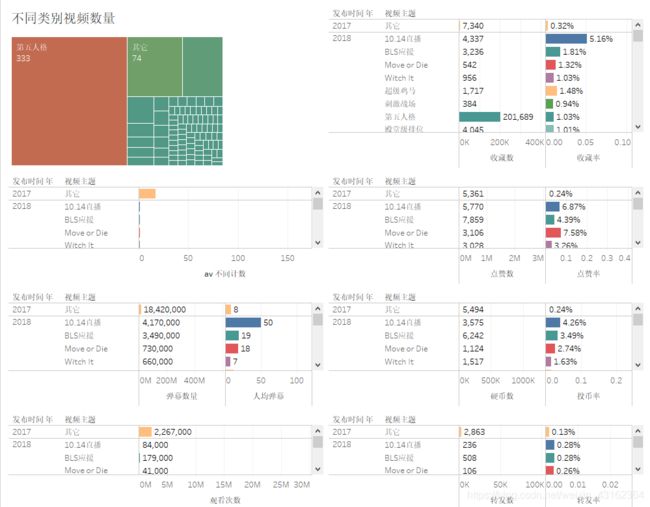
上图是个综合表,从上到下从左到右依次是:
- 主播发布的不同主题视频数量树状图
- 2017-2020年不同主题视频的收藏数和收藏率柱状图
- 2017-2020年不同主题视频的数量柱状图
- 2017-2020年不同主题视频的点赞数和点赞率柱状图
- 2017-2020年不同主题视频的弹幕数和人均弹幕数柱状图
- 2017-2020年不同主题视频的硬币数和投币率柱状图
- 2017-2020年不同主题视频的播放量柱状图
- 2017-2020年不同主题视频的转发数和转发率柱状图
下面对结果进行简单分析:
主播视频方向
由于图很大这里只放部分截图
![]()
17年是主播刚刚开始直播,视频数量较少,且没有固定分类
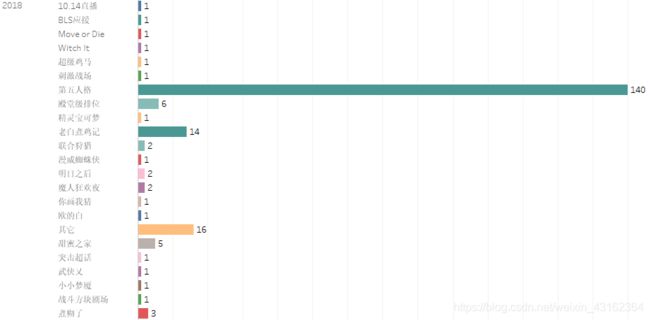
2018年主营第五人格(包括第五人格、殿堂级排位和煮鸡记),占据了视频的大部分,在此之外比较突出的是甜蜜之家视频。
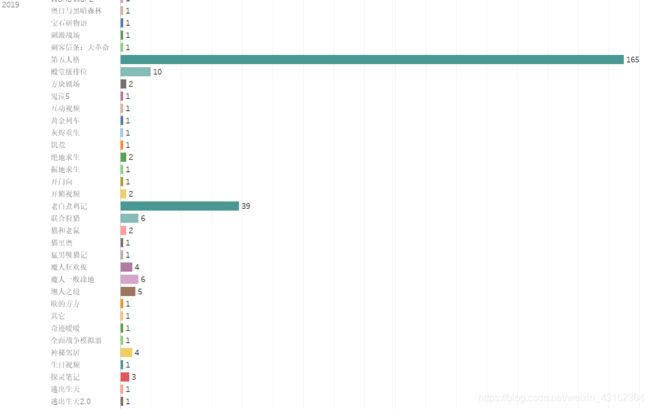
2019年仍然主营第五人格,且整体数目都比2018年高,除此之外,比较突出的是魔人一败涂地和魔人狂欢夜,另外需要重点关注的是其它类只有1条。

2020年则有比较大的变化,其它类的视频首次超越了第五人格视频,且达到历史新高,除此之外,视频数较高的是原神和动物之森。
可以看到需要着重分析的视频种类有第五人格、其它、甜蜜之家、魔人、原神、动物之森。
下面单独观察这几类视频的变化情况:
第五人格
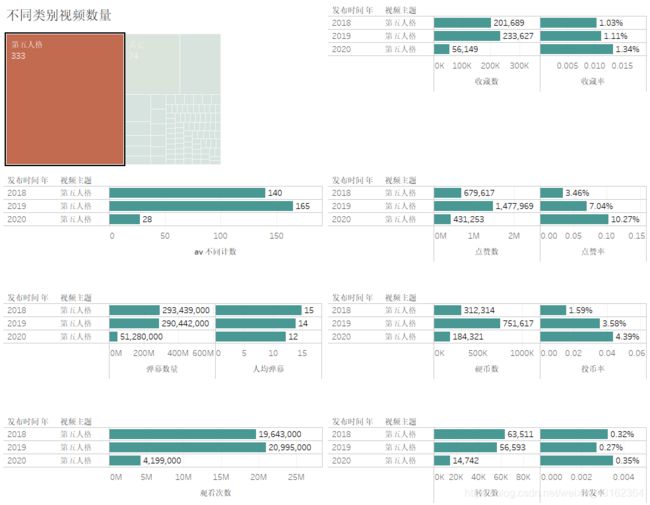
- 视频数在2019年达到高峰,而2020年则趋势减少,其它及别类游戏的数量增多,大概可以看出主播的侧重点有偏移。
- 收藏和播放量都和视频的数量成正比,而点赞和投币都在2019年比较高,相对于,总体上是比较好的趋势,比较异常的是转发量,2018年的视频虽然少于2019年但转发却更加高。
- 从比率的角度来说,转化较高的是投币和点赞,且逐年递增,点赞率到2020年高达10.27%,投币也到达4.39%,其次是收藏率平均只有1%左右,而转化率只有0.3%左右。
- 人均弹幕数大约在14左右,但逐年递减,这可能与主播第五人格精力减少有关。
其它
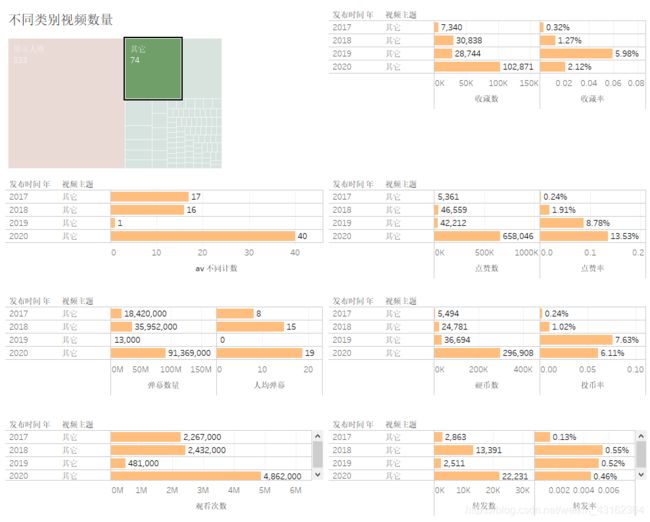
-
其他类视频在2020年有异常高的数量,相较于前几年,在2020年达到半年的时候其他类视频数量就已经比较高了,相应的点赞、投币、收藏等指标也都随着视频量增加。
-
从比率的角度来说,点赞、投币、收藏、转化的比率与第五人格相比都更高,也就是说这种视频方向的转变在粉丝中的接受程度比较高。
-
人均弹幕数2020年高达19,说明与粉丝互动可能更多。
甜蜜之家
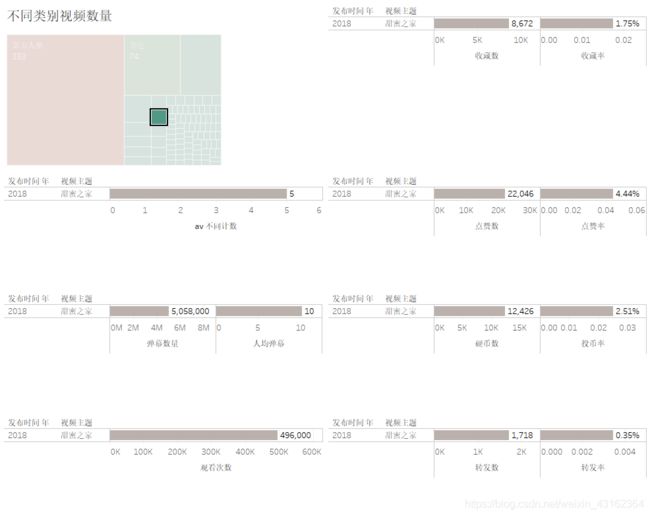
魔人

原神

动物之森

以上分别是甜蜜之家、魔人、动物之森、原神的数据可视化,与第五人格相比,表现最好的是魔人类的视频,人均弹幕数、点赞率和转发率都处于比较高的值,其次则是原神类视频。
总结
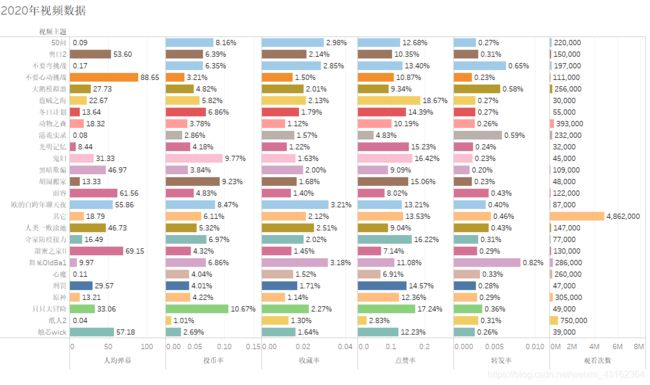
结合之前的分析,再查看一下2020年以来已经播过的视频数据情况(排除生日茶话会,第五人格等视频)如上图
- 舞见OldBa1、除夕夜谈等几个贴近主播生活的视频几个指标都相对较高。
- 播放量更多的是只只大冒险、港诡实录、动物之森等游戏。
- 弹幕量更多的是一些恐怖游戏和互动视频,如甜蜜之家、面容和不要心动挑战。
- 只只大冒险,烛芯,盗贼之海,鬼父四款游戏主题的特点是播放量不高,但其他指标例如弹幕数、点赞数却相对较高。
总结
总体而言,视频重心的改变并没有产生大幅度的粉丝流失,关于改变的方向仍然需要探索,数据较好的游戏视频(如港诡实录)属于短期一次性游戏,不具有可持续性。生活类视频和互动类视频也比较受欢迎,也是着重分享的一部分。